说明
读者在阅读本文前,建议先看看本系列的第一篇文章:[1](毫米波雷达数据处理中的)聚类算法(1) --- 概述-CSDN博客
DBSCAN算法(Density-Based Spatial Clustering of Applications With Noise)是一种基于密度的聚类算法,其它的应用领域我不清楚,但是对于车载毫米波雷达的点云聚类,DBSCAN是最常用的聚类算法。本文没有使用实际的雷达点云数据进行实践,而是将本算法用于Iris数据集以及自己生成的二维点簇数据集,不过算法的处理是相通的,读者可以基于后文提供的代码做一些简单的修改就可以用于雷达点云数据(以及其它的应用领域)。
Blog
2024.5.15 博文第一次撰写
目录
说明
目录
一、DBSCAN算法介绍
二、基于DBSCAN的Iris数据集聚类实践
2.1 关于Iris数据集
2.2 基于DBSCAN算法的处理结果
三、基于DBSCAN的自生成二维平面点簇数据集聚类实践
3.1 二维平面点簇生成结果
3.2 基于DBSCAN算法的处理结果
四、总结
五、参考资料
六、参考代码与数据集
一、DBSCAN算法介绍
网上关于DBSCAN算法的介绍有很多,本章对DBSCAN算法的介绍如果读者没能理解可以搜搜其它的资料,如[2]。这里先给出该算法的流程框图,读者可以结合此图、后续的说明以及后文所提供的代码一起进行理解:
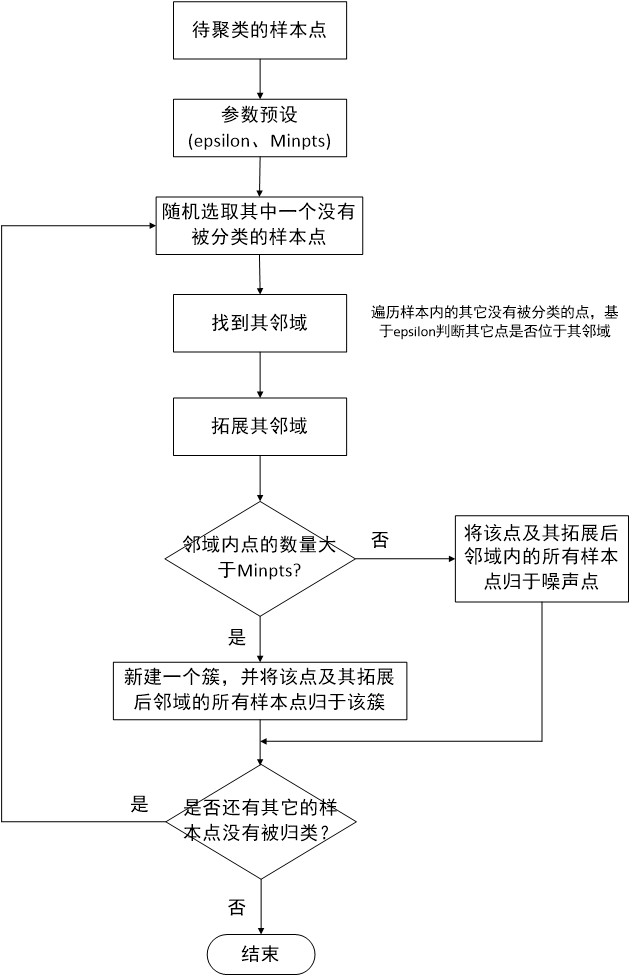
图1.1 典型的DBSCAN算法流程图
DBSCAN算法有两个最核心的概念:邻域半径(我们一般用变量名epsilon来表示)和评价是否为簇的最少样本数(我们一般用Minpts来表示)。
DBSCAN是一种基于密度的聚类算法,邻域半径就是用来衡量紧密程度的:只有当两个样本点的间隔(如何定义间隔?)小于预设的epsilon时,我们才认为这两样本点是属于一类的,epsilon在算法的实现中,具有可拓展性(感觉有点类似侵蚀性,就是上图中的邻域拓展部分做的事):假设点A和点B之间的间隔满足要求,点A和点C之间的间隔不满足要求,但如果点B和点C之间的间隔满足要求,此时我们会认为A、B、C都属于同一类!总之:我们需要尽可能地把符合epsilon条件的样本点都找到。而Minpts是我们新建一个簇的阈值条件:只有当同一类的样本点的总数超过该值,我们才认为其是一个簇,如果没超过我们认为它们是噪声点。
【DBSCAN除去不需要事先预设簇的数量外,能分辨出噪声点也是其优势之一!】
这里以车载雷达的数据处理对这两概念做更细节的说明:在车载雷达的数据处理流程中,聚类发生在CFAR(或者说求得点云)之后,此时这些点云会有诸多属性(特征):每个点会有其相对雷达的距离R、速度V、能量值P等等,在车载雷达中,我们聚类的目的是将所属同一个目标(特别是运动目标)的点云聚集到一起,不难理解的是,这些所属同一个目标的点云,它们会有近似相等的距离、速度以及能量值,那么我们就可以籍此设置epsilon的值!比如可以设置epsilon(1) = 1.5m,只有当两点云之间的间隔dR小于该值时,我们才认为其可能所属同一类,同理还可以设置epsilon(2)为dV的阈值、epsilon(3)为dP的阈值,并且规定:只有当满足全部三个条件时,这两个点才会被归于同一个类【构建epsilon还有其它的方法,比如我们还可以归一化各个属性值并将之合并为一个值,这里面可供探讨的细节还是蛮多的】。再结合Minpts,比如只有当该类中的点云数量超过4时,我们才会给这几个点构建一个簇,如果一个类中符合epsilon要求的点数小于4,我们认为它是噪声点,在后续的跟踪算法中不予考虑。【注:前面示例中的具体数字仅做举例用】。
从上文的讨论可知,该算法对epsilon值的定义和选取、Minpts值的设置是很敏感的!
二、基于DBSCAN的Iris数据集聚类实践
2.1 关于Iris数据集
该数据集也叫鸢尾花卉数据集,数据集包含150个样本,分三类,每类50个数据,每个数据有4个属性(所以该数据集大小为150*4的矩阵):分别是花萼长度、花萼宽度、花瓣长度、花瓣宽度。我们需要基于这四个属性来对数据聚类。该数据集以及UCI提供的其它可聚类用数据集我一并打包在后续的代码和数据链接中了,本章对Iris数据集进行聚类实践,读者也可以参考本章的方法对其它数据集进行聚类实践。
将数据导入Matlab,并画出这150组数据:
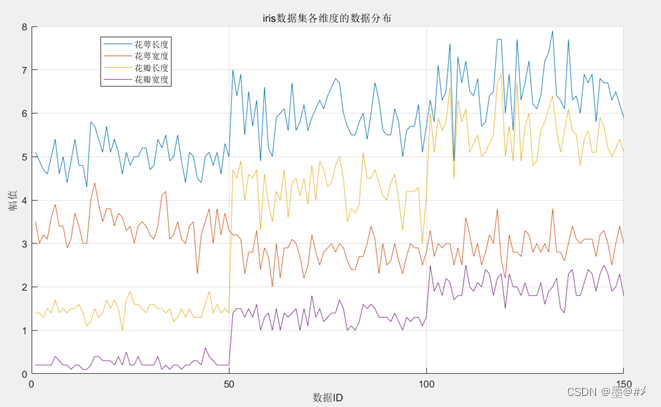
图2.1 Iris数据集展示
从图中可以看到,花萼长度、花瓣长度以及花瓣宽度这三个属性还是能看到比较明显的三个类别的(呈比较明显的阶梯状分布)!我们可以将这三个属性值相加以更加突出其区别:
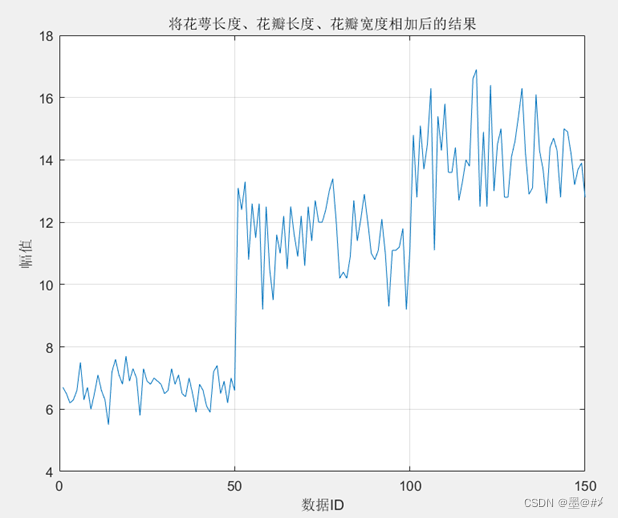
图2.2 将三个属性值相加后的结果
我们此时其实可以设计特定的epsilon值来对各样本点进行归类了!我们还可以从各属性值的统计规律中找到一些其它的可用于辅助分类的特征?(这里只画出其统计特征,不做更多讨论。) 各属性值的直方图以及概率密度分布图如下所示:
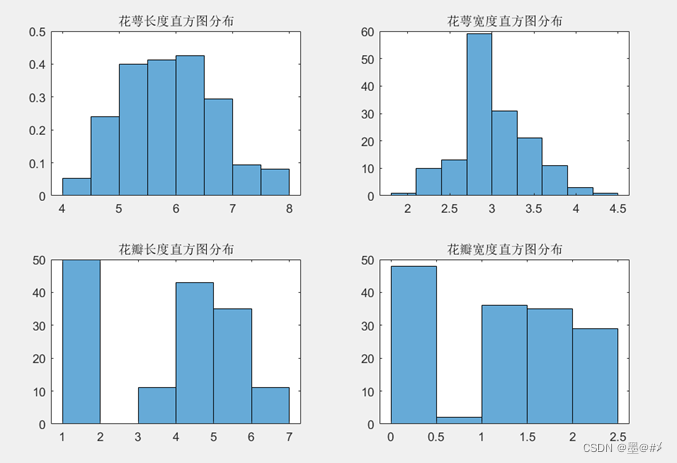
图2.3 Iris数据集各属性值的分布(1)
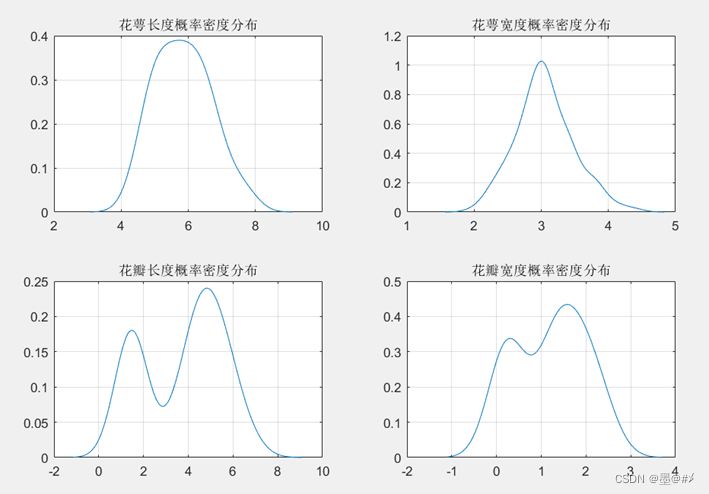
图2.4 Iris数据集各属性值的分布(2)
我们可以从上面几幅图中构思一些分类的解决方案。不过本章的聚类还是使用别的方法:数据降维。 数据降维顾名思义就是把高维数据降成低维的,Iris数据集中数据(单个样本点)是四维的,四维的数据我们是无法直观展示的,上面几张图我都是只拿出各样本点的一维进行画图。数据降维、(数据的归一化、标准化)是机器学习等领域对数据预处理最基本同时也很重要的手段,关于该话题我后续可能会出相关的博文进行介绍,不过在本文中暂不对这些概念和手段做深究,读者可以看看参考资料[3][4]。
本章我直接使用Matlab自带的tsne函数对Iris数据集进行降维(降成二维数据)。(t-SNE(t-distributed stochastic neighbor embedding)是用于降维的一种机器学习算法,t-SNE 是一种非线性降维算法,非常适用于高维数据降维到2维或者3维进行可视化。降维后的结果如下:
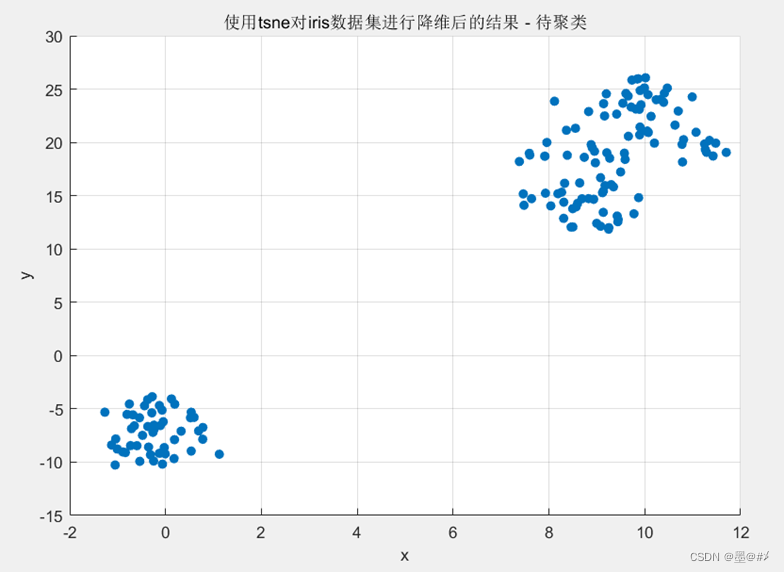
图2.5 对Iris数据集进行降维后的结果
此时数据变成了二维平面内的点簇形数据(我们可以直接基于相对距离进行聚类了)! 需要注意的是:使用tsne对数据降维的结果前后并不一定是一样的)。从图中可以看到两个明显分离的点簇,右上角的点簇细看似乎也可以分成两个,Iris数据集给每个点都有一个预设的分类,这里再基于上图画出其原始的分类:
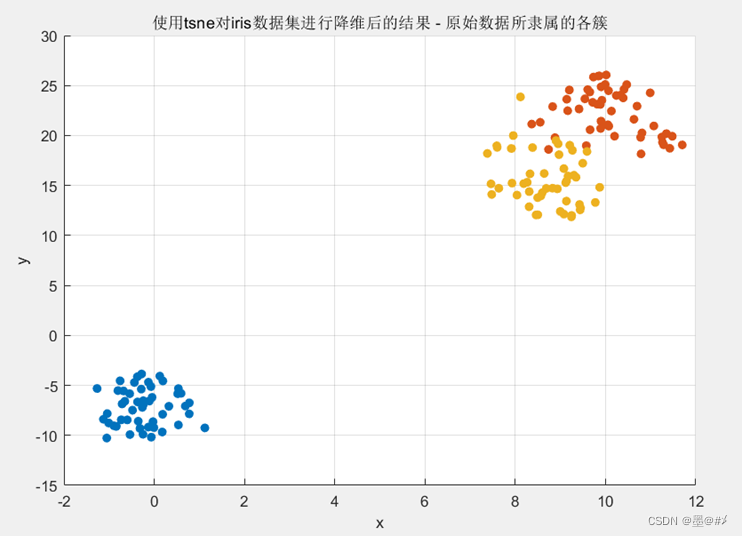
图2.6 降维后的Iris数据集各点所属分类
我们期望使用DBSCAN或者K-means后可以得到与图2.6一样的聚类效果。
2.2 基于DBSCAN算法的处理结果
在本次仿真中,我将epsilon设置为1.05,Minpts设置为4,得到聚类后的结果如下:
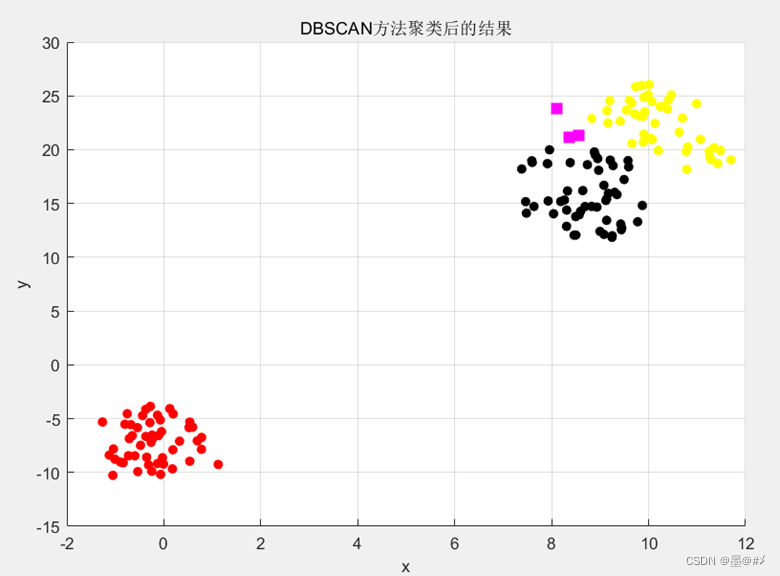
图2.7 DBSCAN聚类后的结果
(注:这里横纵坐标的刻度值不一样)
从上图的结果来看,DBSCAN算法将前述数据也聚成了三个簇,此外还包括三个噪声点(品红色矩形方块)。将之与2.6对比,基本达到了预期的效果。计算该聚类结果的各评价指标得到:

图2.8 聚类结果的客观评价指标计算结果
【为方便与K-means算法比较,我在代码中对两聚类算法使用的是同一组数据】
读者可以结合博文[3]的结果、以及博文[1]中对这几个客观评价指标的描述做一些更深入的对比和分析。
三、基于DBSCAN的自生成二维平面点簇数据集聚类实践
3.1 二维平面点簇生成结果
关于二维平面点簇的介绍我在博文[1]中已经有过说明,这里不再赘述。和[1]中同样的参数设计下,生成的点簇如下图所示:
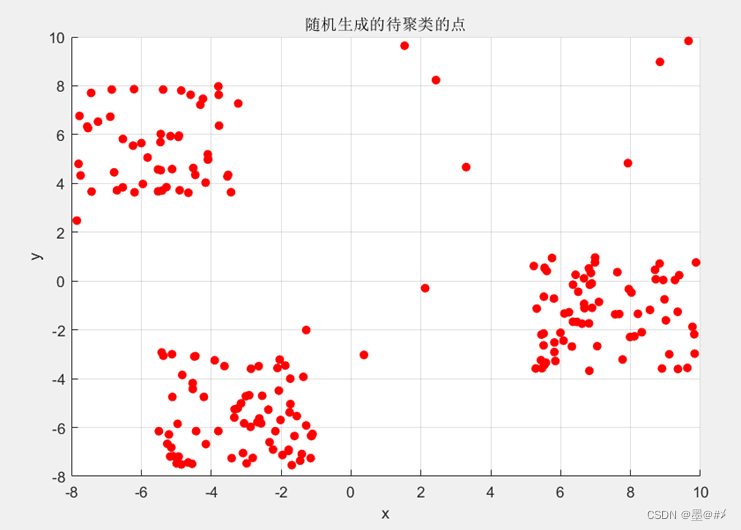
图3.1 随机生成的待聚类点簇
原始点的各所属分类如下:
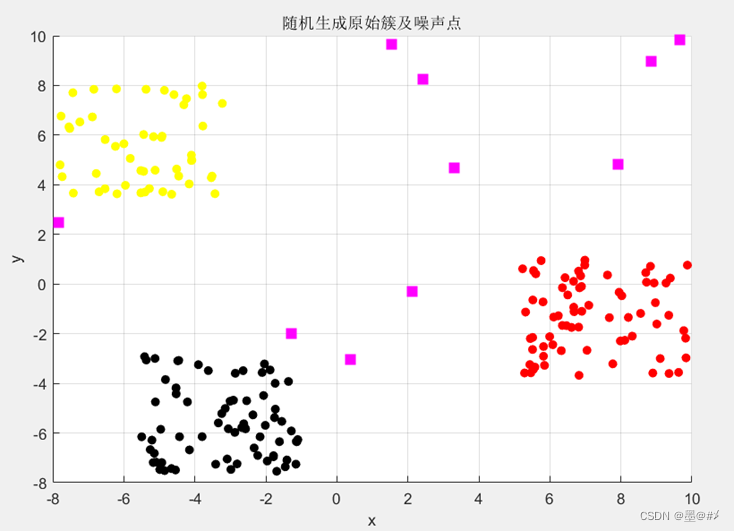
图3.2 随机生成的点簇各点的所属分类示意图
图中,三种不同颜色的圆点对应三个簇,品红色的矩形方块对应噪声点。在后续的聚类实践中,我们期望聚类的结果应尽可能与本图展示的一致。
3.2 基于DBSCAN算法的处理结果
仿真中预设epsilon值为1.16,Minpts值为3,得到的聚类结果如下:
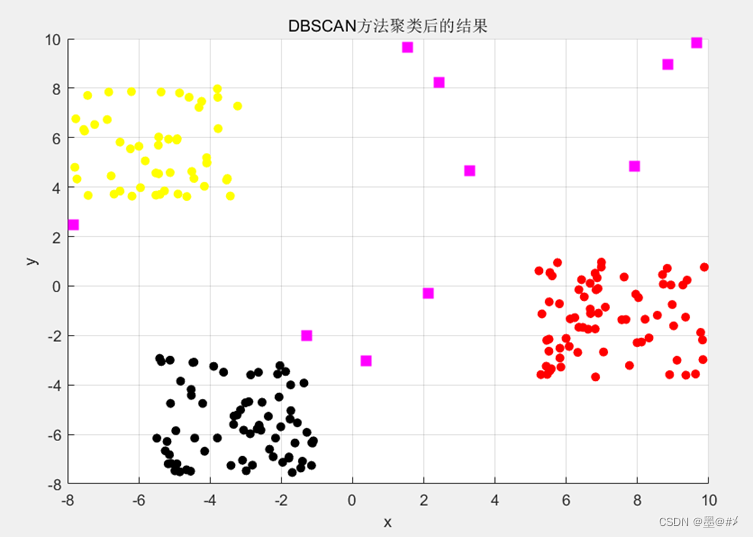
图3.3 DBSCAN聚类结果
对比图3.2可知,聚类完全达到了理想的效果。并进一步计算聚类结果的客观评价指标如下:

图3.4 DBSCAN聚类结果的客观评价指标计算结果
【为方便与K-means算法比较,我在代码中对两聚类算法使用的是同一组数据】
读者可以结合博文[3]的结果、以及博文[1]中对这几个客观评价指标的描述做一些更深入的对比和分析。
四、总结
本文对DBSCAN算法进行了实践。首先对DBSCAN算法进行了介绍,给出了其典型的算法流程图、对其涉及的两个核心概念:邻域半径和最小样本数进行了介绍,并以车载雷达数据处理为例对这两概念做了更深入的探讨。随后比较详尽地介绍了Iris数据集,并分别给出了基于DBSCAN算法对Iris数据集、自己生成的二维平面点簇形数据集的聚类结果。
五、参考资料
[1] (毫米波雷达数据处理中的)聚类算法(1) --- 概述-CSDN博客
[2] 20分钟学会DBSCAN - 知乎 (zhihu.com)
[3] (毫米波雷达数据处理中的)聚类算法(3) – K-means算法及其实践-CSDN博客
[4] 知识干货-机器学习-TSNE数据降维 - 知乎 (zhihu.com)
[5] 数据预处理:归一化和标准化 - 知乎 (zhihu.com)
六、参考代码与数据集
我将本聚类算法系列的三篇博文所涉及的代码和数据集打包成了一份,其内含如下内容:
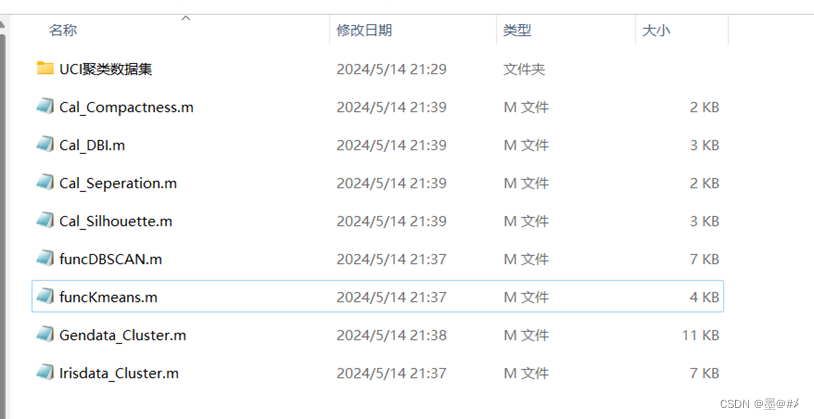
图中,UCI聚类数据集包含了多个可用于聚类算法实践的数据集;前四个m文件为[1]中第4章所介绍的四种客观评价指标的计算函数;funcDBSCAN为基于DBSCAN算法的聚类函数,funcKmeans为基于K-means算法的聚类函数;Gendata_Cluster.m为主函数,该函数首先生成点簇数据集,然后分别调用funcDBSCAN.m、funcKmeans.m完成聚类以及聚类结果的展示,最后再分别调用前面的四个客观指标计算函数完成客观评价指标的计算;Irisdata_Cluster.m则是另一个主函数,该函数获取UCI的Iris数据集,并对该数据集做一些处理(包括降维),随后和Gendata_Cluster.m函数一样,完成聚类、客观指标计算等流程。读者可以自行下载参考,链接为(抱歉,要收费):
(毫米波雷达数据处理中的)聚类算法系列博文对应的代码和数据集资源-CSDN文库