在Pandas中,
factorize()函数主要用于将分类变量转换为整数编码,这对于减少内存使用或准备数据进行某些统计分析非常有用。它实际上是将列的唯一值映射到从0开始的整数序列上。
假设有一个DataFrame,其中一列包含一些类别值,你希望将这些类别值替换为从0开始的整数序号,这可以看作是一种“重新命名”的方式。
以下是一个例子:
一、准备数据
import pandas as pd# 示例数据
data = {'Category': ['Apple', 'Banana', 'Cherry', 'Apple', 'Banana', 'Cherry']}
df = pd.DataFrame(data)print("Original DataFrame:")
df
二、对Categoey列进行整数编码
# 使用 factorize() 函数对 'Category' 列进行整数编码
# factorize 返回两个值:一个是编码后的Series,另一个是原始类别的数组,这里我们只需要第一个
df['Category'] = pd.factorize(df['Category'])[0]df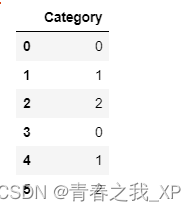
在这个例子中,原始的
DataFrame有一列名为Category,包含苹果(Apple)、香蕉(Banana)和樱桃(Cherry)三种水果的名称。使用
pd.factorize()后,这一列的每个唯一字符串值被替换为一个整数:'Apple'变为0,'Banana'变为1,'Cherry'变为2。这样一来,虽然列名没有变,但列中的数据被赋予了新的、连续的整数标识,这在某些数据分析场景下非常有用。



![[自动化]pyautogui的使用](https://img-blog.csdnimg.cn/direct/c7b55e1cd56f4d278613d4719c8b8ee6.png)

