一、问题
链表分为单向链表、双向链表和循环链表,它们的不同之处是什么呢?
二、解答
(1)单向链表。
所谓单向链表,就是指数据结点是单向排列的。⼀个单向链表结点由两个域组成,存储在结构体类型中。⼀个域⽤于存放数据元素 data,其数据类型由应⽤问题决定,称为数据域;
另⼀个域存放⼀个指向该链表中下⼀个结点的指针 link ,指向下 ⼀个结点的开始存储地址,称为链域或者指针域。
例如,可以写成这样⼀个结构体类型。
struct NODE
{int number;char name[20];struct student *next;
};其中 number 和 name[20] ⽤来存放数据域中的数据信息;指针*next ⽤来存储下⼀个结点的指针,就是指针域部分。
图下为⼀个简单的单向链表。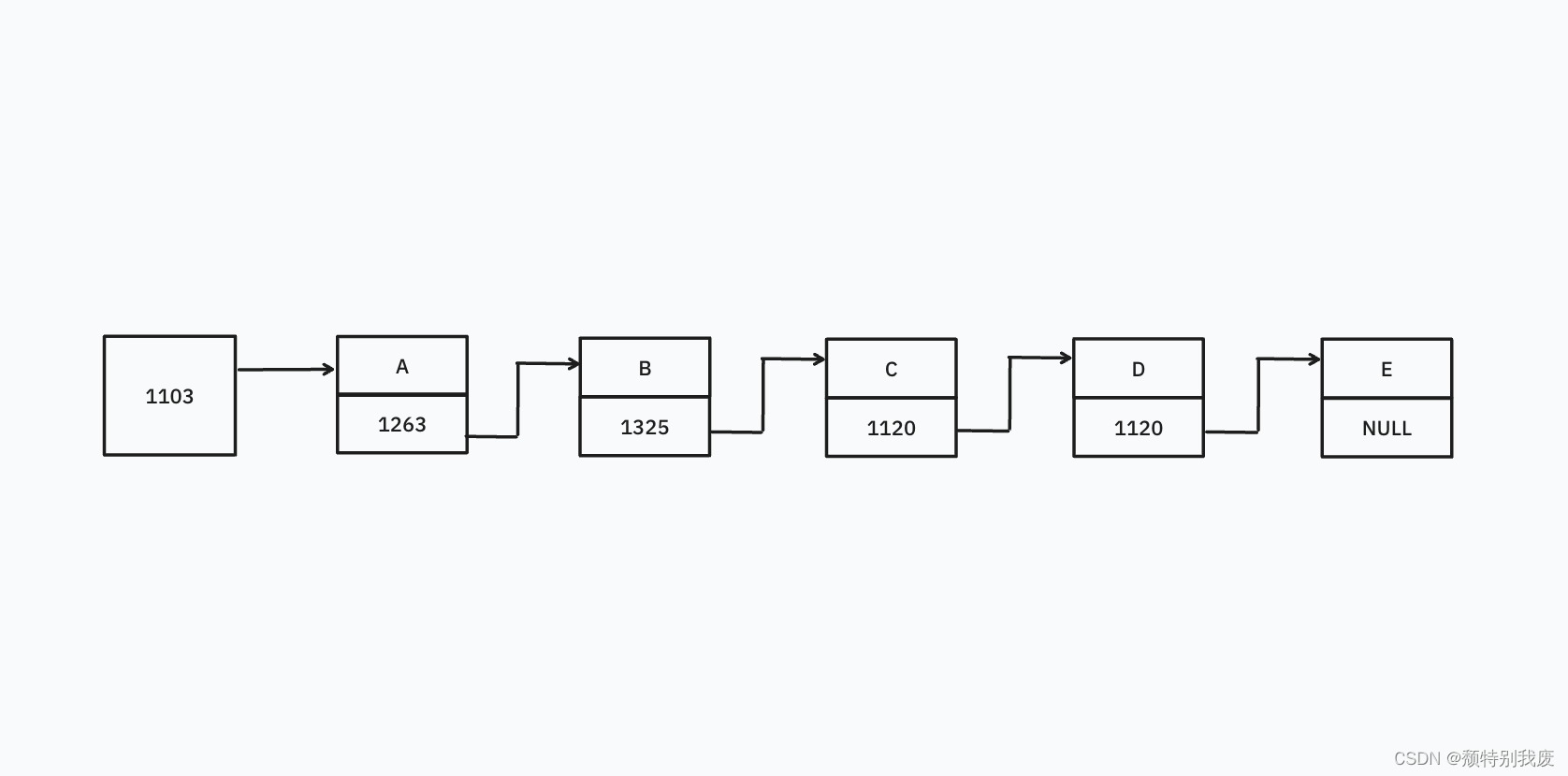
单向链表有⼀个头结点,在图12.8 中以 head 表示,它存放头结点的地址,没有数据,只是⼀个指针变量,又叫做“头指针”。
链表中的其余结点都有两个部分,即数据域和指针域。在 struct NODE 结构体中,number 和 name[20]的数据信息都存储在数据域中,相当于图中的 A、 B、 C、 D、E。next 是指针类型的成员,它指向 struct NODE 类型数据。 ⽤这种⾃⼰指向⾃⼰的数据类型的⽅法,就可以建⽴链表。链表的尾结点的 next 指针指向NULL。
(2)双向链表。
当对单向链表进⾏操作时,若需要对某个结点的直接前驱进⾏操作, 就必须从链表头开始查找。因为单向链表的指针域是指向直接后继的结点,因此就出现了 既能存储直接后继结点地址的链域,又能存储直接前驱结点地址的链域,这就是⼀个双向链表。
在双向链表中,结点除含有数据域外,还有两个指针域。⼀个存储直接后继结点的地址,称为右链域:另⼀个存储直接前驱结点的地址,称为左链域。
(3)循环链表。
循环链表与单向链表⼀样,都含有⼀个数据域和⼀个指向直接后继结点的指针域。唯⼀不同的是,循环链表没有尾结点。循环链表的最后⼀个结点的指针指向该循环链表的第⼀个结点,或者表头结点,从⽽构成⼀个环形的链。在建⽴⼀个循环链表时,还可以在最后⼀个结点后插⼊⼀个新的结点。判断循环链表是否到结尾,就是判断该结点链域的值是否为表头结点。当链域值等于表头指针时,说明⼰到结尾。
三、总结
单链表是最简单的⼀种链表。但是,在查找结点时,只能查找后继结点。然⽽,双向链表可以查找前驱结点和后继结点,在循环链表中则可以查找任意位置的结点,因为循环链表是⼀个环形的链表,由任意结点都可以遍历到所有结点。