交换排序基本思想:
所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
目录
1.冒泡排序
2.快速排序
2.1 递归实现
2.2 快速排序优化
2.3 非递归实现
1.冒泡排序
假设升序。每次遍历,两两比较,将大的元素向后交换,直到选出最大的元素放在最后,这时已经确定了升序中最后一个元素,然后多次遍历前面无序的元素,每次可以确定一个最大的数,直到排序完成。
动态图解:
代码实现:
//交换函数
void Swap(int* p1, int* p2)
{int t = *p1;*p1 = *p2;*p2 = t;
}void BubbleSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++){for (int j = 0; j < n - 1 - i; j++){if (arr[j] > arr[j + 1]){Swap(&arr[j], &arr[j + 1]);}}}
}如果在排序有序数据时,我们还可以优化一下,提高一下效率,代码如下
void BubbleSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++){int flag = 1;//假设已经有序for (int j = 0; j < n - 1 - i; j++){if (arr[j] > arr[j + 1]){Swap(&arr[j], &arr[j + 1]);flag = 0;//发生交换,说明无序}}if(flag == 1)//已经有序,不在继续排序{break;}}
}冒泡排序的特性总结:
- 冒泡排序是─种非常容易理解的排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
2.快速排序
2.1 递归实现
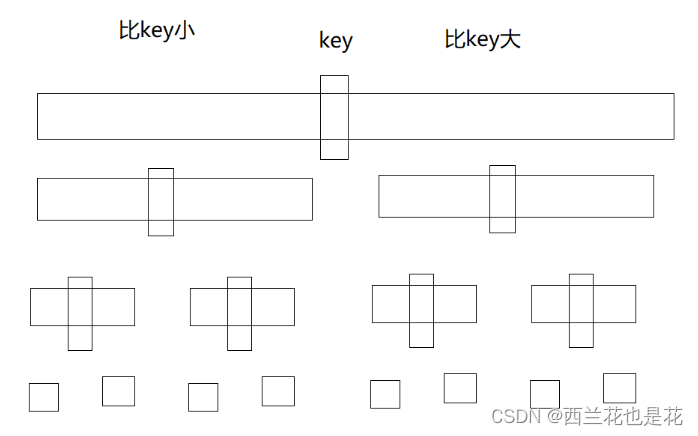
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值key,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值key,右子序列中所有元素均大于基准值key,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
图示:
代码实现:
假设按照升序对array数组中【left, right】左右都是闭区间中的元素进行排序。
void QuickSort(int* a, int left, int right)
{if (left >= right){return;}//按照基准值(中间位置)对array数组的[left, right]区间中的元素进行划分int keyi = PartSort(a, left, right);//划分成功后以div为边界形成了左右两部分[left, keyi-1]和[key+1,right]//递归排 [left, keyi-1]QuickSort(a, left, keyi - 1);//递归排[key+1,right]QuickSort(a, keyi + 1, right);
}上述为快速排序递归实现的主框架,发现与二叉树前序遍历规则非常像,大家在写递归框架时可想想二叉树前序遍历规则即可快速写出来,后序只需分析如何按照基准值来对区间中数据进行划分的方式即可。
将区间按照基准值划分为左右两半部分(PartSort)的常见方式有:
1. hoare 版本
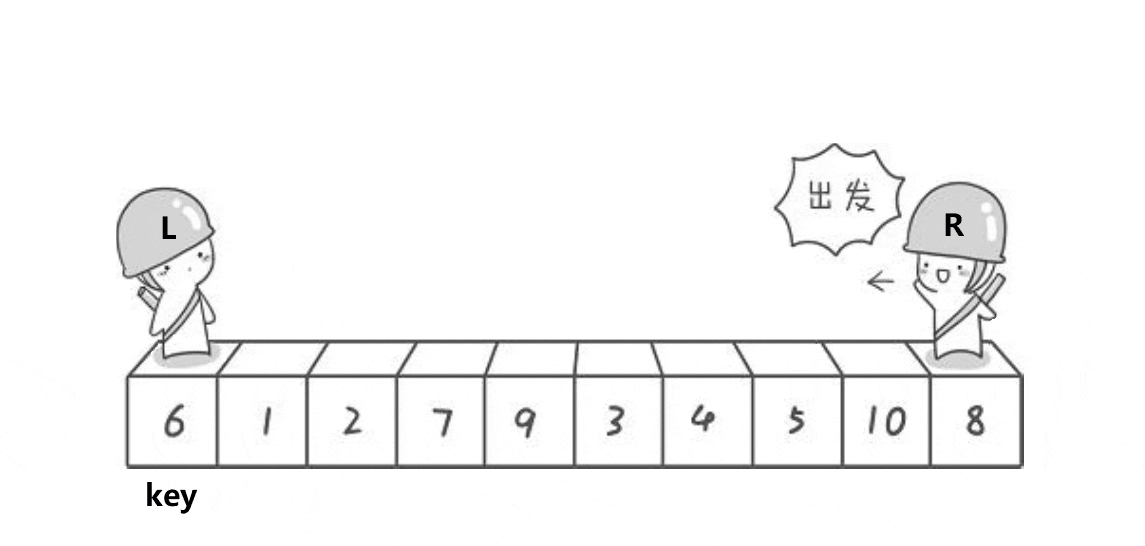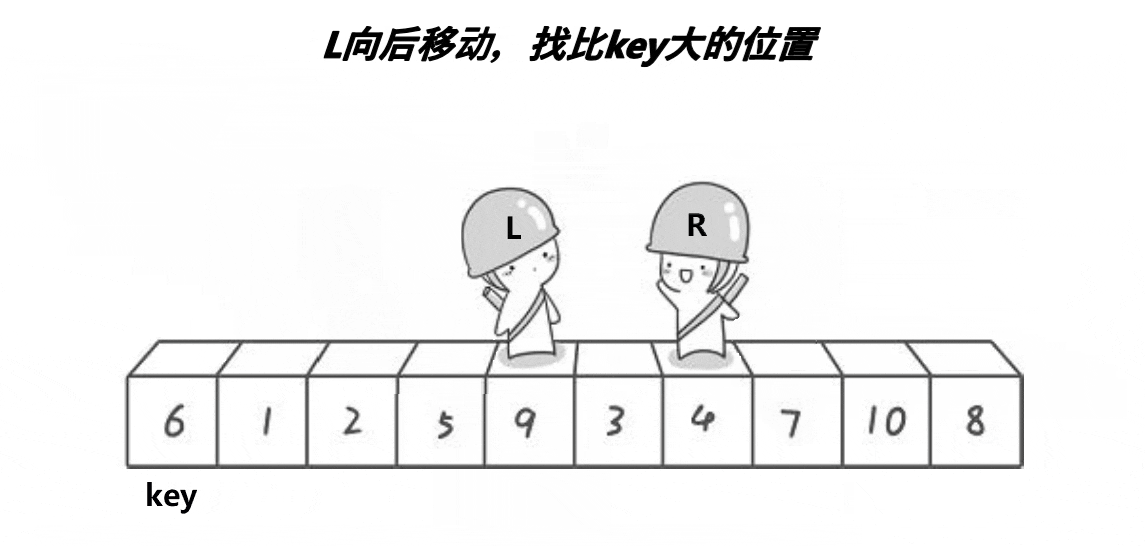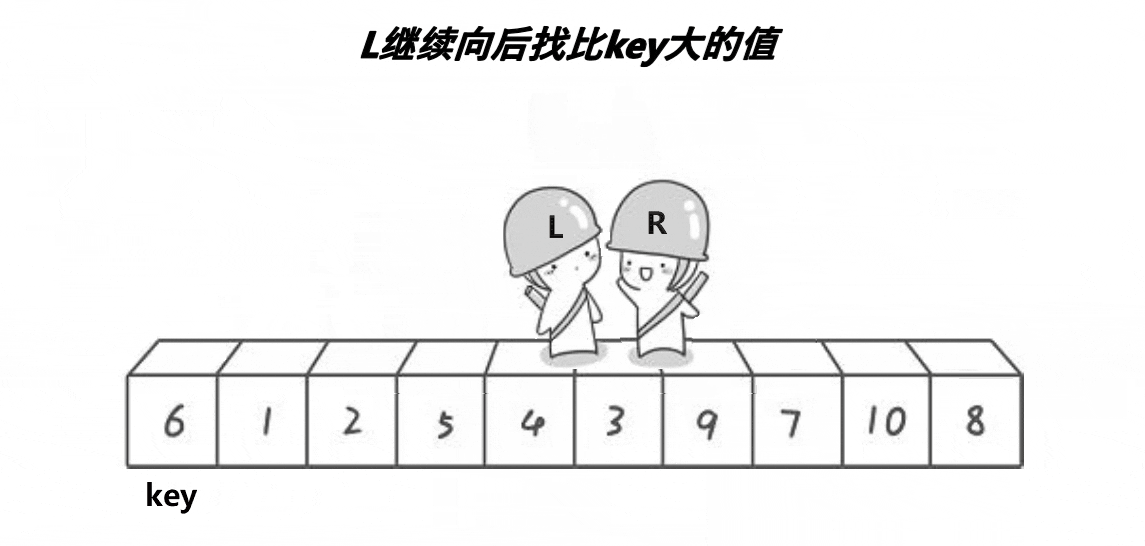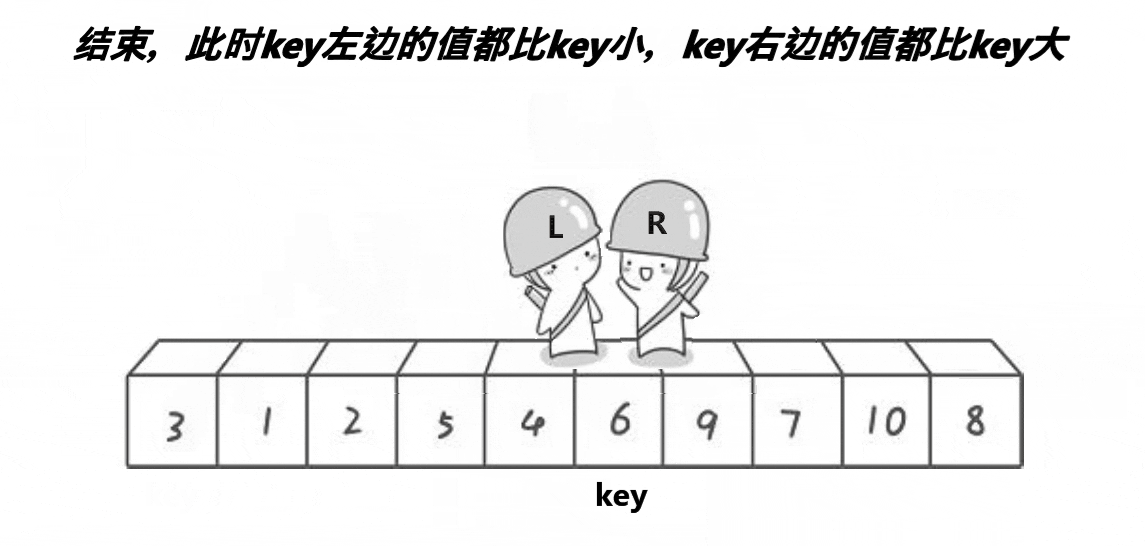
我们先看一下动图,方便理解
巧妙之处:
- 左边做key,右边先走;保障了相遇位置的值比key小,或者就是key的位置
- 右边做key,左边先走;保障了相遇位置的值比key大,或者就是key的位置
我们这里使用第一种方法:
L和R相遇无非就是两种情况,L遇R和R遇L:
- 情况一:L遇R,R是停下来,L在走,R先走,R停下来的位置一定比key小,相遇的位置就是R停下的位置,就一定比key要小
- 情况二:R遇L,在相遇这一轮,L就没动,R在移动,跟L相遇,相遇位置就是L的位置,L的位置就是key的位置或者这个位置交换过,换成了比key小的,相遇L位置一定比key小
代码实现:
int PartSort1(int* a, int left, int right)
{int keyi = left;while (left < right){//右边找小 与key相等的数据放在左边右边都可以while (left < right && a[right] >= a[keyi]){right--;}//左边找大 与key相等的数据放在左边右边都可以while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[right]);return right;
}2. 挖坑法
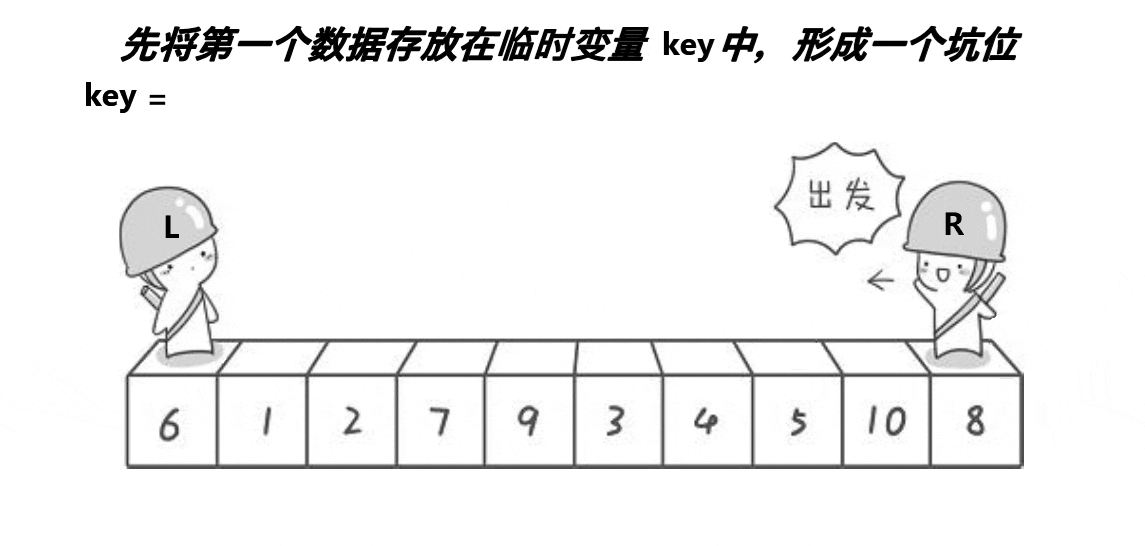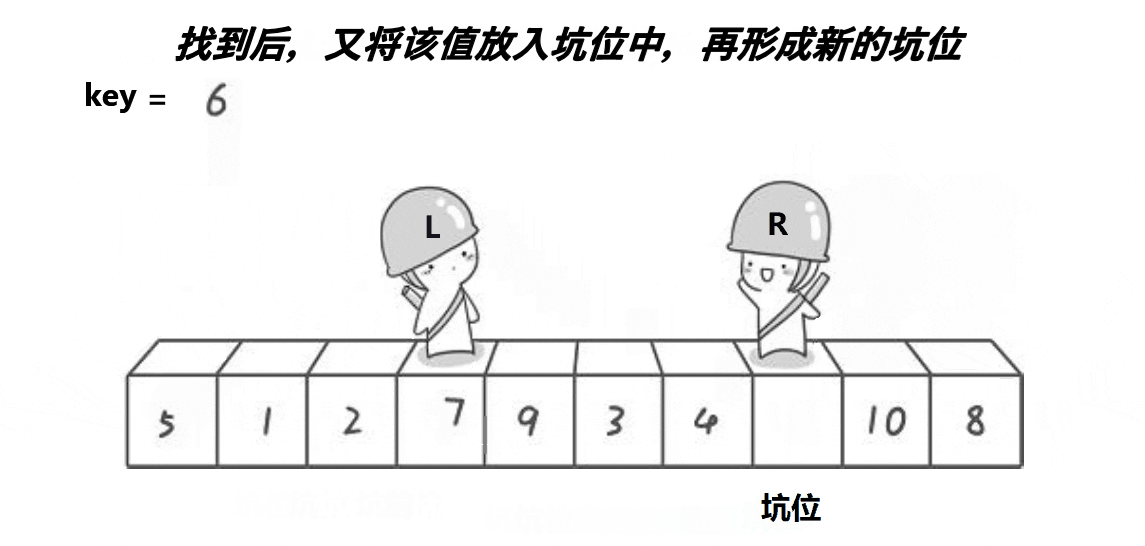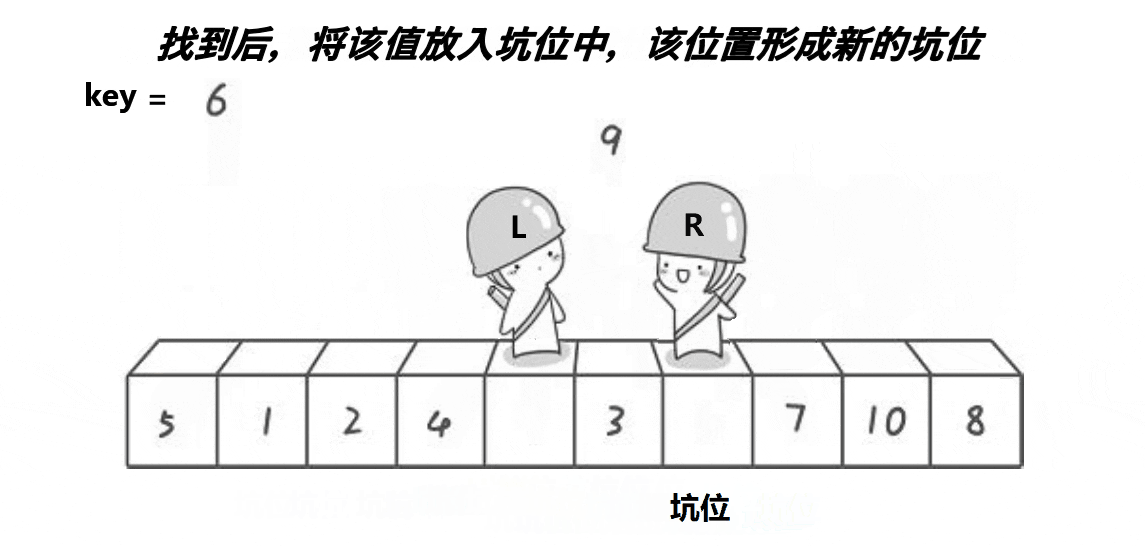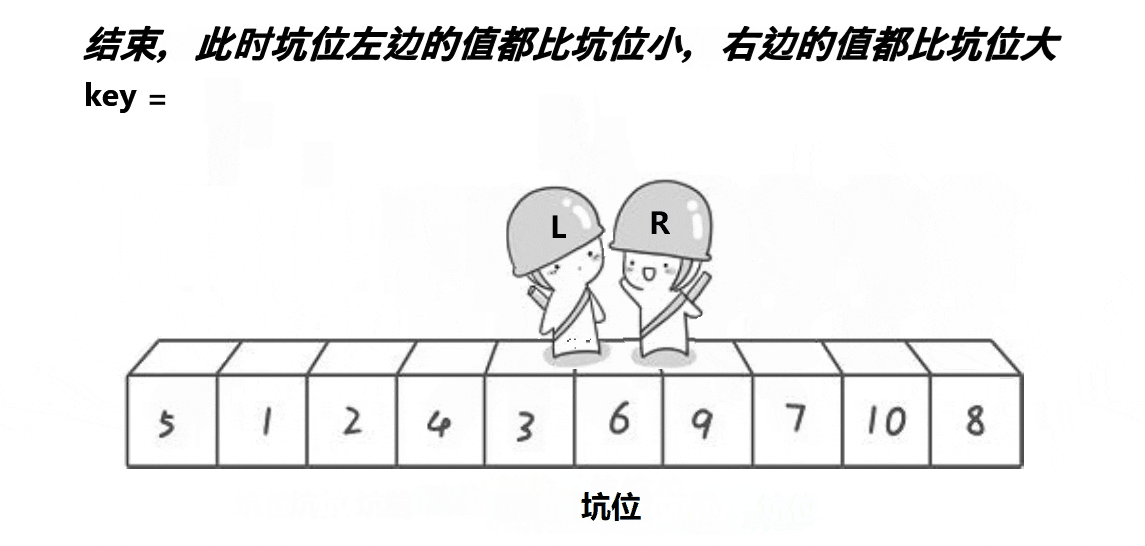
left 和 right 中有一个一定是坑位,右边找小,左边找大,找到就将值放入原坑位,该位置成为新坑位。
代码实现:
int PartSort2(int* a, int left, int right)
{int hole = left;int key = a[left];while (left < right){//右边找小while (left < right && a[right] >= key){right--;}a[hole] = a[right];hole = right;//左边找大while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}3. 前后指针版本
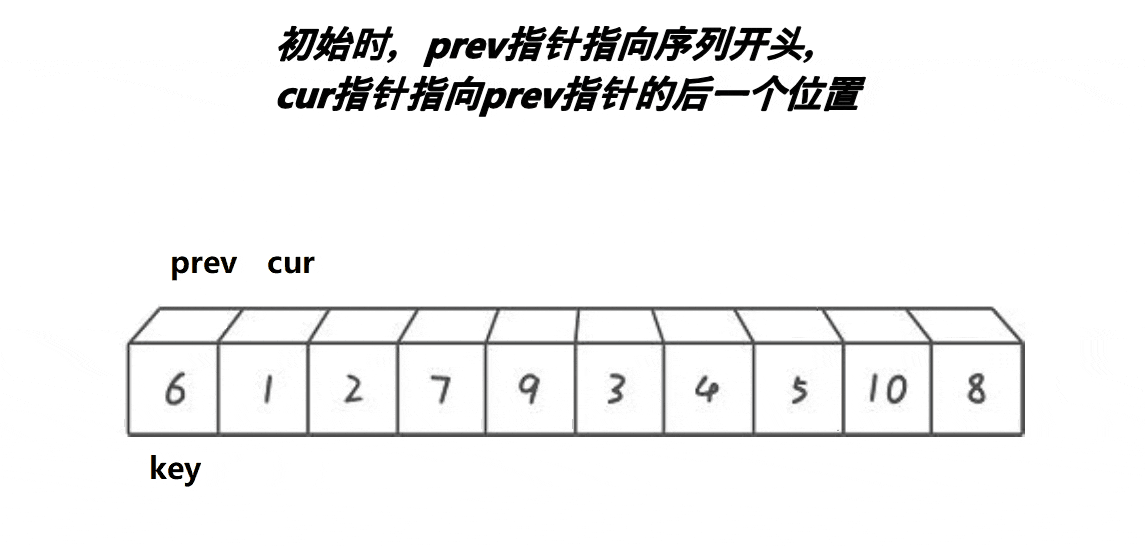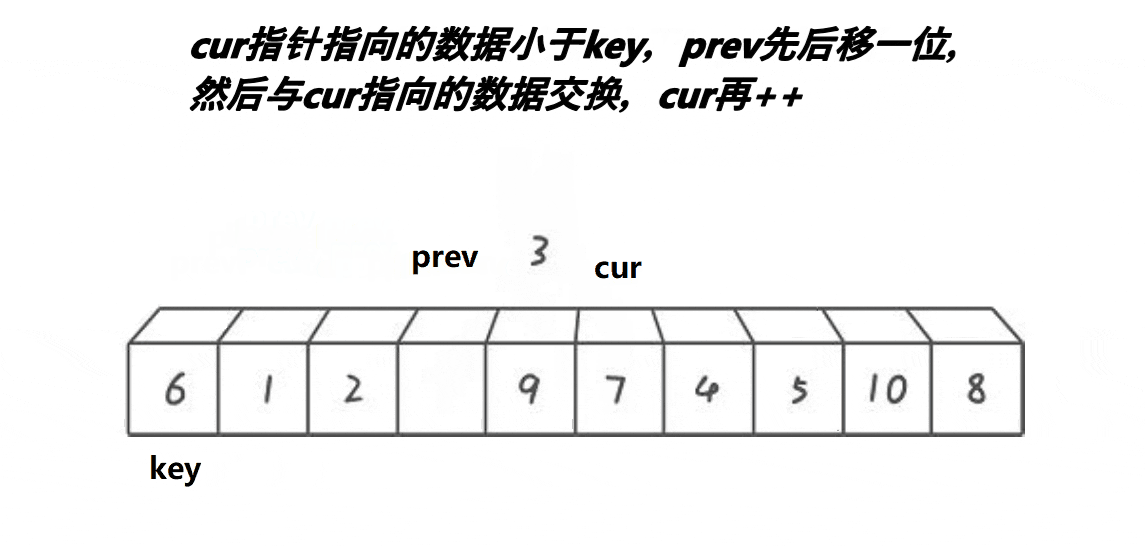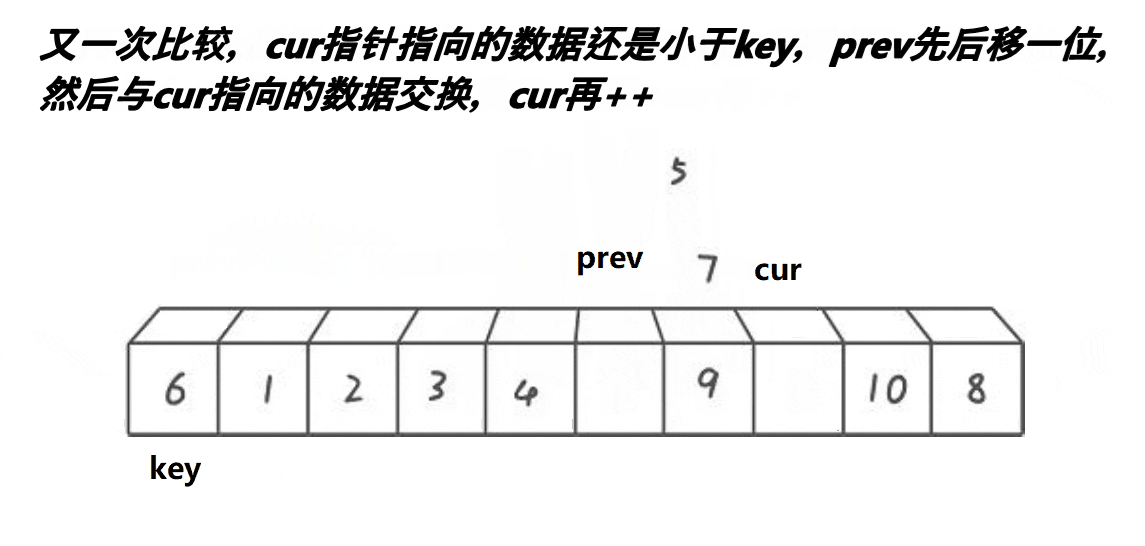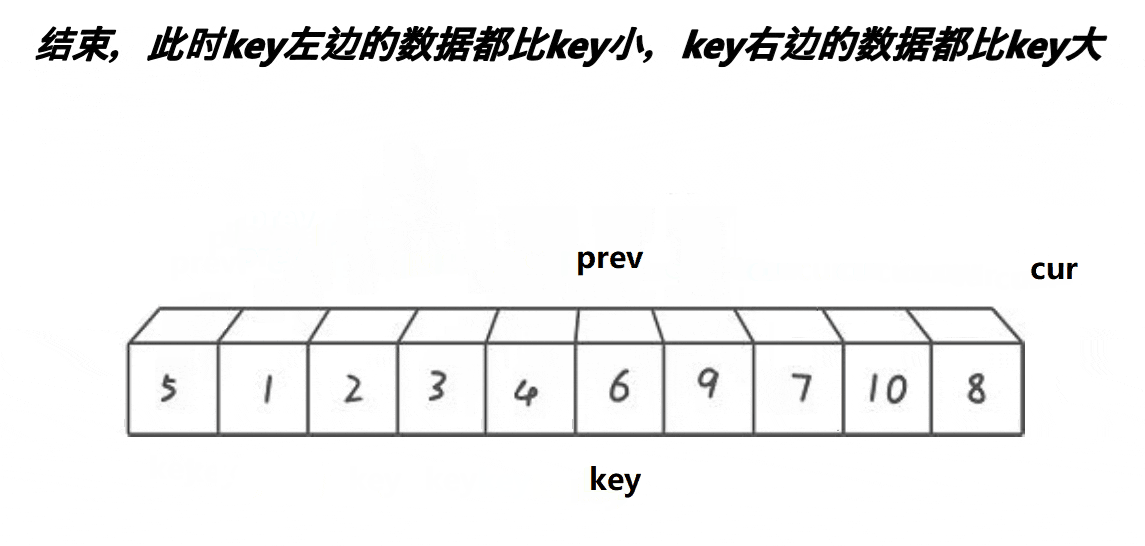
- 最开始prev和cur相邻的
- 当cur遇到比key的大的值以后,他们之间的值都是比key大的值
- cur找小,找到小的以后,跟++prev位置的值交换,相当于把大翻滚式往右边推同时把小的换到左边
代码实现:
int PartSort3(int* a, int left, int right)
{int keyi = left;int prev = left;int cur = left + 1;while (cur <= right){if (a[cur] <= a[keyi]&&++prev!=cur)//自己不与自己交换{Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[prev], &a[keyi]);return prev;
}2.2 快速排序优化
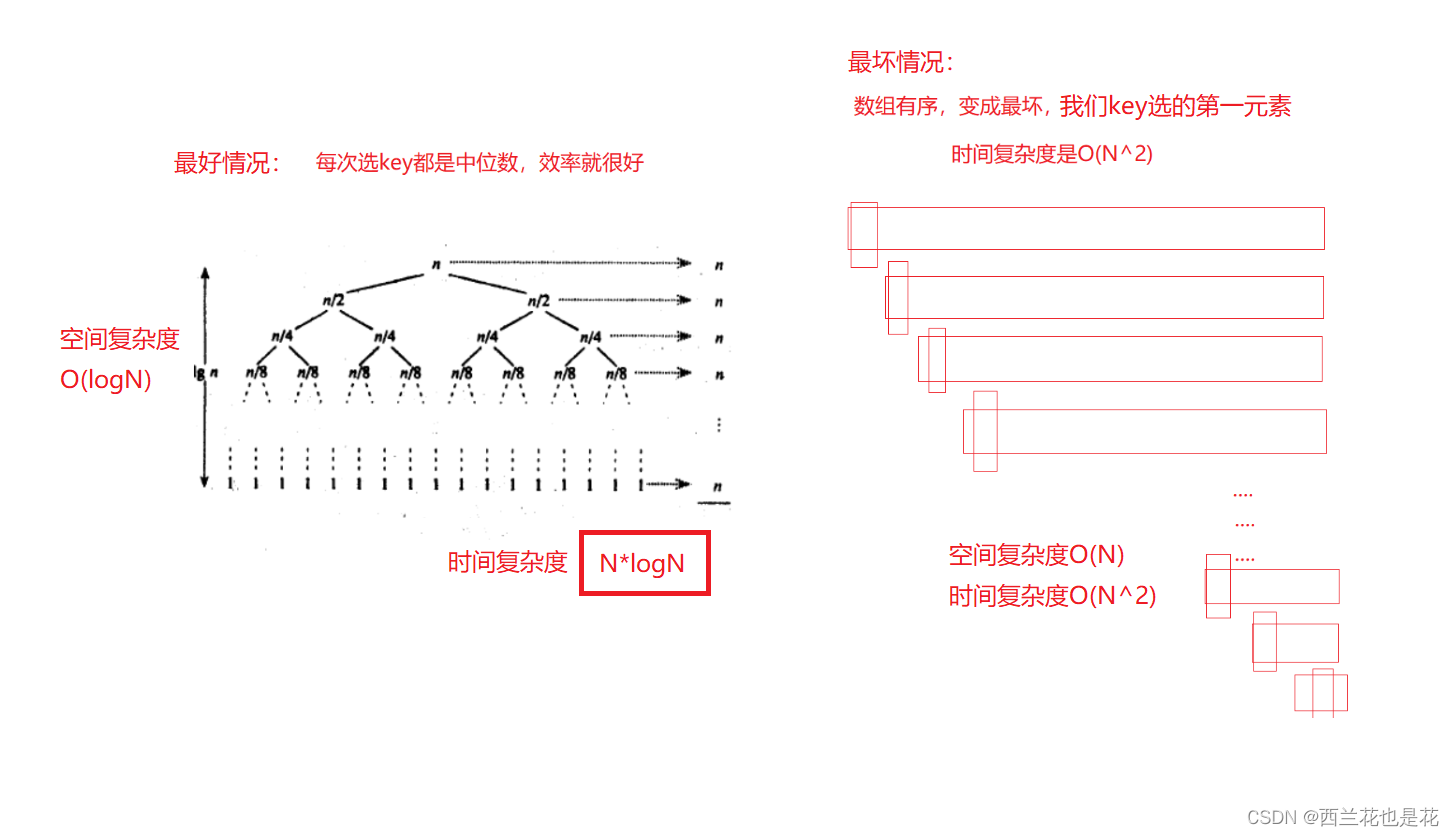
当我们遇到有序数据时,由于我们的key是选的第一个元素,时间复杂度会变成O(N^2)。有两种优化方法:
- 三数取中法选key
- 随机数选key
- 小区间优化
三数取中,代码实现:
int GetMidIndex(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if(a[left]>a[right]){return left;}else{return right;}}else//a[left]>a[mid]{if (a[mid] > a[right]){return mid;}else if (a[left] > a[right]){return right;}else{return left;}}
}
然后我们需要在上面3种划分方式开头都加上下面代码,就可以达到优化的目的。
int midi = GetMidIndex(a, left, right);
Swap(&a[midi], &a[left]);2. 随机数选key
int GetRandIndex(int* arr, int left, int right)
{int i = rand()%(right-left+1)+left;return i;
}当然我们也需要使用 srand((unsigned int)time(NULL)) 随机数种子。
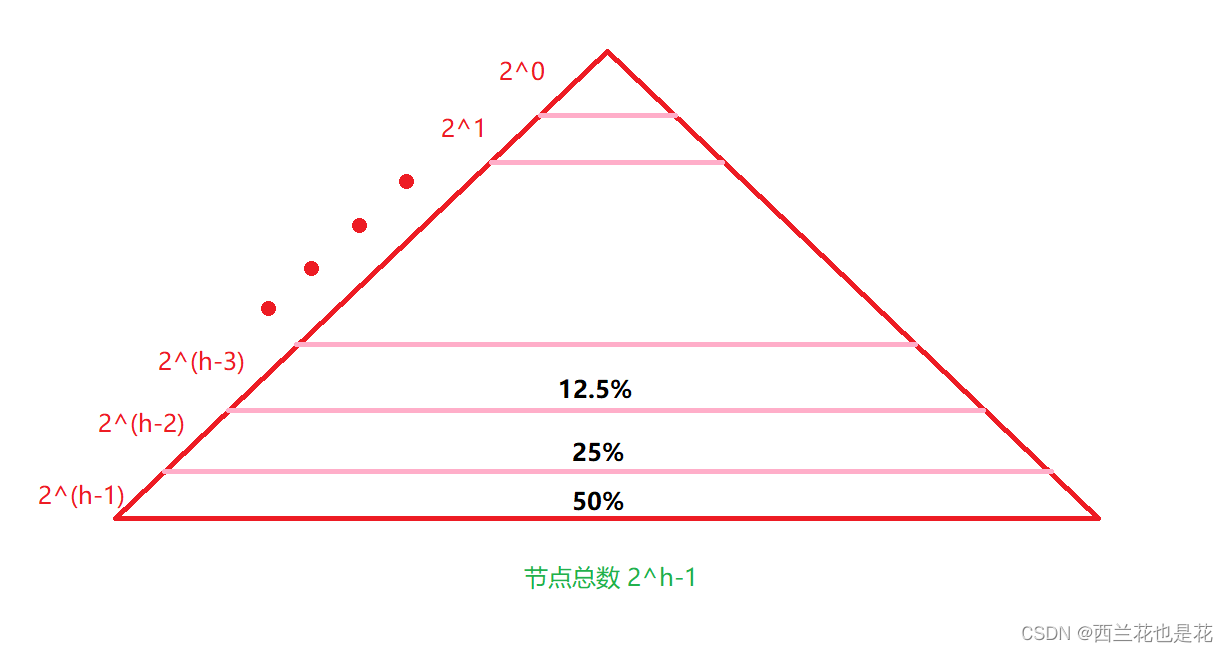
3.小区间优化
//小区间优化
if (end - begin +1<10)
{//使用插入排序InsertSort(arr + begin, end - begin + 1);return;
}优化的本质是减小递归调用的次数,由于二叉树的性质。我们可以得出满二叉树后三层大约占总个数的85%。为了减小递归开销,我们可以将小区间的递归调用改为直接插入排序,可以提高一点排序的性能,但也不会提高很多。
2.3 非递归实现
我们这里使用栈来实现,栈内存放需要划分的区间端点值,利用栈先入后出的特点模拟实现递归
void QuickSortNonR(int* a, int left, int right)
{Stack st;StackInit(&st);//入栈StackPush(&st, right);StackPush(&st, left);while (!StackEmpty(&st)){left = StackTop(&st);StackPop(&st);right = StackTop(&st);StackPop(&st);int keyi = PartSort1(a, left, right);//想先处理左边,就先右边区间先入栈//以基准值为分割点,形成左右两部分:[left, keyi-1]和[keyi+1,right)if(right > keyi + 1){StackPush(&st, right);StackPush(&st, keyi + 1);}if (left < keyi - 1){StackPush(&st, keyi - 1);StackPush(&st, left);}}StackDestroy(&st);
}当然也可以使用队列来模拟。队列相当于广度优先,二叉树中的层序遍历,栈是深度优先,二叉树的先序遍历。
快速排序的特性总结:
- 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
- 时间复杂度:O(N*logN)
- 空间复杂度:O(logN)
- 稳定性:不稳定
2.4 存在大量相同元素情况
当要排序的数组存在大量相同元素时,快排的时间复杂度会下降到O(N^2)。
三路划分:
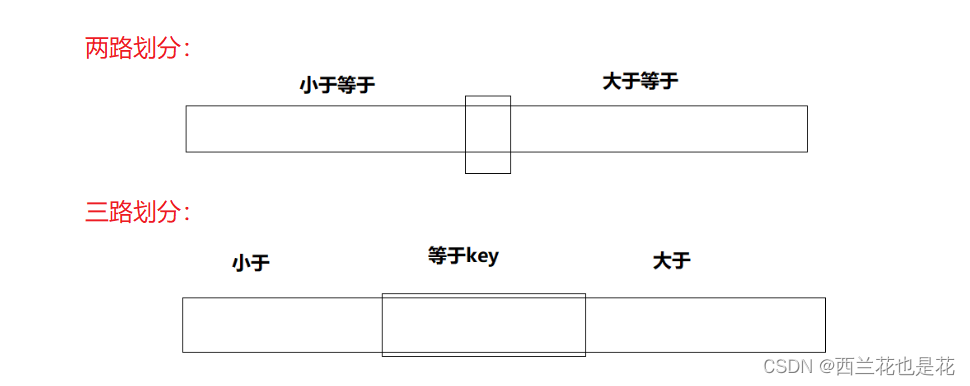

步骤:
- a[c] < key,交换c和l位置的值,++l,++c
- a[c] > key,交换c和r位置的值,--r
- a[c] == key,++cu
三路划分本质:
- 小的甩到左边,大的甩到右边
- 跟key相等的值推到中间
- l 一直指向第一个与key相等的数据
代码实现:
int RandIndex(int begin, int end)
{int i = rand() % (end - begin + 1) + begin;return i;
}void QuickSortThree(int* arr, int begin, int end)
{//1.区间只有一个值//2.区间不存在if (begin >= end){return;}//三路划分 效率有一定的下降int left = begin;int cur = begin + 1;int right = end;int Index = RandIndex(begin, end);Swap(&arr[Index], &arr[left]);int key = arr[left];while (cur <= right){if (arr[cur] < key){Swap(&arr[cur++], &arr[left++]);}else if (arr[cur] == key){cur++;}else if (arr[cur] > key){Swap(&arr[cur], &arr[right--]);}}QuickSortThree(arr, begin, left - 1);QuickSortThree(arr, cur, end);}
注意:三路划分效率相对于二路划分有一定的下降。
本篇结束!我们下一篇文章来学习排序第四课【归并排序】。