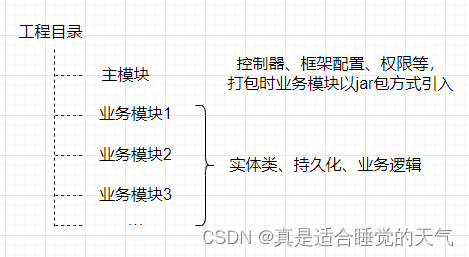
项目目录
主模块配置
配置类
@Configuration
@EnableTransactionManagement
@MapperScan("com.sms.**.mapper")
public class MybatisPlugConfig {@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return mybatisPlusInterceptor;}/*** fix : No MyBatis mapper was found in '[xx.mapper]' package. Please check your configuration*/@Mapperpublic interface NoWarnMapper {}
}启动类
@ComponentScan("com.sms.*")
@SpringBootApplication
@Controller
public class SmsAdminApplication {public static void main(String[] args) {SpringApplication.run(SmsAdminApplication.class, args);}@GetMapping("/message")public String message() {return "message";}
}yml
# Spring配置
spring:jackson:#参数意义:#JsonInclude.Include.ALWAYS 默认#JsonInclude.Include.NON_DEFAULT 属性为默认值不序列化#JsonInclude.Include.NON_EMPTY 属性为 空(””) 或者为 NULL 都不序列化#JsonInclude.Include.NON_NULL 属性为NULL 不序列化default-property-inclusion: NON_NULLdate-format: yyyy-MM-dd HH:mm:sstime-zone: Asia/Shanghaiserialization:WRITE_DATES_AS_TIMESTAMPS: falseFAIL_ON_EMPTY_BEANS: falseprofiles:active: druidmvc:path match:matching-strategy: ant_path_matcherthymeleaf:mode: HTML5suffix: .htmlencoding: UTF-8cache: false# 服务模块devtools:restart:# 热部署开关enabled: trueknife4j:enable: truelogging:level:com.sms.admin: debugfile:name: "./logs/sms-admin.log"logback:rollingpolicy:max-history: 30max-file-size: 50MBtotal-size-cap: 5GBmybatis-plus:mapper-locations: classpath*:com/sms/**/mapper/xml/*.xml#实体扫描,多个package用逗号或者分号分隔typeAliasesPackage: com.sms.**.entity# 以下配置均有默认值,可以不设置global-config:#刷新mapper 调试神器refresh: truedb-config:id-type: auto#驼峰下划线转换tableUnderline: true#数据库大写下划线转换capital-mode: truewhere-strategy: not_emptybanner: falseconfiguration:# 是否开启自动驼峰命名规则映射:从数据库列名到Java属性驼峰命名的类似映射map-underscore-to-camel-case: true#二级缓存cache-enabled: false#延时加载的开关lazyLoadingEnabled: trueaggressiveLazyLoading: true#开启的话,延时加载一个属性时会加载该对象全部属性,否则按需加载属性multipleResultSetsEnabled: true#关闭sql打印
# log-impl: org.apache.ibatis.logging.nologging.NoLoggingImpllog-impl: org.apache.ibatis.logging.stdout.StdOutImplpom
根目录
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.sms</groupId><artifactId>sms</artifactId><version>0.0.1</version><name>···</name><description>···</description><properties><simulationMasterStation.version>0.0.1</simulationMasterStation.version><java.version>11</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>2.7.6</spring-boot.version></properties><dependencyManagement><dependencies><!-- 主模块--><dependency><groupId>com.sms</groupId><artifactId>sms-admin</artifactId><version>${simulationMasterStation.version}</version></dependency><!-- 子模块--><dependency><groupId>com.sms</groupId><artifactId>···</artifactId><version>${simulationMasterStation.version}</version></dependency></dependencies></dependencyManagement><modules><module>sms-admin</module><module>···</module></modules><packaging>pom</packaging><dependencies></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>${java.version}</source><target>${java.version}</target><encoding>${project.build.sourceEncoding}</encoding></configuration></plugin></plugins></build>
</project>
主模块
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><groupId>com.sms</groupId><artifactId>sms</artifactId><version>0.0.1</version></parent><modelVersion>4.0.0</modelVersion><name>sms-admin</name><description>sms-admin</description><packaging>jar</packaging><artifactId>sms-admin</artifactId><properties><java.version>11</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>2.7.6</spring-boot.version></properties><dependencies><!-- 子模块--><dependency><groupId>···</groupId><artifactId>···</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring-boot.version}</version><configuration><mainClass>com.sms.admin.SmsAdminApplication</mainClass></configuration><executions><execution><id>repackage</id><goals><goal>repackage</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-war-plugin</artifactId><version>3.1.0</version><configuration><failOnMissingWebXml>false</failOnMissingWebXml><warName>${project.artifactId}</warName></configuration></plugin></plugins><finalName>${project.artifactId}</finalName></build>
</project>
后记
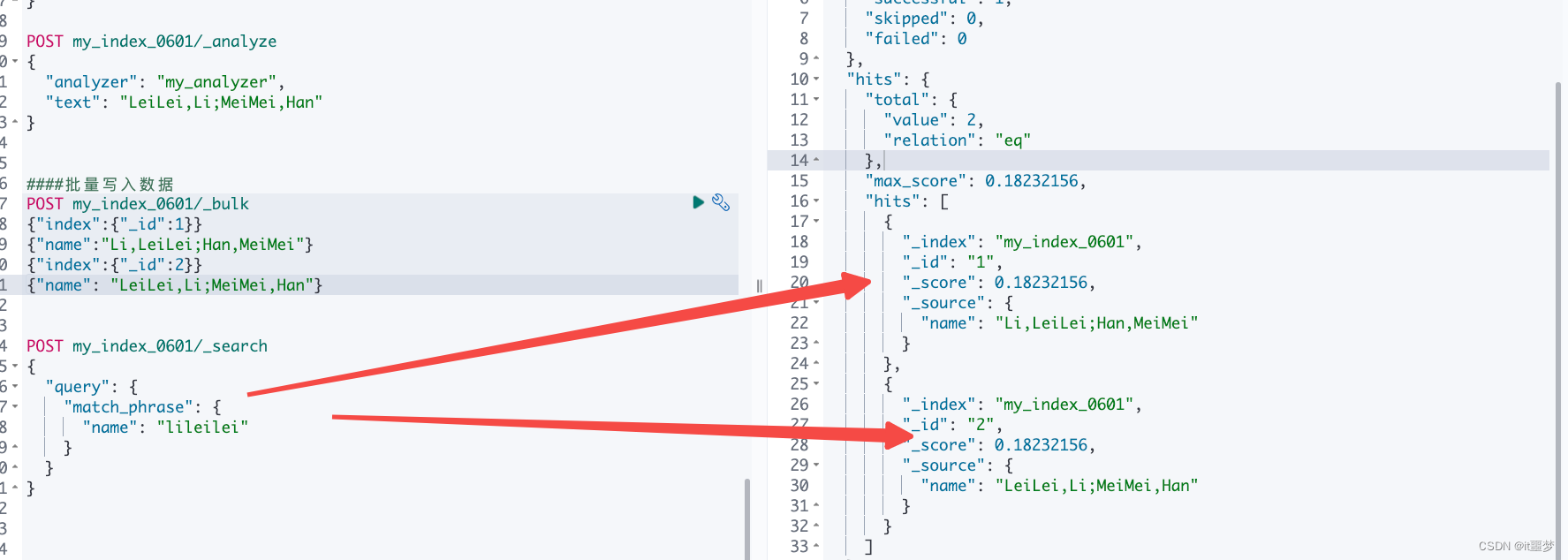
classpath和classpath*的区别
classpath:只会到你的class路径中查找找文件。
classpath*:不仅包含class路径,还包括jar文件中(class路径)进行查找。
注意: 用classpath*:需要遍历所有的classpath,所以加载速度是很慢的;因此,在规划的时候,应该尽可能规划好资源文件所在的路径,尽量避免使用classpath*。
mapper-locations配置方式
方式一:放在Mapper目录下
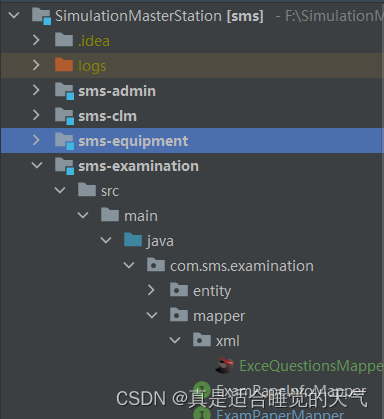
yml
mybatis-plus:mapper-locations: classpath*:com/sms/**/mapper/xml/*.xmlpom
<build><resources><!-- 扫描src/main/java下所有xx.xml文件 --><resource><directory>src/main/java</directory><includes><include>**/*.xml</include></includes></resource></resources></build>方式二:放在resource下
yml
# mybatis-plus相关配置
mybatis-plus:# xml扫描,多个目录用逗号或者分号分隔(告诉 Mapper 所对应的 XML 文件位置)mapper-locations: classpath*:mybatis/*Mapper.xml