文章目录
- 分词发生的阶段
- 写入数据阶段
- 执行检索阶段
- 分词器的组成
- 字符过滤
- 文本切分为分词
- 分词后再过滤
- 分词器的分类
- 默认分词器
- 其他典型分词器
- 特定业务场景的自定义分词案例
- 实战问题拆解
- 实现方案
分词发生的阶段
写入数据阶段
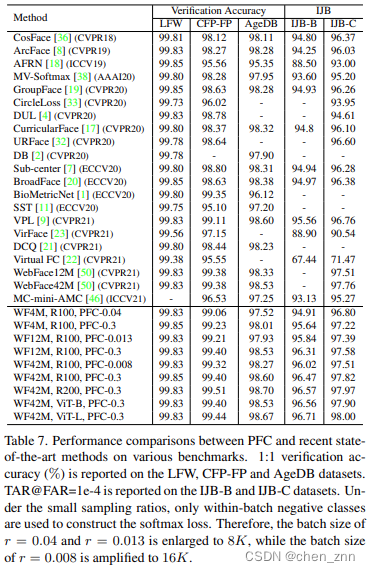
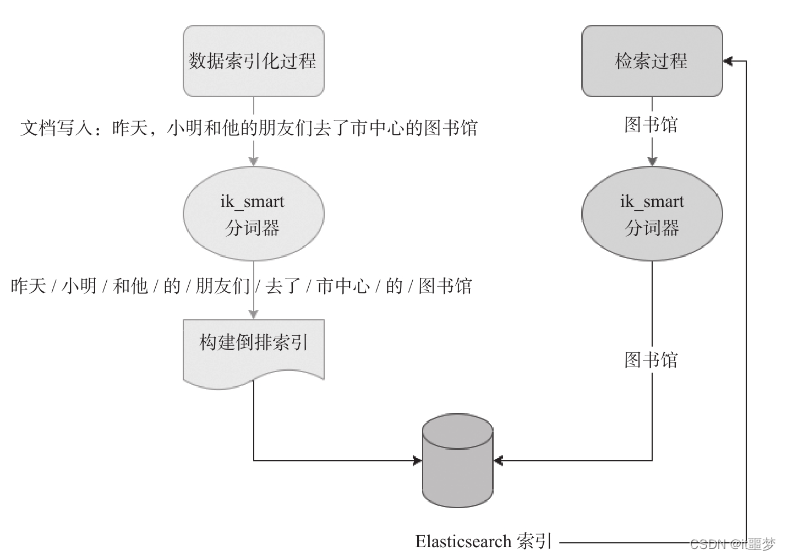
分词发生在数据写入阶段,也就是数据索引化阶段。举例如下。该例中使用的中文分词器ik自带词典,词典系2012年前后的词典。
执行检索阶段
当使用ik_smart分词器对“昨天,小明和他的朋友们去了市中心的图书馆”进行分词后,会将这句话分成不同的词汇或词组。
在执行“图书馆”检索时,Elasticsearch会根据倒排索引查找所有包含“图书馆”的文档。
分词器的组成
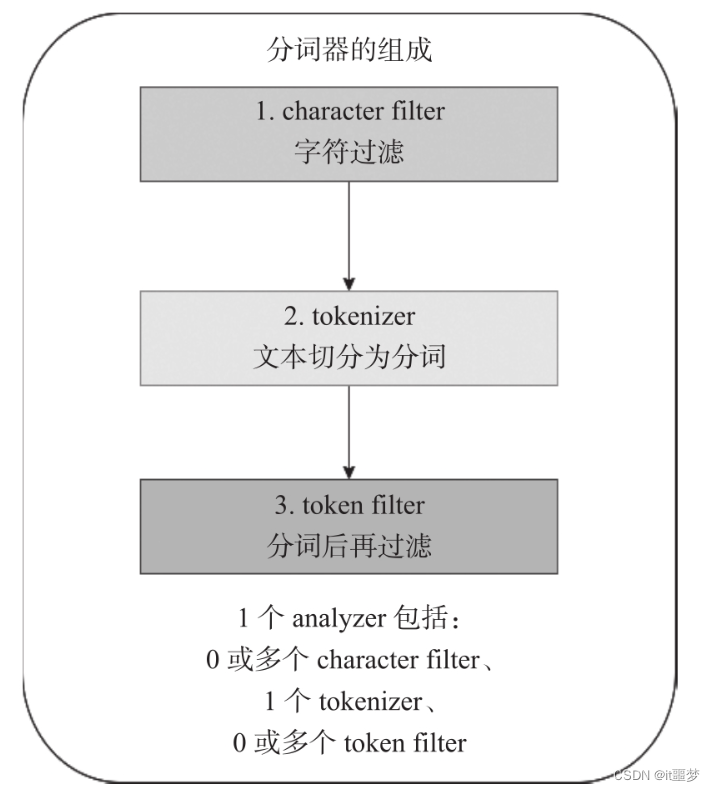
文档被写入并转换为倒排索引之前,Elasticsearch对文档的操作称为分析。而分析是基于Elasticsearch内置分词器(analyzer)或者自定义分词器实现的。
字符过滤
字符过滤器(character filter)将原始文本作为字符流接收,并通过添加、删除或更改字符来转换字符流。字符过滤器分类如下
字符过滤器(character filter)将原始文本作为字符流接收,并通过添加、删除或更改字符来转换字符流。
1)HTML Strip Character Filter:用于删除HTML元素,如删除<b>标签;解码HTML实体,如将&转义为&。
2)Mapping Character Filter:用于替换指定的字符。
3)Pattern Replace Character Filter:可以基于正则表达式替换指定的字符。
文本切分为分词
若进行了字符过滤,则系统将接收过滤后的字符流;若未进行过滤,则系统接收原始字符流。在接收字符流后,系统将对其进行分词,并记录分词后的顺序或位置(position)、起始值(start_offset)以及偏移量(end_offset-start_offset)。而tokenizer负责初步进行文本分词。
tokenizer分类如下,详细使用方法需参考官方文档。
❑Standard Tokenizer(标准分词器)
❑Letter Tokenizer(字母分词器)
❑Lowercase Tokenizer(小写转化分词器)
分词后再过滤
在对tokenizer处理后的字符流进行进一步处理时,例如进行转换为小写、删除(去除停用词)和新增(添加同义词)等操作,可能会感到有些复杂。不用担心,只需将它们的执行顺序牢记在心,结合实战案例的详细解析来进行理解,便能逐渐明白其中的奥妙。
分词器的分类
默认分词器
Elasticsearch默认使用standard分词器。也就是说,针对text类型,如果不明确指定分词器,则默认为standard分词器。standard分词器会将词汇单元转换成小写,并去除停用词和标点符号。它基于Unicode文本分割算法进行工作,适用于大多数语言。standard分词器针对英文的分词效果如下。
1)对于英文,以“A man can be destroyed,but not defeated.”为例,分词效果如下。

2)对于中文,以“昨天,小明和他的朋友们去了市中心的图书馆。”为例,分词效果如下。
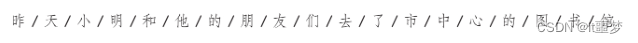
其他典型分词器
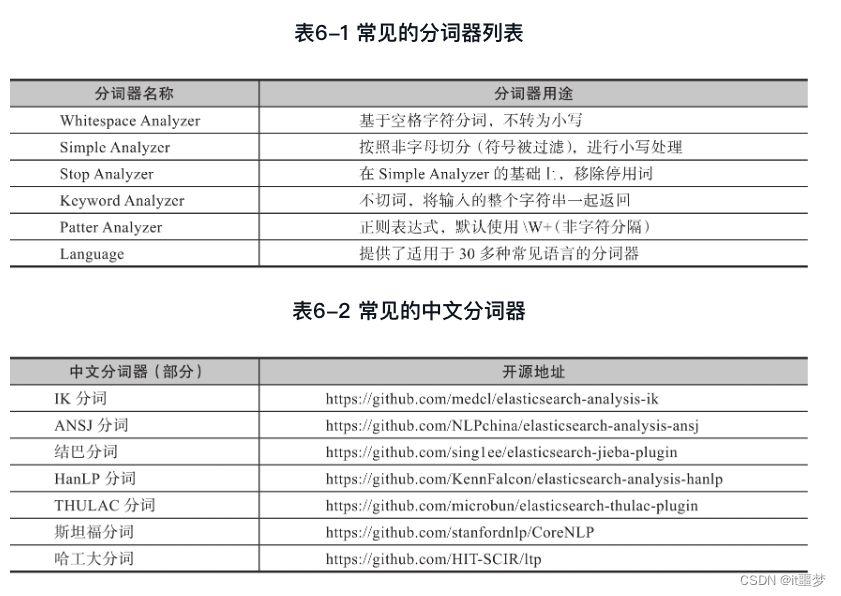
使用IK分词器有以下注意事项。
1)IK自带词典并不完备,建议自己结合业务添加所属业务的词典。
2)IK采用动态添加词典的方式,建议修改IK分词插件源码,与MySQL数据库结合,以灵活支持动态词典的更新。
特定业务场景的自定义分词案例
业务需求是这样的:有一个作者字段,比如Li,LeiLei;Han,MeiMei以及LeiLei Li……现在要对其进行精确匹配。对此,你有什么想法?
你可能会考虑用自定义分词的方式,通过分号分词。但是这样的话,如果检索Li,LeiLei,那么LeiLei Li就不能被搜索到,而我们希望LeiLei Li也被搜索到。并且对于这种分词,Li,LeiLei中间不加逗号也不能匹配到。但是为什么在映射里面添加停用词也是无效的呢?
实战问题拆解
首先来看自定义分词器在映射的Settings部分中的设置。
### 创建索引
PUT my_index_0601
{"settings": {"analysis": {"char_filter": {},"tokenizer": {},"filter": {},"analyzer": {}}}
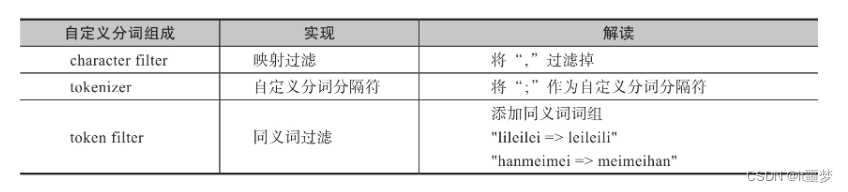
}分词器由如下几部分组成。
❑"char_filter":{},——对应字符过滤部分。
❑"tokenizer":{},——对应文本切分为分词部分。
❑"filter":{},——对应分词后再过滤部分。
❑"analyzer":{}——对应分词器,包含上述三者。
然后来拆解问题,如下所示。
❑核心问题1:实际检索中,名字不带“,”,即逗号需要通过字符过滤掉。
方案:在char_filter阶段实现过滤。
❑核心问题2:基于什么进行分词?
方案:在Li,LeiLei;Han,MeiMei;的构成中,只能采用基于“;”的分词方式。
❑核心问题3:支持姓名颠倒后的查询,即LeileiLi也能被检索到。
方案:需要结合同义词实现。在分词后的过滤阶段,将LiLeiLei和LeiLeiLi设定为同义词。
实现方案
PUT my_index_0601
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "mapping","mappings": [", => "]}},"tokenizer": {"my_tokenizer": {"type": "pattern","pattern": """\;"""}},"filter": {"my_synonym_filter": {"type": "synonym","expand": true,"synonyms": ["leileili => lileilei","meimeihan => hanmeimei"]}},"analyzer": {"my_analyzer": {"tokenizer": "my_tokenizer","char_filter": ["my_char_filter"],"filter": ["lowercase","my_synonym_filter"]}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer"}}}
}POST my_index_0601/_analyze
{"analyzer": "my_analyzer","text": "Li,LeiLei;Han,MeiMei"
}POST my_index_0601/_analyze
{"analyzer": "my_analyzer","text": "LeiLei,Li;MeiMei,Han"
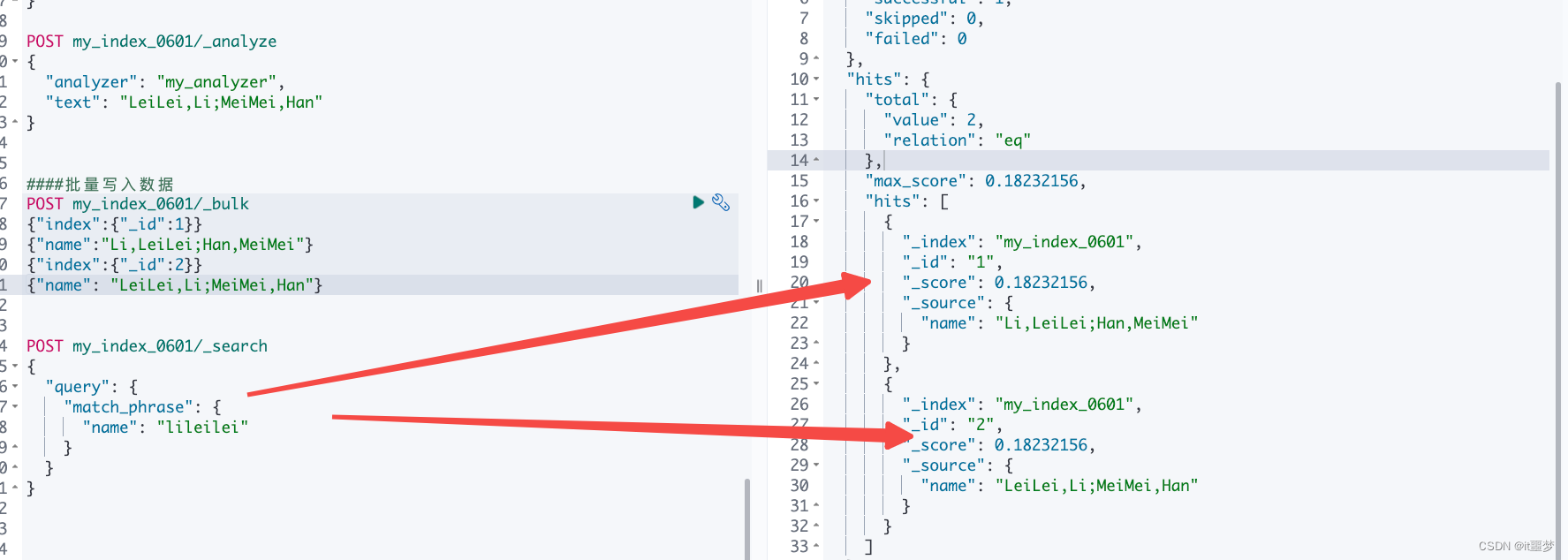
}####批量写入数据
POST my_index_0601/_bulk
{"index":{"_id":1}}
{"name":"Li,LeiLei;Han,MeiMei"}
{"index":{"_id":2}}
{"name": "LeiLei,Li;MeiMei,Han"}POST my_index_0601/_search
{"query": {"match_phrase": {"name": "lileilei"}}
}