文章目录
- 锁机制的应用
- 1.实验目标
- 2.实验过程记录
- (1).阅读kernel/kalloc.c
- (2).理解xv6的自旋锁工作原理
- (3).阅读kernel/bio.c
- (4).阅读kernel/sleeplock.c
- (5).重新设计内存分配器
- (6).重新设计磁盘缓存
- 3.问题及解决方案
- 问题1
- 问题2
- 问题3
- 实验小结
锁机制的应用
1.实验目标
基于xv6内核已经提供的锁机制,完成xv6内核中内存分配器和磁盘缓存的重新设计,尽可能减少CPU内存分配和磁盘缓存中出现的竞争问题,从而提升效率。
2.实验过程记录
(1).阅读kernel/kalloc.c
操作内容:在VS Code中查看并理解kernel/kalloc.c
struct {struct spinlock lock;struct run *freelist;
} kmem;
首先是kmem结构体,这个结构体实际上规定了内存的空闲链表,它用于管理xv6内核中的物理内存页,每一页的大小为4096字节。
而kmem本身是上锁的,也就是说:所有的CPU共享一个唯一的空闲链表,这个链表中存储了若干个页,每一页都是可以被直接使用的,后续如果尝试分配一个物理页,则从链表头中取走一页;如果尝试释放一个物理页,则将归还的内存页放到链表头上即可。
这样一来,kmem上锁的必要性就已经明确了,如果不上锁,这个空闲链表可能在分配的时候有多个CPU抢占同一页内存;在归还的时候可能因为Race Condition导致有的页被覆盖掉,从而彻底丢失了对于某一页内存的管理,因此上锁是有必要的,接下来看一看kinit函数的实现细节:
void
kinit()
{initlock(&kmem.lock, "kmem");freerange(end, (void*)PHYSTOP);
}
kinit函数只做两件事,首先是初始化空闲链表的锁,然后是调用freerange函数,并且传入end和PHYSTOP两个参数,我们首先看一看freerange的定义:
void
freerange(void *pa_start, void *pa_end)
{char *p;p = (char*)PGROUNDUP((uint64)pa_start);for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)kfree(p);
}
它的定义相当简单,实际上就是利用已经实现的kfree函数,完成内存的分页初始化操作,实际上就是将从初始内存地址到结束内存地址进行页面的划分,划分完之后将每一页内存都直接调用kfree函数加入到空闲链表当中,这样一来就可以完成空闲链表和分页内存管理的初始化了,一开始在kinit调用freerange时传入的end和(void*)PHYSTOP分别在kalloc.c的首部以及memlayout.h头文件当中有定义:
// FILE kalloc.c
extern char end[]; // first address after kernel.// defined by kernel.ld.
// FILE memlayout.h
// the kernel expects there to be RAM
// for use by the kernel and user pages
// from physical address 0x80000000 to PHYSTOP.
#define KERNBASE 0x80000000L
#define PHYSTOP (KERNBASE + 128*1024*1024)
这二者的定义也比较简单,end是一个数组,它实际上位于内核空间之后的首个地址,会在kernel.ld中定义;而PHYSTOP则是在memlayout.h当中定义的物理内存的最大内存地址,实际上就是在KERNBASE的基础上增加了128MB的位置。因此xv6会在内核初始化的时候,直接初始化128MB的内存空间进行分页管理操作。
之后再来看看kfree函数,这个函数用于内核层级的归还一页内存操作:
// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void
kfree(void *pa)
{struct run *r;if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)panic("kfree");// Fill with junk to catch dangling refs.memset(pa, 1, PGSIZE);r = (struct run*)pa;acquire(&kmem.lock);r->next = kmem.freelist;kmem.freelist = r;release(&kmem.lock);
}
它的操作也很简单,首先是判断归还的内存地址是合法,确定合法之后获取空闲链表的锁,之后将内存作为一个结点插入到kmem的头部,然后就完成了内存归还的操作,这个操作还是相当简单的。
(2).理解xv6的自旋锁工作原理
操作内容:在VS Code中查看并理解kernel/spinlock.c
首先观察spinlock结构体的定义,它位于kernel/spinlock.h当中:
// Mutual exclusion lock.
struct spinlock {uint locked; // Is the lock held?// For debugging:char *name; // Name of lock.struct cpu *cpu; // The cpu holding the lock.
#ifdef LAB_LOCKint nts;int n;
#endif
};
这是一个相当简单的实现,它有一个数字用于记录是否被持有,以及用于debug的锁名称和占有锁的CPU信息,这一次实验因为是锁机制的应用,因此还有nts和n两个参数用于完成后续的测试工作。
接下来看一看对于任意自旋锁的初始化是如何完成的:
void
initlock(struct spinlock *lk, char *name)
{lk->name = name;lk->locked = 0;lk->cpu = 0;
#ifdef LAB_LOCKlk->nts = 0;lk->n = 0;findslot(lk);
#endif
}
初始化的操作也很简单,就是将对应的内容放到对应的位置上,并且也因为本次实验有了新的字段,因此在初始化的时候需要进行findslot的操作,此时实际上是尝试从锁列表中找到一个目前没有被使用到的锁,从而赋值给lk,这相当于是构建了一个自旋锁池,可以减少对于自旋锁的分配,从而提升效率(可能也有其他用途),这个实现与并发编程中的线程池、网络编程中的连接池等等都是相当类似的。
接下来是acquire,这也是自旋锁最关键的一个实现,它用于尝试获取一把自旋锁,正如其名,自旋锁会循环地测试并尝试获取这把锁:
// Acquire the lock.
// Loops (spins) until the lock is acquired.
void
acquire(struct spinlock *lk)
{push_off(); // disable interrupts to avoid deadlock.if(holding(lk))panic("acquire");
#ifdef LAB_LOCK__sync_fetch_and_add(&(lk->n), 1);
#endif // On RISC-V, sync_lock_test_and_set turns into an atomic swap:// a5 = 1// s1 = &lk->locked// amoswap.w.aq a5, a5, (s1)while(__sync_lock_test_and_set(&lk->locked, 1) != 0) {
#ifdef LAB_LOCK__sync_fetch_and_add(&(lk->nts), 1);
#else;
#endif}// Tell the C compiler and the processor to not move loads or stores// past this point, to ensure that the critical section's memory// references happen strictly after the lock is acquired.// On RISC-V, this emits a fence instruction.__sync_synchronize();// Record info about lock acquisition for holding() and debugging.lk->cpu = mycpu();
}
它的操作步骤大概是这样的:首先关中断避免死锁,这个原因已经在之前的实验报告中解释过了(如果拿到锁之后发生了一次中断,刚才执行的程序会带着锁进入休眠,而中断处理程序此时无法获得锁,但是中断处理程序在没有获得锁之前无法直接回到先前运行的程序,此时二者之间就发生了死锁),并且会通过push_off函数完成一次关中断堆栈的插入操作,这个在Lab2中实际上是有体现的。
之后会判断这把锁是否已经被当前的CPU所占有,这个判断是很明显的,因为如果是别的CPU占有同一把锁,那还可以等待其他CPU释放,但如果是同一个CPU占有,那么该CPU在此忙等待是不可能等到另一个进程将这把锁释放的,因此在这里会直接panic。
之后就是获取锁的关键步骤,自旋锁的实现基于TSL完成,也就是会在while循环之下不停地尝试将锁的值替换为1,如果成功了,那么也就成功获取到了锁。对于新定义的两个字段,也增加了对应的自增操作,不过这里也需要使用__sync_fetch_and_add()完成原子自增操作。
之后还要调用__sync_synchronize()调用GCC编译器预定义的屏障指令来避免GCC对load和store指令进行位置调整,因此load和store的位置调整可能引发严重的问题,先前我尝试过在开启-O3优化的情况下对一个没有采用屏障的Peterson解决方案代码进行测试,最后发现在一些测试当中,编译优化导致的指令乱序的确会导致Peterson算法的实现出现问题,因此在这里必须使用__sync_synchronize()来保证指令的编译前与编译后一致性。而__sync_synchronize()实际上也是一条内联汇编指令,因为在不同的指令集下屏障的代码并不一致,为了方便程序员进行使用所以在后来GCC编译器增加了这一条指令方便进行统一的操作。
在完成了上述的所有操作之后,会最后将当前的CPU信息传给锁,这样就完成了整个锁的获取过程,它使用了关中断、TSL、原子指令和内存屏障等等方式来严格保障整个加锁期间不会出现数据竞争问题。由于释放锁的操作类似,这里就不再过多阐述了。
(3).阅读kernel/bio.c
操作内容:在VS Code中查看并理解kernel/bio.c
bio.c这个文件中定义了利用链表管理的缓冲区,其中定义的bcache是比较关键的,它的结构体定义如下:
struct {struct spinlock lock;struct buf buf[NBUF];// Linked list of all buffers, through prev/next.// Sorted by how recently the buffer was used.// head.next is most recent, head.prev is least.struct buf head;
} bcache;
它其中也包含了一把锁,之后还包含了一个利用静态数组buf组成的双向链表,每一次尝试读入或写出一个磁盘块的时候,都会将内容放到一个内存的缓存块当中,然后利用lock来保障数据并发访问的安全性。
我们可以在kernel/buf.h当中找到struct buf的定义:
struct buf {int valid; // has data been read from disk?int disk; // does disk "own" buf?uint dev;uint blockno;struct sleeplock lock;uint refcnt;struct buf *prev; // LRU cache liststruct buf *next;uchar data[BSIZE];
};
前面是一部分缓冲区对应磁盘的具体信息,之后是双向链表的前一个结点指针和后一个结点指针,最后使用data字段静态数组来保存缓冲区存储的真实数据内容。
回到bio.c当中,binit函数完成了对于这个循环双向链表的构建:
void
binit(void)
{struct buf *b;initlock(&bcache.lock, "bcache");// Create linked list of buffersbcache.head.prev = &bcache.head;bcache.head.next = &bcache.head;for(b = bcache.buf; b < bcache.buf+NBUF; b++){b->next = bcache.head.next;b->prev = &bcache.head;initsleeplock(&b->lock, "buffer");bcache.head.next->prev = b;bcache.head.next = b;}
}
其实也是比较简单的,就是首先初始化锁,然后将每个结点都连到对应的前一个结点以及后一个结点上,而head结点实际上是链表的头结点,为了更加便于链表的操作,因此在bcache中定义了一个唯一的head结点用于后续的管理,可以看到这里构建链表采取头插的方式,每一次将结点插在head结点的后面。
之后是bread函数,上层文件系统读取磁盘的时候会调用bread完成磁盘→内存缓冲区的操作:
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{struct buf *b;b = bget(dev, blockno);if(!b->valid) {virtio_disk_rw(b, 0);b->valid = 1;}return b;
}
这个函数比较简单,它首先会使用bget函数获取到对应设备、对应块号的缓存块,它(bget函数)的定义如下:
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{struct buf *b;acquire(&bcache.lock);// Is the block already cached?for(b = bcache.head.next; b != &bcache.head; b = b->next){if(b->dev == dev && b->blockno == blockno){b->refcnt++;release(&bcache.lock);acquiresleep(&b->lock);return b;}}// Not cached.// Recycle the least recently used (LRU) unused buffer.for(b = bcache.head.prev; b != &bcache.head; b = b->prev){if(b->refcnt == 0) {b->dev = dev;b->blockno = blockno;b->valid = 0;b->refcnt = 1;release(&bcache.lock);acquiresleep(&b->lock);return b;}}panic("bget: no buffers");
}
bget函数完成了获取数据的全部操作,如果缓存命中,则直接将对应的块return给调用者;否则的话会利用LRU策略清理掉缓存块,并且将对应的块放回给调用者。
剩余的bwrite、brelse、bpin和bunpin几个函数也是类似的写入磁盘、释放块和增加减少引用计数操作,这里就不过多赘述,Buffer Cache通过这一系列操作完成了内存和硬盘之间中间区的构建。
(4).阅读kernel/sleeplock.c
操作内容:在VS Code中查看并理解kernel/sleeplock.c
首先是阅读sleeplock.h中对于sleeplock锁的定义:
// Long-term locks for processes
struct sleeplock {uint locked; // Is the lock held?struct spinlock lk; // spinlock protecting this sleep lock// For debugging:char *name; // Name of lock.int pid; // Process holding lock
};
sleeplock的结构体当中除了是否锁住的字段还有一个专门的自旋锁字段用于保障锁本身的实现,获取sleeplock的操作在sleeplock.c中实现:
void
acquiresleep(struct sleeplock *lk)
{acquire(&lk->lk);while (lk->locked) {sleep(lk, &lk->lk);}lk->locked = 1;lk->pid = myproc()->pid;release(&lk->lk);
}
获取sleeplock的过程是这样的:首先获取睡眠锁内部的自旋锁,在当前睡眠锁被锁定的时候,会调用sleep函数让当前睡眠锁在睡眠锁内部的自旋锁上睡眠并等待唤醒,sleep函数的定义如下:
// Atomically release lock and sleep on chan.
// Reacquires lock when awakened.
void
sleep(void *chan, struct spinlock *lk)
{struct proc *p = myproc();// Must acquire p->lock in order to// change p->state and then call sched.// Once we hold p->lock, we can be// guaranteed that we won't miss any wakeup// (wakeup locks p->lock),// so it's okay to release lk.if(lk != &p->lock){ //DOC: sleeplock0acquire(&p->lock); //DOC: sleeplock1release(lk);}// Go to sleep.p->chan = chan;p->state = SLEEPING;sched();// Tidy up.p->chan = 0;// Reacquire original lock.if(lk != &p->lock){release(&p->lock);acquire(lk);}
}
sleep的行为是:首先获取当前的进程,如果传入自旋锁并非进程锁时,需要获取进程锁再释放传入的自旋锁;否则就直接进行后续操作,让当前进程直接进入挂起态再直接调用sched()开始调度,在完成了sleep之后,将锁还原成之前的锁,所以如果这个流程传入睡眠锁,那么可以保证在挂起的状态当中,睡眠锁内真实发挥作用的自旋锁本身已经被释放了,因此持有睡眠锁的过程中是允许发生中断的。
但也正是因为睡眠锁开中断,因此睡眠锁不可被用于中断处理程序,中断处理程序本身不能被其他的中断所打断;同理,被自旋锁保护的临界区也不可以使用睡眠锁,睡眠锁会开中断并且还可能通过sleep让出CPU,此时就会导致进程带锁睡眠,从而导致死锁现象的产生。
(5).重新设计内存分配器
操作内容:修改空闲链表管理机制,重新设计内存分配器
首先直接在xv6内核中直接使用kalloctest进行测试,可以看到下面的结果:锁的fetch-and-add被多次调用,并且测试过程中也能发现时间非常长,最终的测试要求需要tot的值小于10,因此要完成这个任务,需要在目前的空闲链表机制上进行一些修改:
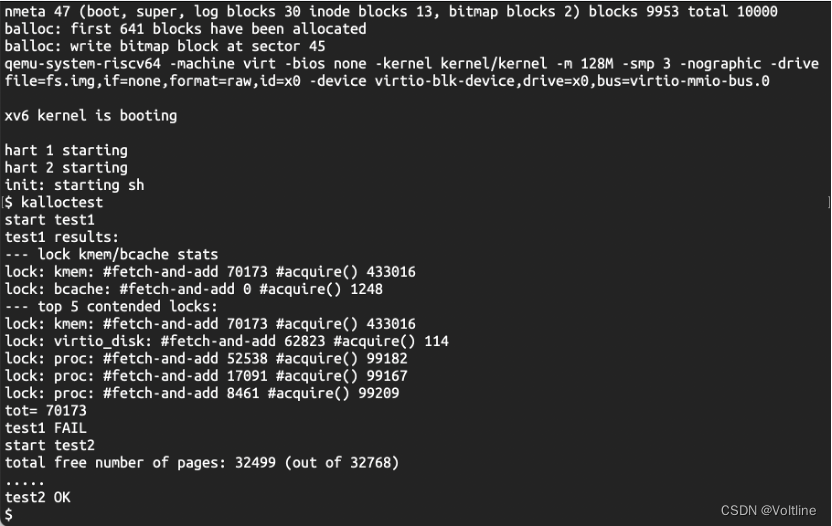
首先需要修改的是kmem和kinit两个部分:
struct {struct spinlock lock;struct run *freelist;
} kmem[NCPU];void
kinit()
{for (int i = 0; i < NCPU; i++) {initlock(&kmem[i].lock, "kmem");}freerange(end, (void*)PHYSTOP);
}
在这里将kmem变成了数组,并且在kinit的操作中直接对整个数组的每一个元素都初始化锁,这是因为在main.c中能够发现:只有CPU0可以完成页内存的初始化流程,因此需要一次性将所有的锁全部初始化完毕,后面的freerange操作的代码没有变动,本来我打算对每个CPU预先分配SIZE/NCPU大小的内存,但是发现这样可能会遇到一些边缘出现重叠的问题,并且实际上后续在分配页的时候,还是会涉及到steal的操作,因此不如直接就全部分配给CPU0,然后在后续CPU分配时没有页面的时候就直接去steal即可。
因此第二个部分就是修改freerange函数当中的kfree函数:
// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void
kfree(void *pa)
{struct run *r;if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)panic("kfree");// Fill with junk to catch dangling refs.memset(pa, 1, PGSIZE);
r = (struct run*)pa;push_off();int cpu = cpuid();
pop_off();acquire(&kmem[cpu].lock);r->next = kmem[cpu].freelist;kmem[cpu].freelist = r;release(&kmem[cpu].lock);
}
kfree函数中最大的修改就是最后一部分,首先关中断开中断获取当前的CPU号,之后将需要归还的内存直接加入到对应CPU的空闲链表当中即可。
之后是kalloc函数,这个修改需要结合一个新的函数steal_pages_from来完成,代码如下:
// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
void *
kalloc(void)
{
struct run *r;push_off();int cpu = cpuid();pop_off();acquire(&kmem[cpu].lock);r = kmem[cpu].freelist;if(r) {kmem[cpu].freelist = r->next;release(&kmem[cpu].lock);}else {int free_cpu_id;for (free_cpu_id = 0; free_cpu_id < NCPU; free_cpu_id++) {if (free_cpu_id == cpu) continue;acquire(&kmem[free_cpu_id].lock);if (kmem[free_cpu_id].freelist != 0) {r = steal_pages_from(free_cpu_id);release(&kmem[free_cpu_id].lock);break;}release(&kmem[free_cpu_id].lock);}release(&kmem[cpu].lock);}if(r)memset((char*)r, 5, PGSIZE); // fill with junkreturn (void*)r;
}
kalloc函数的改动幅度比较大,对于能够从当前CPU自己的空闲链表获得可用页的情况,就直接分配,如果不行,则从所有的CPU的空闲链表中进行搜索,当搜索到某个CPU中存在可用的页面的时候,就直接调用steal_pages_from函数完成内存页面的窃取,它的定义如下:
void* steal_pages_from(int cpu)
{int count = 0;struct run* start = kmem[cpu].freelist;struct run* end = kmem[cpu].freelist;while (end && count < 100) {end = end->next;count++;
}if (end) {kmem[cpu].freelist = end->next;end->next = 0;}else {kmem[cpu].freelist = 0;
}push_off();int my_cpu = cpuid();pop_off();
kmem[my_cpu].freelist = start->next;
// 将start直接分配出去return (void*)start;
}
因为当前CPU以及被窃取的CPU的空闲链表锁都已经被获取了,因此此时可以直接完成后续的操作而不用关注锁的问题,在这里我采取的策略是:每一次从被窃取的CPU中窃取至多100页内存,这样可以减少steal的操作从而提升效率,这段代码中就是一些比较简单的链表操作,因此不再赘述。
在完成了这几个函数之后,多CPU的内存分配问题就基本得到了解决,不过在早期,我实现kalloc的时候,在找到了有可用页面的CPU时先释放锁,再在循环体之外完成后续的steal操作,结果发现一定会在kalloctest中出现kerneltrap的panic,基于之前的经验,这应该是出现了页面被多个CPU占有或是先前尝试获取的页面已经不存在了的问题,因此我将这段调用steal_pages_from函数的代码放进了循环体,这样可以保证至少刚才判定存在可用页面的CPU在窃取过程中也是能够正常拿到页面的,这样一来就完成了这部分代码的实现,最终使用kalloc和usertests sbrkmuch完成了关于内存分配的测试,测试全部通过:
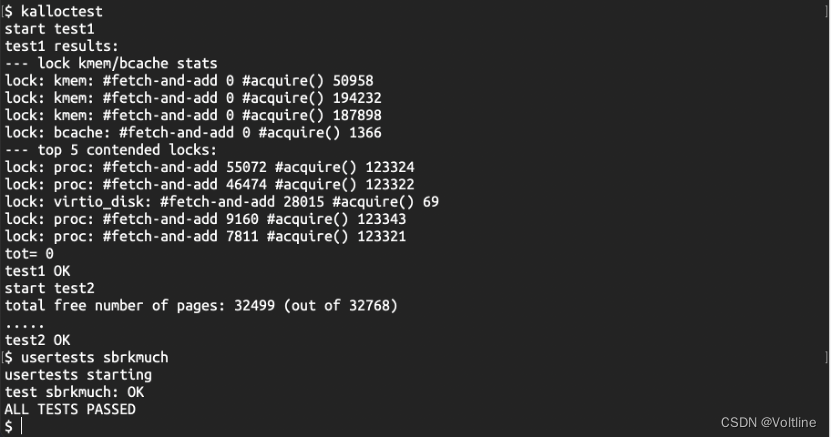
这里的tot的值变成了0,在修改内存分配器之前的tot的值超过了70000,也就是说,经过了内存分配器的修改,锁争用的现象已经明显减少了。
(6).重新设计磁盘缓存
操作内容:修改磁盘缓存Buffer Cache的代码,减少缓存块管理的锁争用
首先直接在xv6内核中直接使用bcachetest进行对于没有修改过的Buffer Cache的测试,可以发现,此时的tot为78733,因此缓存块的锁争用现象是相当严重的,接下来我们需要通过修改Buffer Cache的代码来减少锁争用现象从而通过测试。
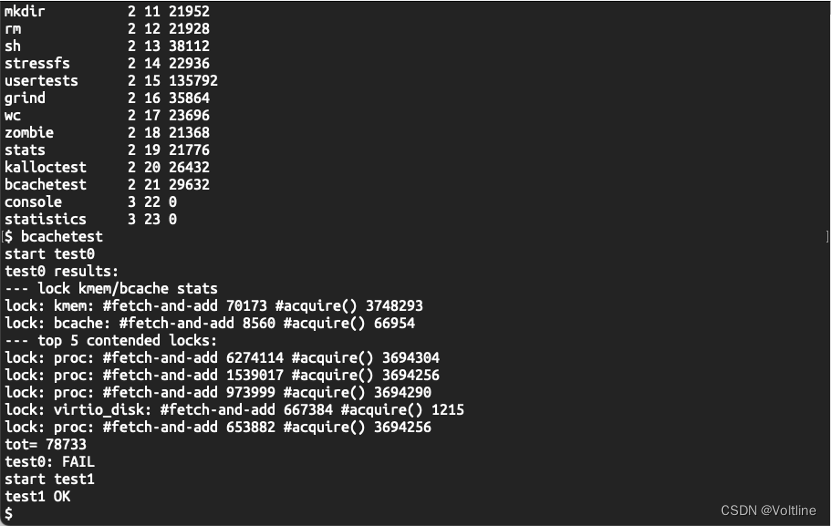
为了实现这个操作,我们需要对缓存块进行分桶,然后对于每个桶分别有对应的锁,这样一来对于不同的块号,在哈希过后总是可以有效地降低碰撞的概率,从而减少锁的竞争,一开始我对于这个的实现是简单的设定固定数额的缓存块,然后让缓存块在各个桶之间流转。
但是后续出现了太多问题以至于我无法解决,因此我选择了另一个相对比较简单的解决方案:我为每个桶都预先分配固定数额的缓存块(这个数额与bcache一开始分配的缓存块数量一致),因此我将bcache修改如下:
struct {struct spinlock lock[NBUCKETS];struct buf buf[NBUCKETS][NBUF];// Linked list of all buffers, through prev/next.// Sorted by how recently the buffer was used.// head.next is most recent, head.prev is least.struct buf hashbucket[NBUCKETS];// 每个桶中有一个链表以及一个lock
} bcache;
这样的修改好处在于:我不需要再使得各个缓存块在不同的桶之间流转,使得后续我不需要进行复杂的操作,也规避了之前出现的很多问题。但这个解决方案也不是十全十美的,原本根据NBUF的宏定义可以知道,缓存块一共只有30个,但是现在为每个桶都分配固定30个之后,就一共有390个缓存块了,理论上讲我们不需要这么多缓存块,的确是可以进行一些优化,不过在此我先采用了这个简单的方式实现,而缓存块增加带来的问题就是:自旋锁的数量明显增加,因此这会导致本次实验中findslot函数会因为锁数量不够而出现panic,不过这个问题很好解决,只需要在spinlock.c里把NLOCK的数量改大一点就好了,这里我把500改成了1000:
#define NLOCK 1000
这样一来初步工作就完成了,接下来是binit函数:
void
binit(void)
{struct buf *b;// 对于每一个桶都进行一次初始化操作for (int i = 0; i < NBUCKETS; i++) {initlock(&bcache.lock[i], "bcache");// Create linked list of buffersbcache.hashbucket[i].prev = &bcache.hashbucket[i];bcache.hashbucket[i].next = &bcache.hashbucket[i];for(b = bcache.buf[i]; b < bcache.buf[i]+NBUF; b++){b->next = bcache.hashbucket[i].next;b->prev = &bcache.hashbucket[i];initsleeplock(&b->lock, "bcache buffer");bcache.hashbucket[i].next->prev = b;bcache.hashbucket[i].next = b;}}
}
因为每个桶都存在自己固定额度的缓存块了,因此直接将缓存块按照对应的哈希值分配到桶中即可。之后是最重要的bget,为了方便后续的操作,这里我还预先定义了一个函数用于哈希,不过它的本质是取余,实际上不定义也可以:
uint Hash(uint blockno)
{return (blockno % 13);
}// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{uint hash_code = Hash(blockno);struct buf *b;acquire(&bcache.lock[hash_code]);// Is the block already cached?for(b = bcache.hashbucket[hash_code].next; b != &bcache.hashbucket[hash_code]; b = b->next){if(b->dev == dev && b->blockno == blockno){b->refcnt++;release(&bcache.lock[hash_code]);acquiresleep(&b->lock);return b;}}// Not cached.// Recycle the least recently used (LRU) unused buffer.for(b = bcache.hashbucket[hash_code].prev; b != &bcache.hashbucket[hash_code]; b = b->prev){if(b->refcnt == 0) {b->dev = dev;b->blockno = blockno;b->valid = 0;b->refcnt = 1;release(&bcache.lock[hash_code]);acquiresleep(&b->lock);return b;}}panic("bget: no buffers");
}
这一步的操作就相当简单了,如果缓存块命中,则和之前的行为一致,如果不命中,则会尝试在当前的桶中根据LRU的策略找出一个块分配出来,之后再带上锁一起返回,就完成了缓存块的获取操作。
还需要修改的就是brelse,因为head字段变成了hashbucket字段,因此需要把代码改成对应的写法:
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{if(!holdingsleep(&b->lock))panic("brelse");releasesleep(&b->lock);uint hash_code = Hash(b->blockno);acquire(&bcache.lock[hash_code]);b->refcnt--;if (b->refcnt == 0) {// no one is waiting for it.b->next->prev = b->prev;b->prev->next = b->next;b->next = bcache.hashbucket[hash_code].next;b->prev = &bcache.hashbucket[hash_code];bcache.hashbucket[hash_code].next->prev = b;bcache.hashbucket[hash_code].next = b;}release(&bcache.lock[hash_code]);
}
之后还有bpin和bunpin两个函数用来增加或减少缓存块的引用计数,也是由于相同的原因,这里将其作出对应的更改:
void
bpin(struct buf *b) {uint hash_code = Hash(b->blockno);acquire(&bcache.lock[hash_code]);b->refcnt++;release(&bcache.lock[hash_code]);
}
void
bunpin(struct buf *b) {uint hash_code = Hash(b->blockno);acquire(&bcache.lock[hash_code]);b->refcnt--;release(&bcache.lock[hash_code]);
}
这样一来就全部修改完毕了,编译运行之后在xv6中使用bcachetest进行测试,能够发现,大部分锁的fetch-and-add计数都为0了,tot的值也从70000左右变为0了,效率大幅提升,完成了对于bcache的改造:
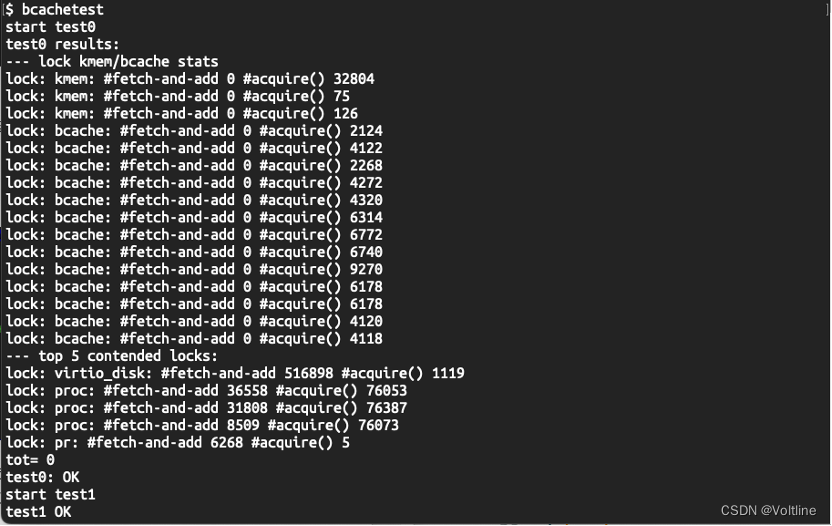
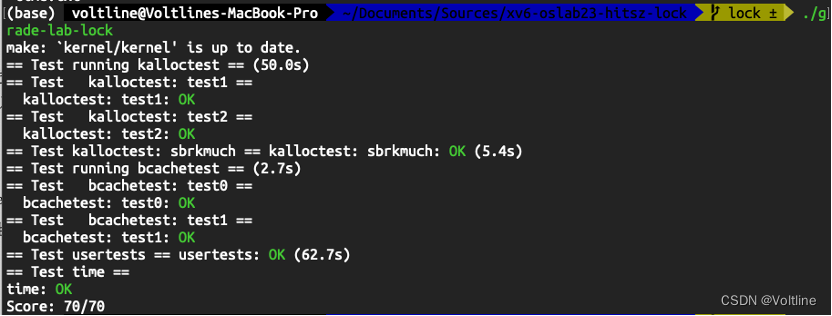
最后,在同目录下创建time.txt写入完成Lab的时间后运行./grade-lab-lock进行测试,所有的测试均能顺利通过,实验成功:
3.问题及解决方案
问题1
问题:Buffer Cache中为什么要采用双向链表来管理缓存块?
解答:因为Buffer Cache要采取LRU策略剔除最不常用的缓存块,需要从链表尾开始向前进行查找,此时采用双向链表管理缓存块的话,从尾到头查找的时间复杂度是最低的,因此采用双向链表进行管理。
问题2
问题:为什么持有自旋锁期间不允许发生中断,持有睡眠锁期间允许中断?
解答:在上面的部分已经解释了相应的问题:
-
为什么持有自旋锁期间不允许中断?
如果拿到锁之后发生了一次中断,刚才执行的程序会带着锁进入休眠,而中断处理程序此时无法获得锁,但是中断处理程序在没有获得锁之前无法直接回到先前运行的程序,此时二者之间就发生了死锁。 -
为什么持有睡眠锁期间允许中断?
sleep的行为是:首先获取当前的进程,如果传入自旋锁并非进程锁时,需要获取进程锁再释放传入的自旋锁;否则就直接进行后续操作,让当前进程直接进入挂起态再直接调用sched()开始调度,在完成了sleep之后,将锁还原成之前的锁,所以如果这个流程传入睡眠锁,那么可以保证在挂起的状态当中,睡眠锁内真实发挥作用的自旋锁本身已经被释放了,即便发生中断也不会产生死锁,因此持有睡眠锁的过程中是允许发生中断的。
但也正是因为睡眠锁开中断,因此睡眠锁不可被用于中断处理程序,中断处理程序本身不能被其他的中断所打断;同理,被自旋锁保护的临界区也不可以使用睡眠锁,睡眠锁会开中断并且还可能通过sleep让出CPU,此时就会导致进程带锁睡眠,从而导致死锁现象的产生。
问题3
问题:当Buffer cache未命中时,xv6的原做法是使用LRU(Least Recent Used)算法从链表尾开始找最不常用的缓存块剔除。除了LRU算法,还有哪些页面置换算法?举例并说明。
解答:简单如FIFO策略,当缓存块被分配出去后,将其插入到链表的最前端,这样可以保证整个缓存块链表是依照到达时间排序的。而当Buffer Cache未命中时,每次都找到链表尾的缓存块剔除再使用,这样就完成了FIFO策略的置换。
实验小结
- 1、阅读了内存分配器、磁盘缓存块、自旋锁、休眠锁等等的代码,理解了它们的基本实现方式。
- 2、本次实验利用xv6内核定义的spinlock与sleeplock完成了对于内存分配器和磁盘缓存块的多核优化,明显减少了锁争用现象的发生。