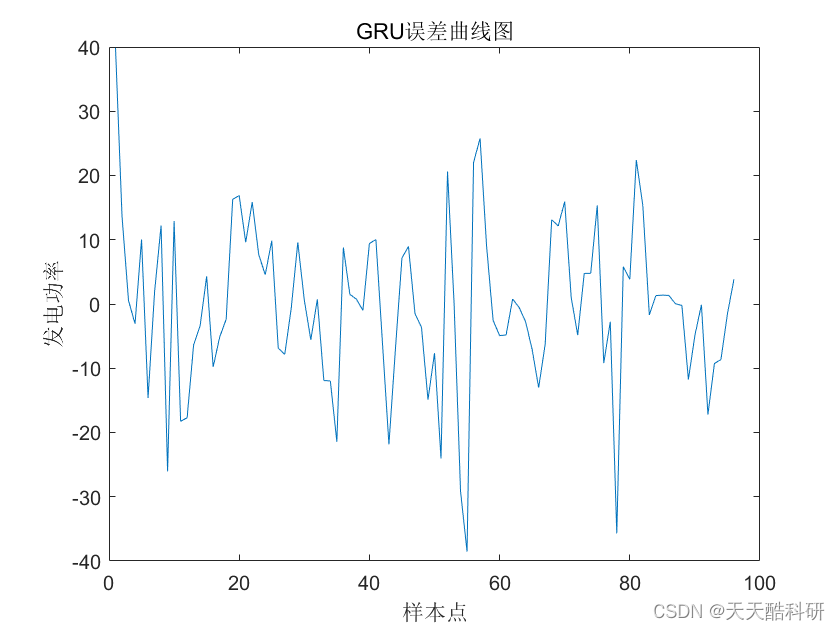
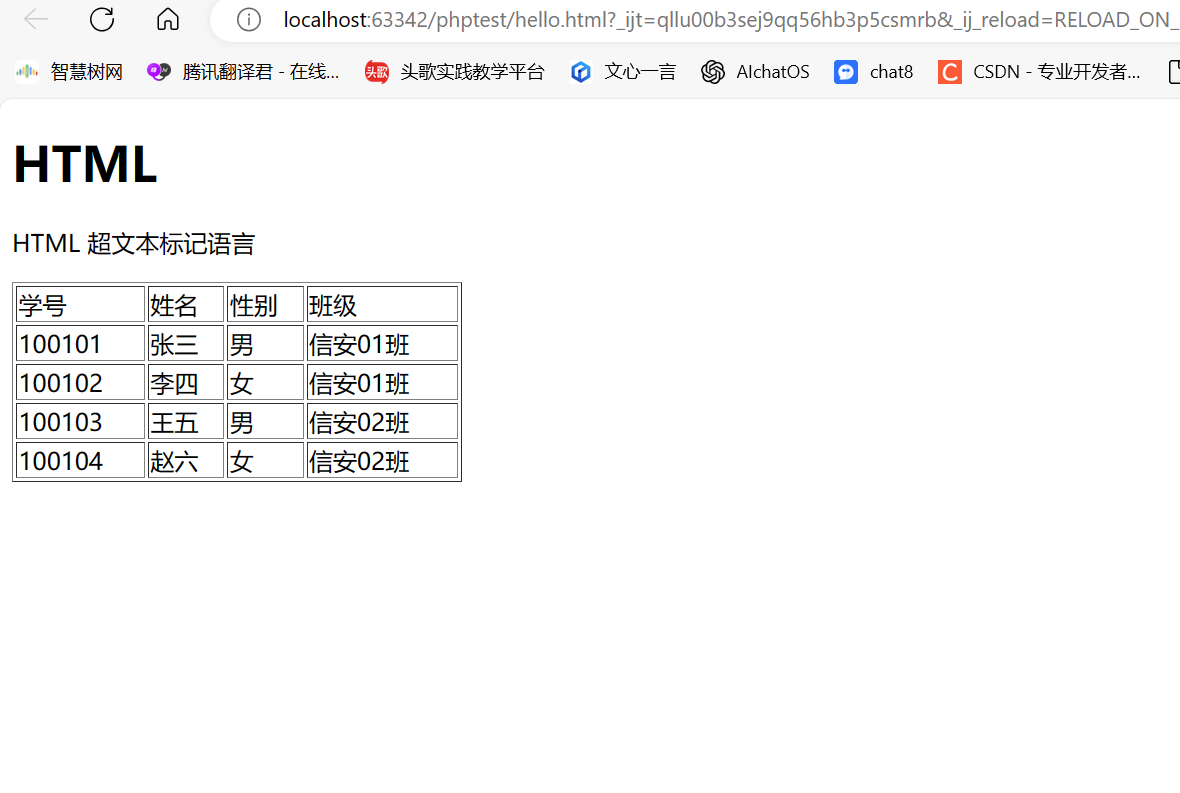
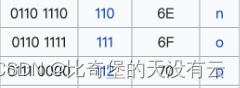
为什么要使用JVM
①一次编写,到处运行,jvm屏蔽字节码与底层的操作差异
②自动内存管理,垃圾回收功能
③数组下边越界检查
④多态
JDK,JRE,JVM的关系

JVM组成部分

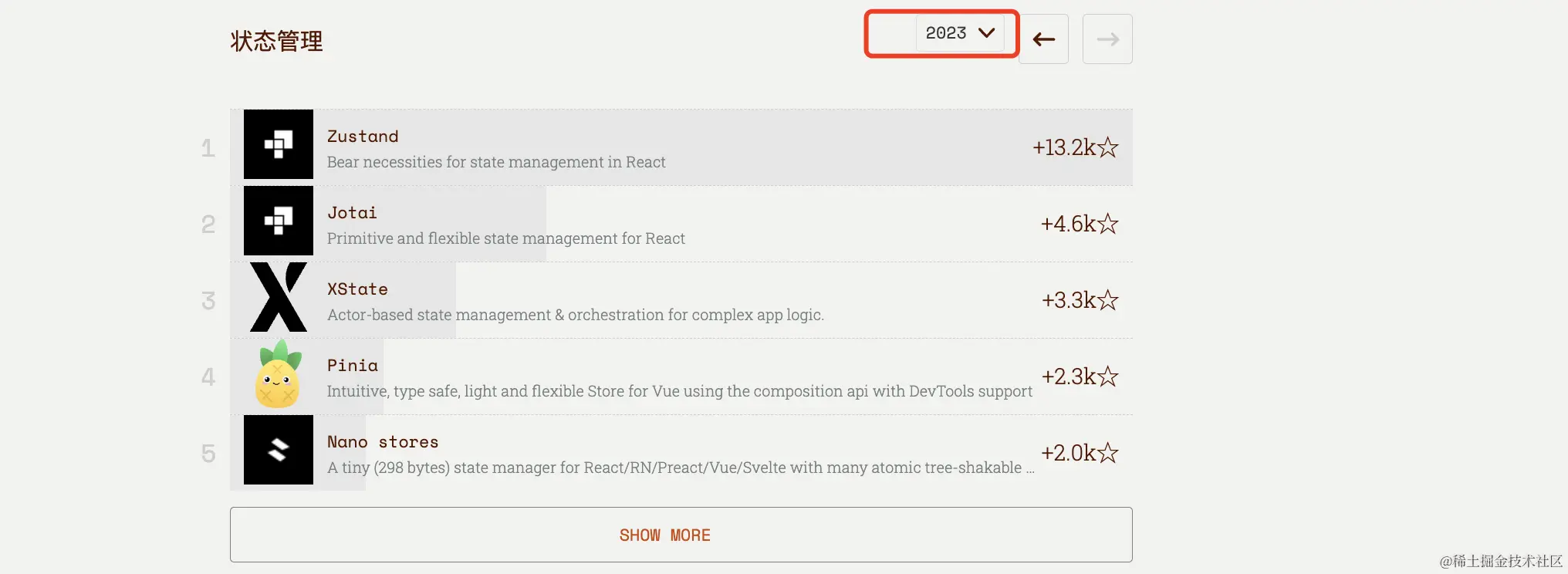
JVM的内存结构
《一》程序计数器(PC Register)
作用:
java代码执行流程: java源代码-->二进制字节码文件(jvm指令)-->解释器-->机器码-->cpu执行,而程序计数器就是去记住下一条jvm指令的执行地址。
特点:
①线程私有
②唯一不会存在内存溢出的区
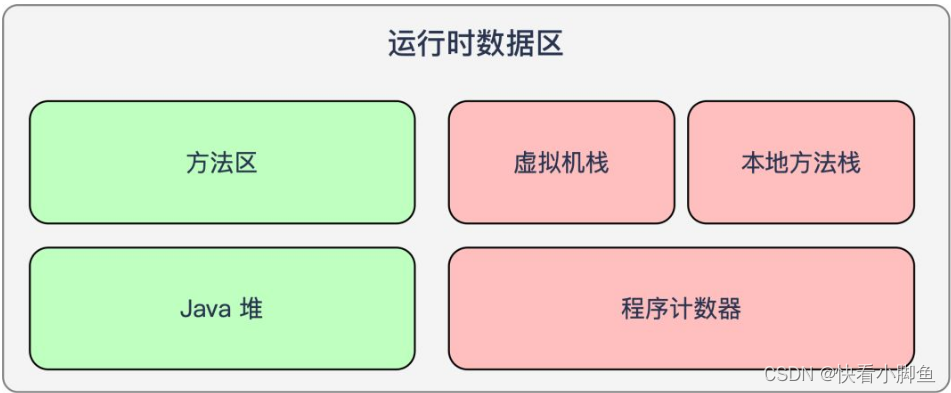
《二》虚拟机栈(JVM Stack)
概念:每个线程运行时所需要的内存,称为虚拟机栈。

1. 答:垃圾回收不涉及栈内存,因为栈中是运行方法时的存放的地方,当方法结束后栈帧会自动退栈释放空间,不需要垃圾回收机制来处理。垃圾回收主要是去处理堆内存。
2. 答:不是,内存分配越大并不会对程序的执行效率有提升,反而会减少内存空间和线程的数量。
3. 答:方法内的局部变量是安全的,因为一个线程对应自己的一个栈,局部变量各自存在栈中。但是如果是static修饰的变量线程间就会共享,可能会产生线程安全问题。另外如果局部变量是引用类型并且逃离了方法的作用范围,就会产生线程安全问题。
栈内存溢出:java.lang.StackOverflowError
①方法(栈帧)过多,栈帧内存超过栈的总内存就会发生栈溢出
②栈帧过大直接挤满了栈发生栈溢出(反复调用)
线程诊断:
①top命令可以查看所有正在运行的进行和系统负荷提供不断更新的概览信息,包括系统负载、CPU利用分布情况、内存使用、每个进程的资源占用情况等信息
②ps H -eo pid,tid,%cpu | grep 进程ID 查看线程的信息
③jstack 进程ID 查看进程的线程信息
《三》本地方法栈(Native Method Stacks)
有的时候我们需要调用操作系统底层的一些方法,但是java语言不可以直接调用,所以就需要一些更底层的c或者c++写的本地方法去间接调用。所以我们要创建一个本地方法栈去存储本地方法运行时需要的空间
《四》堆(Heap)
①通过new 创建的对象都会使用堆内存
②线程共享,其中的对象都需要考虑线程安全的问题
③垃圾回收机制
堆内存溢出: java.lang.OutOfMemoryError
堆内存诊断:
①jps 查看当前正在运行的java进程
②jmap -heap 进程号 查看堆内存的占用情况
③jconsole
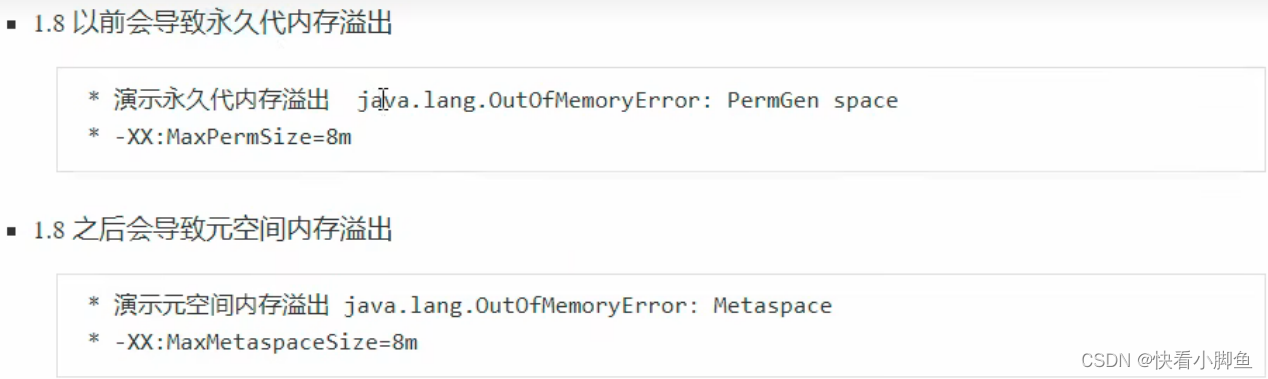
《五》方法区(Method Area)
①线程共享,在虚拟机启动时创建,用于存储已被Java虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
②ClassLoader,类加载器,加载类的二进制字节码
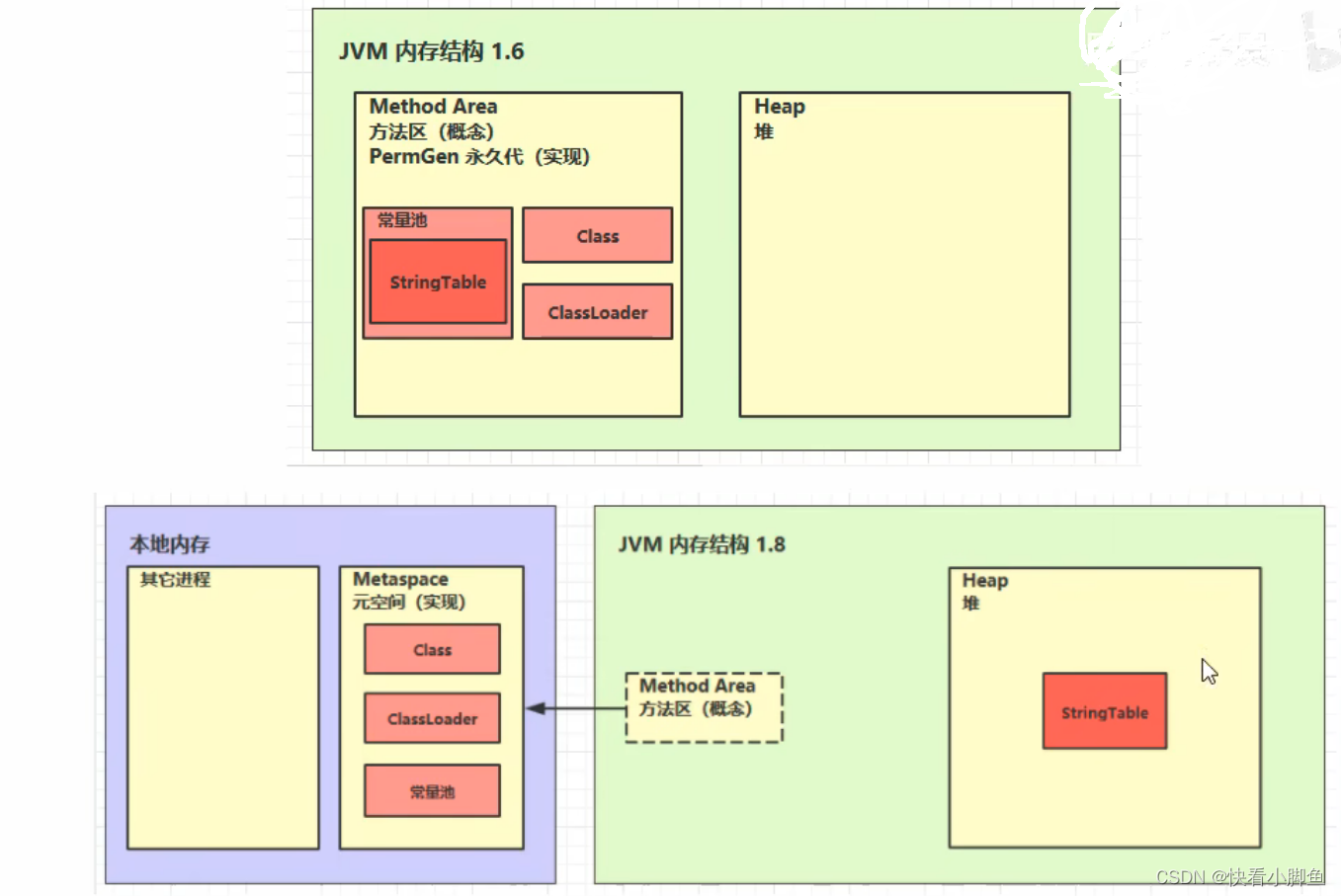
方法区内存溢出:
运行时常量池
①二进制字节码文件:类的基本信息+常量池+类方法定义包括虚拟机指令
②常量池:是.class文件中的,其实就是一张表,虚拟机指令根据常量池去找到要执行对应的类名,方法名,参数等信息
③运行时常量池:当类被加载时他的常量池信息就会放进运行时常量池,并且把其中的符号地址编程真实地址
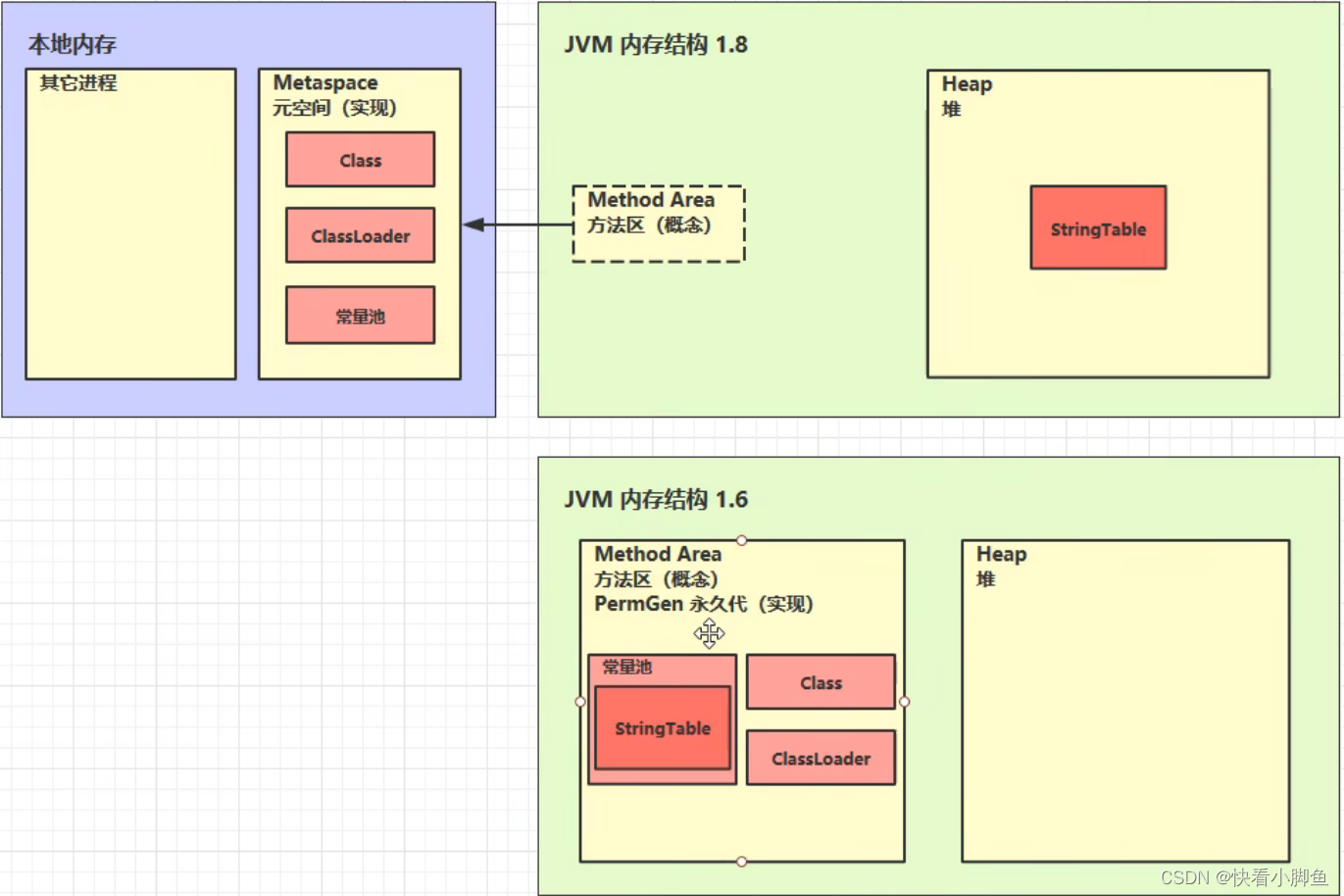
StringTable串池(hashtable结构,不能扩容)

常量池被加载到运行时常量池的时候,这时 a b ab 都是常量池中的符号,还不是java对象。当程序中要使用的时候会先去查看串池中有没有,没有的话就把这些符号放到串池当中变成字符串对象。这个是叫做字符串的延迟加载,不用就不加载

s1+s2会在堆中创建一个新的字符串对象。其底层是一个StringBuilder对象,使用toString方法最后再new String对象,注意:这个对象是只在堆中,不在串池中
s5中,两个字符串拼接起来是直接在串池中找
注意,1.6版本的话如果串池中没有的话,会复制一份对象放进去,而不是放本身,所以串池中的对象跟外面的那个不是一个,外面那个对象还是在堆中
来个题目练练手:

StringTable的位置:1.6下存放在常量池(永久代)中,1.7之后就放在堆中,因为在常量池中的回收效率很低
StringTable垃圾回收
当存入的数据大于Stringtable的空间大小时,会触发垃圾回收机制
StringTable性能调优
①参数StringTableSize来调整StringTable的桶个数,让下面的链表不能太长
②当有大量的字符串对象时,考虑将字符串对象是否入池,去重优化字符串的个数
《六》垃圾回收

1,如何判断对象可以回收:
①引用计数法
②可达性分析算法,这个算法的基本思想就是通过一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是不可用的。

③Java的五种引用

2,垃圾回收算法
①标记—清除:分为两个阶段,一个是标记阶段,为每个对象进行标记看是不是被GC ROOT引用;第二个阶段是清除阶段,该阶段对死亡的对象进行清除,执行 GC 操作。
优点:是可以解决循环引用的问题必要时才回收(内存不足时)
缺点:标记和清除的效率不高,尤其是要扫描的对象比较多的时候,会造成内存碎片
②标记—整理:也是分为两个阶段,一个是标记阶段,为每个对象进行标记看是不是被GC ROOT引用;第二个阶段是整理,在清理垃圾的过程中将所有存活的对象整理移动一下,再去清理空间
优点:解决标记清除算法出现的内存碎片问题。
缺点:压缩阶段,由于移动了可用对象,需要去更新引用。
③复制算法:将内存分成两个相同大小的区,分别为from和to。使用时只使用一个,当进行垃圾回收时,首先将from区的垃圾标记,然后把存活的对象全部放去to区,再清空from区,执行完之后把二者身份互换。
优点:能解决内存碎片
缺点::会造成一部分的内存浪费;如果存活对象的数量比较大,复制算法的性能会变得很差。
3,分代垃圾回收
但是在jvm中不可能只使用上面算法的一种,而是是结合上面的算法,形成一种分代垃圾回收算法
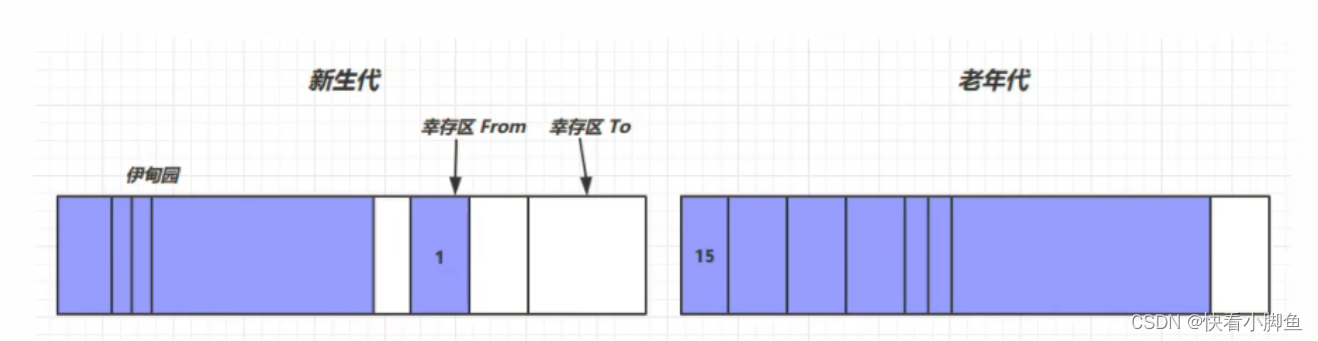
- 堆被划分为新生代和老年代,对象首先被分配在新生代中的伊甸园区
- 当新生代空间不足时,触发minor gc,将伊甸园和from区中存活的对象复制到to中并且对象年年龄+1,到对象年龄到达一定数值(15)后会被放到老年代中,然后再将死亡的对象回收掉,最后交换from和to区
- minor时会引发stop the world,暂停其他线程,等待垃圾回收
- 当老年代空间不足时,先尝试minor gc,如果还不够就会触发full gc,STW时间会更长
- 大对象,当对象的大小超过新生代的空间,并且minor gc之后也没用,会直接晋升到老年代
4,垃圾回收器
可分为三大类:串行,吞吐量优先,响应时间优先

①串行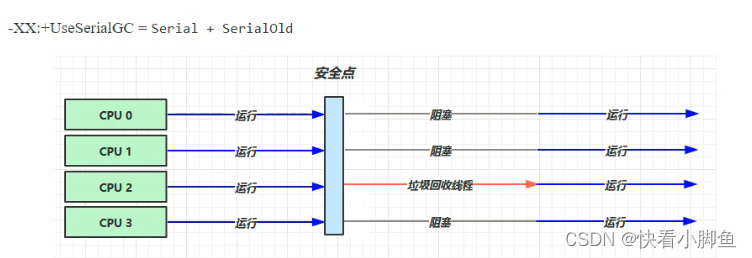
②吞吐量优先
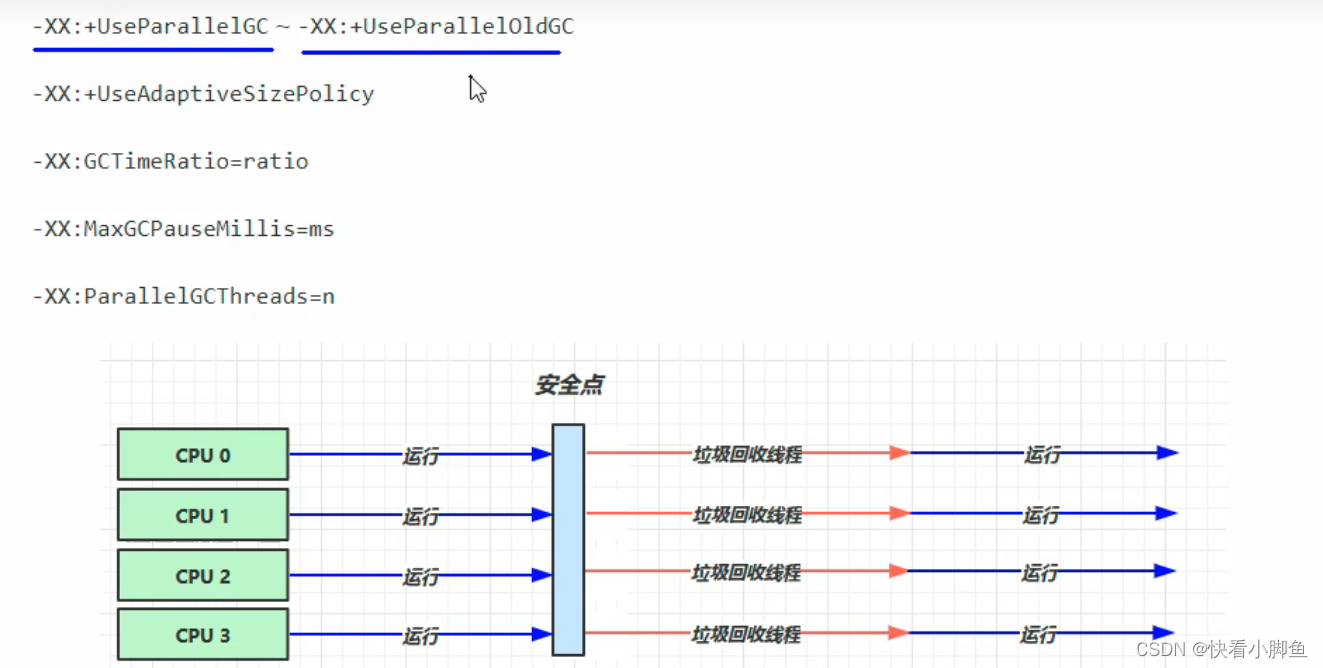
③响应时间优先(并发)
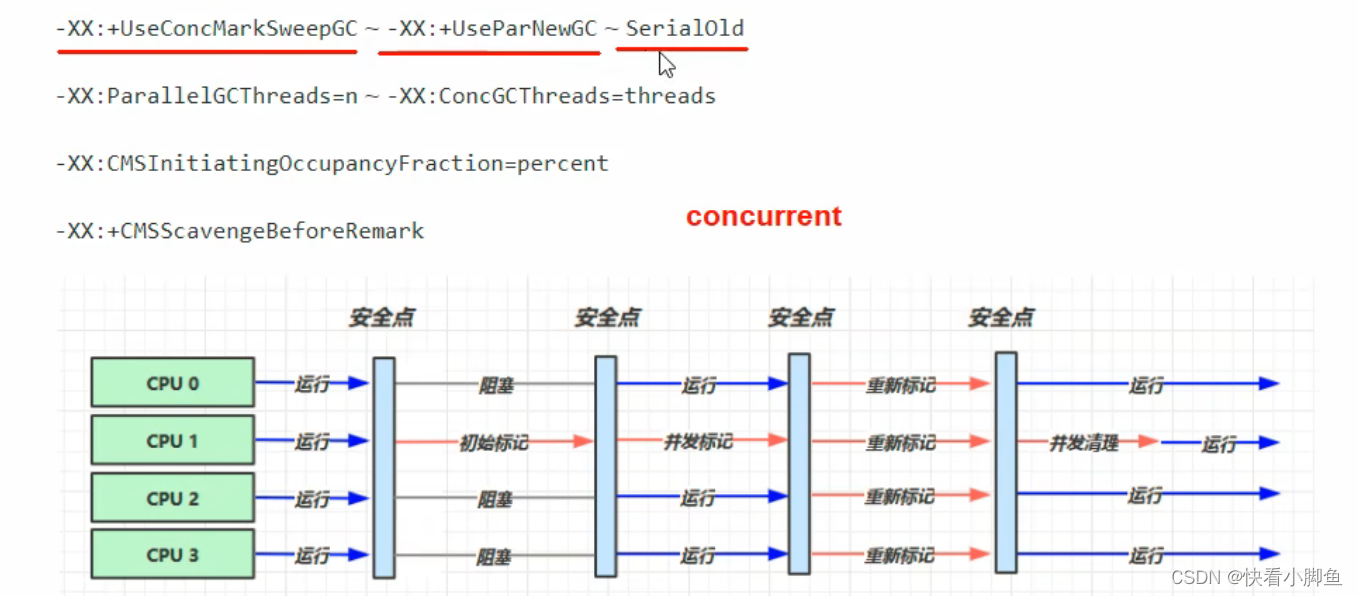
CMS:低延迟,基于标清除算法,并发。
初始标记:标记GC Root - 》 并发标记 - 》 最终标记 - 》 并发清理:
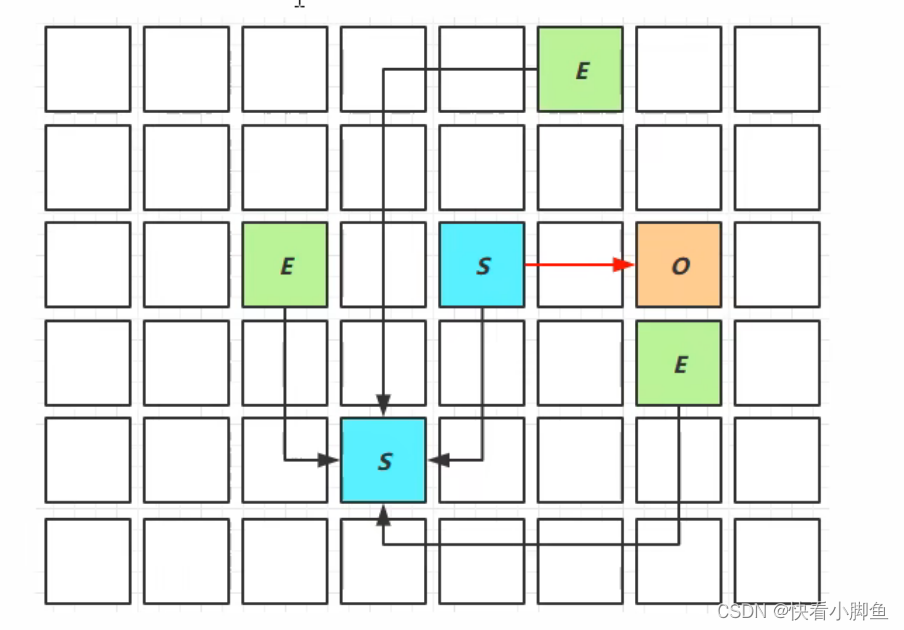
G1垃圾回收器(并发)


第一阶段:新生代(young collection):
第二个阶段:新生代+CM(concurrent mark):
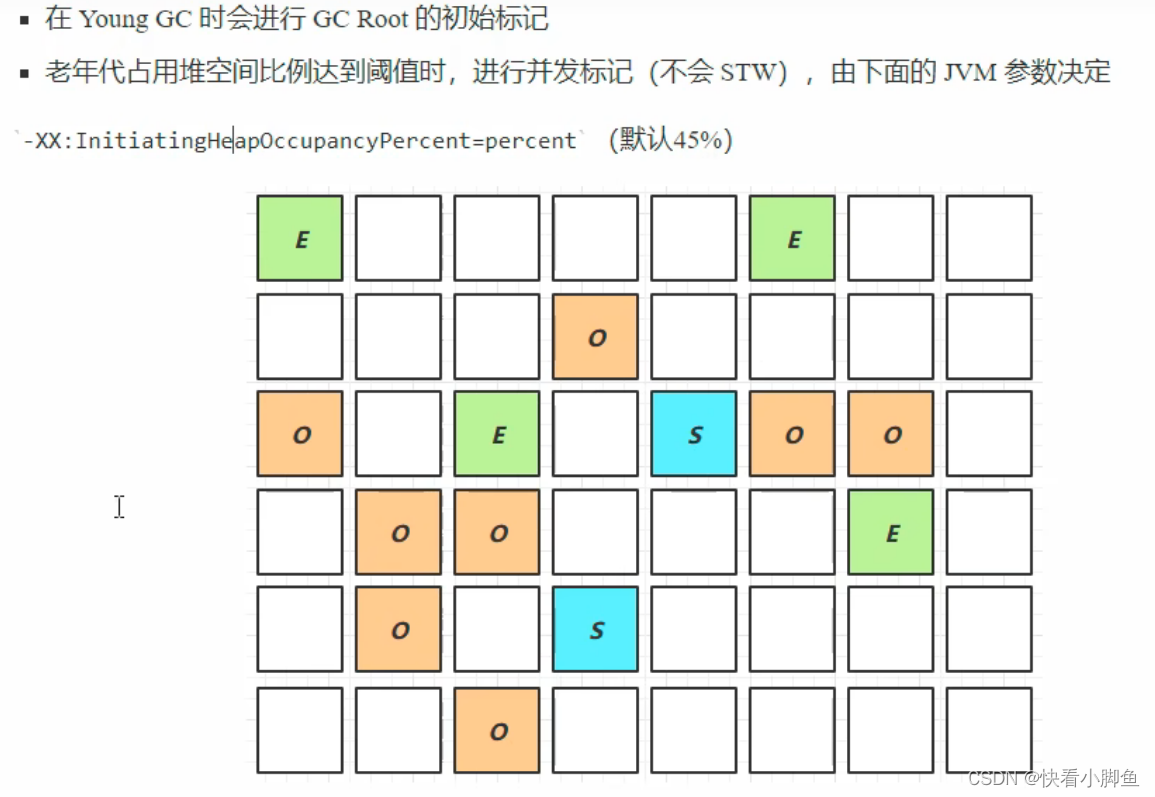
第三个阶段:混合收集(Mixed collection):
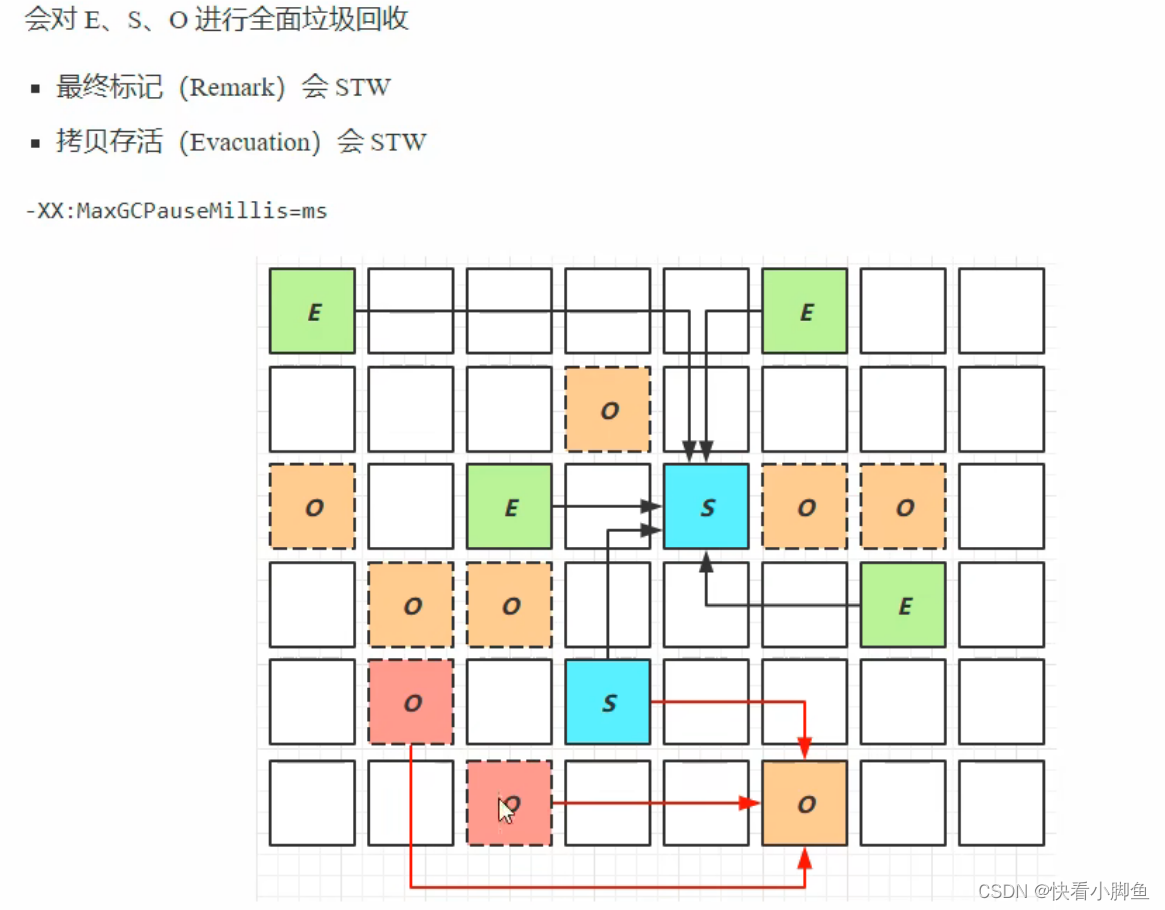
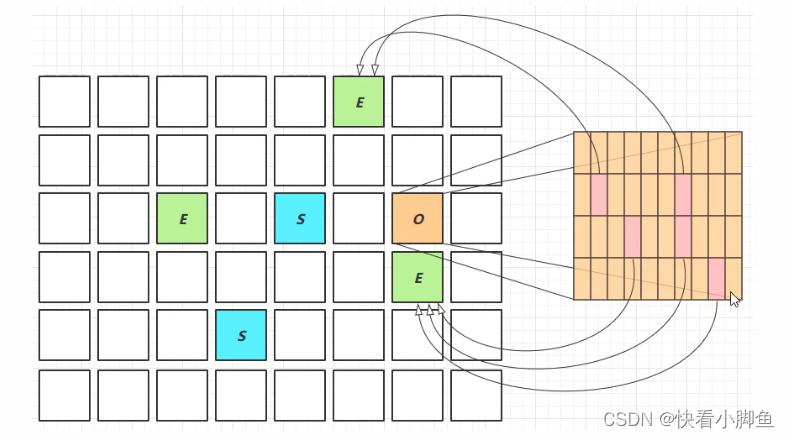
对老年代的回收时,当老年代数量较少时,会全部进行复制回收,但数量较多时,为了达到MaxGcPauseMillis的要求,会进行有挑选的选择垃圾多的老年代区进行复制回收。
跨代引用:卡表技术
《七》类加载器

1,类字节码文件结构
魔数+版本+类相关信息+常量池+各种方法的信息(包括构造方法,主方法,属性,参数,成员变量)
2,字节码指令
常量池加载时放进运行时常量池,方法字节码存入到方法区,栈帧由局部变量表+操作数栈了,由执行引擎条条虚拟机指令
public class test {public static void main(String[] args) {int i =0;int j =0;while(j<10){i = i++;j++;}System.out.println(i);}
}结果输出为0。i每次放进去操作数栈之后,局部变量表中虽然执行了++操作,但是之后操作数栈中的0又会被赋值到i中,一直循环。
多态的原理:

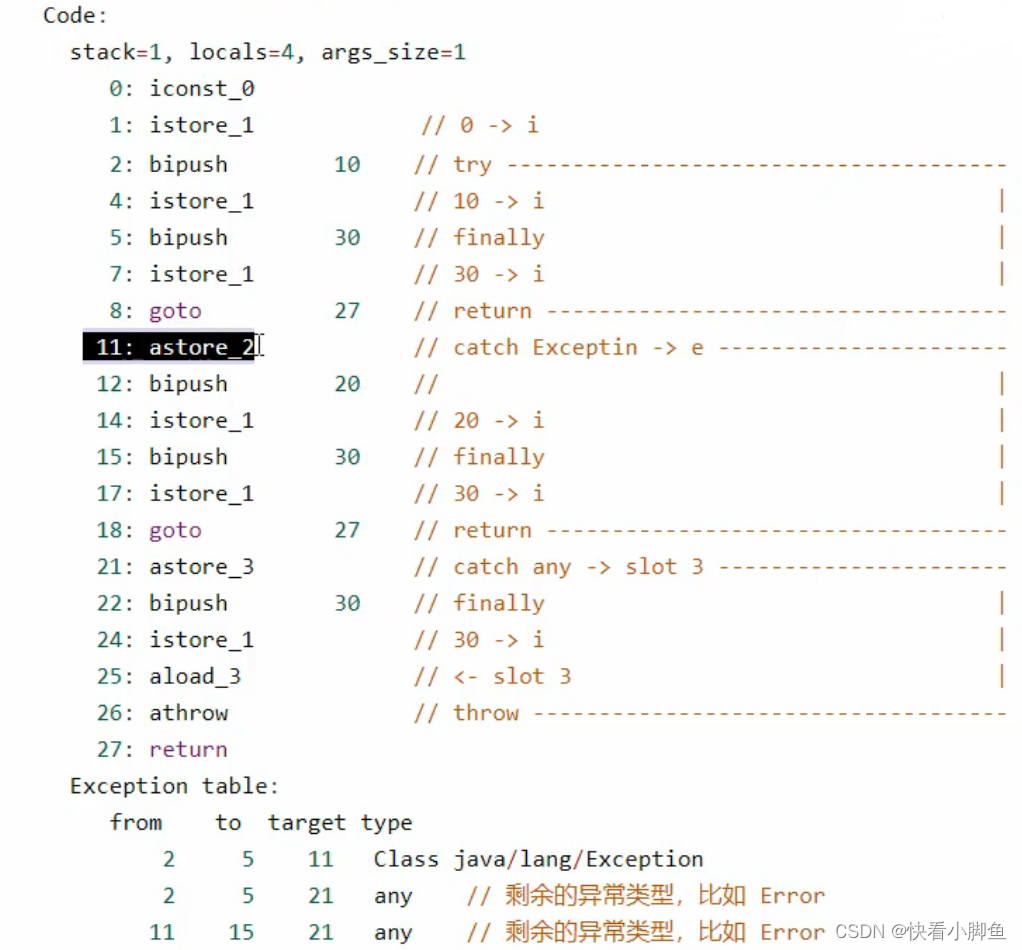
异常的原理:

finally块:其底层原理就是把finally块中的代码部分分别放在try的后面和catch的后面,所以说finally中的代码一定会执行。 ①而且就算是没有捕获到的异常,也会被抓到然后执行finally的代码,再抛异常,②而且finally中抛异常和return只会执行一个