文章目录
- 一、关于 Mixtral
- Mistral AI、 La Plateforme
- Mistral AI LLMs
- 二、Mistral AI API
- 账户设置
- 三、Mixtral 说明
- 通过稀疏架构推动开放模型的前沿
- 表现
- Instructed 模型
- 使用开源部署堆栈部署 Mixtral
- 在我们的平台上使用 Mixtral。
一、关于 Mixtral
- 官网:https://mistral.ai/news/mixtral-of-experts/
- 官方文档:https://docs.mistral.ai
- github : https://github.com/mistralai
- paper : Mixtral of Experts
https://arxiv.org/abs/2401.04088
Mistral AI、 La Plateforme
Mistral AI 是一个研究实验室,致力于构建世界上最好的开源模型。 La Plateforme 使开发人员和企业能够在 Mistral 的开源和商业法学硕士的支持下构建新产品和应用程序。
Mistral AI LLMs
开源
- Mistral 7b, our first dense model released September 2023
- Mixtral 8x7b, our first sparse mixture-of-experts released December 2023
- Mixtral 8x22b, our best open source model to date released April 2024
商业
- Mistral Small, our cost-efficient reasoning model for low-latency workloads
- Mistral Medium, useful for intermediate tasks that require moderate reasoning; please note that this model will be deprecated in the coming months
- Mistral Large, our top-tier reasoning model for high-complexity tasks
- Mistral Embeddings, our state-of-the-art semantic for extracting representation of text extracts
价格 : https://mistral.ai/technology/#pricing
| Model | Available Open-weight | Available via API | Description | Max Tokens | API Endpoints |
|---|---|---|---|---|---|
| Mistral 7B | ✔️ | ✔️ | The first dense model released by Mistral AI, perfect for experimentation, customization, and quick iteration. At the time of the release, it matched the capabilities of models up to 30B parameters. Learn more on our blog post | 32k | open-mistral-7b |
| Mixtral 8x7B | ✔️ | ✔️ | A sparse mixture of experts model. As such, it leverages up to 45B parameters but only uses about 12B during inference, leading to better inference throughput at the cost of more vRAM. Learn more on the dedicated blog post | 32k | open-mixtral-8x7b |
| Mixtral 8x22B | ✔️ | ✔️ | A bigger sparse mixture of experts model. As such, it leverages up to 141B parameters but only uses about 39B during inference, leading to better inference throughput at the cost of more vRAM. Learn more on the dedicated blog post | 64k | open-mixtral-8x22b |
| Mistral Small | ✔️ | Suitable for simple tasks that one can do in bulk (Classification, Customer Support, or Text Generation) | 32k | mistral-small-latest | |
| Mistral Medium (will be deprecated in the coming months) | ✔️ | Ideal for intermediate tasks that require moderate reasoning (Data extraction, Summarizing a Document, Writing emails, Writing a Job Description, or Writing Product Descriptions) | 32k | mistral-medium-latest | |
| Mistral Large | ✔️ | Our flagship model that’s ideal for complex tasks that require large reasoning capabilities or are highly specialized (Synthetic Text Generation, Code Generation, RAG, or Agents). Learn more on our blog post | 32k | mistral-large-latest | |
| Mistral Embeddings | ✔️ | A model that converts text into numerical vectors of embeddings in 1024 dimensions. Embedding models enable retrieval and retrieval-augmented generation applications. It achieves a retrieval score of 55.26 on MTEB. | 8k | mistral-embed |
二、Mistral AI API
Mistral AI API通过以下方式为 LLM 应用程序提供支持:
- 文本生成,支持流式传输并提供实时显示部分模型结果的能力
- Embeddings,对于 RAG 很有用,它将文本的含义表示为数字列表
- 函数调用,使 Mistral 模型能够连接到外部工具
- JSON模式,开发者可以将响应格式设置为json_object
- Guardrailing使开发人员能够在 Mistral 模型的系统级别实施策略
安装
pip install mistralai
Python Client 详情可见:https://github.com/mistralai/client-python
Mistral AI API 为开发人员提供了一种无缝方式,只需几行代码即可将 Mistral 最先进的模型集成到他们的应用程序和生产工作流程中。
API 目前可通过La Platform获取。您需要激活帐户中的付款才能启用 API 密钥。几分钟后,您将能够使用我们的chat端点:
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessageapi_key = os.environ["MISTRAL_API_KEY"]
model = "mistral-large-latest"client = MistralClient(api_key=api_key)chat_response = client.chat(model=model,messages=[ChatMessage(role="user", content="What is the best French cheese?")]
)print(chat_response.choices[0].message.content)
要使用 Mistral AI 的嵌入 API 生成文本嵌入,我们可以向 API 端点发出请求并指定嵌入模型mistral-embed,同时提供输入文本列表。
然后,API 将以数值向量的形式返回相应的嵌入,可用于 NLP 应用程序中的进一步分析或处理。
from mistralai.client import MistralClientapi_key = os.environ["MISTRAL_API_KEY"]
model = "mistral-embed"client = MistralClient(api_key=api_key)embeddings_response = client.embeddings(model=model,input=["Embed this sentence.", "As well as this one."]
)print(embeddings_response)
有关 API 上提供的模型的完整描述,请前往**模型文档**。
账户设置
- 首先,创建一个 Mistral 帐户或登录 console.mistral.ai。
- 然后,导航至
Workspace和Billing以添加您的付款信息并激活您帐户上的付款。 - 之后,转到
API keys页面并通过单击Create new key来创建新的 API 密钥。请务必复制 API 密钥并安全保存,并且不要与任何人共享。
三、Mixtral 说明
Mistral AI 继续履行为开发者社区提供最佳开放模型的使命。人工智能的发展需要采取新的技术变革,而不仅仅是重用众所周知的架构和训练范例。最重要的是,它需要使社区从原始模型中受益,以促进新的发明和用途。
今天,该团队很自豪地发布 Mixtral 8x7B,这是一种具有开放权重的高质量稀疏专家混合模型 (SMoE)。根据 Apache 2.0 许可。 Mixtral 在大多数基准测试中都优于 Llama 2 70B,推理速度提高了 6 倍。它是最强大的开放权重模型,具有宽松的许可证,也是成本/性能权衡方面的最佳模型。特别是,它在大多数标准基准测试中匹配或优于 GPT3.5。
Mixtral 具有以下功能。
- 它可以优雅地处理 32k 令牌的上下文。
- 它可以处理英语、法语、意大利语、德语和西班牙语。
- 它在代码生成方面表现出强大的性能。
- 它可以微调为指令跟踪模型,在 MT-Bench 上获得 8.3 分。
通过稀疏架构推动开放模型的前沿
Mixtral 是一个稀疏的专家混合网络。它是一个纯解码器模型,其中前馈块从一组 8 个不同的参数组中进行选择。在每一层,对于每个令牌,路由器网络选择其中的两个组(“专家”)来处理令牌并相加地组合它们的输出。
该技术增加了模型的参数数量,同时控制了成本和延迟,因为该模型仅使用每个令牌总参数集的一小部分。具体来说,Mixtral 共有 46.7B 个参数,但每个代币仅使用 12.9B 个参数。因此,它以与 12.9B 模型相同的速度和相同的成本处理输入并生成输出。
Mixtral 根据从开放网络提取的数据进行了预训练——我们同时训练专家和路由器。
表现
我们将 Mixtral 与 Llama 2 系列和 GPT3.5 基础模型进行比较。 Mixtral 在大多数基准测试中均匹配或优于 Llama 2 70B 以及 GPT3.5。
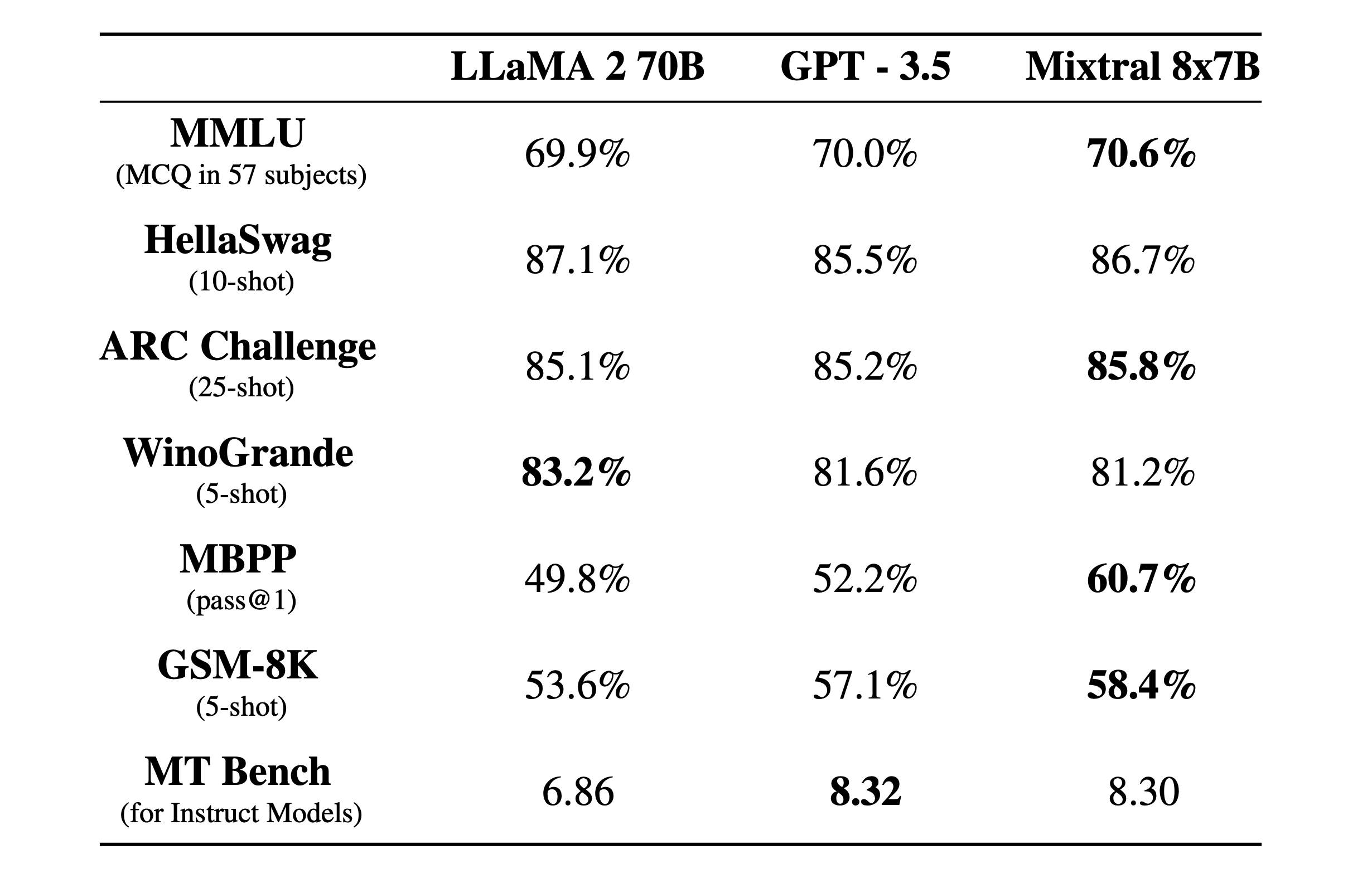
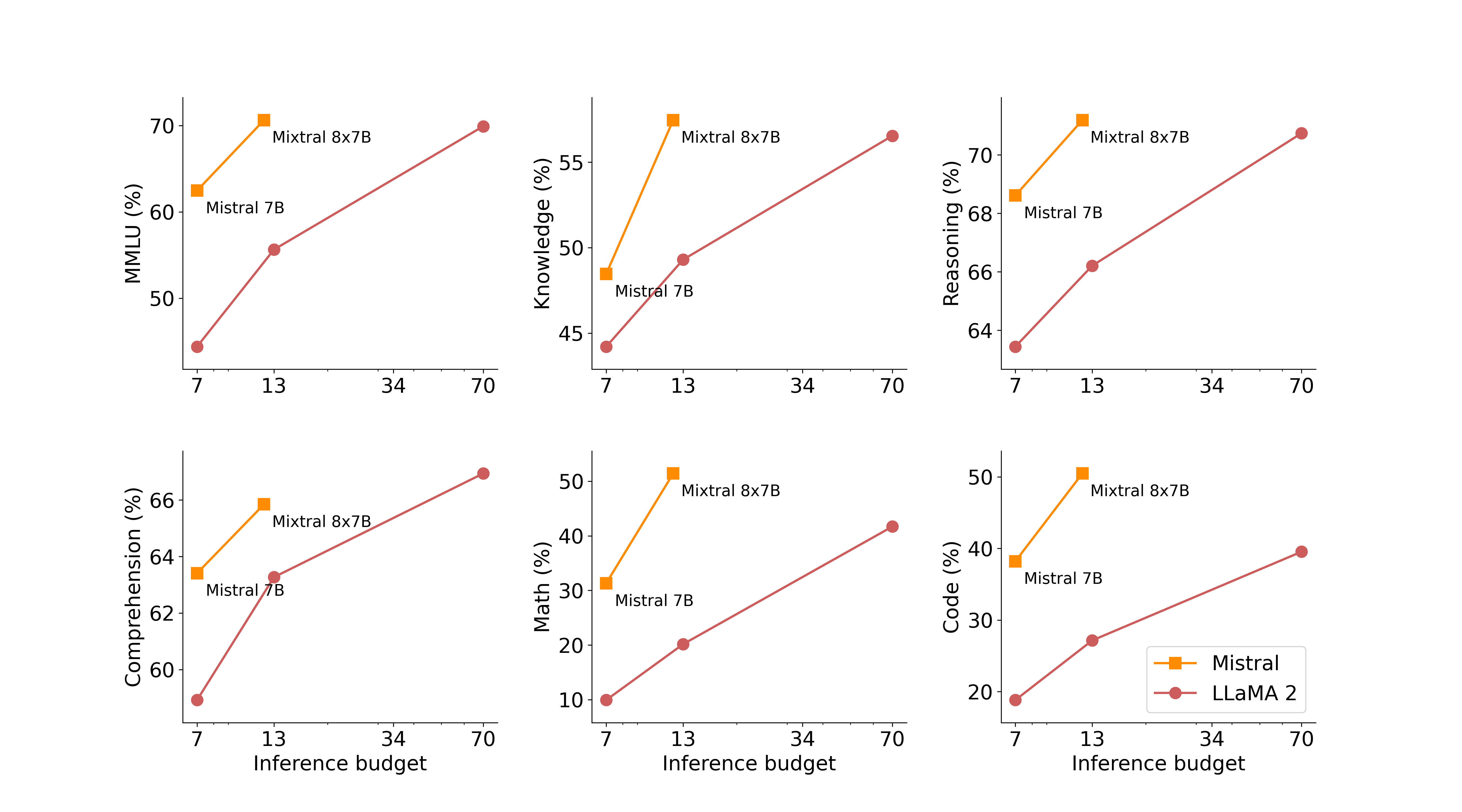
在下图中,我们衡量了质量与推理预算的权衡。与 Llama 2 型号相比,Mistral 7B 和 Mixtral 8x7B 属于高效型号系列。
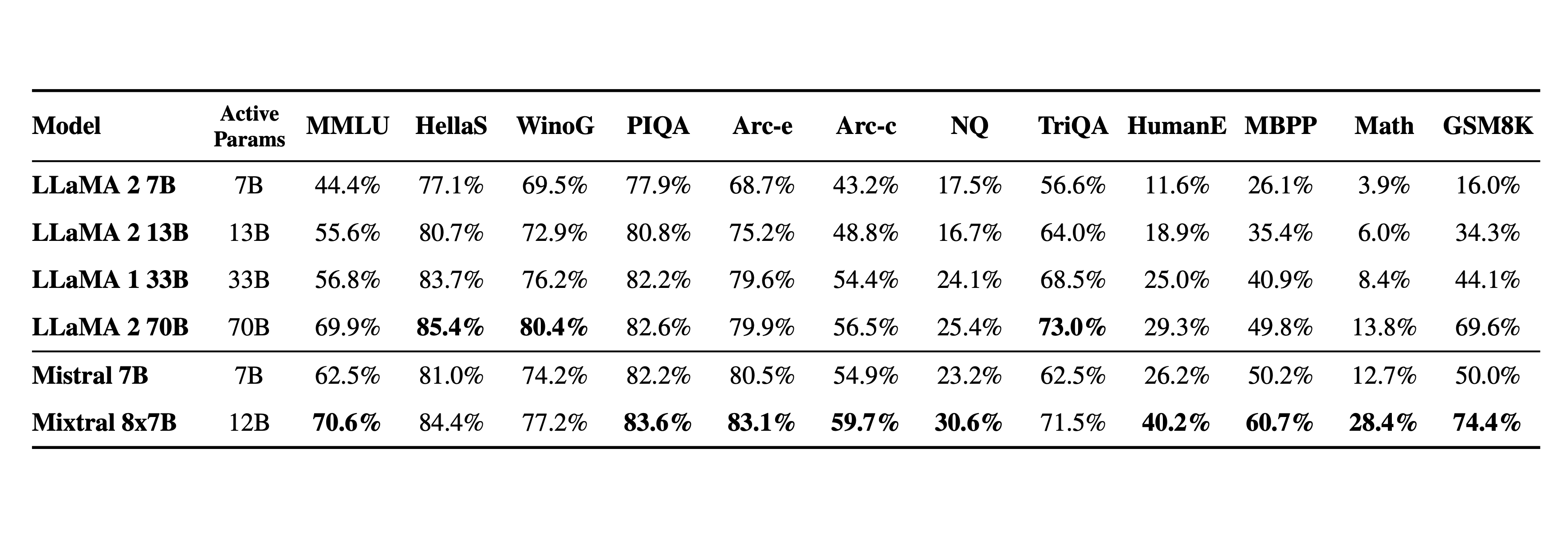
下表给出了上图的详细结果。
**幻觉和偏见。**为了识别可能的缺陷,通过微调/偏好建模来纠正,我们测量了 BBQ/BOLD 上的基本模型性能。
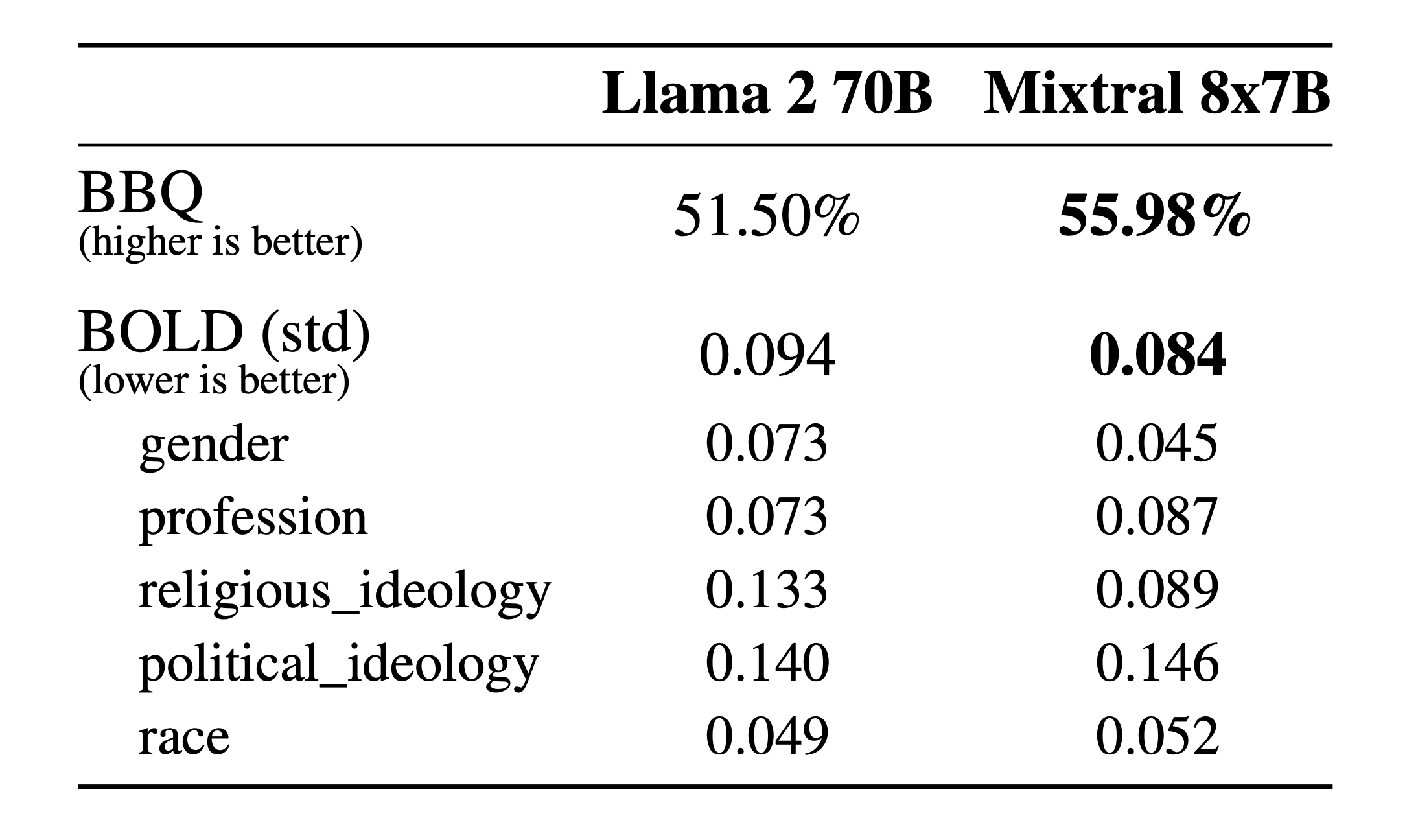
与 Llama 2 相比,Mixtral 对 BBQ 基准的偏差较小。总体而言,Mixtral 在 BOLD 上比 Llama 2 显示出更积极的情绪,每个维度内的差异相似。
语言。 Mixtral 8x7B 精通法语、德语、西班牙语、意大利语和英语。

Instructed 模型
我们与 Mixtral 8x7B 一起发布了 Mixtral 8x7B Instruct。该模型已通过监督微调和直接偏好优化 (DPO) 进行优化,以仔细遵循指令。在MT-Bench上,它达到了8.30的分数,使其成为最好的开源模型,性能可与GPT3.5相媲美。
注意:可以优雅地提示 Mixtral 禁止构建需要严格审核的应用程序的某些输出,如此处所示。适当的偏好调整也可以达到此目的。请记住,如果没有这样的提示,模型将仅遵循给出的任何指示。
使用开源部署堆栈部署 Mixtral
为了使社区能够使用完全开源的堆栈运行 Mixtral,我们已提交对 vLLM 项目的更改,该项目集成了 Megablocks CUDA 内核以实现高效推理。
Skypilot 允许在云中的任何实例上部署 vLLM 端点。
在我们的平台上使用 Mixtral。
目前,我们在端点mistral-small后面使用 Mixtral 8x7B ,该端点已在 beta 版中提供。注册即可尽早访问所有生成和嵌入端点。
2024-05-14(二)