对目标网站的背景调研
- 检查 robot.txt
- 估算网站大小
- 识别网站所用技术
- 寻找网站的所有者
检查 robot.txt
- 目的: 大多数的网站都会包含 robot.txt 文件。该文件用于指出使用爬虫爬取网站时有哪些限制。而我们通过读 robot.txt 文件,亦可以最小化爬虫被封禁的可能。
- 方法: 通过在网站地址后面添加 “/robots.txt”,形成完整的网址,获取该网站对于爬虫的限制信息;
- 案例:
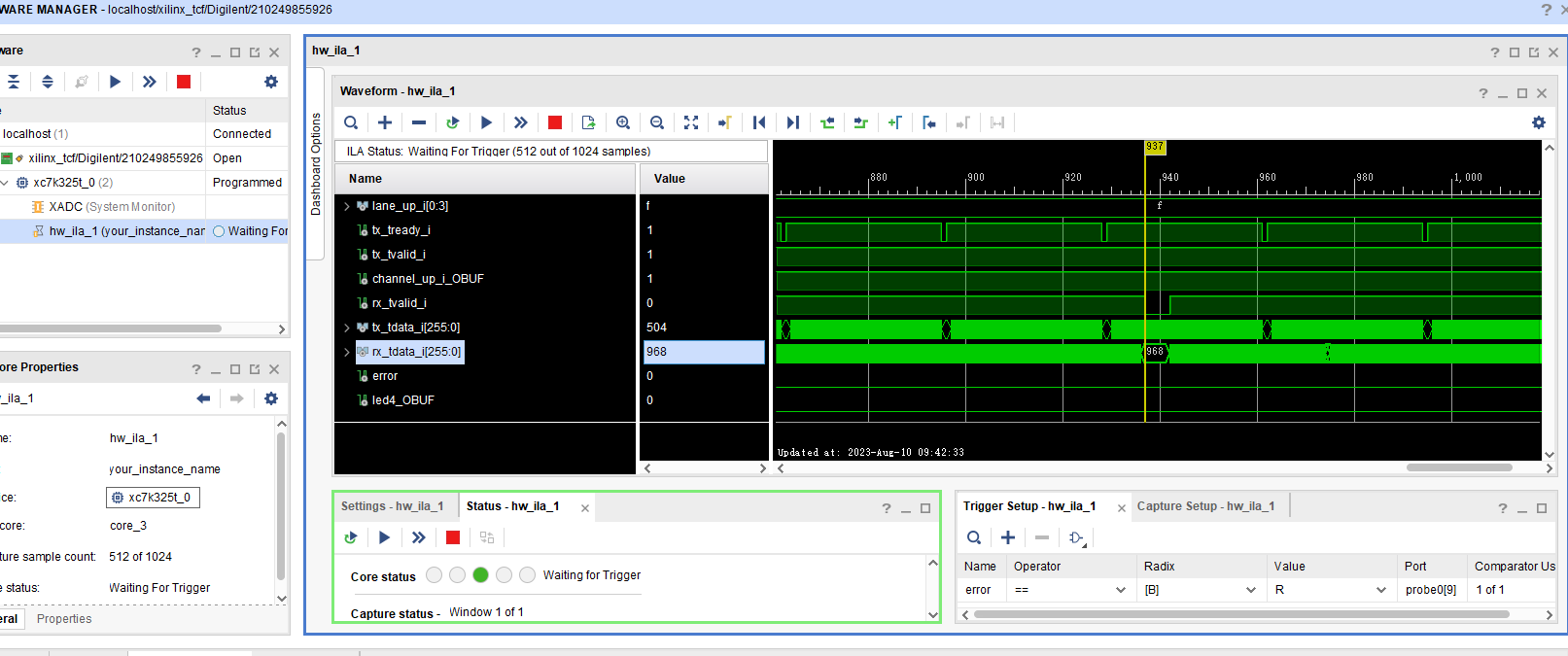
例如:我们想要知道 https://www.csdn.net 即 CSDN 官网的爬虫爬取网站的限制,我们可以通过在网址后添加 “/robots.txt”,形成完整网址:https://www.csdn.net/robots.txt,Enter 访问,看到限制信息如下:
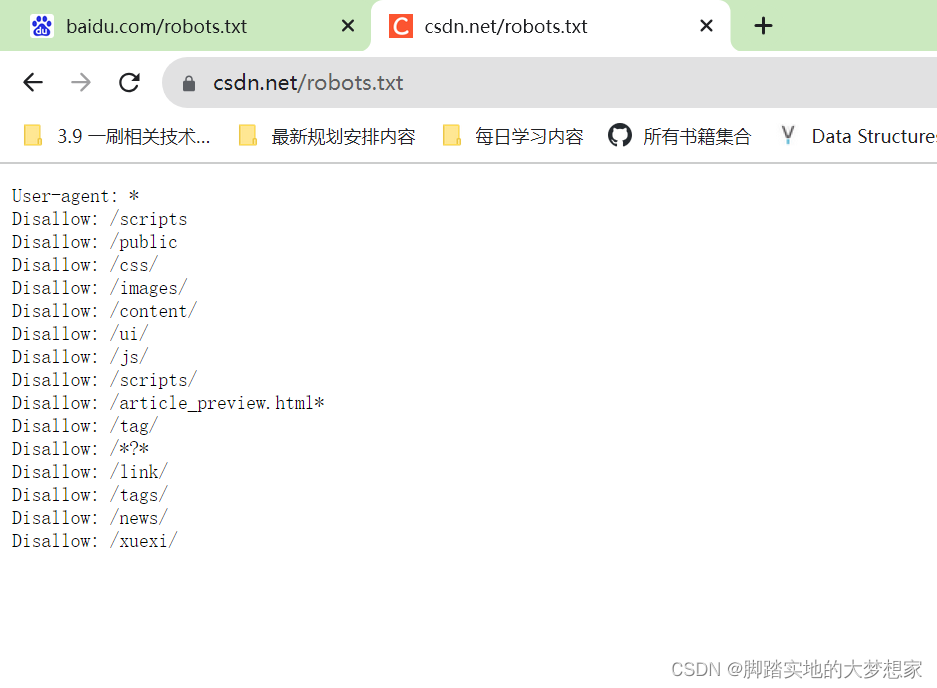
在上图中,我们发现主要包含两个属性:Disallow以及User-agent;- 其中,
"User-agent: *"表示以下所有限制Disallow适用于所有的网络爬虫。 "Disallow: /scripts"表示不允许任何网络爬虫访问网站上的/scripts目录及其下的内容。这意味着爬虫不应该抓取和索引这个目录中的任何内容。
- 其中,
而在访问 baidu 的 robots.txt 文件时,会发现限制不同:
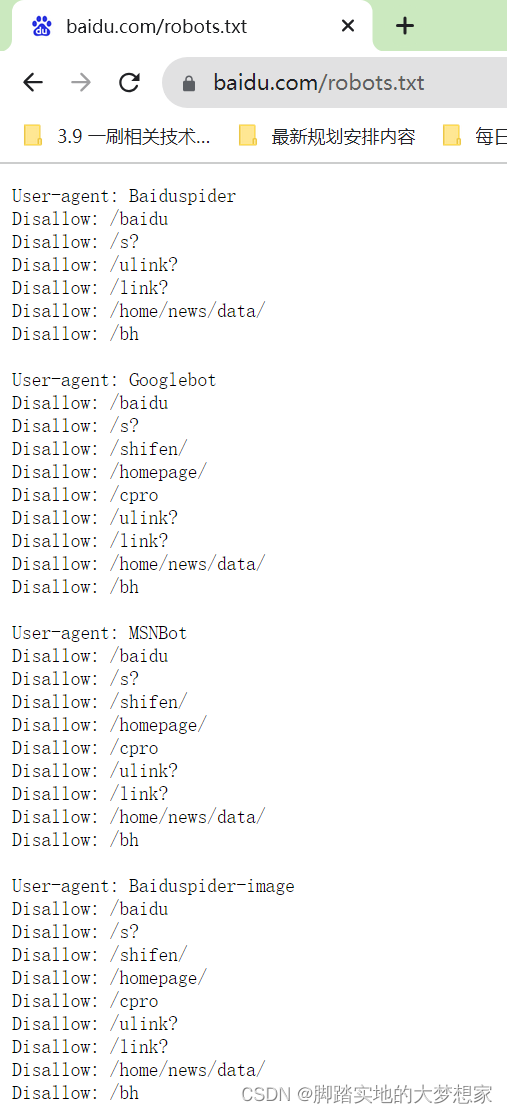
我们提取出第一段解释一下限制信息:
User-agent: Baiduspider
Disallow: /baidu
Disallow: /s?
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
这段 robots.txt 文件中的内容针对百度搜索引擎的爬虫(Baiduspider)定义了一系列规则,指示哪些页面或目录不应该被该搜索引擎的爬虫访问和抓取。这些规则的含义如下:
User-agent: Baiduspider:这条规则定义了适用于百度搜索引擎爬虫(Baiduspider)的规则。Disallow: /baidu:这表示不允许百度爬虫访问网站上的 /baidu 目录及其下的内容。Disallow: /s?:这表示不允许百度爬虫访问类似于 /s? 这样的路径,通常这种路径会包含查询参数。Disallow: /ulink?和Disallow: /link?:这表示不允许百度爬虫访问以 /ulink? 或 /link? 开头的路径,同样是限制查询参数的访问。Disallow: /home/news/data/:这表示不允许百度爬虫访问 /home/news/data/ 目录下的内容。Disallow: /bh:这表示不允许百度爬虫访问 /bh 这个路径。
充分了解如何检查网站爬虫限制后,我们下一步
估算网站大小
-
目的: 对于目标网站大小的估算,会影响我们判断是否采用串行下载还是分布式下载。对于只有数百个 URL 的网站,效率没有那么重要,只需要串行下载即可,但是对于数百万个网页的网站,则需要我们使用分布式下载;
-
方法: 而判断采用串行下载还是分布式下载的第一步,则是对网站的大小做好估算。通过访问 Google 高级搜索网站:https://www.google.com/advanced_search
通过 “高级搜索” 搜索关键字段,如上图下图所示,关于 “理财” 字段全网共有 82,200,000 条结果,即 82,200,000 个网页;
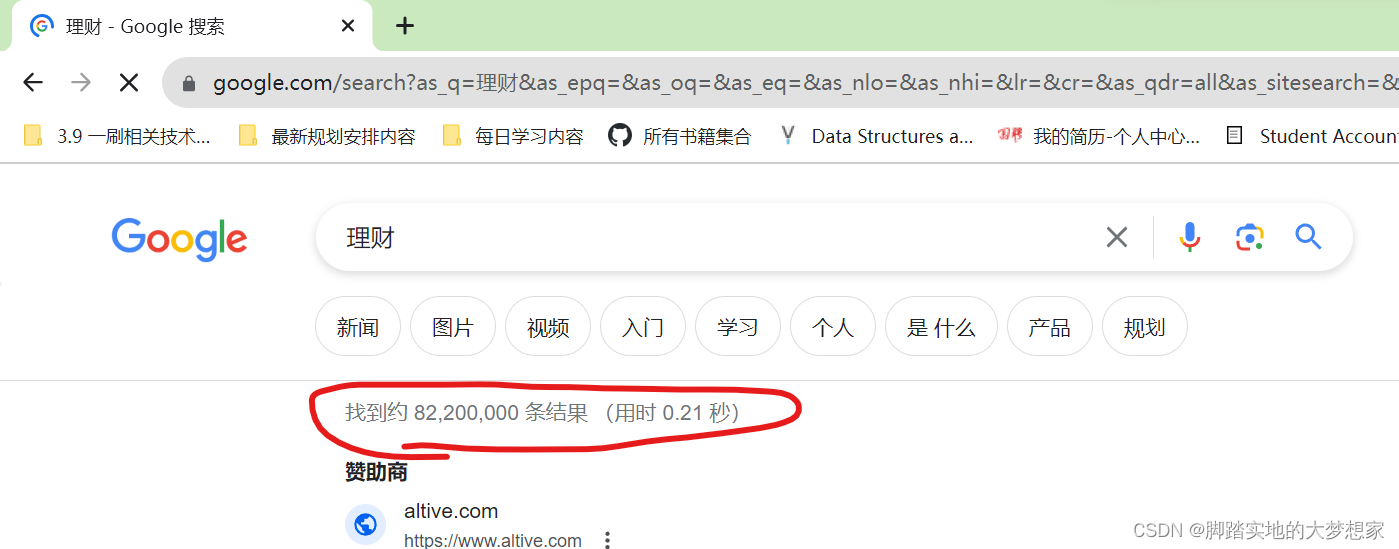
所以根据结果,我们对于 “理财” 信息的爬取,必须通过分布式下载,而非串行下载,因为网站页数数量过大。但是如果我们任务比较紧急,我们只需要获取 baidu 上所有关于 “理财” 字段的网页信息,我们在上述的高级搜索中添加条件即可:
site:www.baidu.com,如下图所示: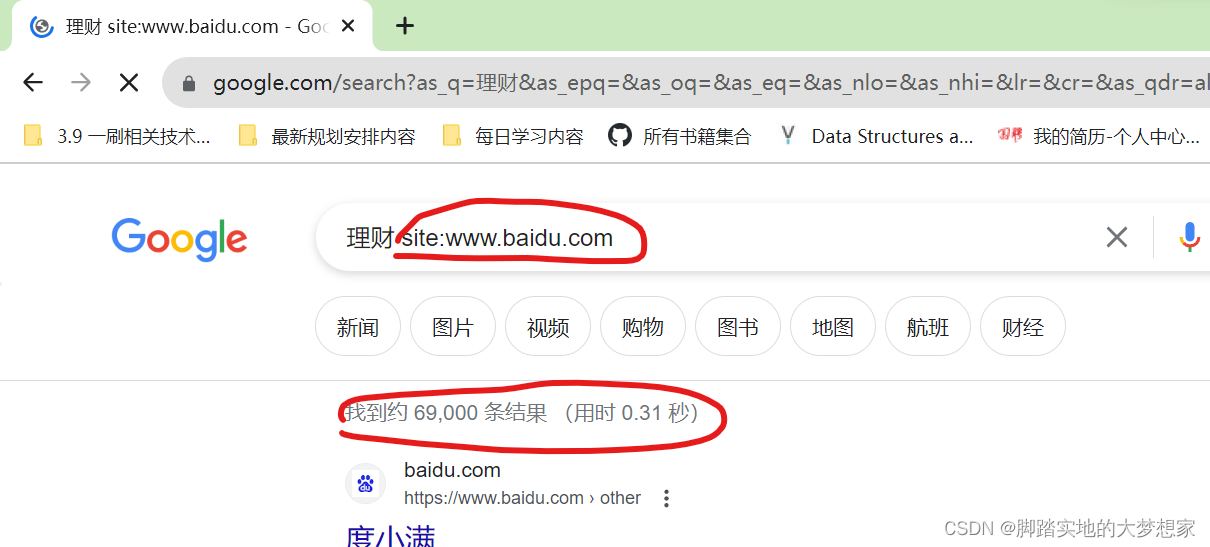
如此筛选,我们发现只有 69,000 条结果,而非上千万条,此时,我们所需时间将大大减少。
识别网站所用技术
-
目的: 网站使用的不同技术,不同框架构建,会对我们如何爬取网站数据有影响。例如,Webpy 框架相对而言比较容易抓取;但是如果改用 AngularJS 构建网站,此时网站内容为动态加载,爬取难度上升;而如果网站使用 ASP.NET 技术,当我们爬取网站时,就必须使用到会话管理和表单提交了。而这些技术与如何爬取的不同方法,将在后续中逐渐阐述出,本节目标为如何得知网址到底使用了什么技术。
-
方法: builtwith 可以检查网站构建的技术类型;
pip install builtwithimport builtwith builtwith.parse("www.baidu.com")但是近些年对于爬虫的限制,导致
builtwith.parse()函数在很多网站不可用,平替的暂时最好方法,是通过网站:https://www.wappalyzer.com/ 进行查看,但是好像需要付费。
寻找网站的所有者
-
目的: 当然,如何需要找到网站的所有者并与之联系,我们可以通过使用 WHOIS 协议查询域名的注册者是谁。
-
方法: python 有针对协议的封装库,具体方案为我们首先:
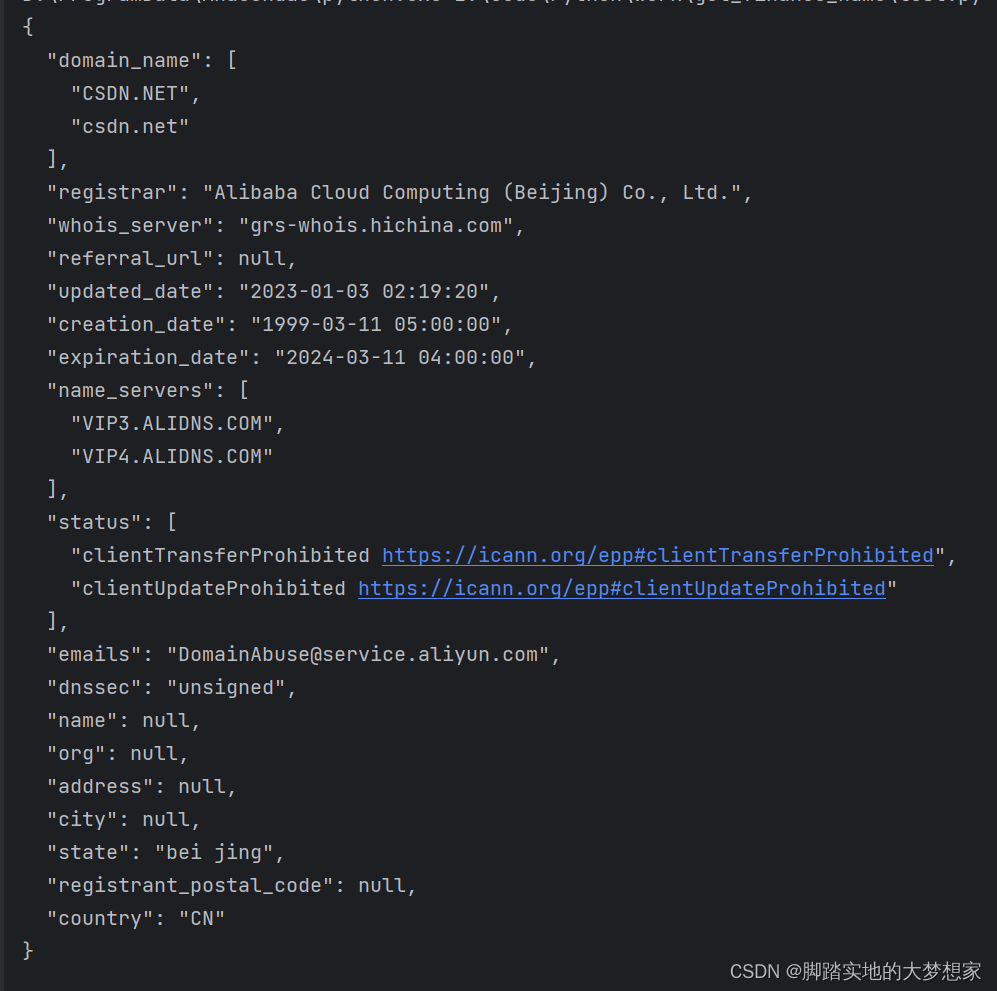
pip install python-whoisimport whois print(whois.whois('www.csdn.net'))结果为:
-
domain_name:列出了域名的主要名称和规范名称,这两者在大小写上略有不同,但指向同一个域名。在这里,主要名称是 “CSDN.NET”,规范名称是 “csdn.net”。
-
registrar:这是域名的注册商或注册服务提供商,即负责管理域名注册的公司。在这里,注册商是 “Alibaba Cloud Computing (Beijing) Co., Ltd.”,这是阿里云计算有限公司。
-
whois_server:这是用于查询域名信息的 WHOIS 服务器。在这里,WHOIS 服务器是 “grs-whois.hichina.com”。
-
updated_date:这是域名信息的最近更新日期。在这里,最近更新的日期是 “2023-01-03 02:19:20”。
-
creation_date:这是域名创建的日期。在这里,域名创建的日期是 “1999-03-11 05:00:00”。
-
expiration_date:这是域名的到期日期。在这里,域名到期的日期是 “2024-03-11 04:00:00”。
-
name_servers:这列出了域名使用的名称服务器(DNS 服务器),它们负责将域名解析为 IP 地址。在这里,有两个名称服务器:“VIP3.ALIDNS.COM” 和 “VIP4.ALIDNS.COM”。
-
status:这个字段列出了域名的状态信息,使用了ICANN定义的状态代码。在这里,状态是 “clientTransferProhibited” 和 “clientUpdateProhibited”,表示在域名的传输和更新方面受到限制。
-
emails:列出了用于与域名注册信息相关问题联系的电子邮件地址。在这里,联系邮箱是 “DomainAbuse@service.aliyun.com”,这是阿里云的服务邮箱。
-
dnssec:这是指定域名是否启用了 DNSSEC(域名系统安全扩展)。在这里,域名的 DNSSEC 设置是 “unsigned”,即未启用。
-
state:这个字段提供了域名注册人所在的州或地区。在这里,注册人所在地是 “bei jing”,即北京。
-
country:这个字段提供了注册人所在的国家/地区。在这里,注册人所在国家是 “CN”,即中国。
这些信息提供了关于域名注册和管理的详细信息,包括注册商、注册人所在地、到期日期等等。
上述内容即关于网站的背景调研方法;