说明
只是为了速记一下这个实践过程。整体上说,这个结果并不是那么好用,但有一些可以借鉴的地方。
先看结果:

生成的PPT
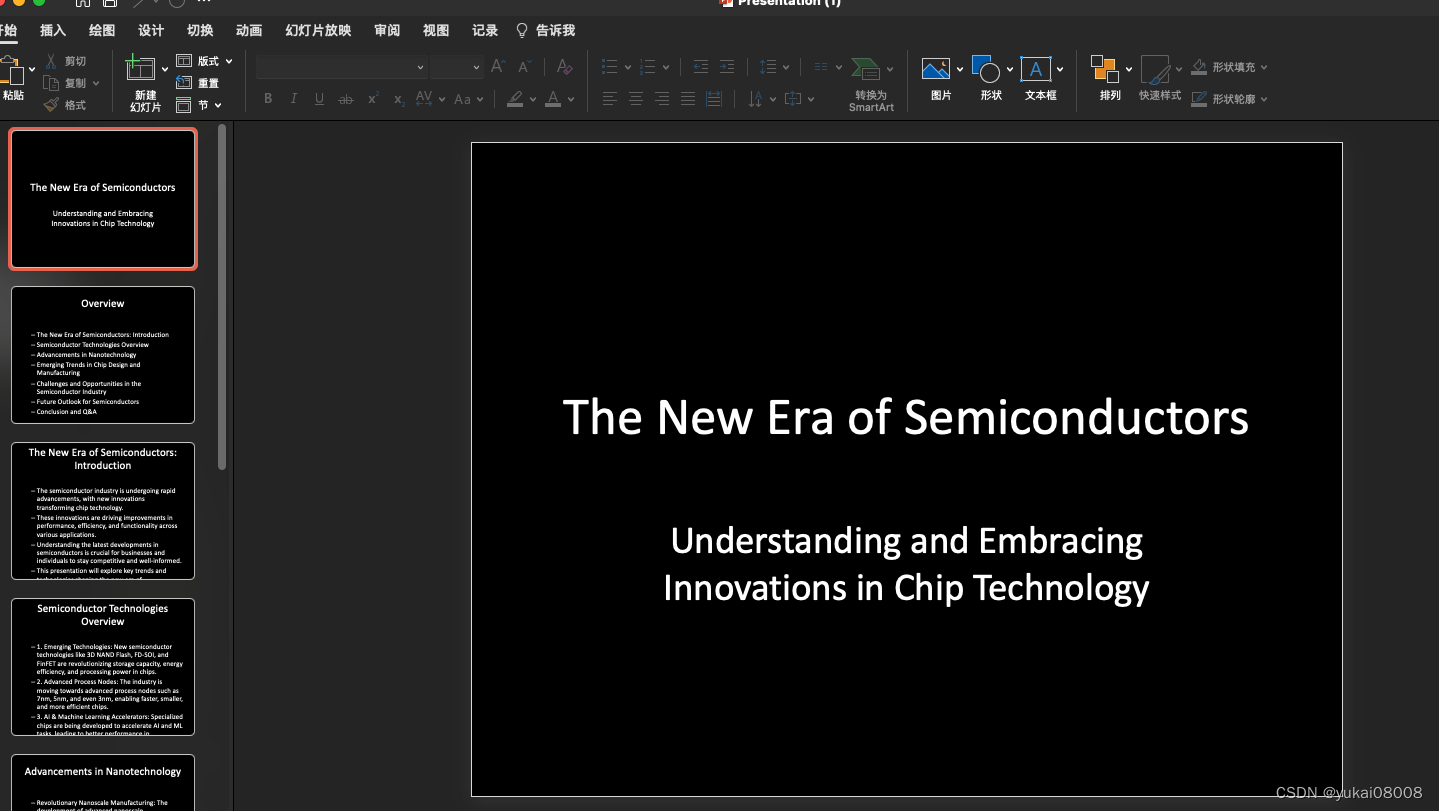
说的直白点,就是用大模型生成了一堆没太有意义的文字,然后做成ppt。所以实用是不成的,但是里面有一些过程可以借鉴。
内容
1 项目地址
ppt_generator
整个项目没有几个文件,感觉也就是一个原型实验。
需要的环境是本地ollama(恰好我有),然后拉一个模型
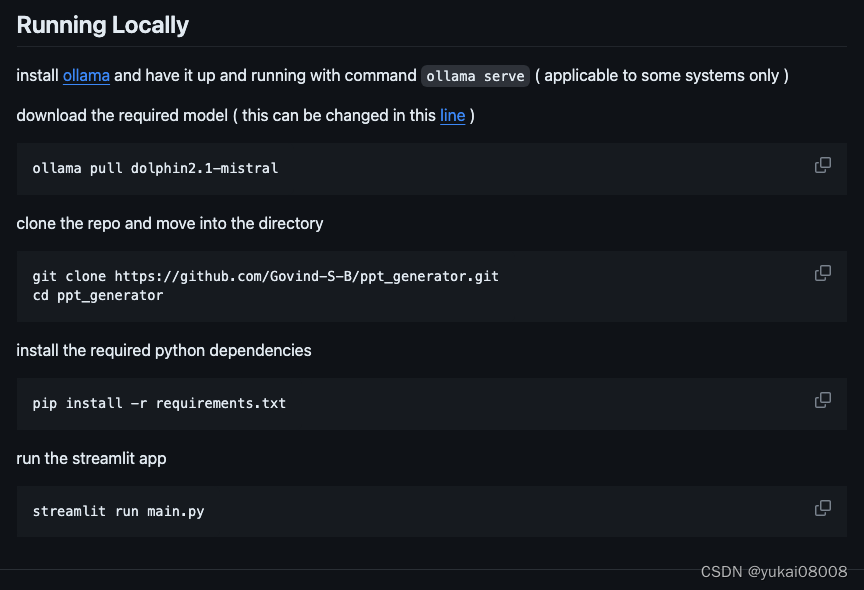
项目里还漏了 requirement.txt,我的环境下,主要再安装一个包就可以了
pip3 install python-pptx -i https://mirrors.aliyun.com/pypi/simple/
2 使用
启动 streamlit run main.py,然后会弹出一个web页面,输入一个主题,然后就返一个ppt给你。整体过程大概1~2分钟,考虑是笔记本,而且也看到什么资源占用,所以可以认为是不太占资源的。
3 核心代码
使用langchain加载了ollama模型,生成数据
def slide_data_gen(topic):llm = Ollama(model="dolphin2.1-mistral",temperature="0.4")slide_data = []point_count = 5slide_data.append(extract_items(llm(f"""You are a text summarization and formatting specialized model that fetches relevant informationFor the topic "{topic}" suggest a presentation title and a presentation subtitle it should be returned in the format :<< "title" | "subtitle >>example :<< "Ethics in Design" | "Integrating Ethics into Design Processes" >>""")))slide_data.append(extract_items(llm(f"""You are a text summarization and formatting specialized model that fetches relevant informationFor the presentation titled "{slide_data[0][0]}" and with subtitle "{slide_data[0][1]}" for the topic "{topic}"Write a table of contents containing the title of each slide for a 7 slide presentationIt should be of the format :<< "slide1" | "slide2" | "slide3" | ... | >>example :<< "Introduction to Design Ethics" | "User-Centered Design" | "Transparency and Honesty" | "Data Privacy and Security" | "Accessibility and Inclusion" | "Social Impact and Sustainability" | "Ethical AI and Automation" | "Collaboration and Professional Ethics" >> """)))for subtopic in slide_data[1]:data_to_clean = llm(f"""You are a content generation specialized model that fetches relevant information and presents it in clear concise mannerFor the presentation titled "{slide_data[0][0]}" and with subtitle "{slide_data[0][1]}" for the topic "{topic}"Write the contents for a slide with the subtopic {subtopic}Write {point_count} points. Each point 10 words maximum.Make the points short, concise and to the point.""")cleaned_data = llm(f"""You are a text summarization and formatting specialized model that fetches relevant information and formats it into user specified formatsGiven below is a text draft for a presentation slide containing {point_count} points , extract the {point_count} sentences and format it as :<< "point1" | "point2" | "point3" | ... | >>example :<< "Foster a collaborative and inclusive work environment." | "Respect intellectual property rights and avoid plagiarism." | "Uphold professional standards and codes of ethics." | "Be open to feedback and continuous learning." >>-- Beginning of the text --{data_to_clean}-- End of the text -- """)slide_data.append([subtopic] + extract_items(cleaned_data))return slide_data
根据数据生成ppt
def ppt_gen(slide_data):ppt = Presentation()# Setting Backgroundslide_master = ppt.slide_masterslide_master.background.fill.solid()slide_master.background.fill.fore_color.rgb = RGBColor(0, 0, 0)# Title Screencurr_slide = ppt.slides.add_slide(ppt.slide_layouts[0])curr_slide.shapes.title.text = slide_data[0][0]curr_slide.shapes.title.text_frame.auto_size = MSO_AUTO_SIZE.TEXT_TO_FIT_SHAPEcurr_slide.shapes.title.text_frame.paragraphs[0].runs[0].font.color.rgb = RGBColor(255, 255, 255)curr_slide.shapes.placeholders[1].text = slide_data[0][1]curr_slide.shapes.placeholders[1].text_frame.auto_size = MSO_AUTO_SIZE.TEXT_TO_FIT_SHAPEcurr_slide.shapes.placeholders[1].text_frame.paragraphs[0].runs[0].font.color.rgb = RGBColor(255, 255, 255)# Overviewcurr_slide = ppt.slides.add_slide(ppt.slide_layouts[1])curr_slide.shapes.title.text = "Overview"curr_slide.shapes.title.text_frame.auto_size = MSO_AUTO_SIZE.TEXT_TO_FIT_SHAPEcurr_slide.shapes.title.text_frame.paragraphs[0].runs[0].font.color.rgb = RGBColor(255, 255, 255)for content in slide_data[1]:tframe = curr_slide.shapes.placeholders[1].text_frametframe.auto_size = MSO_AUTO_SIZE.TEXT_TO_FIT_SHAPEpara = tframe.add_paragraph()para.text = contentpara.level = 1para.font.color.rgb = RGBColor(255, 255, 255)# Content Slidesfor curr_slide_data in slide_data[2:]:curr_slide = ppt.slides.add_slide(ppt.slide_layouts[1])curr_slide.shapes.title.text = curr_slide_data[0]curr_slide.shapes.title.text_frame.auto_size = MSO_AUTO_SIZE.TEXT_TO_FIT_SHAPEcurr_slide.shapes.title.text_frame.paragraphs[0].font.color.rgb = RGBColor(255, 255, 255)for content in curr_slide_data[1:]:tframe = curr_slide.shapes.placeholders[1].text_frametframe.auto_size = MSO_AUTO_SIZE.TEXT_TO_FIT_SHAPEpara = tframe.add_paragraph()para.text = contentpara.level = 1para.font.color.rgb = RGBColor(255, 255, 255)# Thank You Screencurr_slide = ppt.slides.add_slide(ppt.slide_layouts[2])curr_slide.shapes.placeholders[1].text = "Thank You"curr_slide.shapes.placeholders[1].text_frame.paragraphs[0].font.color.rgb = RGBColor(255, 255, 255)curr_slide.shapes.placeholders[1].text_frame.paragraphs[0].font.size = Pt(96)curr_slide.shapes.placeholders[1].text_frame.paragraphs[0].alignment = PP_ALIGN.CENTER# f"{sanitize_string(slide_data[0][0])}.pptx"ppt_stream = io.BytesIO()ppt.save(ppt_stream)ppt_stream.seek(0)return ppt_stream4 总结
- 1 可以参考langchain,进行增强。langchain本身还有agent的能力,继续融合后,是有可能完全不一样的。例如当你提到一个论点,agent可以自动查询实时数据,找到论据来support.
- 2 ppt生成(及读取)。之前比较少用python操作ppt,现在看来,读和简单写应该是没问题的。