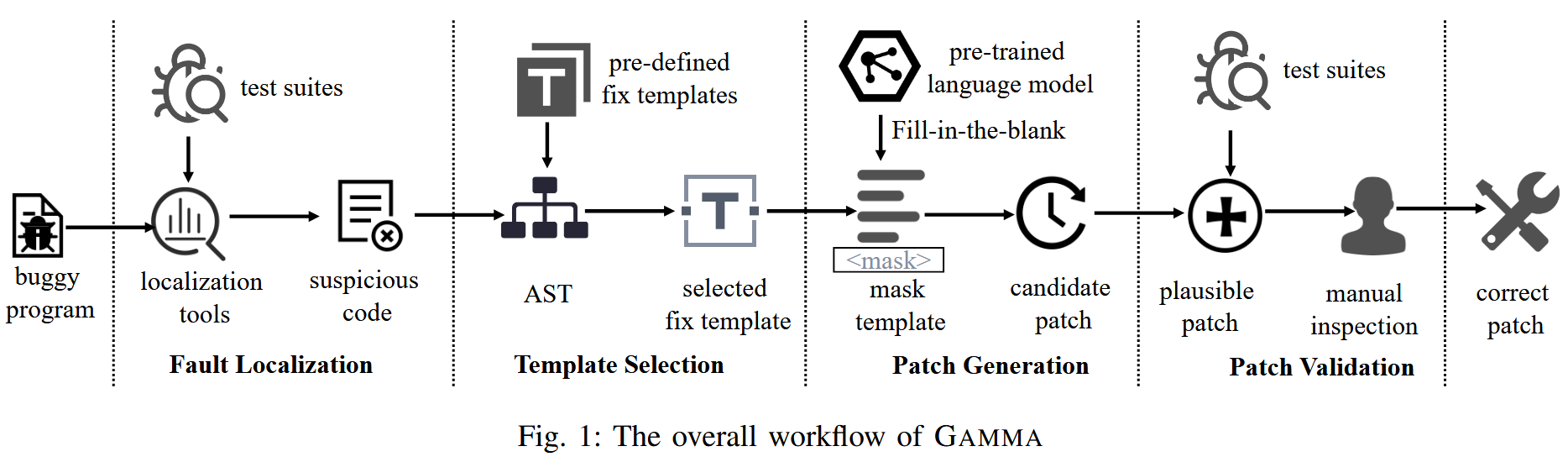
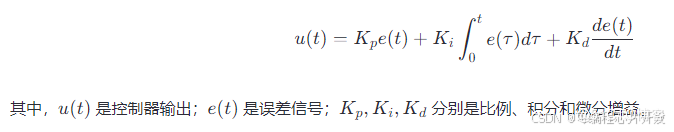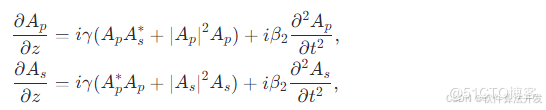一、全链路测试的入门理解
1.1什么是全链路测试?
全链路测试是指对系统中所有组件和服务的完整流程进行测试,确保从用户请求到系统响应的每个环节都能正常工作。它覆盖了前端、后端、数据库、第三方服务等所有部分。
通俗解释:想象你在网上购物,从搜索商品到下单、支付、收货,整个过程涉及多个步骤。全链路测试就是模拟这个完整流程,确保每个环节都顺畅无误。
1.2全链路测试的举例
下面举个实例:
- 用户下单:用户在前端选择商品并提交订单。
- 订单处理:后端接收订单,检查库存。
- 支付:调用支付系统完成支付。
- 物流:生成物流单,通知仓库发货。
- 通知:发送订单确认邮件或短信。
全链路测试会模拟这个流程,确保每个环节都能正常运作。
1.3全链路压测的基本模型
全链路压测是通过模拟高并发场景,测试系统在压力下的表现,找出性能瓶颈。
通俗解释:就像在购物节期间,大量用户同时下单,系统能否承受住这种压力而不崩溃。
下面举个实例:
- 模拟高并发:使用工具模拟成千上万的用户同时下单。
- 监控系统:观察系统在高负载下的表现,如响应时间、错误率等。
- 分析瓶颈:找出性能瓶颈,可能是数据库、服务器或网络。
全链路压测的模型通常包括以下步骤:
- 需求分析:确定测试目标和场景,如模拟多少用户、测试哪些功能。
- 环境搭建:准备与生产环境相似的测试环境。
- 脚本编写:编写模拟用户行为的脚本。
- 执行压测:运行脚本,逐步增加负载。
- 监控与收集数据:实时监控系统性能,收集数据。
- 分析与优化:分析数据,找出瓶颈并优化系统。
- 报告与总结:生成报告,提出改进建议。
下面举个实例:
- 需求分析:模拟“双11”购物节,测试系统能否支持100万用户同时下单。
- 环境搭建:搭建与生产环境相同的测试环境。
- 脚本编写:编写脚本模拟用户从浏览到下单的完整流程。
- 执行压测:逐步增加并发用户数,观察系统表现。
- 监控与收集数据:监控响应时间、错误率等。
- 分析与优化:发现数据库响应慢,优化查询。
- 报告与总结:生成报告,建议增加数据库资源。
通过这些步骤,全链路压测帮助确保系统在高负载下依然稳定可靠。
二、影子体系
2.1什么是影子测试?
影子测试(Shadow Testing)或影子流量(Shadow Traffic)通常指将生产环境的流量复制到测试环境,以验证新版本或新系统是否能正确处理真实流量,而不会影响实际用户。
2.2什么是影子体系?
全链路测试中的影子体系(Shadow System)是一种“无侵入式”的测试技术,通过在生产环境中复制真实流量并引导到测试系统(影子系统),在不影响真实用户的前提下,验证新功能或新系统的正确性和性能。下面用通俗的语言和实例详细解释。
核心目标
- 验证新功能:比如上线一个新支付接口,在不影响用户的情况下,用真实流量测试它是否正常。
- 发现隐藏问题:用真实场景的复杂请求,提前发现代码漏洞或性能瓶颈。
2.3影子体系的工作原理
假设有一个电商系统,用户下单的真实流程如下:

引入影子体系后,流程变为:
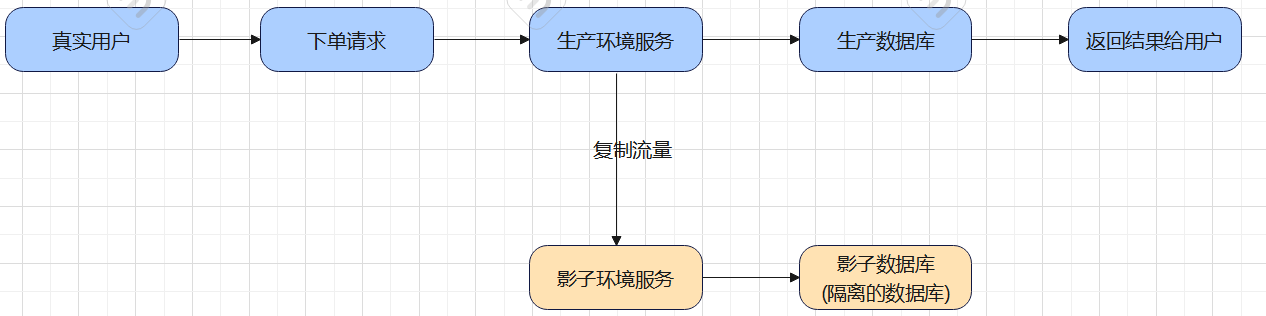
关键点
- 流量复制:真实用户的请求会被同时复制一份发送到影子环境。
- 数据隔离:影子环境使用独立的数据库和资源,不与生产数据混用。
- 无副作用:影子环境的处理结果不会返回给用户,也不影响真实业务。
2.4影子体系的举例
电商系统如何用影子体系测试新功能?
场景:上线一个新的“优惠券计算服务”,需验证其正确性,怎么测?
传统方式的风险:
如果直接在生产环境测试,一旦新服务有Bug,可能导致用户下单失败或优惠券计算错误。
影子体系方案:
1.复制用户请求:当真实用户下单时,系统同时将相同的请求(商品信息、优惠券等)发送到影子环境。
2.并行处理
- 生产环境:用旧服务计算优惠券,完成真实订单。
- 影子环境:用新服务计算优惠券,结果写入影子数据库。
3.结果比对
- 对比新旧服务的计算结果(比如优惠金额是否一致)。
- 如果发现差异,说明新服务存在问题,需修复后再上线。
用户无感知:整个过程对真实用户完全透明,即使新服务出错,也不影响实际订单。
2.5影子体系的核心组件
1.流量复制工具
- 例如:Nginx镜像流量、Apache Kafka复制请求日志。
2.影子环境
- 独立的服务器、数据库、缓存等,配置和生产环境一致。
3.数据隔离机制
- 影子数据库与生产数据库物理隔离,测试数据可定期清理。
4.监控与比对系统
- 监控影子服务的响应时间、错误率,并自动比对生产与影子环境的结果差异。
2.6适用场景和注意事项
***适用场景***
1.新功能上线前的验证(如新支付接口、新算法)。
2.性能压测:用真实流量模拟高并发,观察系统瓶颈。
3.灾难恢复演练:模拟数据库宕机,测试容灾能力。
***注意事项***
1.资源成本:影子环境需要独立的硬件资源,成本较高。
2.数据脱敏:如果复制敏感数据(如用户手机号),需先脱敏处理。
3.流量过滤:避免将恶意请求(如攻击流量)复制到影子环境。
三、影子数据
3.1影子数据
全链路功能根植于影子体系,按照之前的介绍,影子体系是通过影子标来标记影子流量、通过影子表保存影子体系数据的。影子表和正式表同库,表结构和线上保持一致, 只是表名加前缀,如同影子一般,因此,存储在影子表中的数据被称作影子数据。
3.2影子数据的生成
全链路功能要提前验证大促招商的所有数据,涉及的影子数据是上亿级的,且是各库表的各种类型的数据,如何圈定线上数据,将线上数据迁移成可用的影子数据,并且不会对线上数据造成影响,就成为首先需要解决的问题。
影子数据平台是在解决这个问题的过程中诞生的,它构建了一条通道,将正式表的数据搬运到影子表中,产生可用的影子数据,影子数据的生成过程如图所示。
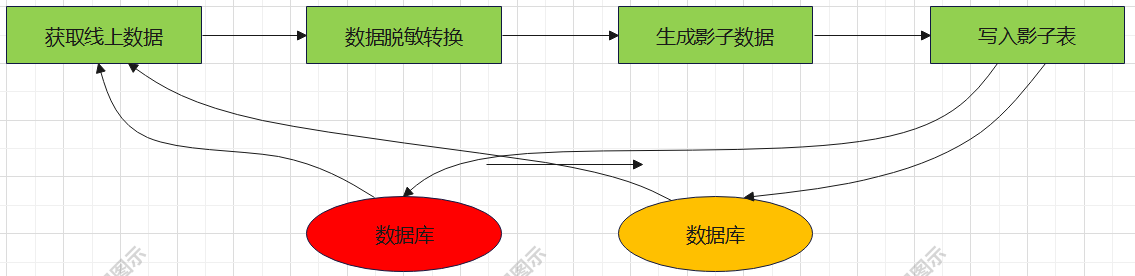
影子数据的生成过程,并不是完全的复制过程。虽然有了影子表,有了中间件作为媒介透传影子表、识别影子流量,但面对复杂的应用系统, 为避免影子表在透传的过程中丢失导致影子数据污染线上正式数据,同时为了保障线上用户信息的安全,影子数据平台在迁移数据到影子表的过程中,增加了脱敏转换和数据区间映射的逻辑,其作用主要有两个:其一,用户的电话、地址等敏感数据在线上已处于不可见状态,在迁移影子表时,会二次脱敏,只根据字段名生成测试数据值;其二,将商品ID、用户ID等核心数据偏移映射到另一个数据区间,这个数据区间与线上正式的数据区间无交集,且预计在相当长的一段时间内都不会有相交的可能性。
影子数据和普通测试数据的区别有以下几点。
●真实:影子数据是经过脱敏及映射转换处理的线上正式数据,而这种脱敏转换可以看作一个映射, 只改变了数据的范围空间,本身是可对线上正式数据进行仿真的。测试数据出于各种原因,都无法完全仿真线上数据。
●海量:影子数据是将线上正式数据复制到影子表中得到的,在拥有快速同步方法的情况下,可以认为,线上所有正式的数据都可以迁移成影子数据,成为被测数据,这样影子数据就是一个海量的数据池。
●准备成本低:构造数据,最困难的点在于准备上下游的数据,线上数据已经拥有这样的上下游关系,而影子数据平台将数据的上下游关系进行了关联,要准备影子数据非常方便。比如想测试某个业务商品的下单功能,只需要提供线上商品ID,影子数据平台就可以将商品相关联的所有域的数据(包含库存、店铺等信息)一起同步到影子表中。
3.3影子数据的使用
影子数据为全链路功能提供了充足的“弹药”,在类似“双11” 这样的大促时,会将千万种商品及其关联数据,脱敏转换后迁移到影子链路中,构建模拟大促真实场景的影子数据模型。拥有了这些“真实”大促场景数据,再基于修改环境时间的功能和用户行为分析功能,全链路功能就可以提前模拟“双11”真实的用户行为,实现提前过“双11”、提前发现线上的潜在问题的目的。
全链路影子数据用于功能测试起源于全链路动能,但是随着影子体系的不断完善,影子数据也开始在更多的测试场景中发挥更多的作用。
四、总结
影子体系就像一个“隐形测试员”,它能用真实用户的请求在后台默默测试新功能,既不影响用户体验,又能提前暴露问题。核心价值是“用真实场景,零风险验证”。


![Hetao P1287 小核桃玩核桃棋 题解 [ 蓝 ] [ 观察 ] [ 二维 dp ] [ 容斥原理 ]](https://img2024.cnblogs.com/blog/3389671/202503/3389671-20250311000022643-955048225.png)