1、 Buffer.h
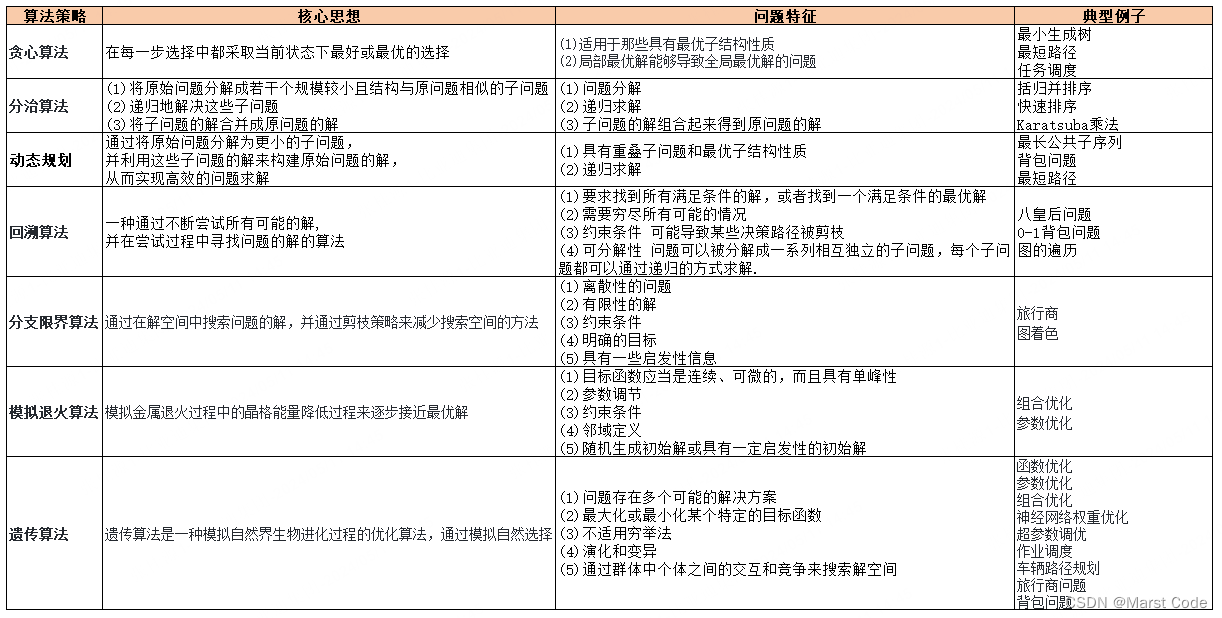
Buffer封装
是一个缓冲区
prependable bytes+readable bytes+writable bytes=8字节长度(解决粘包问题)+读数据+写数据
根据下标进行读或者写

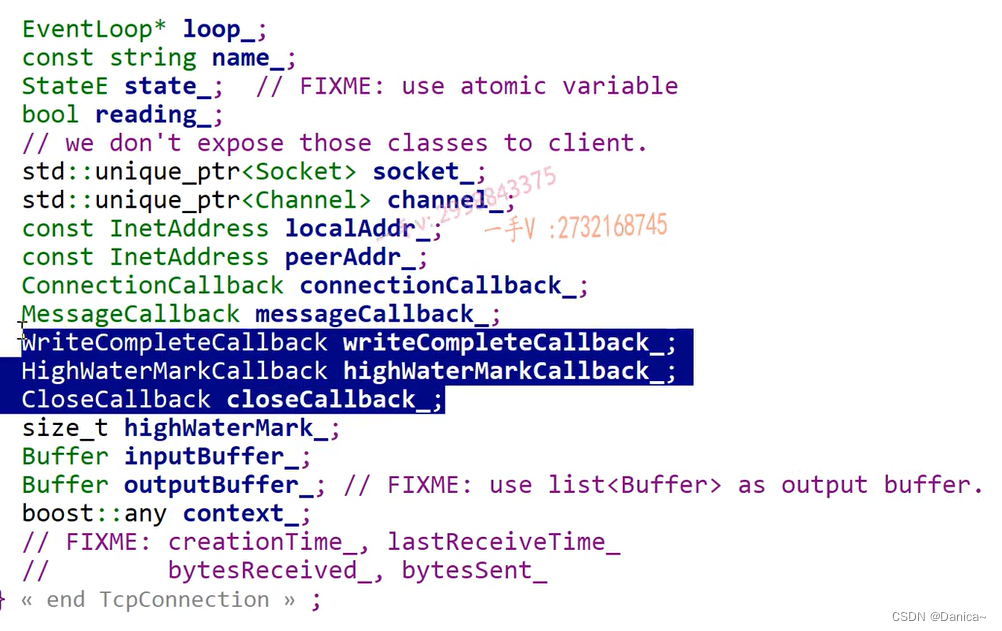
3个成员变量:数组,数据可读的下标,数据可写的下标

#pragma once#include <vector>
#include <string>
#include <algorithm>//网络库底层的缓冲区类型定义
class Buffer
{
public:static const size_t kCheapPrepend=8;//记录数据包的长度static const size_t kInitialSize=1024;//缓冲区的大小explicit Buffer(size_t initialSize=kInitialSize):buffer_(kCheapPrepend+initialSize),readerIndex_(kCheapPrepend),writerIndex_(kCheapPrepend){}size_t readableBytes() const//可读的缓冲区大小{return writerIndex_-readerIndex_;}size_t writableBytes() const//可写的缓冲区大小{return buffer_.size()-writerIndex_;}size_t prependableBytes() const//prependable Bytes区域大小{return readerIndex_;}//返回缓冲区中可读数据的起始地址const char* peek() const{return begin()+readerIndex_;}//注册回调 onMessage 有读写事件发生时,将buffer->stringvoid retrieve(size_t len){if(len<readableBytes()){readerIndex_+=len;//应用只读取了可读缓冲区数据的一部分,就是len,还剩下readerIndex_+=len~writerIndex_没读}else//len==readableBytes(){retrieveAll();}}void retrieveAll(){readerIndex_=writerIndex_=kCheapPrepend;}//把onMessage函数上报的Buffer数据,转成string类型的数据返回std::string retrieveAllAsString(){return retrieveAllAsString(readableBytes());//应用可读取数据的长度}std::string retrieveAllAsString(size_t len){std::string result(peek(),len);//peek() 可读数据的起始地址retrieve(len);//上面一句把缓冲区中可读的数据,已经读取出来,这里肯定要对缓冲区进行复位操作return result;}//剩余的可写缓冲区buffer_.size()~writerIndex_ 要写的数据的长度 lenvoid ensureWriteableBytes(size_t len){if(writableBytes()<len){makeSpace(len);//扩容函数}}//把[data,data+len]内存上的数据,添加到writable缓冲区当中void append(const char* data,size_t len){ensureWriteableBytes(len);//确保空间可用std::copy(data,data+len,beginWrite());writerIndex_+=len;}char* beginWrite()//可以写的地方的地址{return begin()+writerIndex_;}const char* beginWrite()const//常对象可调用{return begin()+writerIndex_;}//从fd上读取数据ssize_t readFd(int fd,int* saveErrno);//通过fd发送数据ssize_t writeFd(int fd,int* saveErrno);private:char* begin(){//it.operator*() 取迭代器访问的第一个元素,再对这个元素取地址return &*buffer_.begin();//vector底层数组首元素的地址,也就是数组的起始地址}const char* begin() const{return &*buffer_.begin();}void makeSpace(size_t len){/*kCheapPrepend | reader | writer |kCheapPrepend | len |*/if(writableBytes()+prependableBytes()<len+kCheapPrepend)//writableBytes()+prependableBytes()=>可写缓存区长度+已读完数据已经空闲下来的缓冲区{buffer_.resize(writerIndex_+len);//扩容}else//将未读数据和可写缓冲区往前挪{size_t readalbe=readableBytes();//未读数据长度std::copy(begin()+readerIndex_,//将未读数据挪到前面begin()+writerIndex_,begin()+kCheapPrepend);readerIndex_=kCheapPrepend;//readerIndex_前移writerIndex_=readerIndex_+readalbe;//writerIndex_前移}}std::vector<char> buffer_;size_t readerIndex_;size_t writerIndex_;
};2、Buffer.cc
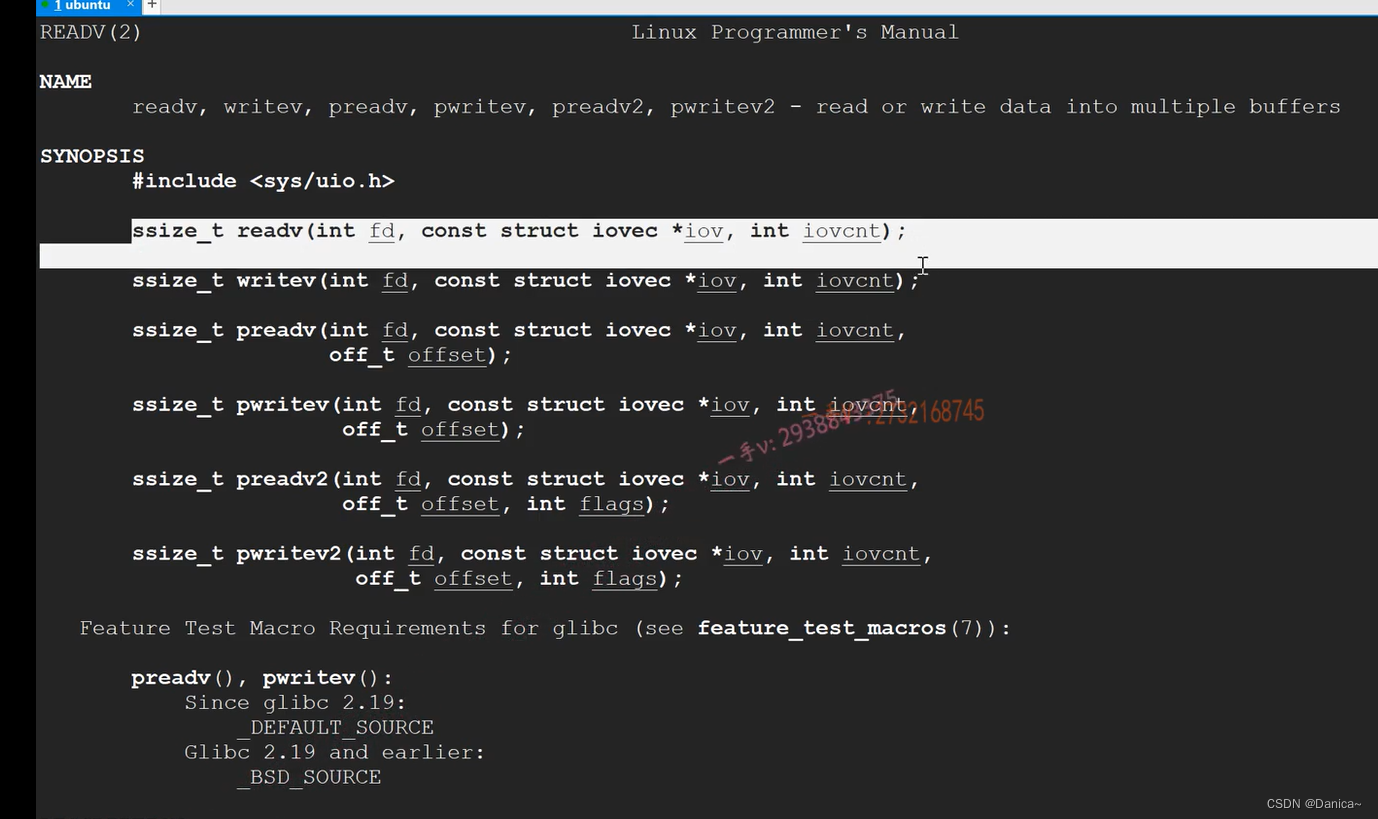
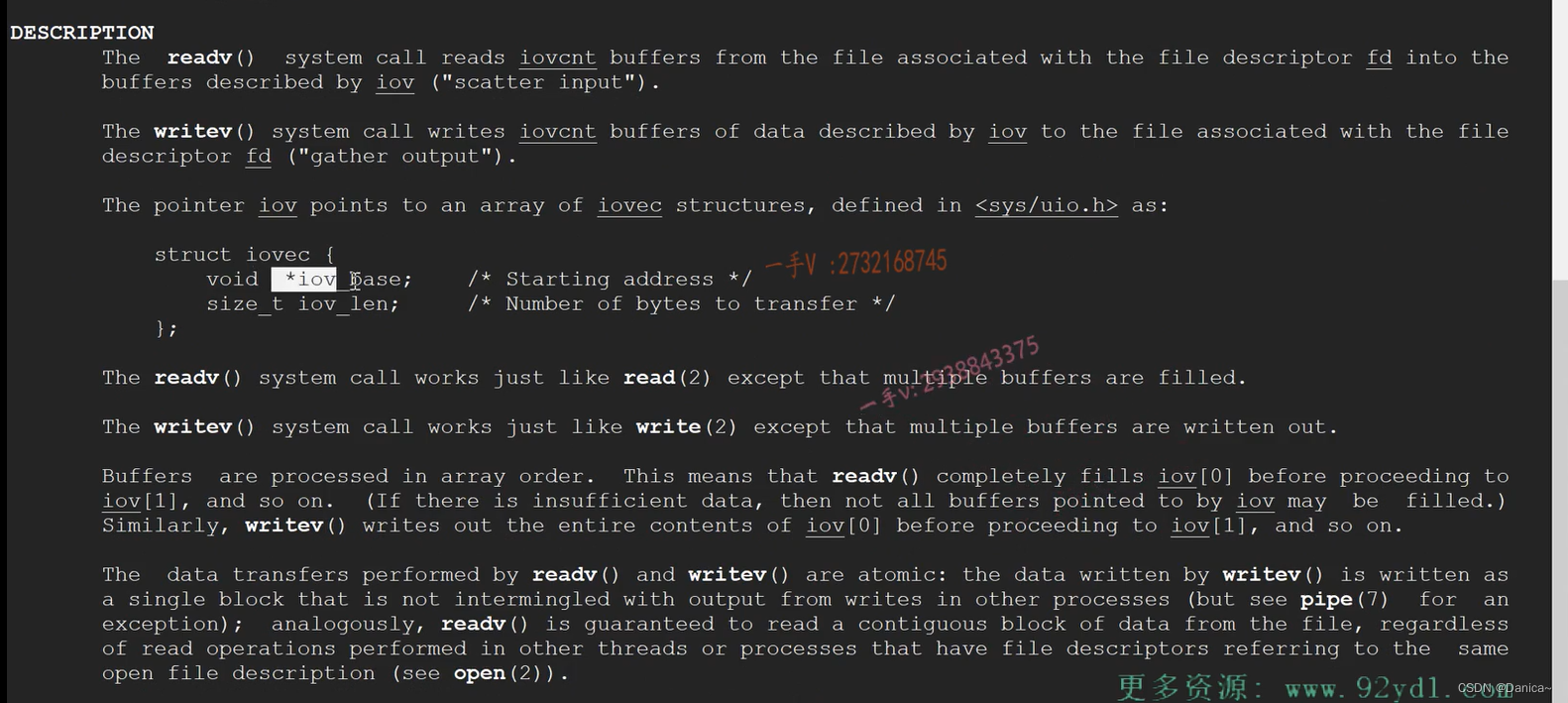
readv()可以根据读出的数据,自动填充多个缓冲区,这些缓冲区不需要连续
iovec:缓冲区的起始地址,缓冲区的长度


#include "Buffer.h"#include <errno.h>
#include <sys/uio.h>
#include <unistd.h>/*** 从fd上读取数据 Poller工作在LT模式* Buffer缓冲区是有大小的! 但是从fd上读数据的时候 却不知道tcp数据最终的大小
*/
ssize_t Buffer::readFd(int fd,int* saveErrno)
{char extrabuf[65536]={0};//栈上的内存空间 64kstruct iovec vec[2];const size_t writable=writableBytes();//这是Buffer底层缓冲区剩余的可写空间大小vec[0].iov_base=begin()+writerIndex_;//缓冲区的起始地址vec[0].iov_len=writable;//缓冲区的长度//如果vec[0]缓冲区够填的话,就填充到vec[0],不够填,就填到vec[1],最后,如果我们看到vec[1]中有内容的话,就把其中的内容直接添加到缓冲区中//缓冲区刚刚好存入所有我们需要写入的内容,不浪费空间,空间利用率高vec[1].iov_base=extrabuf;vec[1].iov_len=sizeof extrabuf;const int iovcnt=(writable<sizeof extrabuf)?2:1;const ssize_t n=::readv(fd,vec,iovcnt);if(n<0){*saveErrno=errno;}else if(n<=writable)//Buffer的可写缓冲区已经够存储读出来的数据了{writerIndex_+=n;}else//extrabuf里面也写入了数据{writerIndex_=buffer_.size();append(extrabuf,n-writable);//writerIndex_开始写n-writable大小的数据}return n;//读取的字节数
}// 通过fd发送数据
ssize_t Buffer::writeFd(int fd, int *saveErrno)
{ssize_t n=::write(fd,peek(),readableBytes());if(n<0)//错误{*saveErrno=errno;}return n;
}