目录
一、SpringData ElasticSearch
1.1、环境配置
1.2、创建实体类
1.3、ElasticSearchTemplate 的使用
1.3.1、创建索引库,设置映射
1.3.2、创建索引映射注意事项
1.3.3、简单的 CRUD
1.3.4、三种构建搜索条件的方式
1.3.5、NativeQuery 搜索实战
1.3.6、completionSuggestion 自动补全
一、SpringData ElasticSearch
1.1、环境配置
a)依赖如下:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><!--SpringBoot3 之后测试必须引入这个包--><dependency><groupId>org.mockito</groupId><artifactId>mockito-core</artifactId><version>2.23.4</version><scope>test</scope></dependency>
b)配置文件如下:
spring:application:name: eselasticsearch:uris: env-base:9200
1.2、创建实体类
a)简单结构如下(后续示例,围绕此结构展开):
import org.springframework.data.annotation.Id
import org.springframework.data.elasticsearch.annotations.Document
import org.springframework.data.elasticsearch.annotations.Field
import org.springframework.data.elasticsearch.annotations.FieldType@Document(indexName = "album_info", )
data class AlbumInfoDo (/*** @Id: 表示文档中的主键,并且会在保存在 ElasticSearch 数据结构中 {"id": "", "userId": "", "title": ""}*/@Id@Field(type = FieldType.Keyword)val id: Long? = null,/*** @Field: 描述 Java 类型中的属性映射* - name: 对应 ES 索引中的字段名. 默认和属性同名* - type: 对应字段类型,默认是 FieldType.Auto (会根据我们数据类型自动进行定义),但是建议主动定义,避免导致错误映射* - index: 是否创建索引. text 类型创建倒排索引,其他类型创建正排索引. 默认是 true* - analyzer: 分词器名称. 中文我们一般都使用 ik 分词器(ik分词器有 ik_smart 和 ik_max_word)*/@Field(name = "user_id", type = FieldType.Long)val userId: Long,@Field(type = FieldType.Text, analyzer = "ik_max_word")var title: String,@Field(type = FieldType.Text, analyzer = "ik_smart")var content: String,
)
b)复杂嵌套结构如下:
import org.springframework.data.annotation.Id
import org.springframework.data.elasticsearch.annotations.Document
import org.springframework.data.elasticsearch.annotations.Field
import org.springframework.data.elasticsearch.annotations.FieldType@Document(indexName = "album_list")
data class AlbumListDo(@Id@Field(type = FieldType.Keyword)var id: Long,@Field(type = FieldType.Nested) // 表示一个嵌套结构var userinfo: UserInfoSimp,@Field(type = FieldType.Text, analyzer = "ik_max_word")var title: String,@Field(type = FieldType.Text, analyzer = "ik_smart")var content: String,@Field(type = FieldType.Nested) // 表示一个嵌套结构var photos: List<AlbumPhotoSimp>,
)data class UserInfoSimp(@Field(type = FieldType.Long)val userId: Long,@Field(type = FieldType.Text, analyzer = "ik_max_word")val username: String,@Field(type = FieldType.Keyword, index = false)val avatar: String,
)data class AlbumPhotoSimp(@Field(type = FieldType.Integer, index = false)val sort: Int,@Field(type = FieldType.Keyword, index = false)val photo: String,
)
对于一个小型系统来说,一般也不会创建这种复杂程度的文档,因为会涉及到很多一致性问题, 需要通过大量的 mq 进行同步,给系统带来一定的开销.
因此,一般会将需要进行模糊查询的字段存 Document 中(es 就擅长这个),而其他数据则可以在 Document 中以 id 的形式进行存储. 这样就既可以借助 es 高效的模糊查询能力,也能减少为保证一致性而带来的系统开销. 从 es 中查到数据后,再通过其他表的 id 从数据库中拿数据即可(这点开销,相对于从大量数据的数据库中进行 like 查询,几乎可以忽略).
1.3、ElasticSearchTemplate 的使用
1.3.1、创建索引库,设置映射
@SpringBootTest
class ElasticSearchIndexTests {@Resourceprivate lateinit var elasticsearchTemplate: ElasticsearchTemplate@Testfun test1() {//存在索引库就删除if (elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).exists()) {elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).delete()}//创建索引库elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).create()//设置映射elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).putMapping(elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).createMapping())}}
效果如下:
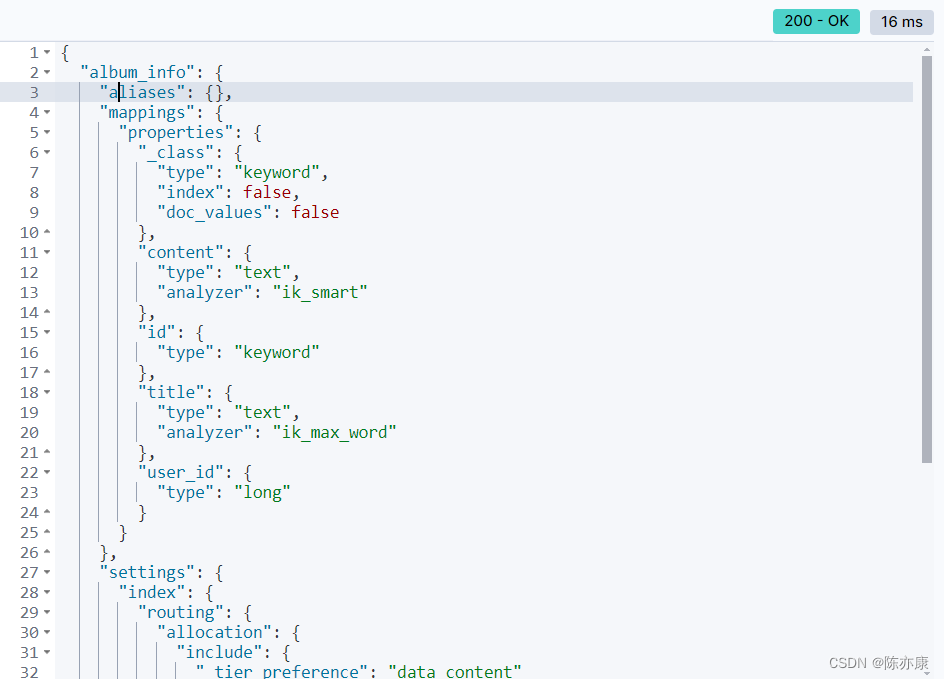
1.3.2、创建索引映射注意事项
a)在没有创建索引库和映射的情况下,也可以直接向 es 库中插入数据,如下代码:
@Testfun test2() {val obj = AlbumListDo(id = 1,userinfo = UserInfoSimp(userId = 1,username = "cyk",avatar = "env-base:9200"),title = "今天天气真好",content = "早上起来,我要好好学习,然去公园散步~",photos = listOf(AlbumPhotoSimp(1, "www.photo.com/aaa"),AlbumPhotoSimp(2, "www.photo.com/bbb")))val result = elasticsearchTemplate.save(obj)println(result)}
即使上述代码中 AlbumListDo 中有各种注解标记,但是不会生效!!! es 会根据插入的数据,自动转化数据结构(无视你的注解).
因此,建议先创建索引库和映射,再进行数据插入!
1.3.3、简单的 CRUD
import jakarta.annotation.Resource
import org.cyk.es.model.AlbumInfoDo
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
import org.springframework.data.elasticsearch.client.elc.ElasticsearchTemplate
import org.springframework.data.elasticsearch.core.document.Document
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates
import org.springframework.data.elasticsearch.core.query.UpdateQuery@SpringBootTest
class ElasticSearchCRUDTests {@Resourceprivate lateinit var elasticsearchTemplate: ElasticsearchTemplate@Testfun testSave() {//保存单条数据val a1 = AlbumInfoDo(id = 1,userId = 10000,title = "今天天气真好",content = "学习完之后,我要出去好好玩")val result = elasticsearchTemplate.save(a1)println(result)//保存多条数据val list = listOf(AlbumInfoDo(2, 10000, "西安六号线避雷", "前俯后仰。他就一直在那前后动。他背后是我朋友,我让他不要挤了,他直接就急了,开始故意很大力的挤来挤去。"),AlbumInfoDo(3, 10000, "字节跳动快上车~", "#内推 #字节跳动内推 #互联网"),AlbumInfoDo(4, 10000, "连王思聪也变得低调老实了", "如今的王思聪,不仅交女友的质量下降,在网上也不再像以前那样随意喷这喷那。显然,资金的紧张让他低调了许多"))val resultList = elasticsearchTemplate.save(list)resultList.forEach(::println)}@Testfun testDelete() {//根据主键删除,例如删除主键 id = 1 的文档elasticsearchTemplate.delete("1", AlbumInfoDo::class.java)}@Testfun testGet() {//根据主键获取文档val result = elasticsearchTemplate.get("1", AlbumInfoDo::class.java)println(result)}@Testfun testUpdate() {//例如,修改 id = 1 的文档val id = 1val title = "今天天气不太好"val content = "天气不好,只能在家里学习了。。。"val uq = UpdateQuery.builder(id.toString()).withDocument(Document.create().append("title", title).append("content", content)).build()val result = elasticsearchTemplate.update(uq, IndexCoordinates.of("album_info")).resultprintln(result.ordinal)println(result.name)}}
1.3.4、三种构建搜索条件的方式
关于搜索条件的构建,Spring 官网上给出了三种构建方式:Elasticsearch Operations :: Spring Data Elasticsearch
a)CriteriaQuery:允许创建查询来搜索数据,而不需要了解 Elasticsearch 查询的语法或基础知识。它们允许用户通过简单地链接和组合 Criteria 对象来构建查询,Criteria 对象指定被搜索文档必须满足的条件。
Criteria criteria = new Criteria("lastname").is("Miller") .and("firstname").is("James")
Query query = new CriteriaQuery(criteria);b)StringQuery:这个类接受 Elasticsearch 查询作为 JSON String。下面的代码显示了一个搜索名为“ Jack”的人的查询:
Query query = new StringQuery("{ \"match\": { \"firstname\": { \"query\": \"Jack\" } } } ");
SearchHits<Person> searchHits = operations.search(query, Person.class);c)NativeQuery:当您有一个复杂的查询或者一个无法使用 Criteria API 表示的查询时,例如在构建查询和使用聚合时,可以使用 NativeQuery 类。
d)到底使用哪一种呢?在最新的这一版 SpringDataES 中,NativeQuery 中可以通过大量的 Lambda 来构建条件语句,并且外观上也很符合 ElasticSearch DSL,那么对于比较熟悉原生的 DSL 语句的就建议使用 NativeQuery 啦. 我本人也更倾向 NativeQuery,因此后续的案例都会使用它.
1.3.5、NativeQuery 搜索实战
import co.elastic.clients.elasticsearch._types.SortOrder
import co.elastic.clients.json.JsonData
import jakarta.annotation.Resource
import org.cyk.es.model.AlbumInfoDo
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
import org.springframework.data.domain.PageRequest
import org.springframework.data.elasticsearch.client.elc.ElasticsearchTemplate
import org.springframework.data.elasticsearch.client.elc.NativeQuery
import org.springframework.data.elasticsearch.core.query.HighlightQuery
import org.springframework.data.elasticsearch.core.query.highlight.Highlight
import org.springframework.data.elasticsearch.core.query.highlight.HighlightField
import org.springframework.data.elasticsearch.core.query.highlight.HighlightParameters@SpringBootTest
class SearchTests {@Resourceprivate lateinit var elasticsearchTemplate: ElasticsearchTemplate/*** 全文检索查询(match_all)*/@Testfun testMatchAllQuery() {val query = NativeQuery.builder().withQuery { q -> q.matchAll { it }}.build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 精确查询(match)*/@Testfun testMatchQuery() {val query = NativeQuery.builder().withQuery { q -> q.match {it.field("title").query("天气")}}.build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 精确查询(term)*/@Testfun testTerm() {val query = NativeQuery.builder().withQuery { q -> q.term { t -> t.field("id").value("2")}}.build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 范围搜索*/@Testfun testRangeQuery() {val query = NativeQuery.builder().withQuery { q -> q.range { r -> r.field("id").gte(JsonData.of(1)).lt(JsonData.of(4)) // 大于等于 1,小于 4}}.build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** bool 复合搜索*/@Testfun testBoolQuery() {val query = NativeQuery.builder().withQuery { q -> q.bool { b -> b.must { m -> m.range { r -> r.field("id").gte(JsonData.of(1)).lt(JsonData.of(4)) // 大于等于 1,小于 4}}.mustNot { n -> n.match { mc -> mcmc.field("title").query("天气")}}.should { s -> s.matchAll { it }}}}.build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 排序 + 分页*/@Testfun testSortAndPage() {//a) 方式一
// val query = NativeQuery.builder()
// .withQuery { q -> q
// .matchAll { it }
// }
// .withPageable(
// PageRequest.of(0, 3) //页码(从 0 开始),非偏移量
// .withSort(Sort.by(Sort.Order.desc("id")))
// ).build()//b) 方式二val query = NativeQuery.builder().withQuery { q -> q.matchAll { it }}.withSort { s -> s.field { f->f.field("id").order(SortOrder.Desc) } }.withPageable(PageRequest.of(0, 3)) //页码(从 0 开始),非偏移量).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}@Testfun testHighLight() {//所有需要高亮的字段val highField = listOf(HighlightField("title"),HighlightField("content"))val query = NativeQuery.builder().withQuery { q ->q.multiMatch { ma -> ma.fields("title", "content").query("天气")}}.withHighlightQuery(HighlightQuery(Highlight(HighlightParameters.builder().withPreTags("<span style='color:red'>") //前缀标签.withPostTags("</span>") //后缀标签.withFragmentSize(10) //高亮的片段长度(多少个几个字需要高亮,一般会设置的大一些,让匹配到的字段尽量都高亮).withNumberOfFragments(1) //高亮片段的数量.build(),highField),String::class.java)).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)//hits.content 本身是没有高亮数据的,因此这里需要手动处理hits.forEach {val result = it.content//根据高亮字段名称,获取高亮数据集合val titleList = it.getHighlightField("title")val contentList = it.getHighlightField("content")if (titleList.size > 0) result.title = titleList[0]if (contentList.size > 0) result.content = contentList[0]println(result)}}}
1.3.6、completionSuggestion 自动补全
import org.springframework.data.annotation.Id
import org.springframework.data.elasticsearch.annotations.CompletionField
import org.springframework.data.elasticsearch.annotations.Document
import org.springframework.data.elasticsearch.annotations.Field
import org.springframework.data.elasticsearch.annotations.FieldType
import org.springframework.data.elasticsearch.core.suggest.Completion@Document(indexName = "album_doc")
data class AlbumSugDo (@Id@Field(type = FieldType.Keyword)val id: Long,@Field(name = "user_id", type = FieldType.Long)val userId: Long,@Field(type = FieldType.Text, analyzer = "ik_max_word", copyTo = ["suggestion"]) //注意,copyTo 的字段一定是 var 类型val title: String,@Field(type = FieldType.Text, analyzer = "ik_smart")val content: String,@CompletionField(maxInputLength = 100, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")var suggestion: Completion? = null, //注意,被 copyTo 的字段一定要是 var 类型
)
Ps:被 copyTo 的字段一定要是 var 类型
b)需求:在搜索框中输入 “今天”,对其进行自动补全.
import co.elastic.clients.elasticsearch.core.search.FieldSuggester
import co.elastic.clients.elasticsearch.core.search.FieldSuggesterBuilders
import co.elastic.clients.elasticsearch.core.search.Suggester
import jakarta.annotation.Resource
import org.cyk.es.model.AlbumSugDo
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
import org.springframework.data.elasticsearch.client.elc.ElasticsearchTemplate
import org.springframework.data.elasticsearch.client.elc.NativeQuery
import org.springframework.data.elasticsearch.core.suggest.response.Suggest@SpringBootTest
class SuggestTests {@Resourceprivate lateinit var elasticsearchTemplate: ElasticsearchTemplate@Testfun init() {if(elasticsearchTemplate.indexOps(AlbumSugDo::class.java).exists()) {elasticsearchTemplate.indexOps(AlbumSugDo::class.java).delete()}elasticsearchTemplate.indexOps(AlbumSugDo::class.java).create()elasticsearchTemplate.indexOps(AlbumSugDo::class.java).putMapping(elasticsearchTemplate.indexOps(AlbumSugDo::class.java).createMapping())elasticsearchTemplate.save(listOf(AlbumSugDo(1, 10000, "今天发现西安真美", "西安真美丽啊,来到了钟楼...."),AlbumSugDo(2, 10000, "今天六号线避雷", "前俯后仰。他就一直在那前后动。他背后是我朋友,我让他不要挤了,他直接就急了,开始故意很大力的挤来挤去。"),AlbumSugDo(3, 10000, "字节跳动快上车~", "#内推 #字节跳动内推 #互联网"),AlbumSugDo(4, 10000, "连王思聪也变得低调老实了", "如今的王思聪,不仅交女友的质量下降,在网上也不再像以前那样随意喷这喷那。显然,资金的紧张让他低调了许多")))}@Testfun suggestTest() {//模拟客户端输入的需要自动补全的字段val input = "今天"val limit = 10val fieldSuggester = FieldSuggester.Builder().text(input) //用户输入.completion(FieldSuggesterBuilders.completion().field("suggestion") //对哪个字段自动补全.skipDuplicates(true) //如果有重复的词条,自动跳过.size(limit) //最多显示 limit 条数据.build()).build()val query = NativeQuery.builder().withSuggester(Suggester.of { s -> s.suggesters("sug1", fieldSuggester) }) //参数一: 自定义自动补全名.build()val hits = elasticsearchTemplate.search(query, AlbumSugDo::class.java)val suggestList = hits.suggest?.getSuggestion("sug1")?.entries?.get(0)?.options?.map(::map) ?: emptyList()println(suggestList)}private fun map(hit: Suggest.Suggestion.Entry.Option): String {return hit.text}}
上述代码中的 hits 结构如下:

运行结果: