👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——从编码器-解码器架构到seq2seq(机器翻译)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
在理解了seq2seq以后,开始用它来实现一个机器翻译的模型。我们先要进行机器翻译的数据集的选择以及处理,在之后将正式使用seq2seq来进行训练。
seq2seq实现机器翻译
- 机器翻译与数据集
- 下载和预处理数据集
- 词元化
- 词表
- 加载数据集
- 训练模型
机器翻译与数据集
语言模型是自然语言处理的关键,而机器翻译是语言模型最成功的基准测试。因为机器翻译正是将输入序列转换成输出序列的序列转换模型的核心问题。
机器翻译指的是将序列从一种语言自动翻译成另一种语言。我们这里的关注点是神经网络机器翻译方法,强调的是端到端的学习。机器翻译的数据集是由源语言和目标语言的文本序列对组成的。我们需要将预处理后的数据加载到小批量中用于训练。
import os
import torch
from d2l import torch as d2l
下载和预处理数据集
下载一个“英-法”数据集,数据集中每一行都是都是制表符分隔的文本序列对,序列对由英文文本序列和翻译后的法语文本序列组成(每个文本序列可以是一个句子, 也可以是包含多个句子的一个段落)。在这个将英语翻译成法语的机器翻译问题中, 英语是源语言,法语是目标语言。
#@save
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip','94646ad1522d915e7b0f9296181140edcf86a4f5')#@save
def read_data_nmt():"""载入“英语-法语”数据集"""data_dir = d2l.download_extract('fra-eng')with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:return f.read()raw_text = read_data_nmt()
我们可以打印查看一下:
print(raw_text[:75])
输出结果:
Go. Va !
Hi. Salut !
Run! Cours !
Run! Courez !
Who? Qui ?
Wow! Ça alors !
下载数据集后,原始文本数据需要经过几个预处理步骤。例如,我们用空格代替不间断空格,使用小写字母替换大写字母,并在单词和标点符号之间插入空格。
#@save
def preprocess_nmt(text):"""预处理“英语-法语”数据集"""def no_space(char, prev_char):return char in set(',.!?') and prev_char != ' '# 使用空格替换不间断空格# 使用小写字母替换大写字母text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()# 在单词和标点符号之间插入空格out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else charfor i, char in enumerate(text)]return ''.join(out)text = preprocess_nmt(raw_text)
可以输出查看:
print(text[:80])
运行结果:
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ça alors !
词元化
在机器翻译中,我们更喜欢单词级词元化。下面的tokenize_nmt函数对前num_examples个文本序列对进行词元,其中每个词元要么是一个词,要么是一个标点符号。
此数返回两个词元列表:source和target,source[i]是源语言(也就是这里的英语)第i个文本序列的词元列表,target[i]是目标语言(这里是法语)第i个文本序列的词元列表。
#@save
def tokenize_nmt(text, num_examples=None):"""词元化“英语-法语”数据数据集"""source, target = [], []for i, line in enumerate(text.split('\n')):if num_examples and i > num_examples:breakparts = line.split('\t')if len(parts) == 2:source.append(parts[0].split(' '))target.append(parts[1].split(' '))return source, targetsource, target = tokenize_nmt(text)
可以输出查看验证:
print(source[:6], target[:6])
运行结果:
[[‘go’, ‘.’], [‘hi’, ‘.’], [‘run’, ‘!’], [‘run’, ‘!’], [‘who’, ‘?’], [‘wow’, ‘!’]]
[[‘va’, ‘!’], [‘salut’, ‘!’], [‘cours’, ‘!’], [‘courez’, ‘!’], [‘qui’, ‘?’], [‘ça’, ‘alors’, ‘!’]]
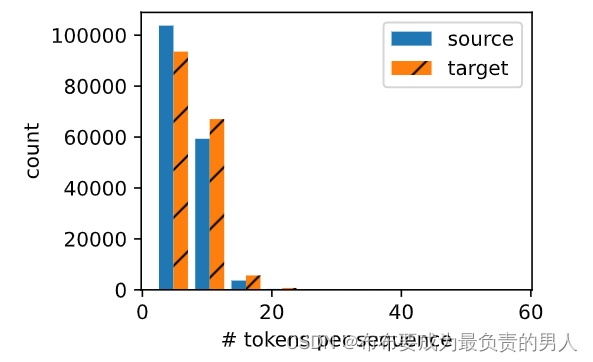
我们可以绘制每个文本序列所包含的词元数量的直方图,在这个数据集中,大多数文本序列的词元数量少于20个。
#@save
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):"""绘制列表长度对的直方图"""d2l.set_figsize()_, _, patches = d2l.plt.hist([[len(l) for l in xlist], [len(l) for l in ylist]])d2l.plt.xlabel(xlabel)d2l.plt.ylabel(ylabel)for patch in patches[1].patches:patch.set_hatch('/')d2l.plt.legend(legend)show_list_len_pair_hist(['source', 'target'], '# tokens per sequence','count', source, target)
d2l.plt.show()
词表
由于机器翻译数据集由语言对组成,因此我们可以分别为源语言和目标语言构建两个词表。
使用单词级词元化时,词表大小将明显大于使用字符级词元化时的词表大小。为了缓解这一问题,我们做一个处理方法,将一些低频率的词元视为相同的未知词元unk,在这里我们将出现次数少于2次视为低频率词元。
此外,我们还指定了额外的特定词元,例如在小批量时用于将序列填充到相同长度的填充词元pad,以及序列的开始词元bos和结束词元eos。
例如:
src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])
print(len(src_vocab))
输出结果:
10012
加载数据集
在之前,我们做过语言模型的处理,而语言模型中的序列样本都有一个固定的长度,这个固定长度由num_steps(时间步数或词元数量)来决定的。而在机器翻译中,每个样本都是由源和目标组成的文本序列对,其中的每个文本序列可能具有不同的长度。
为了提高计算效率,我们仍然可以通过截断和填充方式实现一次只处理一个小批量的文本序列。假设同一个小批量中的每个序列都应该具有相同的长度num_steps。那么若词元数目数目少于num_steps,我们就在末位填充pad词元;否则我们就截断词元取前num_steps个。只要每个文本序列具有相同的长度,就方便以相同形状的小批量进行加载。
我们定义一个函数来实现对文本序列的截断或填充。
#@save
def truncate_pad(line, num_steps, padding_token):"""截断或填充文本序列"""if len(line) > num_steps:return line[:num_steps] # 截断return line + [padding_token] * (num_steps - len(line)) # 填充
验证一下:
print(truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>']))
运行结果:
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
可以分析一下这个运行结果,source[0]里面有两个词元,按照词元的出现频率来进行排序,分别是第47和第4,此时我们需要10个词元,那就需要填充,理所当然要填充最常见的那种词,造成的概率是最小的,所以其对应着词表中的都是频率最高的。
如果语料corpus、词表这类概念忘记了,可以看我之前的这篇文章:
机器学习&&深度学习——文本预处理
现在我们定义一个函数,可以将文本序列转换成小批量数据集用于训练。我们将eos词元添加到所有序列的末尾,用于表示序列的结束。当模型通过一个词元接一个词元地生成序列进行预测时,生成的eos词元说明完成了序列的输出工作。此外,我们还记录了每个文本序列的初始长度(排除了填充词元的长度),后序会用到。
#@save
def build_array_nmt(lines, vocab, num_steps):"""将机器翻译的文本序列转换成小批量"""lines = [vocab[l] for l in lines]lines = [l + [vocab['<eos>']] for l in lines]array = torch.tensor([truncate_pad(l, num_steps, vocab['<pad>']) for l in lines])valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1) # 统计原始长度return array, valid_len
训练模型
接下来就可以定义load_data_nmt函数来返回数据迭代器,以及源语言和目标语言的两种词表:
#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):"""返回翻译数据集的迭代器和词表"""text = preprocess_nmt(read_data_nmt())source, target = tokenize_nmt(text, num_examples)src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])tgt_vocab = d2l.Vocab(target, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)data_iter = d2l.load_array(data_arrays, batch_size)return data_iter, src_vocab, tgt_vocab
我们可以读出数据集中的第一个小批量数据:
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:print('X:', X.type(torch.int32))print('X的有效长度:', X_valid_len)print('Y:', Y.type(torch.int32))print('Y的有效长度:', Y_valid_len)break
运行结果:
X: tensor([[ 17, 119, 4, 3, 1, 1, 1, 1],
[ 6, 124, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
X的有效长度: tensor([4, 4])
Y: tensor([[11, 0, 4, 3, 1, 1, 1, 1],
[ 6, 27, 7, 0, 4, 3, 1, 1]], dtype=torch.int32)
Y的有效长度: tensor([4, 6])