本节必须掌握的知识点:
示例九
代码分析
汇编解析
浮点数的输出精度
【补充内容】
3.4.1 示例九
浮点型分为:单精度float、双精度double、长双精度long double。
| 类型 | 存储大小 | 值范围 | 精度 |
| 单精度 float | 4字节 | 【1.2E-38~ 3.4E+38】 | 6位小数 |
| 双精度 double | 8字节 | 【2.3E-308 ~1.7E+308】 | 15位小数 |
| 长双精度long double | 16字节 | 【3.4E-4932 ~ 1.1E+4932】 | 19位小数 |
表3-5(浮点类型)
【注意】因为 ANSI C 标准并未规定 long double 的确切精度,所以对于不同平台可能有不同的实现。long double 有16字节、12字节、8字节,其中16字节占大多数。
表3-5已经明确给出了存储大小、取值范围和精度。接下来我们就要一一证明。
示例代码九
/*
验证浮点数据类型的长度
*/
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
float a = 1.012f;//常量值f或F后缀表示float浮点型
double d = 2.012l;//常量值l或L后缀表示long类型
long double Ld = 3.012L;
printf("a = %f\nd = %lf\nLd = %Lf\n", a, d, Ld);
printf("float的存储大小:%u\n", sizeof(a));
printf("double的存储大小:%u\n", sizeof(d));
printf("long double的存储大小:%u\n", sizeof(Ld));
system("pause");
return 0;
}
●输出结果:
a = 1.012000
d = 2.012000
Ld = 3.012000
float的存储大小:4
double的存储大小:8
long double的存储大小:8
请按任意键继续. . .
3.4.2 代码分析
■浮点数常量值后缀
默认缺省的浮点类型为double类型。
后缀f或F表示该常量值为float类型。
后缀l(小写L)或L表示该常量值为long double类型。整数常量值后面的后缀L表示为long int类型。
■浮点数输出格式
float类型的浮点数输出格式为’%f’。
double类型的浮点数输出格式为’%f’或’%lf’。
long double类型的浮点数输出格式为’%lf’。
【注意】浮点数的默认输出精度为小数点后6位。
■浮点数的长度
在VS中:
float类型的浮点数长度为4个字节。
double类型的浮点数长度为8个字节。
long double类型的浮点数长度为8个字节。
■其他常量值后缀
整数常量值默认为signed int类型,如果是无符号整数常量值,需添加后缀u,例如100u,-123u(注意负数取其补码后为无符号正整数)。
如果是unsigned long类型的整数常量值,后缀为ul或UL,例如123456UL。
如果缺省后缀,整数默认为int类型,浮点数默认为double类型。
二进制数后缀b或B:1000b,0001B。
十六进制后缀h或H:0ah,0dh,123H。
十六进制数前缀0x或0X:0xFFFFFFFF。
八进制数前缀0: 020表示十进制的16。
二进制数前缀0b:0b10000表示十进制的16。
【注意】常量值后缀和前缀不区分大小写。
3.4.3 汇编解析
■汇编代码
;C标准库头文件和导入库
include vcIO.inc
.data ;MASM支持的浮点数据类型
a real4 1.012 ;32位等价于float类型
d real8 2.012 ;64位等价于double类型
Ld real10 3.012 ;80位约等价于long double类型
.const ;常量区
szMsg1 db "a = %f",0dh,0ah,"d = %lf",0dh,0ah,"Ld = %lf",0dh,0ah,0
szMsg2 db "float的存储大小:%u",0dh,0ah,0
szMsg3 db "double的存储大小:%u",0dh,0ah,0
szMsg4 db "long double的存储大小:%u",0dh,0ah,0
.code ;代码区
start:
invoke printf,offset szMsg1,a,d,Ld
invoke printf,offset szMsg2,sizeof a
invoke printf,offset szMsg3,sizeof d
invoke printf,offset szMsg4,sizeof Ld
;
invoke _getch
ret
end start
●输出结果:
a = 208333622436031750000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000.000000
d = -301434019394126830000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000.000000
real4的存储大小:4
real8的存储大小:8
real10的存储大小:10
MASM汇编器只支持real4、real8和real10三种浮点类型,长度分别为32位、64位和80位。调用printf函数输出结果错误,调试器中查一下原因。
打开DtDebug调试器,拖入3-4-1.exe;
按Ctrl+F9进入程序入口点;
如图3-5所示,观察反汇编窗口的红色区域,前面3个PUSH入栈10个字节,即real10变量Ld,接着两个PUSH入栈8个字节,即real8变量d,最后一个PUSH入栈4个字节,即变量a。
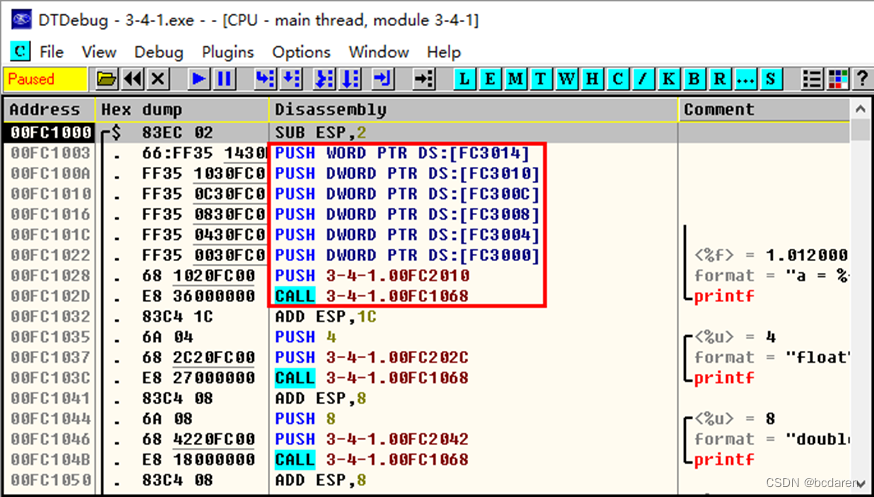
图3-5 3-4-1.exe反汇编窗口
![]()
 结论
结论
1.示例九中,printf函数输出的float、double和long double类型的3个变量分别为4个字节、8个字节和8个字节。其中float类型转换为8个字节的double类型后再输出(前文已经论述过)。
2.汇编程序中,调用的printf函数是按照4个字节、8个字节和10个字节输出结果的,所以出现错误。
3.MASM汇编器对printf函数调用的编译与VS C语言编译器的编译完全不同,参见下文中的示例九反汇编代码。
![]()
解决方案:
将变量a、d和Ld的数据类型都改成real8类型。
a real8 1.012
d real8 2.012
Ld real8 3.012
输出结果:
a = 1.012000
d = 2.012000
Ld = 3.012000
float的存储大小:8
double的存储大小:8
long double的存储大小:8
![]()
■反汇编代码
float a = 1.012f;//常量值f或F后缀表示float浮点型
009E1838 movss xmm0,dword ptr [__real@3f818937 (09E7BB0h)]
float a = 1.012f;//常量值f或F后缀表示float浮点型
009E1840 movss dword ptr [a],xmm0
double d = 2.012l;//常量值l或L后缀表示long类型
009E1845 movsd xmm0,mmword ptr [__real@4000189374bc6a7f (09E7BB8h)]
009E184D movsd mmword ptr [d],xmm0
long double Ld = 3.012L;
009E1852 movsd xmm0,mmword ptr [__real@4008189374bc6a7f (09E7BC8h)]
009E185A movsd mmword ptr [Ld],xmm0
printf("a = %f\nd = %lf\nLd = %Lf\n", a, d, Ld);
009E185F sub esp,8
009E1862 movsd xmm0,mmword ptr [Ld]
009E1867 movsd mmword ptr [esp],xmm0
009E186C sub esp,8
009E186F movsd xmm0,mmword ptr [d]
009E1874 movsd mmword ptr [esp],xmm0
009E1879 cvtss2sd xmm0,dword ptr [a]
009E187E sub esp,8
009E1881 movsd mmword ptr [esp],xmm0
009E1886 push offset string "a = %f\nd = %lf\nLd = %Lf\n" (09E7B30h)
009E188B call _printf (09E104Bh)
009E1890 add esp,1Ch
printf("float的存储大小:%u\n", sizeof(a));
009E1893 push 4
009E1895 push offset string "float\xb5\xc4\xb4\xe6\xb4\xa2\xb4\xf3\xd0\xa1\xa3\xba%u\n" (09E7B50h)
009E189A call _printf (09E104Bh)
009E189F add esp,8
printf("double的存储大小:%u\n", sizeof(d));
009E18A2 push 8
009E18A4 push offset string "double\xb5\xc4\xb4\xe6\xb4\xa2\xb4\xf3\xd0\xa1\xa3\xba%u\n" (09E7B6Ch)
009E18A9 call _printf (09E104Bh)
009E18AE add esp,8
printf("long double的存储大小:%u\n", sizeof(Ld));
009E18B1 push 8
009E18B3 push offset string "long double\xb5\xc4\xb4\xe6\xb4\xa2\xb4\xf3\xd0\xa1\xa3\xba%u\n" (09E7B88h)
009E18B8 call _printf (09E104Bh)
009E18BD add esp,8
上述代码是VS中3-4-1.c程序的反汇编代码,注意加黑部分的反汇编代码。使用movss指令将4个字节的float类型常量值存入变量a。接着两次使用movsd分别将8个字节的double类型和long double类型常量存入变量d和变量Ld。
接下来调用printf函数时,注意,有3条sub esp,8语句,意味着按照从右往左的入栈顺序,分别将3个参数Ld、d和a入栈,均为8个字节。
3.4.4 浮点数的输出精度
实验二十八:控制浮点数的输出精度
![]()
VS中新建项目3-4-2.c。代码如下:
/*
按指定精度输出浮点数
*/
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
float a = 1.01234567f;
double d = 2.012345678901234567891l;
long double Ld = 3.012345678901234567892L;
printf("a = %f\nd = %lf\nLd = %Lf\n", a, d, Ld);
printf("a = %.6f\nd = %.16lf\nLd = %.18Lf\n", a, d, Ld);
system("pause");
return 0;
}
●输出结果
a = 1.012346
d = 2.012346
Ld = 3.012346
a = 1.012346
d = 2.0123456789012346
Ld = 3.012345678901234614(%.18Lf)
请按任意键继续. . .
上述代码中,格式说明符’%.6f’表示输出小数点后6位。与此同理,’%.16f’输出小数点后16位,’%.18f’输出小数点后18位。
【注意】float类型的精度为6位小数,double类型的精度为15位小数,long double类型精度为19位小数。
d = 2.0123456789012346,是取2.01234567890123456四舍五入的近似值。
Ld变量分别取18位、19位和20位,对比分析:
Ld = 3.012345678901234614(%.18Lf)
Ld = 3.0123456789012346135(%.19Lf)
Ld = 3.01234567890123461353(%.20Lf)
![]()
 结论
结论
1.浮点数输出小数位越长精度越低。
2.二进制浮点数转换为十进制浮点数后再按四舍五入的方法取近似值。
3.long double类型的浮点数取小数点后第16位开始取近似值,而后会再次取近似值。
4.浮点数丢失精度的原因:计算机在存储浮点数时有长度限制,对小数部分进行截取,造成精度丢失。
5.记住:计算机中的浮点数永远都是一个近似值。
![]()
解决浮点数精度丢失的方法为:将浮点数转为整数,然后再进行算术逻辑运算,运算的结果再还原为浮点数。
![]()
 举例
举例
1.123456*2.1234=?
1.123456*2.1234=(1.123456*1000000)*(2.1234*10000)=1123456*21234/10000000000
读者可以将上述两种计算方法转换为代码的形式实现,并比较结果。
![]()
 练习
练习
- 请读者将3-4-2.c翻译成汇编语言实现。
- 请读者分析3-4-2.c的反汇编代码。
3.4.5 【补充内容】
下面分别从存储格式、内存分布、编码规则、取值范围、有效数字位数和测试示例代码六个部分来详细说明浮点类型。
■存储格式
浮点数在计算机中存储时,按照二进制科学计数法拆分为三部分:符号位、指数部分、尾数部分,如图3-6所示。
■编码规则
在实际存储时要对使用二进制科学计数法表示的浮点数值的符号位、指数部分和尾数部分进行编码处理。一般需要分为正规化形式的浮点数、非正规化形式的浮点数和特殊值三种类型进行编码。
●符号
浮点数的最高位为符号位,如果该位为1表示负数,为0表示正数。浮点数0是正数。
●尾数
在形如m*be的表达式表示的浮点数中,m称为尾数,b是基数,e是指数。尾数部分m是一个十进制小数。
●指数
单精度浮点数的指数是以8位无符号整数的格式存储的。实际存储的是指数值与127相加的和。以数字1.101*25为例,指数5与127相加的和(十进制132,二进制10100010)存储在指数部分。
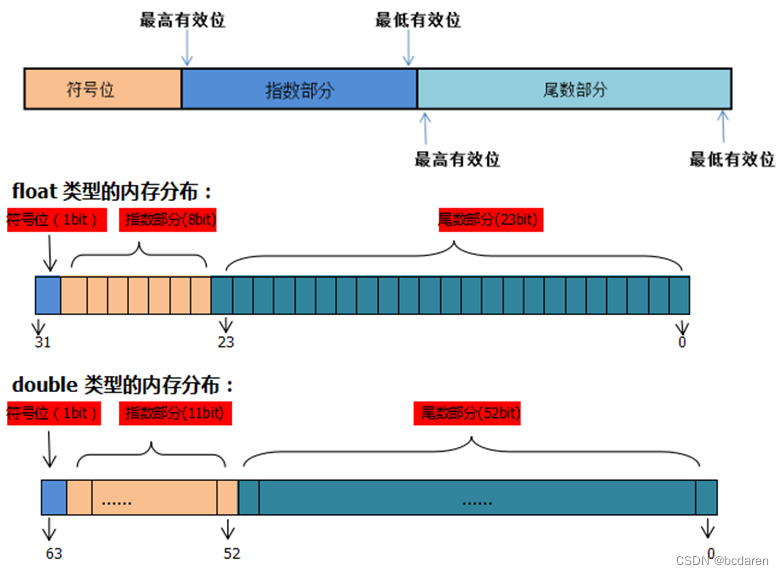
图3-6 浮点数存储格式
指数部分为何要加127?这是因为单精度浮点数的指数必须以8位无符号整数格式存储,不可以是负数或0,因此指数部分存储时的取值范围必须是1~254之间,单精度浮点数指数的实际值可以是-126~127之间,与127相加后的取值范围刚好是1~254之间。
![]()
 举例
举例
指数 调整后(E+127) 二进制值
+5 132 10000100
0 127 01111111
-10 117 01110101
+127 254 11111110
-127 0 00000000
-1 126 01111110
![]()
●位权法表示浮点数
十进制123.154可表示如下表达式的和:
123.154=(1*102)+(2*101)+(3*100)+(1*10-1)+(5*10-2)+(4*10-3)
二进制浮点数的表示方法是类似的,只要用2为基数计算位权值即可。例如浮点二进制值11.1011可表示为:
11.1011=(1*21)+(1*20)+(1*2-1)+(0*2-2)+(1*2-3)+(1*2-4)
●分数表示浮点数
另一种表示小数后面的值的方法是用以2的幂为分母的分数之和表示,下例中和是11/16(或0.6875):
.1011=1/2+0/4+1/8+1/16=11/16
可以将浮点数的整数部分和小数部分分别转换为十进制数,小数部分用分数表示。
![]()
 举例
举例
二进制浮点数 转换后的十进制整数和分数
1.11 1 + 1/2 + 1/4
111.0011 7+0/2+0/4+1/8+1/16
1100.10101 12+1/2+0/4+1/8+0/16+1/32
![]()
●尾数的精度
计算机存储的数据都是有数据宽度的。浮点数的存储自然也是有数据宽度的。当浮点数超出存储的数据宽度时,需要取近似值。
浮点处理器可以选择下面4种近似方法:
•近似到最接近的偶数:近似结果最接近准确结果,如果有两个值与精确值结果近似度相同,则选取最接近的偶数(最低有效位是0)。
•向下近似趋向于-∞:近似结果小于或等于精确结果。
•向上近似趋向于+∞:近似结果大于或等于精确结果。
•近似趋向于0:也称裁剪,近似结果的绝对值小于或等于精确结果。
![]()
 举例
举例
近似到最近的偶数 近似前:1.0111 近似后:1.100(最低有效位为0)
向下近似趋向于-∞ 近似前:1.0111 近似后:1.011(小于或等于)
向上近似趋向于+∞ 近似前:1.0111 近似后:1.100(大于或等于)
近似趋向于0(剪裁) 近似前:1.0111 近似后:1.011(去掉最后一位)
近似到最近的偶数 近似前:-1.0111 近似后:-1.100(最低有效位为0)
向下近似趋向于-∞ 近似前:-1.0111 近似后:-1.100(小于或等于)
向上近似趋向于+∞ 近似前:-1.0111 近似后:-1.011(大于或等于)
近似趋向于0(剪裁) 近似前:-1.0111 近似后:-1.011(去掉最后一位)
![]()
●二进制浮点数的正规化
二进制浮点数是以正规化的格式存储的。存储时分为符号位、指数部分和尾数部分。因此,在二进制浮点数存储前,需要将其转换为正规化格式。对于任何给定的浮点二进制数,可通过移动小数点,使小数点前仅有一个数字“1”从而使其正规化,指数表示小数点向左(正数)或向右移动(负数)的位数。
![]()
 举例
举例
未正规化格式 正规化格式
1110.1111 1.1101111*2^3
0.1010101 1.010101*2^-1
101010. 1.01010*2^5
![]()
●非正规化值:二进制浮点数正规化操作的逆过程称为逆正规化,可通过移动二进制小数点直到指数为0。如果指数部分是正数n,那么向右移动小数点n位;如果指数部分是负数n,那么向左移动小数点n位。如果需要,开头的空位应以0填充。
■ IEEE表示法
●实数编码
对二进制浮点数的符号位、指数和尾数域进行了正规化,就可以得到一个完整的二进制IEEE短实数。
![]()
 举例
举例
二进制值 调整后的指数值 符号 指数 尾数
-1.11 127 1 01111111 11000000000000000000000
+1101.101 130 0 10000010 10110100000000000000000
-.00101 124 1 01111100 01000000000000000000000
+100111.0 132 0 10000100 00111000000000000000000
+.0000001101011 120 0 01111000 10101100000000000000000
![]()
●正规化和反向正规化
由于指数范围的限制,浮点处理器有可能无法实现二进制浮点数的正规化存储。假设浮点处理器的计算结果是1.0101111*2^-129,其指数太小,无法在单精度实数中存储,这时将产生一个下溢异常,可通过向左移动小数点(每次一位)使其正规化,直到指数落在有效的范围内为止:
1.01011110000000000001111 x 2^-129
0.10101111000000000000111 x 2^-128
0.01010111100000000000011 x 2^-127
0.00101011110000000000001 x 2^-126
在这个例子中,由于移动了小数点,精度会有一些损失。
●特殊值的编码
IEEE规范中还规定了几类实数和非实数的编码:
•正数0和负数0
•反向正规化的有限数
•正规化的有限数
•正无穷和负无穷
•非数字值(NaN)
•不确定数
值 符号 指数 尾数
正数0 0 00000000 00000000000000000000000
负数0 1 00000000 00000000000000000000000
正无穷 0 11111111 00000000000000000000000
负无穷 1 11111111 00000000000000000000000
QnaN x 11111111 1xxxxxxxxxxxxxxxxxxxxxx
SNaN x 11111111 0xxxxxxxxxxxxxxxxxxxxxxa
Intel浮点单元使用不确定数响应一些无效的浮点操作。
●正无穷和负无穷
正无穷(+∞)表示最大的正实数,负无穷(-∞)表示最小的负实数。可以比较无穷值和其他值:-∞小于+∞,-∞小于任何有限数,+∞大于任何有限数。正无穷和负无穷都能用来表示溢出。
●非数字(NaN)
NaN是不表示任何有效实数的位序列。X86 32位处理器体系结构包含两种类型的NaN:
quiet NaN可通过大多数算术运算而不会导致任何异常;
signalling NaN可用于产生一个无效操作异常。
编译器可以用Signalling NaN值填充未初始化的数组,对该数组进行任何计算的企图都会引发一个异常。quiet NaN可用于存放调试会话产生的诊断信息。浮点单元不会试图对NaN执行操作。X86 32位处理器手册详细描述了一套规则,用于确定以这两种类型的NaN组合作为操作数时指令执行的结果。
■十进制浮点数转换为二进制浮点数
●方法一:分数转换法
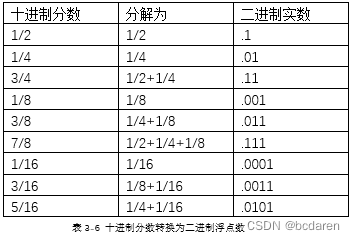
如果十进制分数可以很容易地表示为1/2+1/4+1/8+…的格式,那么就很容易得到其对应的二进制实数,如表3-6所示。
●方法二:长除法
很多实数,如1/10(0.1)或1/100(0.01),不能用有限个二进制数字位表示,这样的分数只能近似表示为若干以2的幂为分母的分数之和。对于这样的实数可以使用二进制长除法。把十进制分数转换成二进制数时,如果涉及到的十进制值比较小,可以使用一种很方便的方法:首先把分子和分母都转换成二进制值,然后再进行除法操作。
![]()
 举例
举例
例1:十进制值5/10转换为二进制数0.1。
分别将分子和分母转换为二进制数0101B和1010B,然后做除法运算,分子除以分母。
在被除数减去1010后余数为0时,除法终止。因此十进制分数5/10等于二进制0.1,我们称上面这种方法为二进制长除法。

例2:把十进制的0.2(2/10)转换为二进制值,使用长除法。首先,将十进制2和10转
换为二进制数10和1010,然后进行二进制除法计算:10除以1010。

![]()
第一个足够大的余数时10000,在除以1010之后,余数时110,在末尾添加一个0,新的被除数是1100,除以1010后,余数是10,…….。商中重复出现0011,因此我们得知准确的商是无法得到的,0.2不能用有限个二进制位表示。0.2的单精度编码的尾数部分是00110011001100110011001
![]()
 总结
总结
把单精度转换成十进制数:
单精度二进制数:0 10000010 01011000000000000000000
转换成十进制数时的推荐步骤:
1.如果最高有效位是1,该值是负数,最高有效位是0,表示该值为正数。
2.未调整的指数值是00000011,也就是十进制数3。
3.组合符号位、指数和尾数得到二进制数+1.01011*23。
4.逆正规化后的二进制数是+1010.11。
5.对应的十进制数为:10 3/4或10.75。
![]()
实验二十九:控制浮点数的输出精度
![]()
VS中新建项目3-4-3.c。代码如下:
/*
查看单精度浮点类型的存储
*/
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
float a = 8.5f;
printf("a = %f\n", a);
system("pause");
return 0;
}
第一步:在float a = 8.5f;这一行按F9下断点。
第二步:按F5调试执行。
第三步:监视1窗口中输入名称&a,显示当前变量a的地址和值:
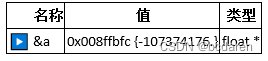
第四步:将地址0x008ffbfc(每次运行都不一样)复制到内存1窗口地址栏,显示当前该地址处的值为0xcccccccc。如图3-7所示。

图3-7 存储浮点数之前的内存窗口
第五步:连续按两次F10单步执行,监视1窗口显示内容:

再观察一下内存窗口:

图3-8 存储浮点数之后的内存窗口
float a = 8.5f 对应的反汇编代码是:
00131838 movss xmm0,dword ptr [__real@41080000 (0137B44h)]
00131840 movss dword ptr [a],xmm0
8.5的二进制是0100 0001 0000 1000 0000 0000 0000 0000转化成十六进制就是41080000。
■有效数字位数
因为有效数字位只与位数有关,只要计算出十进制表示的尾数中有效字位数就能知道该浮点数的有效数字位数。
floatl类型:
尾数部分:23bit;
尾数最大值:223=8388608;
有效数字位数:6位或7位(不能保证精确)
double类型:
尾数部分:52bit;
尾数最大值:252=4503599627370496;
有效数字位数:15位或16位(不能保证精确,小数点后尾数越大精确度越低)。
double的存储格式依照上述方式类推,第63位为符号位,第62~51位为指数位,第50~0位为尾数位。long double 在VC++ 6.0 里效果等同于double。
【注:浮点数据表示测试可以通过IEEE-754 Analysis 网页在线测试链接:HTTP://babbage.cs.qc.cuny.edu/IEEE-754/ 】
实验三十:输出浮点类型占用的存储空间以及它的范围值
VS中新建项目3-4-4.c。需要引用float.h标准库函数头文件。代码如下:
/*
输出浮点类型占用的存储空间以及它的范围值
*/
#include <stdio.h>
#include <stdlib.h>
#include <float.h>
int main(void)
{
printf("float存储最大字节数:%lu\n", sizeof(float));
printf("float最小值:%E\n", FLT_MIN);
printf("float最大值:%E\n", FLT_MAX);
printf("float精度:%d\n", FLT_DIG);
printf("double存储最大字节数:%lu\n", sizeof(double));
printf("double最小值:%E\n", DBL_MIN);
printf("double最大值:%E\n", DBL_MAX);
printf("double精度:%d\n", DBL_DIG);
system("pause");
return 0;
}
●输出结果:
float存储最大字节数:4
float最小值:1.175494E-38
float最大值:3.402823E+38
float精度:6
double存储最大字节数:8
double最小值:2.225074E-308
double最大值:1.797693E+308
double精度:15
请按任意键继续. . .
我们可以鼠标右键打开float.h头文件的内容,【float.h标准库函数详见附录D】。
![]()
 练习
练习
1、已知长方形的高为3.5cm、宽为5.5cm,求长方形的面积。
2、创建一个程序,从键盘输入float型、double型,long double型的变量,并显示其值。注意试着输入各种各样的值,并验证其动作。
![]()


![[Linux]一篇文章带你全面理解信号](https://img-blog.csdnimg.cn/direct/28f01a76dc7c4c6cba7e00ab393dc7bb.png#pic_center)