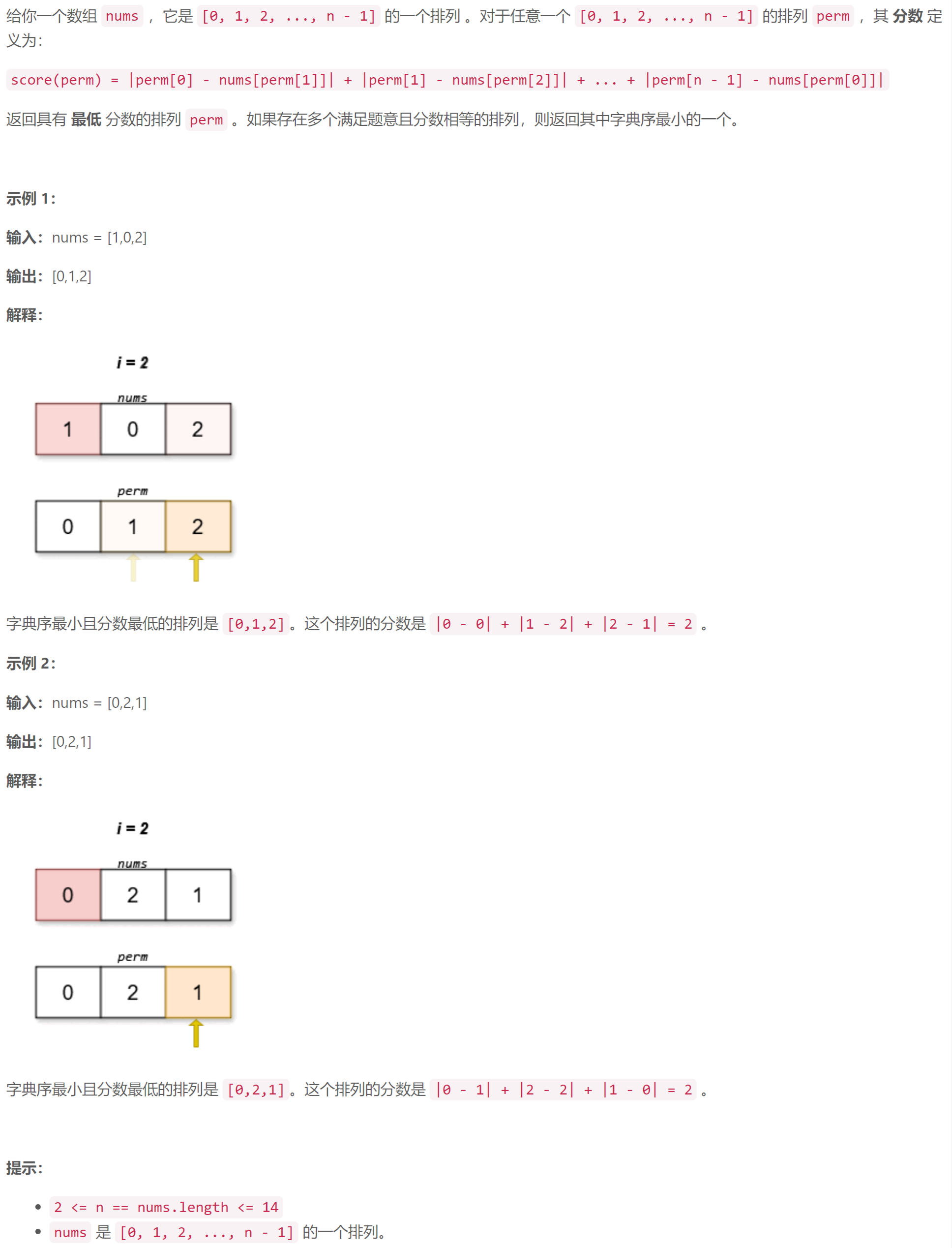
内存屏障(Memory Barrier)是在计算机体系结构中使用的一种同步机制,用于确保在多线程或多核处理器环境中,对共享内存的操作按照预期顺序进行。它们通过强制在特定点执行一些指令来规定内存访问的顺序,并防止内存乱序执行带来的不一致性问题。
内存屏障分为两种类型:读屏障(Read Barrier)和写屏障(Write Barrier)。
读屏障用于确保在读操作之前,所有该读操作之前的写操作已经完成。它可以防止指令乱序执行,保证读取到的数据是最新的。
写屏障用于确保在写操作之前,所有该写操作之前的写操作和读操作都已经完成。它可以防止指令乱序执行,保证写入的数据不会被其他操作覆盖或丢失。
内存屏障的使用能够解决多线程或多核处理器中的原子性、可见性和有序性等问题,确保程序的正确性和一致性。在编写并发程序时,合理地使用内存屏障可以提高程序的性能和正确性。
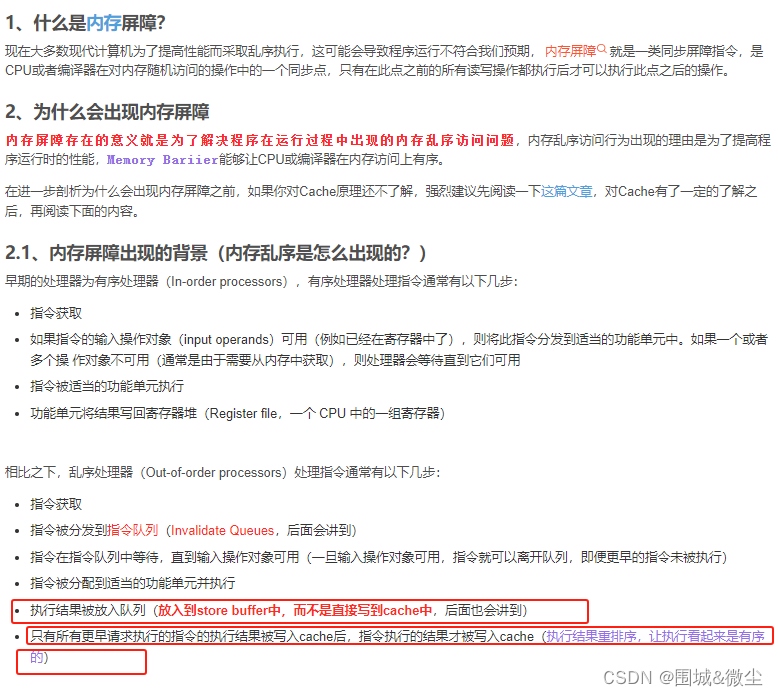



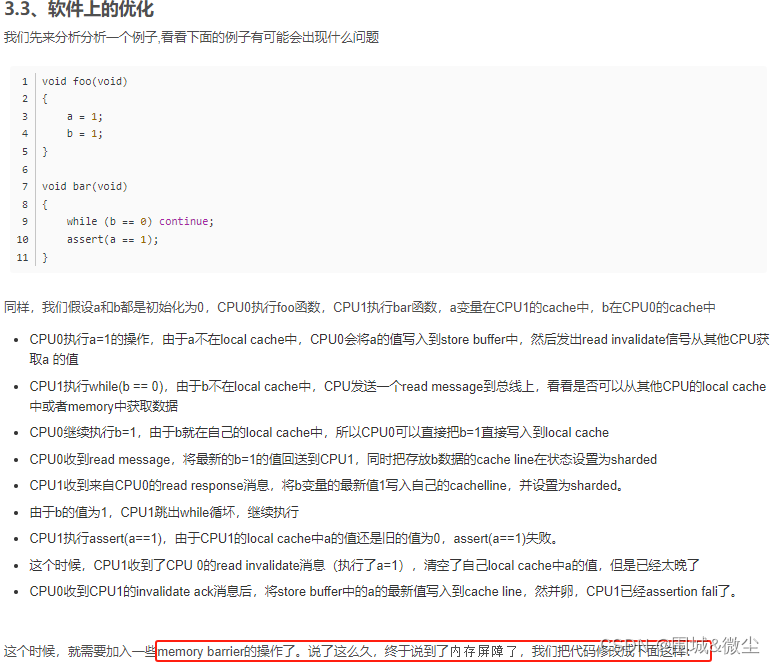
void foo(void)
{a = 1;smp_mb();b = 1;
}void bar(void)
{while (b == 0) continue;assert(a == 1);
}


https://www.kernel.org/doc/Documentation/memory-barriers.txt![]() https://www.kernel.org/doc/Documentation/memory-barriers.txt
https://www.kernel.org/doc/Documentation/memory-barriers.txt

Consider the following abstract model of the system:: :: :: :+-------+ : +--------+ : +-------+| | : | | : | || | : | | : | || CPU 1 |<----->| Memory |<----->| CPU 2 || | : | | : | || | : | | : | |+-------+ : +--------+ : +-------+^ : ^ : ^| : | : || : | : || : v : || : +--------+ : || : | | : || : | | : |+---------->| Device |<----------+: | | :: | | :: +--------+ :: :
(memory barriers logically act on the dotted line in the following diagram):<--- CPU ---> : <----------- Memory ----------->:+--------+ +--------+ : +--------+ +-----------+| | | | : | | | | +--------+| CPU | | Memory | : | CPU | | | | || Core |--->| Access |----->| Cache |<-->| | | || | | Queue | : | | | |--->| Memory || | | | : | | | | | |+--------+ +--------+ : +--------+ | | | |: | Cache | +--------+: | Coherency |: | Mechanism | +--------++--------+ +--------+ : +--------+ | | | || | | | : | | | | | || CPU | | Memory | : | CPU | | |--->| Device || Core |--->| Access |----->| Cache |<-->| | | || | | Queue | : | | | | | || | | | : | | | | +--------++--------+ +--------+ : +--------+ +-----------+::

Cache 一致性问题出现的原因是在一个多处理器系统中,每个处理器核心都有独占的Cache 系统(比如一级 Cache 和二级 Cache),而导致一个内存块在系统中同时可能有多个备份,从而引起访问时的不一致性问题。Cache 一致性问题的根源是因为存在多个处理器独占的 Cache,而不是多个处理器。它的限制条件比较多:多核,独占 Cache,Cache 写策略。当其中任一个条件不满足时便不存在cache一致性问题。 

read: 包含要读取的CACHE-LINE的物理地址
read response: 包含READ请求的数据,要么由内存满足要么由cache满足
invalidate: 包含要invalidate的cache-line的物理地址,所有其他cache必须移除相应的数据项
invalidate ack: 回复消息
read invalidate: 包含要读取的cache-line的物理地址,同时使其他cache移除该数据。需要read response和invalidate ack消息
writeback:包含要写回的数据和地址,该状态将处于modified状态的lines写回内存,为其他数据腾出空间



void foo(void)
{a = 1;smp_mb();b = 1;
}smp_mb()指令可以迫使CPU在进行后续store操作前刷新store-buffer。以上面的程序为例,增加memory barrier之后,就可以保证在执行b=1的时候CPU0-store-buffer中的a已经刷新到cache中了,此时CPU1-cache中的a 必然已经标记为invalid。对于CPU1中执行的代码,则可以保证当b==0为假时,a已经不在CPU1-cache中,从而必须从CPU0- cache传递,得到新值“1”




![[windows系统安装/重装系统][step-3]装驱动、打驱动、系统激活](https://img-blog.csdnimg.cn/img_convert/4b9f1a763c56496a25fe50437f2a5da3.png)