文章目录
- 一、背景
- 二、方法
- 2.1 模型架构
- 2.2 输入和输出
- 2.3 训练
- 三、效果
- 3.1 Image Caption 和 General Visual Question Answering
- 3.2 Text-oriented Visual Question Answering
- 3.3 Refer Expression Comprehension
- 3.4 视觉-语言任务的少样本学习
- 3.5 真实世界用户行为中的指令遵循
论文:Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
代码:https://github.com/QwenLM/Qwen-VL
出处:阿里
时间:2023.10
贡献:
- Qwen-VL 在大量以视觉为中心的理解基准上实现了优秀的性能
- Qwen-VL 支持多语言,尤其是英文和中文,自然的支持英文、中文和多语言指令
- Qwen-VL 在训练阶段支持任意交错的图像-文本数据作为输入
- Qwen-VL 在细粒度的图像理解上更好,因为在训练中使用了更高分辨率的输入大小和细粒度的语料库,有很好的文本阅读、面向文本的问答、细粒度的对话等能力
一、背景
尽管现有的很多多模态大模型取得了不错的效果,但开源的多模态大模型仍然有训练和优化不足的问题,也落后于专有模型,此外,现实场景非常复杂,所以地力度的视觉理解很重要,但相关研究不是很多。
本文开源了一系列 Qwen 家族的模型 Qwen-VL 系列,该系列模型是基于 Qwen-7B 语言模型的,作者通过引入了一个新的 visual capacity,包括一个 language-aligned 视觉编码器和一个 position-aware adapter,来提升 LLM 基准。
整个模型架构及输入输出都很简洁,且作者使用了一个三阶段的训练流程
Qwen-VL 的能力:
- 能够感知和理解视觉输入,根据给定的提示生成回答,并完成各种视觉任务,如 caption、问题回答等
Qwen-VL-Chat:
- 基于 Qwen-VL 的指令调优视觉语言聊天机器人,能够和用户交流,根据用户意图来感知输入图像

二、方法
2.1 模型架构
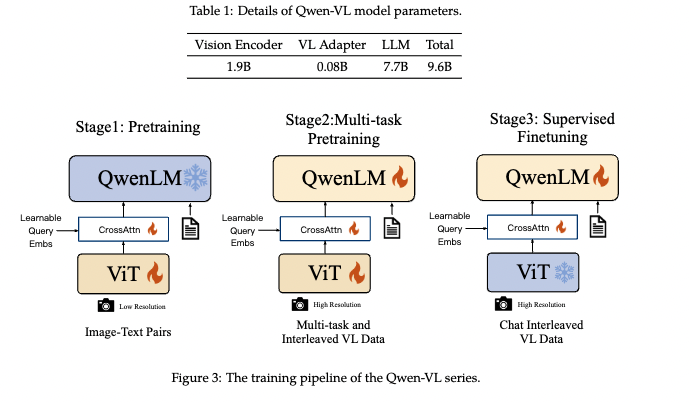
网络整体架构由 3 个部分组成,如表 1 所示:
- 大型语言模型:Qwen-VL 使用大语言模型 Qwen-7b 作为其基础组件,使用预训练好的权重来初始化模型
- 视觉编码器:Qwen-VL 使用 ViT 架构作为视觉编码器,具体的是使用的 Openclip 的 ViT-bigg 预训练的权重进行初始化,在训练过程中,输入图像都被调整到特定的分辨率。且视觉编码器将图像分割成 14 大小的 patch 后生成一组图像特征
- position-aware Vision-Language Adapter:为了环境长图像特征序列带来的效率问题, Qwen-VL 引入了一个压缩图像特征的适配器,该适配器包含一个随机初始化的单层 cross-attention 模块。该模块使用一组可训练的向量(embedding)来作为 query,encoder 提取到的图像特征作为 key,这种机制将视觉特征序列压缩为固定长度 256。
2.2 输入和输出
1、图像输入
图像通过 visual encoder 和 adapter 进行处理,产生固定长度的图像特征序列,为了区分图像特征输入和文本特征输入,在图像特征序列的开始和结束添加了两个特殊标记 ( 和 ),分别表示开始和结束
2、bounding box 输入和输出
为了增强模型对细粒度视觉的理解和定位,Qwen-VL 的训练包括 region description、questions、detections,该任务需要模型以指定格式准确理解和生成区域描述。
对应任何给定的 bbox,使用归一化方法将其归一化到 [0,1000],并转换为指定的字符串格式:“(x1,y1),(x2,y2)”,且在开始和结束处添加 ( 和 ),与其相关的描述语句还会添加特殊标记 ( 和 )
2.3 训练
Qwen-VL 的训练分为三个阶段,前两个阶段是预训练,最后一个阶段是指令微调
1、预训练
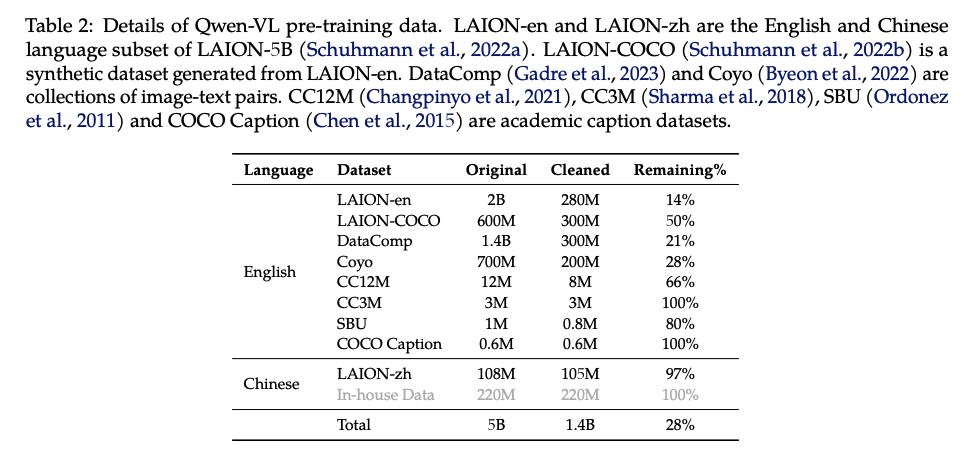
在第一预训练结果,作者主要使用 large-scale,weakly labeled,web-crawled 的 image-text pairs 来训练,数据如表 2 所示,original dataset 包含共 50 亿的图像-文本对儿,清洗后保留了 14 亿的数据,其中 77.3% 的英文数据和 22.7% 的中文数据
在这个阶段,作者将大语言模型冻结,只优化 vision encoder 和 VL adapter,输入图像 resize 到了 224x224,训练的目标是最小化 text token 的 cross-entropy
最大的学习率为 2e-4,batch size 为 30720 个 pairs,整个第一阶段预训练共 50000 steps,共使用 15 亿个图像-文本 pairs
下图为 stage 1 的收敛曲线
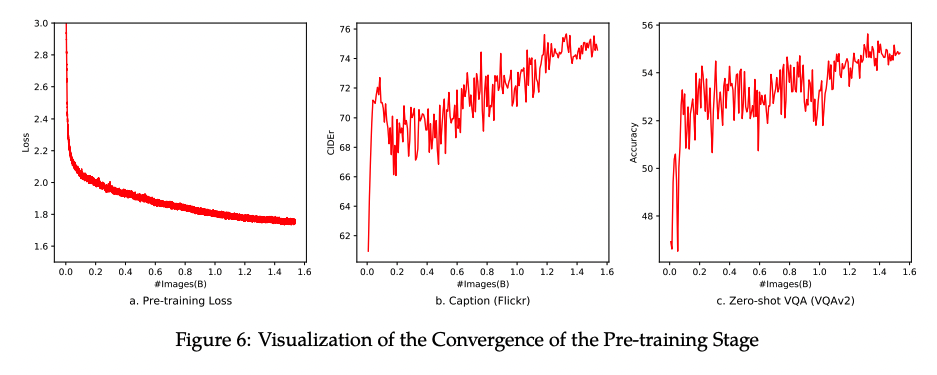
2、多任务预训练
在 stage 2 会进行多任务预训练,会引入有更大分辨率和交错图文数据的高质量和细粒度数据
作者同时对 Qwen-VL 进行了 7 项任务训练,相关数据如表 3 所示,作者将 visual encoder 的输入从 224x224 提升到了 448x448
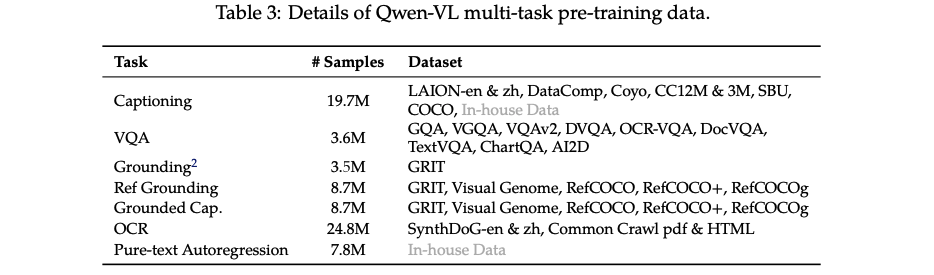
3、有监督微调
在这个阶段,作者对预训练后的模型使用指令微调来提升模型的指令跟随能力和对话能力,来实现交互式的 Qwen-VL-Chat 模型
数据主要来源于 caption 数据或对话数据,这些标签都是使用 LLM 模型得到的,而且这些数据往往只处理单幅图像的对话和推理,仅限于图像内容理解
数据量:350k
训练技巧:冻结 visual encoder,训练语言模型和adapter模块

三、效果
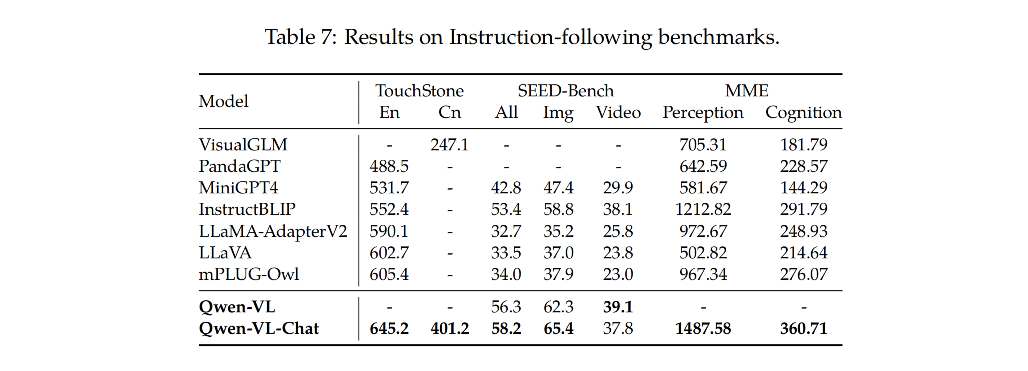
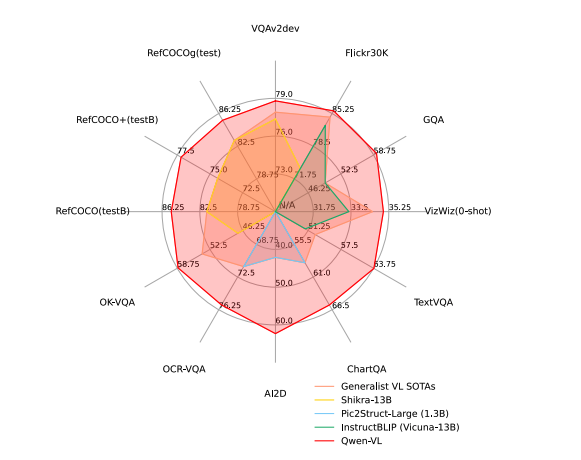
下面作者会对各种多模态任务进行评估,Qwen-VL 表示多任务训练后的模型(第二阶段后),Qwen-VL-chat 表示经过有监督微调(SFT)后的模型(第三阶段后)
3.1 Image Caption 和 General Visual Question Answering
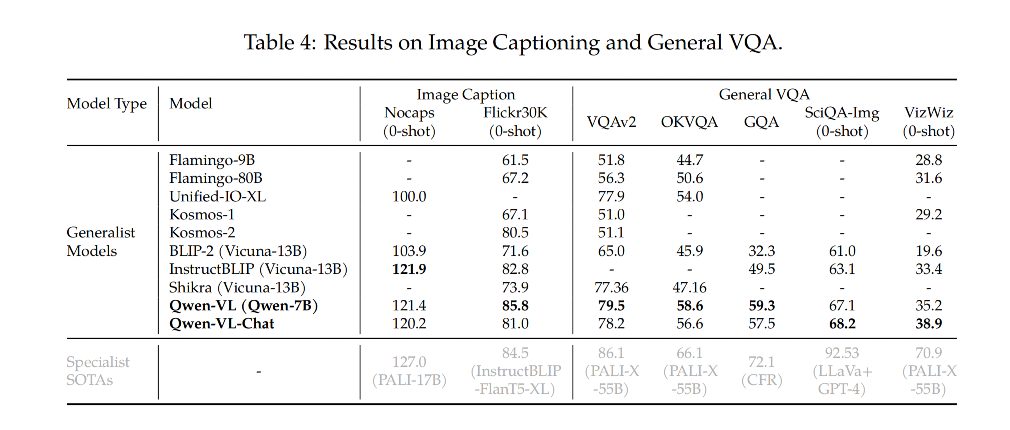
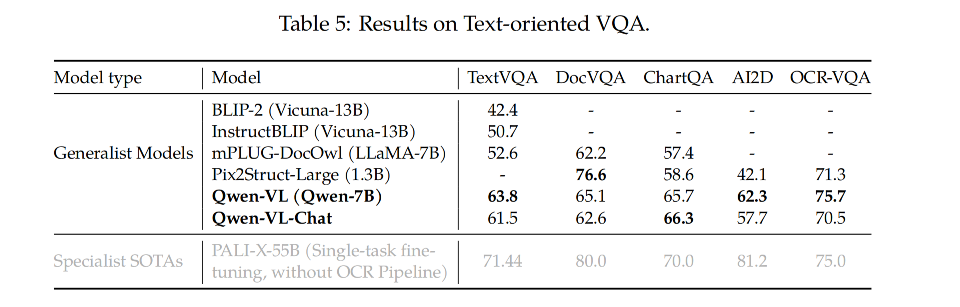
3.2 Text-oriented Visual Question Answering
面向文本的视觉问答
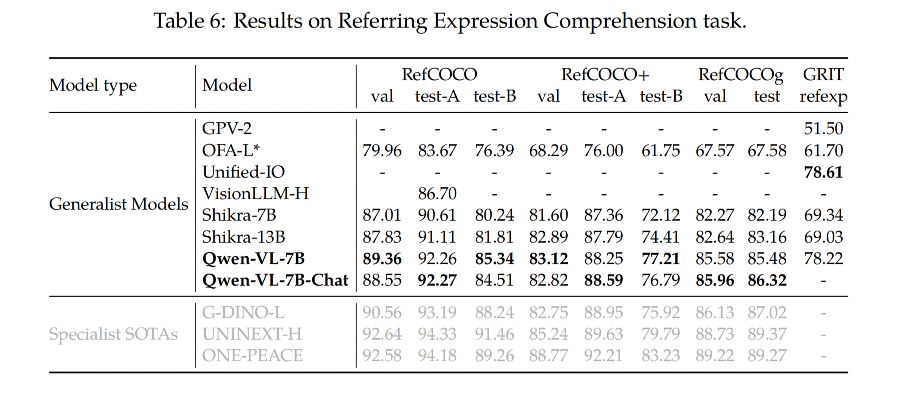
3.3 Refer Expression Comprehension
提及表达的理解
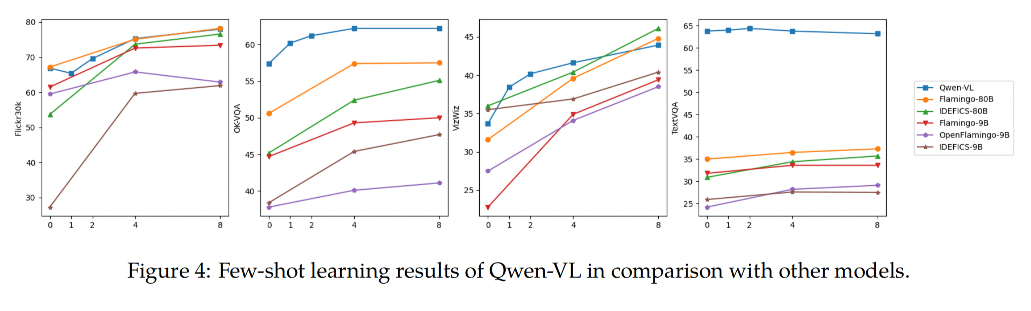
3.4 视觉-语言任务的少样本学习
3.5 真实世界用户行为中的指令遵循