0.概述
在过去的几年中,基于调整的扩散模型在广泛的图像个性化和定制任务中取得了显着的进展。然而,尽管有潜力,当前基于调整的扩散模型在生成和生成风格一致的图像方面仍然面临着一系列复杂的挑战,其背后可能有三个原因。首先,风格的概念仍然广泛未定义和确定,它由氛围、结构、设计、材料、颜色等元素的组合组成。第二种基于反演的方法很容易出现风格退化,导致细粒度细节频繁丢失。最后,基于适配器的方法需要频繁调整每个参考图像的权重,以保持文本可控性和风格强度之间的平衡。
此外,大多数风格转移方法或风格图像生成的主要目标是使用参考图像,并将其特定风格从给定子集或参考图像应用到目标内容图像。然而,正是风格的大量属性使得研究人员很难收集风格化数据集、正确地表示风格以及评估迁移的成功与否。以前,处理基于微调的扩散过程的模型和框架对具有共同风格的图像数据集进行微调,这个过程既耗时,又在现实世界任务中通用性有限,因为它很困难收集具有相同或几乎相同风格的图像子集。
在本文中,我们将讨论 InstantStyle,这是一个旨在解决当前基于调整的图像生成和定制扩散模型所面临的问题的框架。我们将讨论 InstantStyle 框架实现的两个关键策略:
- 一种简单而有效的方法,可以将样式和内容与特征空间内的参考图像解耦,该方法是基于同一特征空间内的特征可以相互添加或减去的假设进行预测的。
- 通过将参考图像特征专门注入特定于样式的块来防止样式泄漏,并故意避免使用繁琐的权重进行微调,通常表征参数较多的设计。
本文旨在深入介绍 InstantStyle 框架,我们探讨该框架的机制、方法、架构以及它与最先进框架的比较。我们还将讨论InstantStyle框架如何展现出卓越的视觉风格化效果,并在文本元素的可控性和风格强度之间取得最佳平衡。

1.文本到图像生成中的样式保留
基于扩散的文本到图像生成人工智能框架在广泛的定制和个性化任务中取得了显着的成功,特别是在一致的图像生成任务中,包括对象定制、图像保存和风格迁移。然而,尽管最近取得了成功并且性能有所提高,但由于风格的不确定性和不确定性,风格迁移对研究人员来说仍然是一项具有挑战性的任务,通常包括各种元素,包括氛围、结构、设计、材料、颜色等等。话虽如此,风格化图像生成或风格迁移的主要目标是应用给定参考图像或图像参考子集的特定风格 到目标内容图像。然而,风格的大量属性使得研究人员很难收集风格化数据集、正确表示风格以及评估迁移的成功与否。以前,处理基于微调的扩散过程的模型和框架对具有共同风格的图像数据集进行微调,这个过程既耗时,又在现实世界任务中通用性有限,因为它很困难收集具有相同或几乎相同风格的图像子集。
鉴于当前方法遇到的挑战,研究人员对开发风格迁移或风格迁移的微调方法产生了兴趣。 风格化图像生成,这些框架可以分为两个不同的组:
-
无适配器方法: 无适配器方法和框架利用扩散过程中自注意力的力量,并通过实现共享注意力操作,这些模型能够直接从给定的参考风格图像中提取包括键和值在内的基本特征。
-
基于适配器的方法: 另一方面,基于适配器的方法和框架包含一个轻量级模型,旨在从参考风格图像中提取详细的图像表示。然后,该框架使用交叉注意机制巧妙地将这些表示集成到扩散过程中。集成过程的主要目标是指导生成过程,并确保生成的图像与参考图像所需的风格细微差别保持一致。
然而,尽管有这些承诺,免调优方法通常会遇到一些挑战。首先,无适配器方法需要在自注意力层内交换键和值,并预先捕获从参考样式图像派生的键和值矩阵。当在自然图像上实现时,无适配器方法需要使用 DDIM 或去噪扩散隐式模型反演等技术将图像反演回潜在噪声。然而,使用 DDIM 或其他反演方法可能会导致颜色和纹理等细粒度细节的丢失,从而减少生成图像中的风格信息。此外,这些方法引入的额外步骤是一个耗时的过程,并且可能在实际应用中造成显着的缺点。另一方面,基于适配器的方法的主要挑战在于在上下文泄漏和风格强度之间取得适当的平衡。当风格强度的增加导致在生成的输出中出现来自参考图像的非风格元素时,就会发生内容泄漏,其中主要的困难点是有效地将风格与参考图像内的内容分离。为了解决这个问题,一些框架构建了配对数据集,以不同的样式表示同一对象,从而促进内容表示的提取和解开样式。然而,由于风格本质上不确定的表示,创建大规模配对数据集的任务在它可以捕获的风格多样性方面受到限制,而且这也是一个资源密集型的过程。

为了解决这些限制,引入了InstantStyle框架,它是一种基于现有基于适配器的方法的新型免调优机制,能够与其他基于注意力的注入方法无缝集成,并有效实现内容和风格的解耦。此外,InstantStyle框架引入的不是一种而是两种有效的方法来完成风格和内容的解耦,实现更好的风格迁移,而不需要引入额外的方法来实现解耦或构建配对数据集。
此外,现有的基于适配器的框架已广泛应用于基于CLIP的方法中作为图像特征提取器,一些框架已经探索了在特征空间内实现特征解耦的可能性,并且与风格的不确定性相比,更容易用文字描述内容。由于在基于 CLIP 的方法中图像和文本共享特征空间,因此上下文文本特征和图像特征的简单减法操作可以显着减少内容泄漏。此外,在大多数 扩散模型,其架构中有一个特定的层注入样式信息,并通过仅将图像特征注入到特定的样式块中来完成内容和样式的解耦。通过实现这两个简单的策略,InstantStyle框架能够解决大多数现有框架遇到的内容泄漏问题,同时保持样式的强度。
综上所述,InstantStyle 框架采用两种简单、直接但有效的机制来实现内容和风格与参考图像的有效分离。 Instant-Style 框架是一种独立于模型且无需调优的方法,在样式传输任务中表现出卓越的性能,并且在下游任务中具有巨大的潜力。
2.方法论和架构
正如之前的方法所证明的,在免调整扩散模型中样式条件的注入存在平衡。如果图像条件的强度太高,可能会导致内容泄漏,而如果图像条件的强度太低,则风格可能显得不够明显。这种观察背后的一个主要原因是,在图像中,风格和内容是相互耦合的,并且由于固有的未确定的风格属性,很难将风格和意图解耦。因此,通常会对每个参考图像进行细致的权重调整,以试图平衡文本的可控性和风格的强度。此外,对于给定的输入参考图像及其在基于反演的方法中相应的文本描述,对图像采用DDIM等反演方法以获得反演扩散轨迹,这是一个近似反演方程以将图像转换为潜在图像的过程。噪声表示。在此基础上,从反向扩散轨迹和一组新的提示开始,这些方法生成新内容,其风格与输入保持一致。然而,如下图所示,真实图像的DDIM反演方法往往不稳定,因为它依赖于局部线性化假设,导致误差传播,导致内容丢失和图像重建不正确。

就方法论而言,Instant-Style 框架没有采用复杂的策略将内容和风格与图像分离,而是采用最简单的方法来实现类似的性能。与未确定的样式属性相比,内容可以用自然文本表示,从而允许即时样式框架使用 CLIP 中的文本编码器来提取内容文本的特征作为上下文表示。同时,Instant-Style框架实现了CLIP图像编码器来提取参考图像的特征。利用 CLIP 全局特征的表征,并从图像特征中减去内容文本特征,Instant-Style 框架能够显式地解耦样式和内容。尽管这是一个简单的策略,但它可以帮助 Instant-Style 框架非常有效地将内容泄漏保持在最低限度。
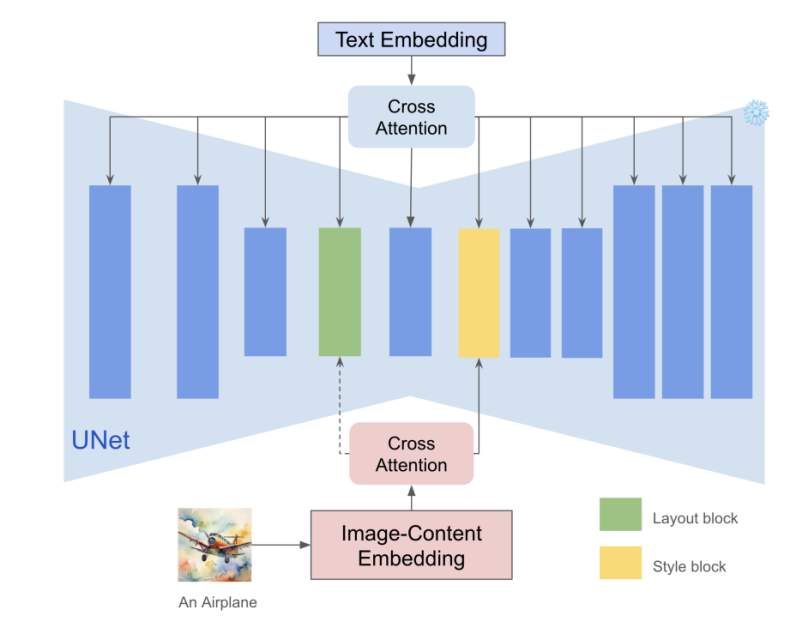
此外,深层网络中的每一层都负责捕获不同的语义信息,并且从以前的模型中观察到的关键是存在两个负责处理风格的注意层。具体来说,blocks.0.attentions.1和down block.2.attentions.1层负责捕捉颜色、材质、氛围等风格,空间布局层分别捕捉结构和构图。 Instant-Style框架隐式地使用这些层来提取样式信息,并在不损失样式强度的情况下防止内容泄漏。该策略简单而有效,因为模型已经定位了样式块,可以将图像特征注入到这些块中以实现无缝样式迁移。此外,由于该模型大大减少了适配器的参数数量,增强了框架的文本控制能力,并且该机制也适用于其他基于注意力的特征注入模型,用于编辑和其他任务。

3. 实验和结果
Instant-Style框架是在Stable Diffusion XL框架上实现的,它使用常用的预训练IR适配器作为其范例来验证其方法,并将除图像特征的样式块之外的所有块静音。 Instant-Style 模型还从头开始在 4 万个大规模文本图像配对数据集上训练 IR 适配器,并且不是训练所有块,而是仅更新样式块。
为了发挥其泛化能力和鲁棒性,Instant-Style 框架对不同内容的各种风格进行了大量的风格迁移实验,结果如下图所示。给定单一样式参考图像以及不同的提示,即时样式框架可提供高质量、一致的样式 图像生成。

此外,由于该模型仅在样式块中注入图像信息,因此能够显着减轻内容泄漏的问题,因此不需要执行权重调整。

接下来,Instant-Style框架还采用ControlNet架构来实现基于图像的风格化和空间控制,结果如下图所示。

与以前最先进的方法(包括 StyleAlign、B-LoRA、Swapping Self Attention 和 IP-Adapter)相比,Instant-Style 框架展示了最佳的视觉效果。

4.项目部署
源码地址:https://github.com/InstantStyle/InstantStyle.git
项目应用:
git clone https://github.com/InstantStyle/InstantStyle.git
cd InstantStyle# download the models
git lfs install
git clone https://huggingface.co/h94/IP-Adapter
mv IP-Adapter/models models
mv IP-Adapter/sdxl_models sdxl_models
项目应用:
from diffusers import StableDiffusionXLPipeline
from diffusers.image_processor import IPAdapterMaskProcessor
from transformers import CLIPVisionModelWithProjection
from PIL import Image
import torchimage_encoder = CLIPVisionModelWithProjection.from_pretrained("h94/IP-Adapter", subfolder="models/image_encoder", torch_dtype=torch.float16
).to("cuda")pipe = StableDiffusionXLPipeline.from_pretrained("RunDiffusion/Juggernaut-XL-v9", torch_dtype=torch.float16, image_encoder=image_encoder, variant="fp16"
).to("cuda")pipe.load_ip_adapter(["ostris/ip-composition-adapter", "h94/IP-Adapter"],subfolder=["", "sdxl_models"],weight_name=["ip_plus_composition_sdxl.safetensors","ip-adapter_sdxl_vit-h.safetensors",],image_encoder_folder=None,
)scale_1 = {"down": [[0.0, 0.0, 1.0]],"mid": [[0.0, 0.0, 1.0]],"up": {"block_0": [[0.0, 0.0, 1.0], [1.0, 1.0, 1.0], [0.0, 0.0, 1.0]], "block_1": [[0.0, 0.0, 1.0]]},
}
# activate the first IP-Adapter in everywhere in the model,
# configure the second one for precise style control to each masked input.
pipe.set_ip_adapter_scale([1.0, scale_1])female_mask = Image.open("./assets/female_mask.png")
male_mask = Image.open("./assets/male_mask.png")
background_mask = Image.open("./assets/background_mask.png")
mask2 = processor.preprocess([female_mask, male_mask, background_mask], height=1024, width=1024)
mask2 = mask2.reshape(1, mask2.shape[0], mask2.shape[2], mask2.shape[3]) # output -> (1, 3, 1024, 1024)ip_female_style = Image.open("./assets/ip_female_style.png")
ip_male_style = Image.open("./assets/ip_male_style.png")
ip_background = Image.open("./assets/ip_background.png")
ip_composition_image = Image.open("./assets/ip_composition_image.png")image = pipe(prompt="high quality, cinematic photo, cinemascope, 35mm, film grain, highly detailed",negative_prompt="",ip_adapter_image=[ip_composition_image, [ip_female_style, ip_male_style, ip_background]],cross_attention_kwargs={"ip_adapter_masks": [mask1, mask2]},guidance_scale=6.5,num_inference_steps=25,
).images[0]
image
5.总结
在本文中,我们讨论了 Instant-Style,这是一个通用框架,它采用两种简单但有效的策略来实现内容和风格与参考图像的有效分离。 InstantStyle 框架的设计目的是解决当前基于调整的扩散模型在图像生成和定制方面所面临的问题。 Instant-Style 框架实现了两个重要策略:一种简单而有效的方法,用于将样式和内容与特征空间内的参考图像解耦,该方法是基于同一特征空间内的特征可以相互添加或减去的假设进行预测的。其次,通过将参考图像特征专门注入到特定于风格的块中来防止风格泄漏,并故意避免使用繁琐的权重进行微调,通常表征参数较多的设计。