前言
这个项目是为了让开发者最喜欢的动画角色唱歌而开发的,任何涉及真人的东西都与开发者的意图背道而驰。
项目地址:https://github.com/svc-develop-team/so-vits-svc/blob/4.1-Stable/README_zh_CN.md
安装
可以自行配置,应该也不难
也可以下载配置好的百度网盘:链接: https://pan.baidu.com/s/1iAhrkvlWry3gIe_EnpB7NQ
提取码: 2ftj
数据预处理
首先准备1小时以上的歌声文件,最好是WAV格式
来带下载的文件UVR5目录,解压安装UVR5,把模型文件放入model目录下,覆盖即可
UVR5可以对语音文件进行伴奏分离,去除和声,去除混响回声,打开UVR5
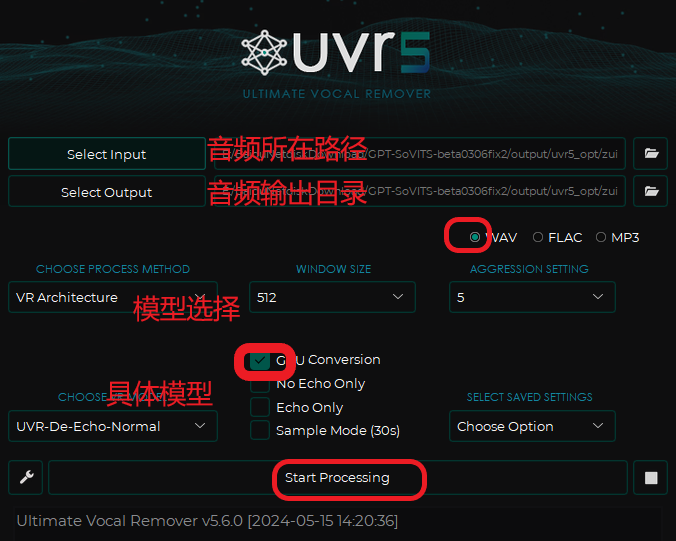
把音频文件输入输出目录,和模型类型,具体模型,勾选GPU conversion,WAV,基本选择这些就可以,其他默认,或者微调
提取人声的顺序流程是分离伴奏——去除和声——去除混响和回声
分离伴奏-MDX_Net_Models或Demucs_Models
分离伴奏可以从以下方法任选其一:
- (苹果用户专享)使用 Ripple 分离人声
- 剪映专业版+录屏(直接导出要开VIP,录屏可以白嫖,而且没有音质损失)
- 使用 UVR5 - MDX23C-InstVoc HQ 或v3|UVR_Model_1模型
其中前2个使用的是字节跳动的闭源技术内核,因此可能需要收费。第三个方法是目前最强的开源分离模型,但效果可能没有前2个好。
去除和声-VR_Models
使用 UVR5 的去除和声模型(以下三个任选其一)
-
- UVR-BVE-4B_SN-44100-1 (Instrumental Only)
- 5_HP_Karaoke-UVR (Vocals Only) (比6激进,有可能会扣过头)
- 6_HP_Karaoke-UVR (Vocals Only)(没有5激进)
去除混响和回声-VR_Models
使用 UVR5 的去混响模型(以下三个任选其一)
-
- UVR-De-Echo-Normal选No Echo Only(轻度混响)
- UVR-De-Echo-Aggressive选No Echo Only(重度混响)
- UVR-De-Echo-Dereverb选No Echo Only(遇到鸟之诗这种变态的混响可以用)
使用 UVR5 需要确保 UVR 版本在 5.6.0 以上,如果UVR里面没上述模型,点小扳手,去 Download Center 里面下载模型(请自备科学上网,否则会下载失败)
音频切分
之前用的一直是这个,对比了webui自带的,感觉对空白音频去除的更干净
https://github.com/flutydeer/audio-slicer
点击最下面webui bat文件来到webui,tensorboard是查看训练日志信息的
输入之前去伴奏,去回声,去混响,处理好的音频文件,输入路径,和输出路径,加载后切分
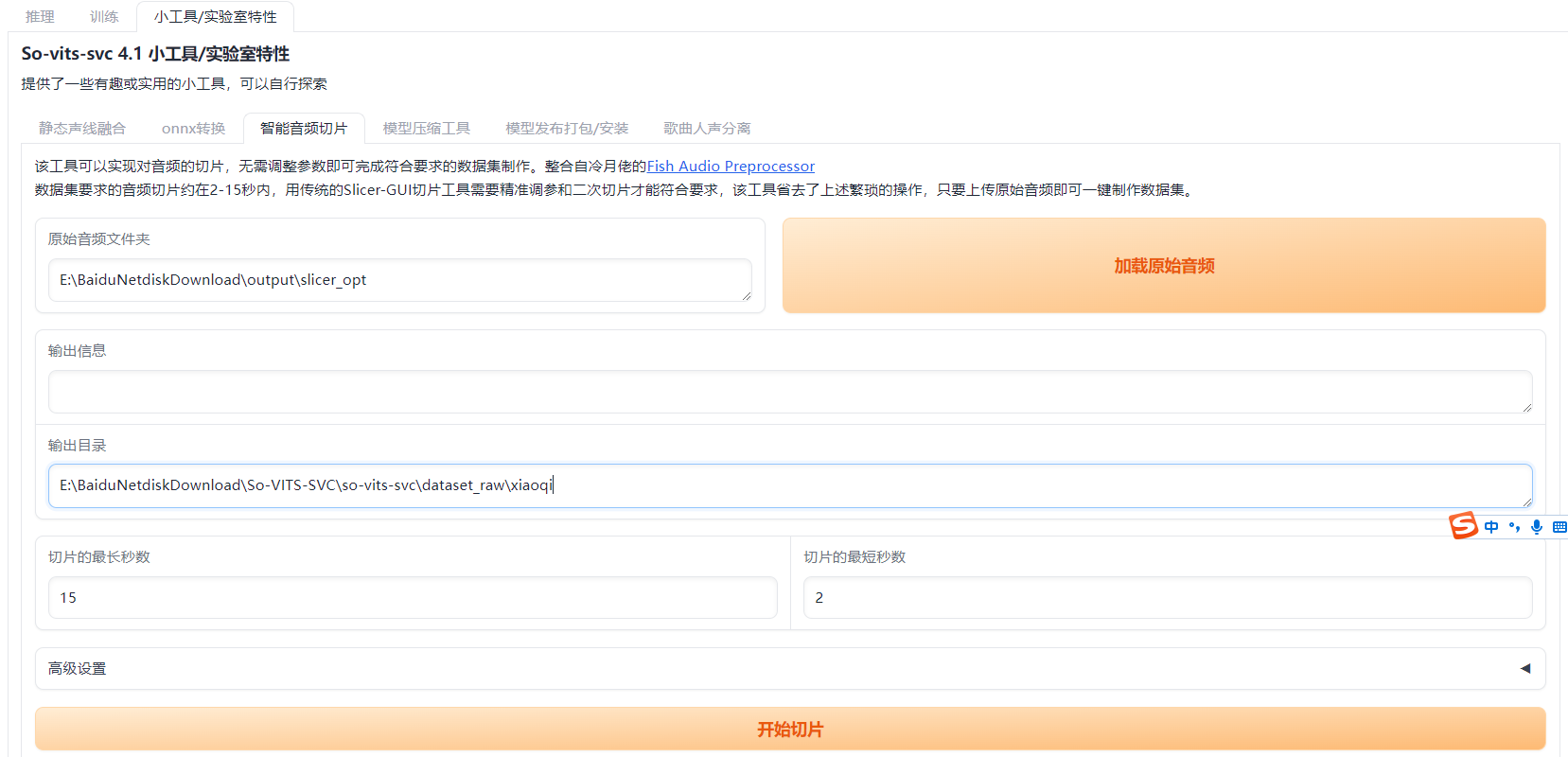
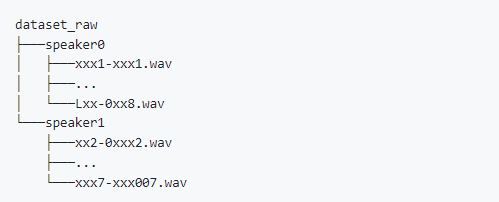
之后把切分的音频文件放入data_raw目录下,一个文件夹代表一个人声
训练
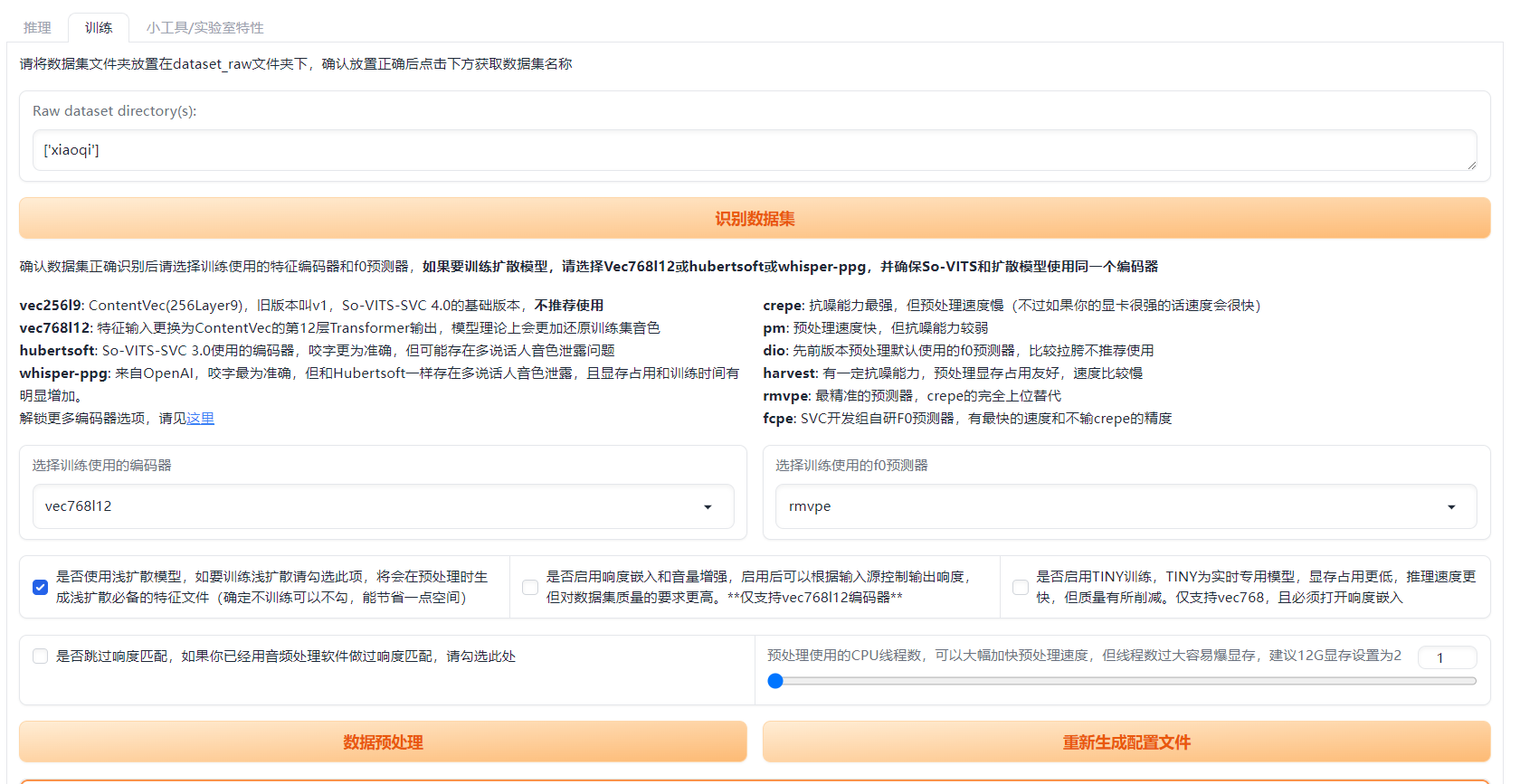
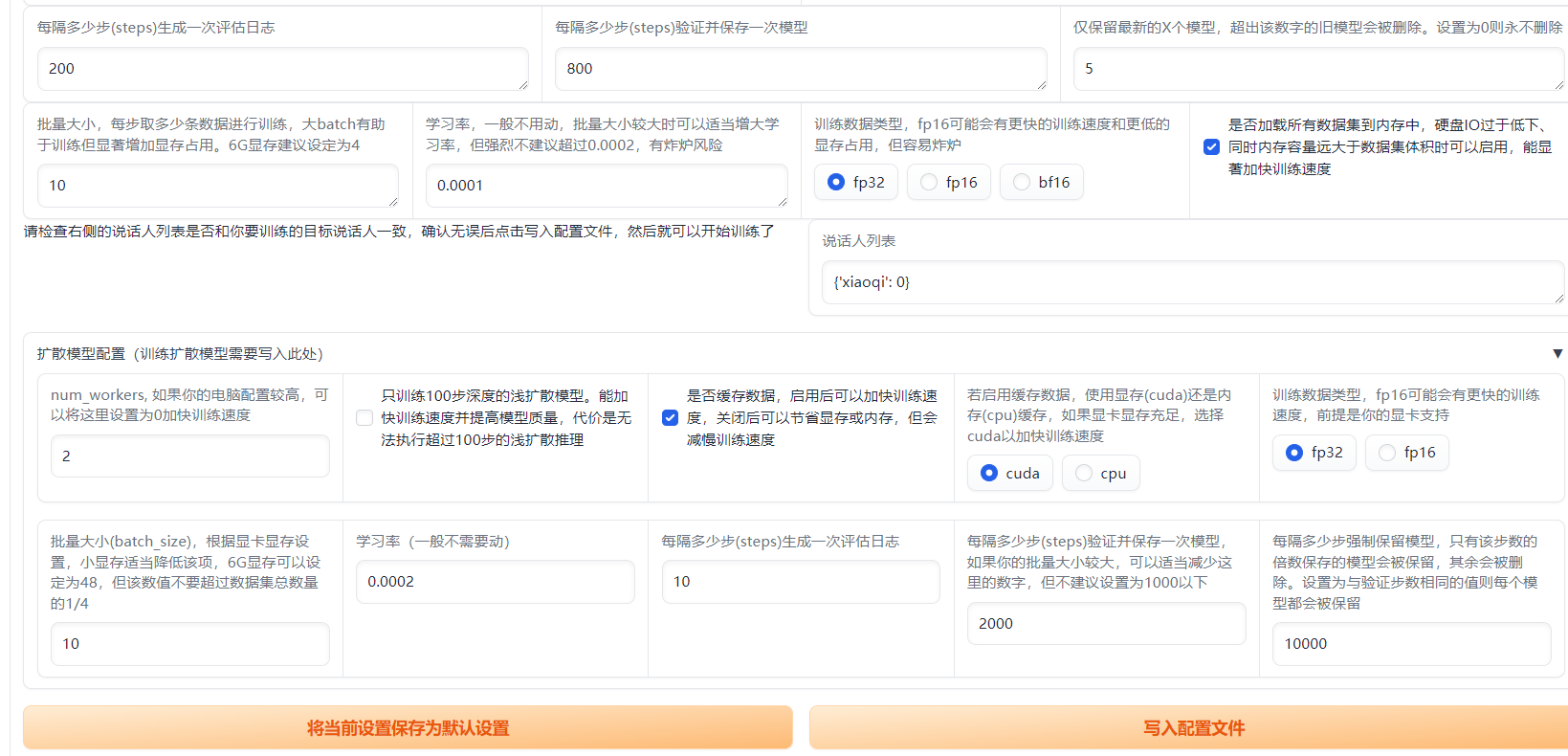
点击识别训练集,数据预处理,重新生成配置文件
参数选择:基本调一下保存的模型个数,没多少步保存一次模型,一轮步数=音频数量/批量大小
然后保存设置,导入配置文件
关于预训练模型
预训练模型(底模)是指使用大量高质量数据集训练得来的模型。使用底模辅助你的训练将可以极大增强模型的性能并大幅减少训练难度。整合包会根据你所选择的编码器、网络结构在训练时自动加载底模。目前整合包内含有以下底模:
| 标准底模 | 响度嵌入 | 响度嵌入 + TINY | 完整扩散 | 100 步浅扩散 | |
|---|---|---|---|---|---|
| Vec768L12 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Vec256L9 | ✅ | ❌ | ❌ | ❌ | ❌ |
| hubertsoft | ✅ | ❌ | ❌ | ✅ | ❌ |
| whisper-ppg | ✅ | ❌ | ❌ | ✅ | ❌ |
关于浅扩散步数(训练)
在 v2.3.6 之前的版本,浅扩散模型是训练完整 1000 步深度的,但在大多数情况下,推理时很少会用到完整深度扩散。可以只训练一个特定步数深度的浅扩散模型(“100步深度”,注意不等同训练时只训练100步,和训练步数是完全不同的概念),由此可以进一步加快浅扩散的训练速度。在理论和实践测试中,只训练部分步数浅扩散的模型表现也比纯扩散模型更好。但代价是在推理时无法进行超过该步数的浅扩散推理。
关于聚类模型
聚类方案可以减小音色泄漏,使得模型训练出来更像目标的音色(但其实不是特别明显),但是单纯的聚类方案会降低模型的咬字(会口齿不清,这个很明显)。本模型采用了融合的方式,可以线性控制聚类方案与非聚类方案的占比,也就是可以手动在"像目标音色" 和 “咬字清晰” 之间调整比例,找到合适的折中点,使用聚类只需要额外训练一个聚类模型,虽然效果比较有限,但训练成本也比较低。
然后依次训练模型
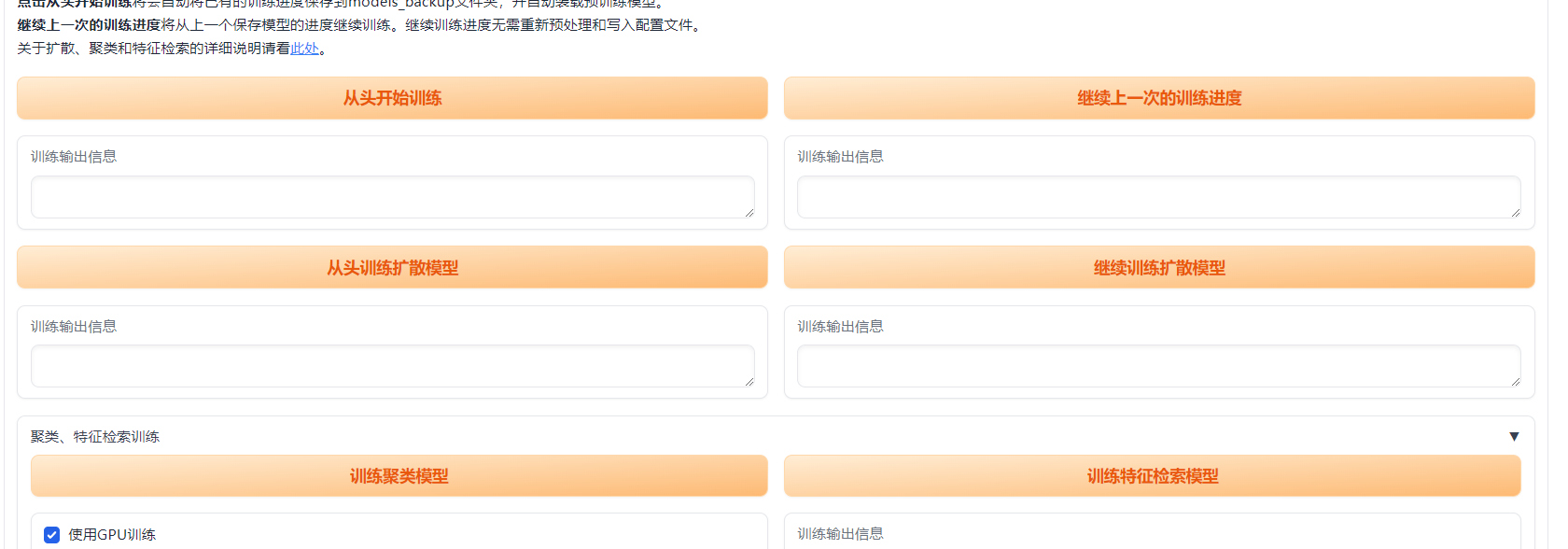
什么时候停止训练?
可以通过cmd命令行查看loss值,如果一直无法下降可以ctrl c停止,或者tensorboard是查看训练日志信息来看什么时候停止
第一个是必须有的,至于扩散和聚类模型是可选的
推理
这里拿之前比较火的孙燕姿语音试试
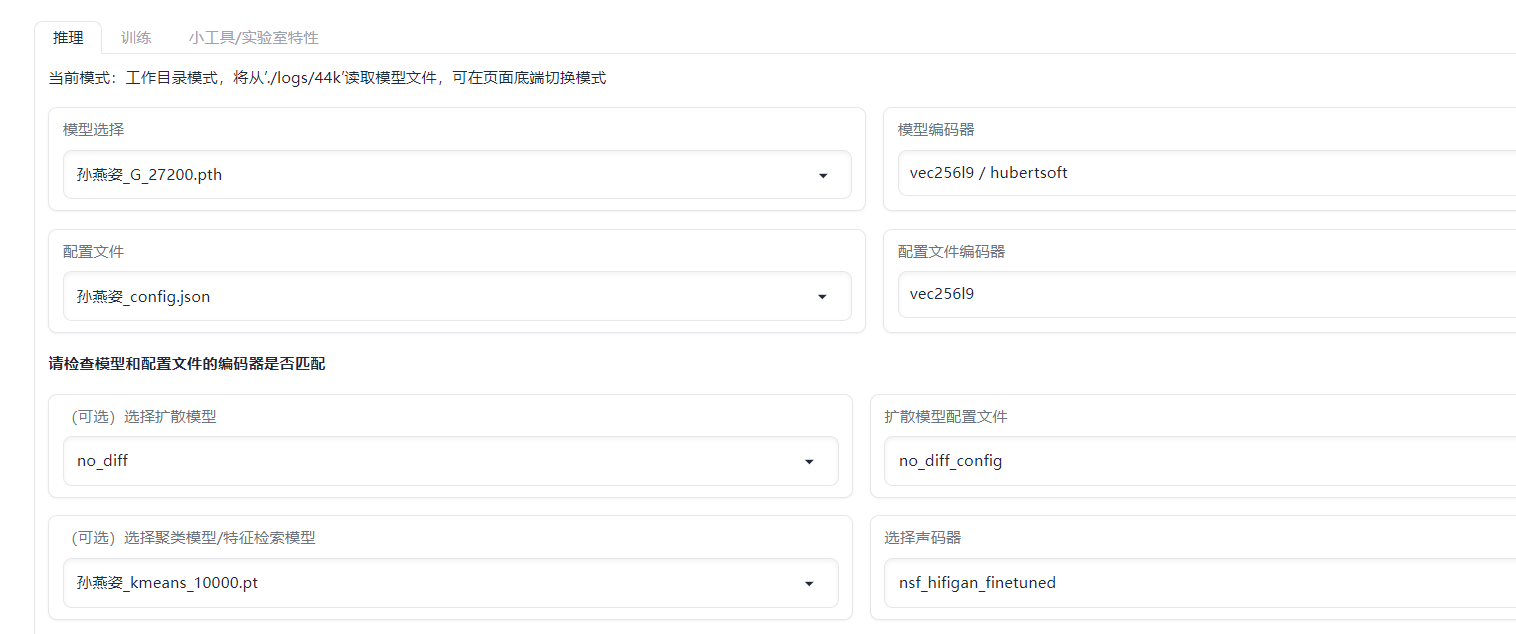
如果是克隆歌声,声音数据必须是干声,然后音频转换,
f0预测器可以选crepe或rmvpe,fcpe,具体看效果
在UVR5可以对语音文件进行伴奏分离,去除和声,去除混响回声,得干声数据,音频转换后再使用剪辑软件把之前分离的伴奏,混响回声合并(和声感觉加上去有点像杂音)
如果转换识别失败,可能输入音频时长过长,最好不超过1分半,
不要用切分工具切分,它会把空白也去掉了
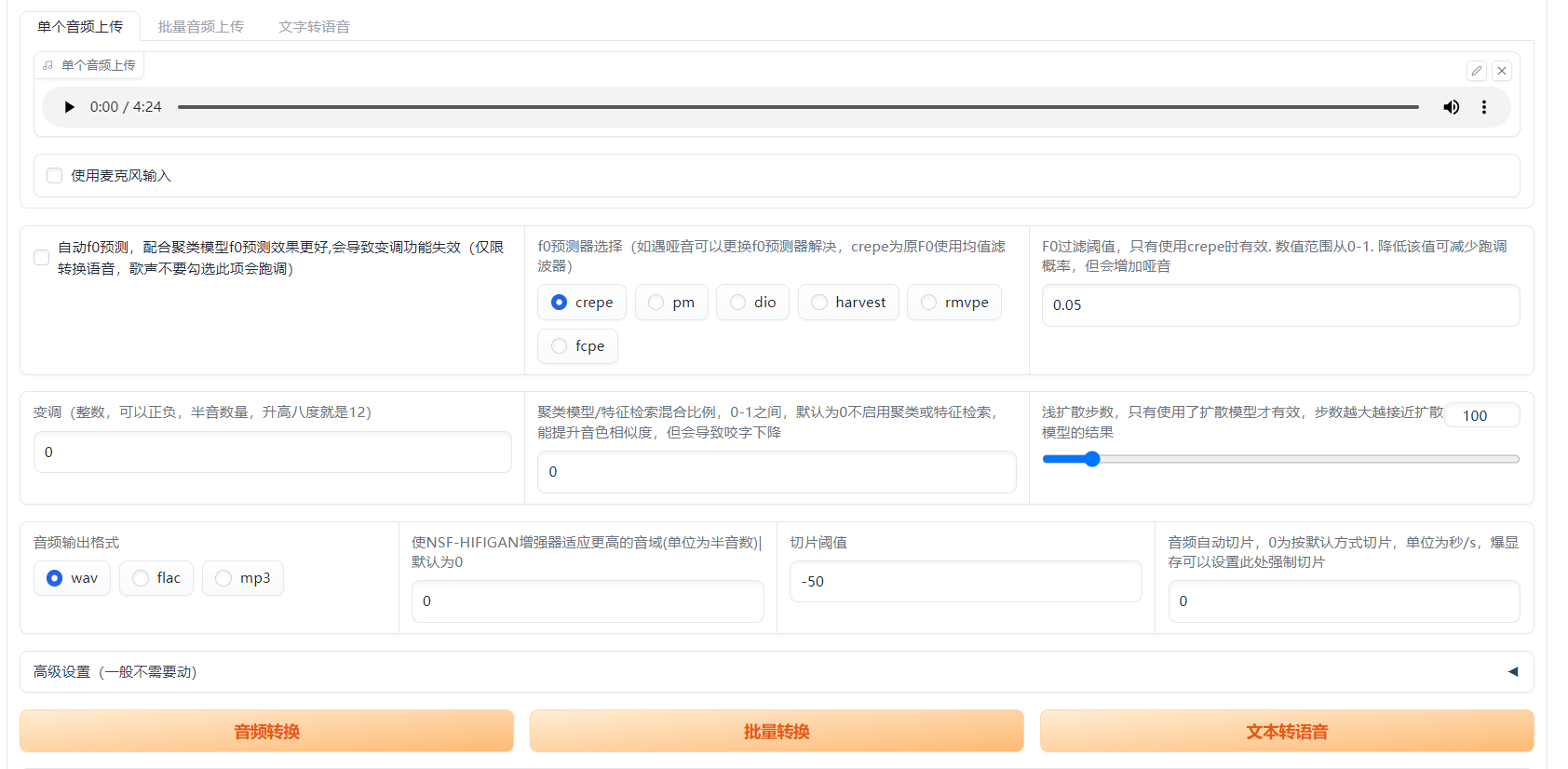
自动 f0 预测
基本上是一个自动变调功能,可以将模型音高匹配到推理源音高,用于说话声音转换时可以打开,能够更好匹配音调。
f0 预测器
在推理时必须选择一个 f0 预测算法。以下是各个预测器算法在推理时的优缺点:
| 预测器 | 优点 | 缺点 |
|---|---|---|
| pm | 速度快,占用低 | 容易出现哑音 |
| crepe | 基本不会出现哑音 | 显存占用高,自带均值滤波,因此可能会出现跑调 |
| dio | - | 可能跑调 |
| harvest | 低音部分有更好表现 | 其他音域就不如别的算法了 |
| rmvpe | 六边形战士,目前最完美的预测器 | 几乎没有缺点(极端长低音可能会出错) |
| fcpe | SVC 开发组自研,目前最快的预测器,且有不输 crepe 的准确度 | - |
关于浅扩散步数(推理)
完整的高斯扩散为 1000 步,当浅扩散步数达到 1000 步时,此时的输出结果完全是扩散模型的输出结果,So-VITS 模型将被抑制。浅扩散步数越高,越接近扩散模型输出的结果。如果你只是想用浅扩散去除电音底噪,尽可能保留 So-VITS 模型的音色,浅扩散步数可以设定为 30-50.
最后看看效果,
Adobe Audition或剪映合并
孙燕姿演唱最后一页
链接
补
从外部迁移模型(放入对应文件夹)
推理 (Inference) 是指将输入源音频通过 So-VITS 模型转换为目标音色的过程。因此,执行 So-VITS 的推理过程,你必须拥有:
| 名称 | 文件后缀 | 存放目录 | 描述 |
|---|---|---|---|
| So-VITS 模型 | .pth | .\logs\44k | 推理所必须的神经网络模型 |
| 配置文件 | .json | .\configs | 存放模型参数的配置文件,必须与模型一一对应 |
除此之外,还有一些文件属于可选项,能够执行推理的扩展功能。即使缺失也可以正常执行推理:
| 名称 | 文件后缀 | 存放目录 | 描述 |
|---|---|---|---|
| 聚类 (Kmeans) 模型 | .pt | .\logs\44k | 执行混合聚类方案必须的模型 |
| 扩散模型 | .pt | .\logs\44k\diffusion | 执行浅扩散推理必须的模型 |
| 扩散模型配置文件 | .yaml | .\configs | 存放扩散模型参数的配置文件,必须与模型一一对应 |
| 特征索引模型 | .pkl | .\logs\44k | 执行混合特征索引必须的模型 |
模型兼容(如果有问题修改)
在configs文件夹内用文本编辑器打开模型的对应配置文件,找到 "n_speakers" 项,在这一行最后添加一个英文逗号(“,”),然后添加新的两行:
"speech_encoder": "vec256l9", //如果是Vec768模型,这一项改为"vec768l12"
"speaker_embedding": false
⚠️请注意 “speech_encoder” 行后有一个英文逗号,而 “speaker_embedding” 后没有英文逗号。
简单个人娱乐!切勿作恶!后果自行承担!
参考:https://www.yuque.com/umoubuton/ueupp5