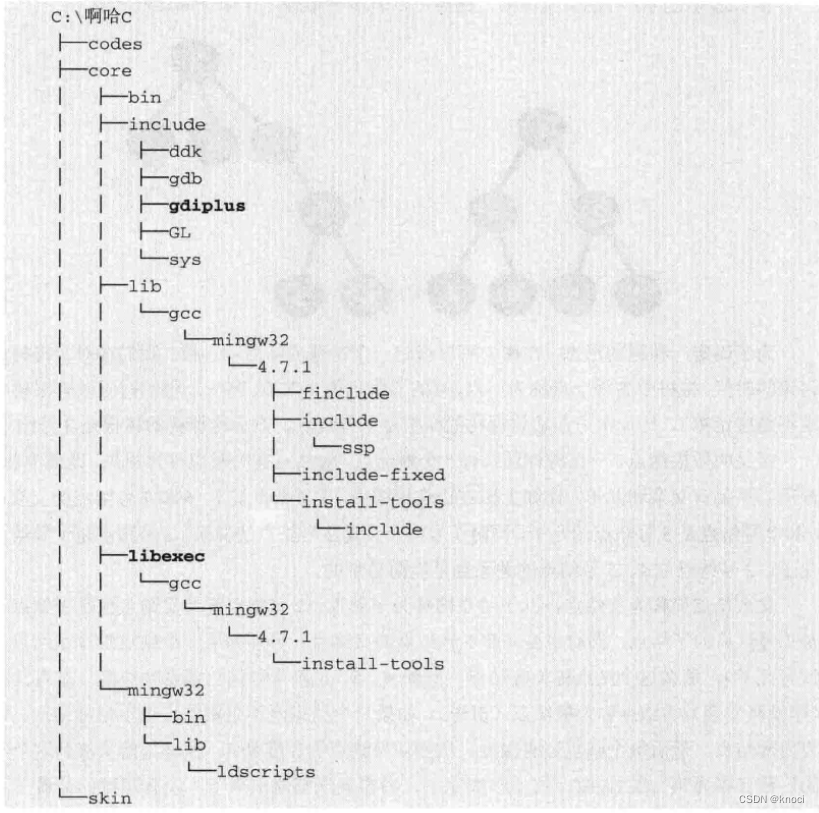
目录
开启“树”之旅
二叉树
堆--优先队列
并查集
开启“树”之旅
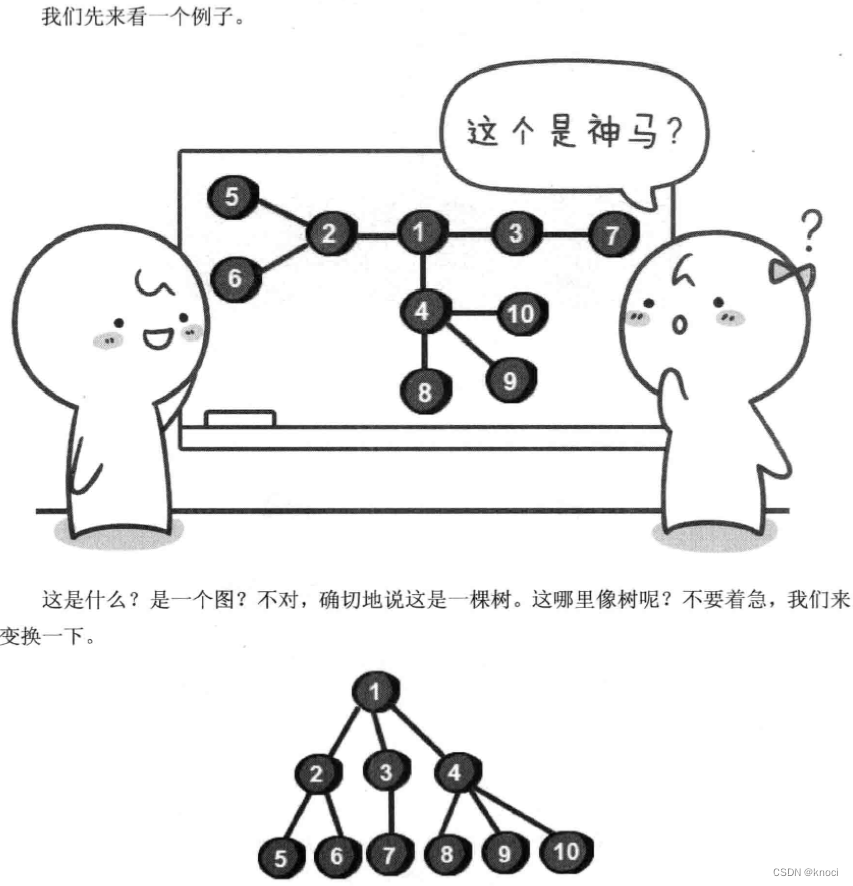
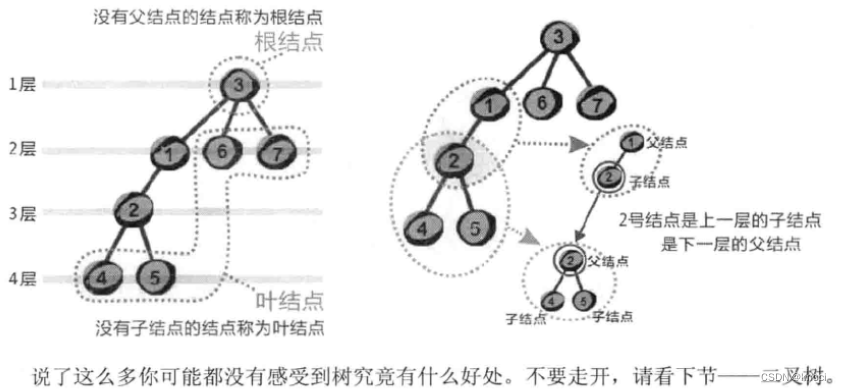
是不是很像一棵倒挂的树?也就是说它是根朝上, 而叶子朝下的。不像?哈哈,来看看下面的图你就会觉得像啦。

你可能会间: 树和图有什么区别?这个称之为树的东西和无向图差不多嘛。不要着急,继续往下看。树其实就是不包含回路的连通无向阳。你可能还是无法理解这其中的差异, 下面举个例子。 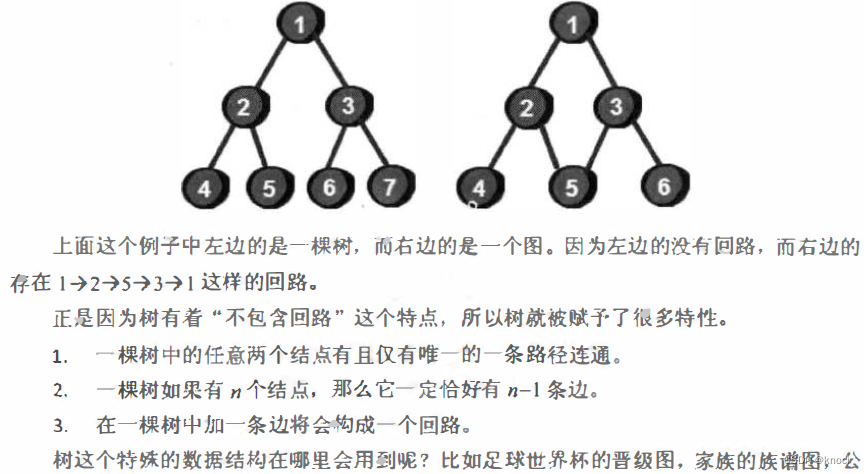




二叉树
二义树是一种特殊的树。二叉树的特点是每个结点最多有两个儿子, 左边的叫做左儿子,右边的叫做右儿子, 或者说每个结点最多有两棵于树。更加严格的递归定义是: 二叉树要么为空, 要么由根结点、左子树和右子树组成, 而左子树和石子树分别是一棵二叉树。下面这棵树就是一棵二叉树。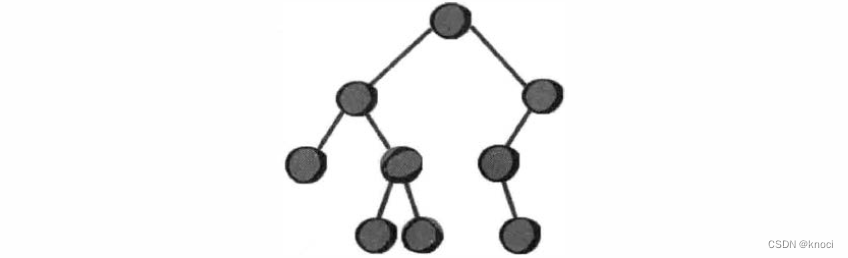
二叉树的使用范阶最广,一棵多叉树也可以转化为二叉树, 因此我们将着重讲解二叉树。
二叉树中还有两种特殊的二叉树, 叫做满二义树和完全二叉树。如果二叉树中每个内部结点都有两个儿子, 这样的二叉树叫做满二叉树。或者说满二义树所有的叶结点都有同样的深度。比如下面这棵二叉树, 是不是感觉很“ 丰满"。满二叉树的严格的定义是一棵深度为h且有2^h-1个结点的二叉树。
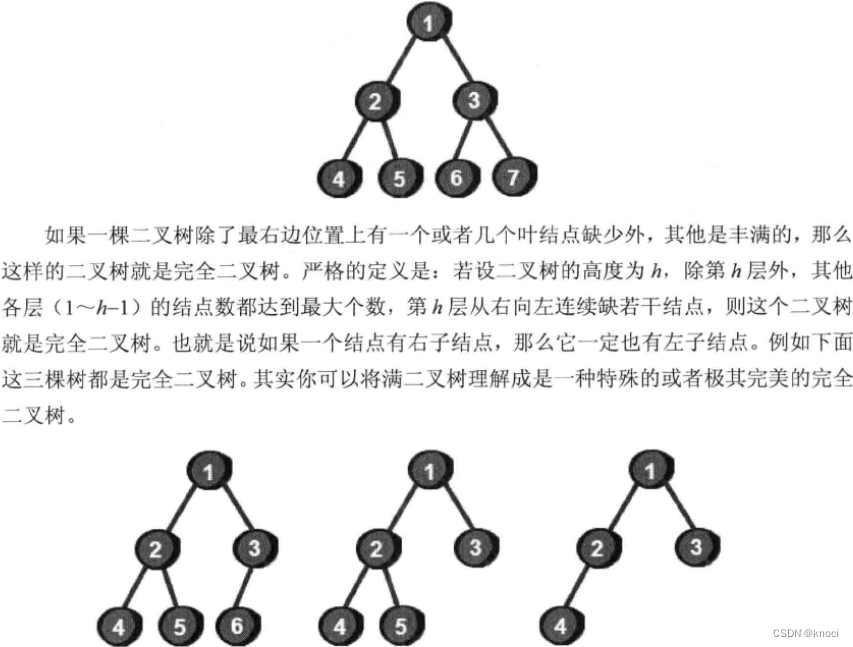
其实完全二叉树类似下面这个形状。

说到这里我们马上就要领略到完全二叉树的魅力了。先想一想: 一棵完全二叉树如何存储呢?其实完全二叉树中父亲和儿子之间有着神奇的规律,我们只需用一个一维数组就可以存储完全二叉树。首先将完全二叉树进行从上到下, 从左到右编号。

堆--优先队列
假如有14 个数, 分别是99、5 、36、7、22、17 、46、12 、2 、19 、25 、28 、1 和92, 请找出这14个数中最小的数, 请间怎么办呢?最简单的方法就是将这14个数从头到尾依次扫一遍, 用一个循环就可以解决。这种方法的时间复杂度是0(14), 也就是O(N) 。
for (i = 1; i <= 14; i++) {if (a [i] <min) {min=a [i];}
}
现在我们需要删除其中最小的数, 并增加一个新数23, 再次求这14 个数中最小的一个数。请间该怎么办呢?只能重新扫描所有的数, 才能找到新的最小的数, 这个时间复杂度也是O(N)。假如现在有14 次这样的操作(删除最小的数后再添加一个新数), 那么整个时间复杂度就是0(14^2)即O(N2)。那有没有更好的方法呢?堆这个特殊的结构恰好能够很好地解决这个问题。
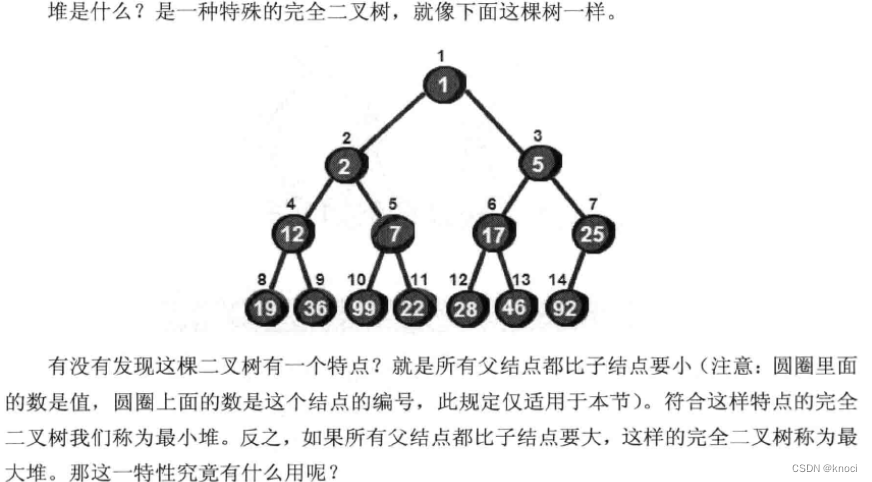
首先我们把这14 个数按照最小堆的要求(就是所有父结点都比子结点要小)放入一棵完全二叉树, 就像下面这棵树一样。

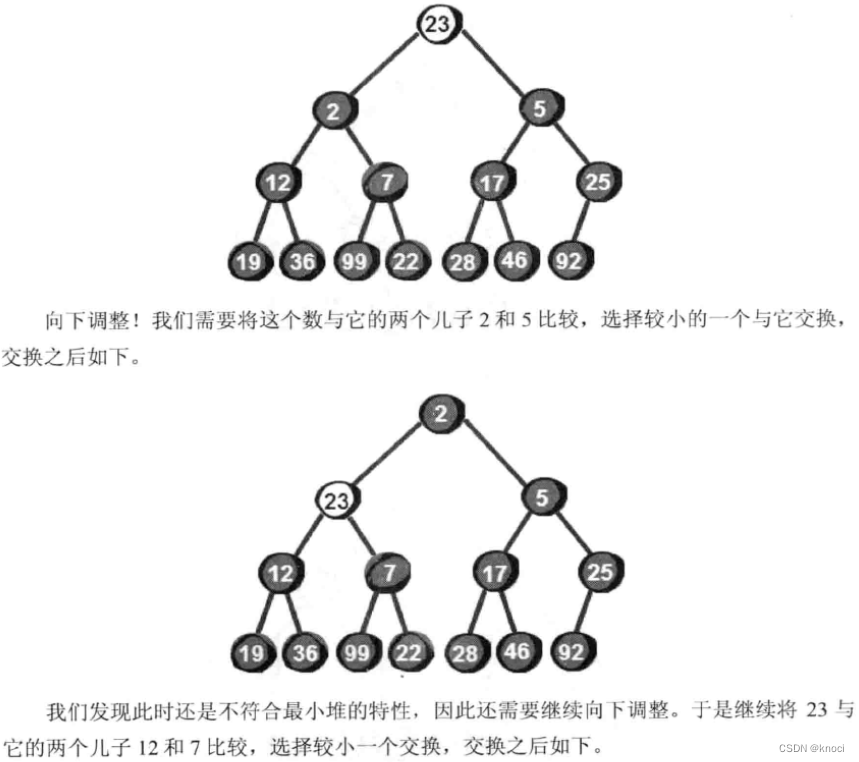
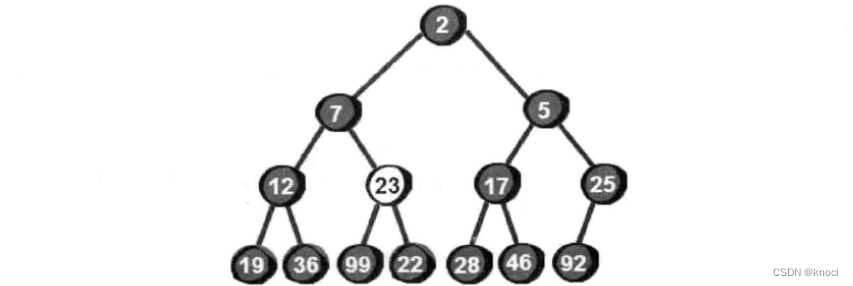
很显然最小的数就在堆顶, 假设存储这个堆的数组叫做h的话, 最小数就是h[1] 。接下来, 我们将堆顶部的数删除。将新增加的数23放到堆顶。显然加了新数后已经不符合最小堆的特性, 我们需要将新增加的数调整到合适的位置。那如何调整呢?
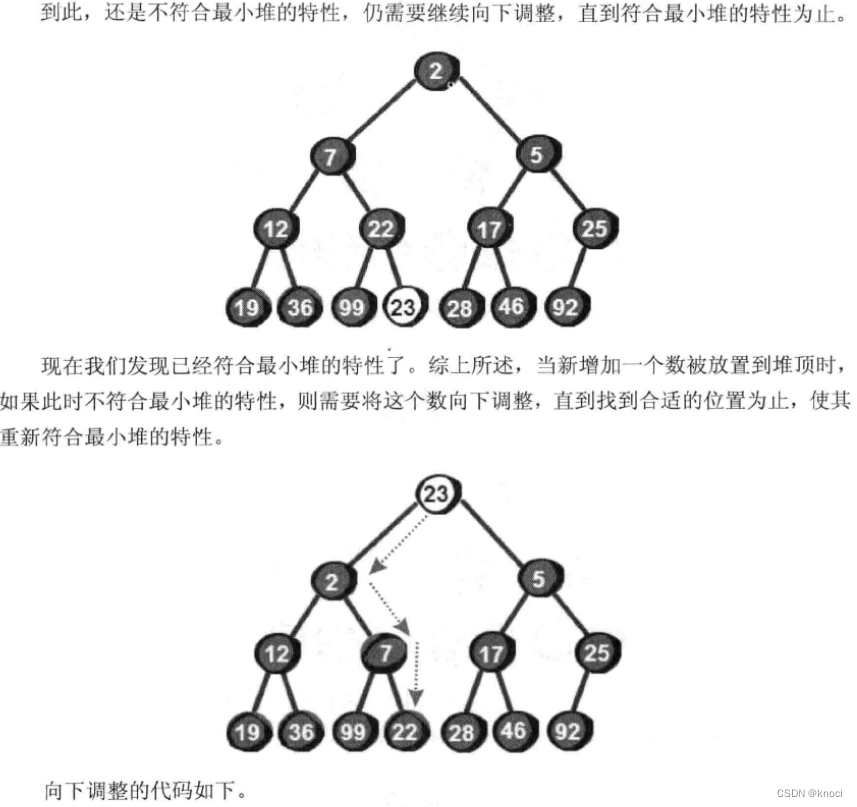
void siftdown(int i) //传入一个需要向下调整的节点编号i,这里传入1,即从堆的顶点开始向下调整
{int t, flag = 0;//flag用来交际是否需要继续向下调整//当i节点有儿子(其实是至少有左儿子的情况下)并且有需要继续调整的时候,循环就执行while(i * 2 <= n && flag == 0) {//首先判断他和左儿子的关系,并用t记录值较小的节点编号if (h[i] > h[i*2]) {t = i * 2;} else {t = i;}//如果他有右儿子,再对有儿子进行讨论if (i * 2 + 1 <= n) {//如果右儿子的值更小,更新较小的节点编号if (h[t] > h[i*2+1]) {t = i * 2 + 1;}}//如果发现最小的节点编号不是自己,说明子节点中有比父节点更小的if (t != i) {swap(t, i);i = t;//更新i为刚才与他交换的儿子节点的编号,便于继续向下调整} else {flag = 1;//否则说明当前父节点小于子节点,不用调整了}}
}

void siftup(int i)//传入一个需要向上调整的节点编号i
{int flag = 0;if (i == 1) {return;//如果是堆顶,返回}//不在堆顶,并且当前节点i的值比父节点小的时候就继续向上调整while(i != 1 && falg == 0) {//判断是否比父节点的小if (h[i] < h[i/2]) {swap(i, i/2);} else {flag = 1;//整理表示已经不用调整,当前节点的值比父节点大}i = i/2;//这句话很重要,更新编号i为他父节点的编号,从而便于下一次继续向上调整}
}说了半天, 我们忽略了一个很重要的问题!就是如何建立这个堆。可以从空的堆开始,然后依次往堆中插入每一个元素, 直到所有数都被插入(转移到堆中)为止。因为插入第i个元索所用的时间是O(log i) ,所以插入所有元索的整体时间复杂度是O(MogN), 代码如下。
n = 0;
for (i = 1; i <= m; i++) {n++;h[n] = a[i];//或写成scanf("%d", &h[n]);siftup();
}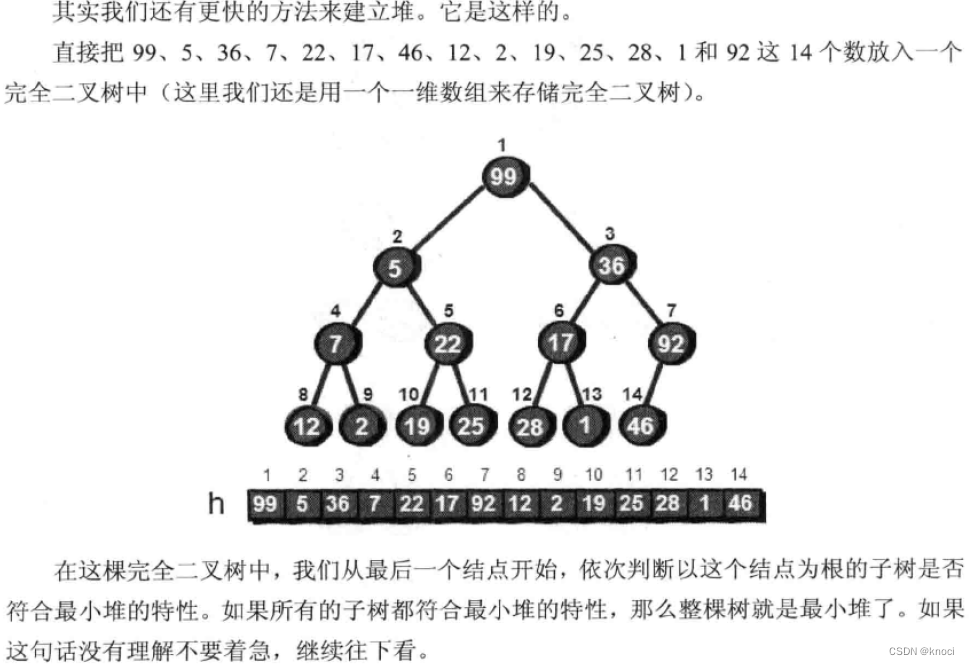

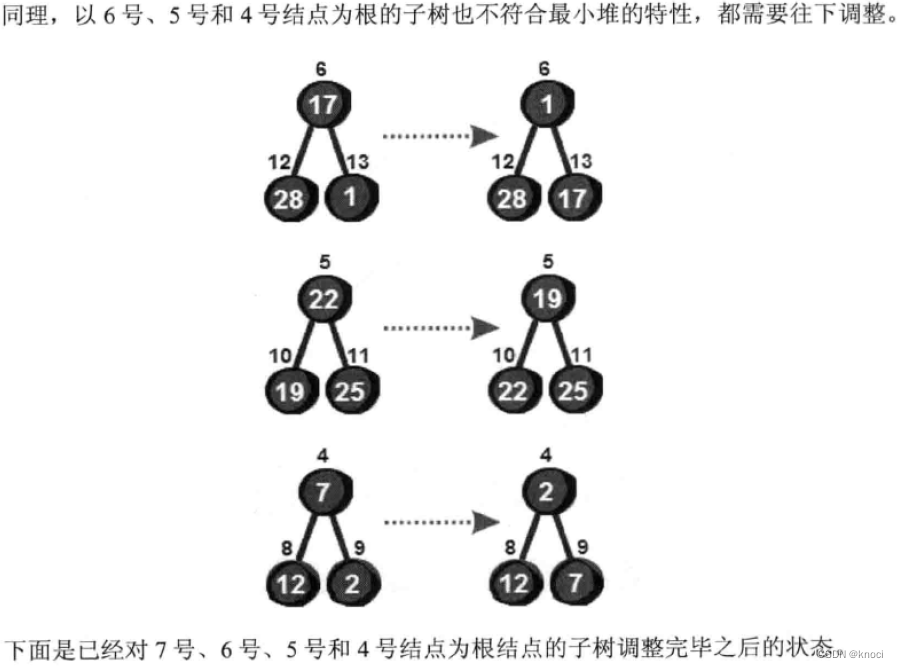


小结一下这个创建堆的算法。把n个元素建立一个堆, 首先我可以将这n个结点以自顶向下、从左到右的方式从1到n编码。这样就可以把这n个结点转换成为一棵完全二叉树。紧接着从最后一个非叶结点(结点编号为n/2)开始到根结点(结点编号为1), 逐个扫描所有的结点, 根据需要将当前结点向下调整, 直到以当前结点为根结点的子树符合堆的特件。虽然讲起来很复杂, 但是实现起来却很简单, 只有两行代码如下:
for (i = n/2; i >= 1; i--) {siftdown(i);
}用这种方法来建立一个堆的时间复杂度是O(N), 堆还有一个作用就是堆排序,与快速排序一样,堆排序的时间复杂度也是O(NlogN).堆排序的实现很简单, 比如我们现在要进行从小到大排序,可以先建立最小堆, 然后每次删除顶部元素并将顶部元素输出或者放入一个新的数组中,直到堆为空为止。最终输出的或者存放在新数组中的数就已经是排序好的了。
//删除最大的元素
int deletemax() {int t;t = h[1];//用一个临时变量记录堆顶点的值h[1] = h[n];//将堆的最后一个点赋值到堆顶n--;//堆的元素减少1siftdown(1);//向下调整return t;//返回之前记录的堆的顶点的最大值
}建堆以及堆排序的完整代码如下:
#include <stdio.h>int h[101]; // 用来存放堆的数组
int n; // 用来存储堆中元素的个数,也就是堆的大小// 交换函数,用来交换堆中的两个元素的值
void swap(int x, int y) {int t;t = h[x];h[x] = h[y];h[y] = t;
}// 向下调整函数
void siftdown(int i) { // 传入一个需要向下调整的结点编号i,这里传入1,即从堆的顶点开始向下调整int t, flag = 0; // flag用来标记是否需要继续向下调整// 当i结点有儿子(其实是至少有左儿子)并且有要继续调整的时候循环就执行while (i * 2 <= n && flag == 0) {// 首先判断它和左儿子的关系,并用t记录值较小的结点编号if (h[i] > h[i * 2])t = i * 2;elset = i;// 如果它有右儿子,再对右儿子进行讨论if (i * 2 + 1 <= n) {// 如果右儿子的值更小,更新较小的结点编号if (h[t] > h[i * 2 + 1])t = i * 2 + 1;}// 如果发现最小的结点编号不是自己,说明子结点中有比父结点更小的if (t != i)swap(t, i); // 交换它们,注意swap函数要自己来写elseflag = 1; // 否则说明当前的父结点已经比两个子结点都要小了,不需要再进行调整了}
}// 建立堆的函数
void create() {int i;// 从最后一个非叶结点到第1个结点依次进行向上调整for (i = n / 2; i >= 1; i--) {siftdown(i);}
}// 删除最大的元素
int deleteMax() {int t;t = h[1]; // 用一个临时变量记录堆顶点的值h[1] = h[n]; // 将堆的最后一个点赋值到堆顶n--; // 堆的元素减少1siftdown(1); // 向下调整return t; // 返回之前记录的堆的顶点的最大值
}int main() {int i, num;// 读入要排序的数字的个数scanf("%d", &num);for (i = 1; i <= num; i++)scanf("%d", &h[i]);n = num;// 建堆create();// 删除顶部元素,连续删除n次,其实也就是从大到小把数输出来for (i = 1; i <= num; i++)printf("%d ", deleteMax());getchar();getchar();return 0;
}当然堆排序还有一种更好的方法。从小到大排序的时候不建立最小堆而建立最大堆, 最大堆建立好后, 最大的元素在h[1],因为我们的需求是从小到大排序, 希望最大的放在最后。因此我们将h[1]和h[n]交换, 此时h[n]就是数组中的最大的元素。请注意, 交换后还需将h[1]向下调整以保持堆的特性。OK, 现在最大的元素已经归位, 需要将堆的大小减1即n--,然后再将h[1]和h[n]交换, 并将h[l]向下调整。如此反复, 直到堆的大小变成1为止。此时数组h中的数就已经是排序好的了。代码如下:
//堆排序
void heapsort() {while(n > 1) {swap(1, n);n--;siftdown(1);}
}完整的堆排序的代码如下,注意使用这种方法来进行从小到大排序需要建立最大堆。
#include <stdio.h>#define lOl 1000 // 用来存放堆的数组大小int h[lOl]; // 用来存放堆的数组
int n; // 用来存储堆中元素的个数,也就是堆的大小// 交换函数,用来交换堆中的两个元素的值
void swap(int x, int y) {int t = h[x];h[x] = h[y];h[y] = t;
}// 向下调整函数
void siftdown(int i) { // 传入一个需要向下调整的结点编号i,这里传入1,即从堆的顶点开始向下调整int t, flag = 0; // flag用来标记是否需要继续向下调整// 当i结点有儿子(其实是至少有左儿子)并且有需要继续调整的时候循环就执行while (i * 2 <= n && flag == 0) {// 首先判断它和左儿子的关系,并用t记录较大的结点编号if (h[i] < h[i * 2])t = i * 2;elset = i;// 如果它有右儿子,再对右儿子进行讨论if (i * 2 + 1 <= n) {// 如果右儿子的值更大,更新较小的结点编号if (h[t] < h[i * 2 + 1])t = i * 2 + 1;}// 如果发现最大的结点编号不是自己,说明子结点中有比父结点更大的if (t != i) {swap(t, i); // 交换它们,注意swap函数需要自己来写i = t; // 更新i为刚才与它交换的儿子结点的编号,便于接下来继续向下调整} else {flag = 1; // 否则说明当前的父结点已经比两个子结点都要大了,不需要再进行调整了}}
}// 建立堆的函数
void create() {int i;// 从最后一个非叶结点到第1个结点依次进行向上调整for (i = n / 2; i >= 1; i--) {siftdown(i);}
}// 堆排序
void heapsort() {while (n > 1) {swap(1, n);n--;siftdown(1);}
}int main() {int i, num;// 读入n个数scanf("%d", &num);for (i = 1; i <= num; i++) {scanf("%d", &h[i]);}n = num;// 建堆create();// 堆排序heapsort();// 输出for (i = 1; i <= num; i++) {printf("%d ", h[i]);}getchar();getchar();return 0;
} 最后还是要总结一下。像这样支持插入元素和寻找最大(小)值元素的数据结构称为优先队列.如果使用普通队列来实现这两个功能,那么寻找最大元素需要枚举整个队列,这样的时间复杂度比较高。如果是已排序好的数组, 那么插入一个元素则需要移动很多元素,时间复杂度依旧很高。而堆就是一种优先队列的实现, 可以很好地解决这两种操作。
另外Dijkstra 算法中每次找离源点最近的一个顶点也可以用堆来优化, 使算法的时间复杂度降到O((M+N)logN)。堆还经常被用来求一个数列中第K 大的数, 只需要建立一个大小为K的最小堆, 堆顶就是第K大的数。(我举个例子, 假设有10个数, 要求第3大的数。第一步选取任意3个数, 比如说是前3个, 将这3个数建成最小堆, 然后从第4个数开始, 与堆顶的数比较, 如果比堆顶的数要小, 那么这个数就不要, 如果比堆顶的数要大, 则舍弃当前堆顶而将这个数做为新的堆顶, 并再去维护堆, 用同样的方法去处理第5~10个数)
并查集
上一节用了很长的篇幅讲解了树在优先队列中的应用一堆的实现。那么树还有哪些神奇的用法呢?咱们从一个故事说起一解密犯罪团伙。

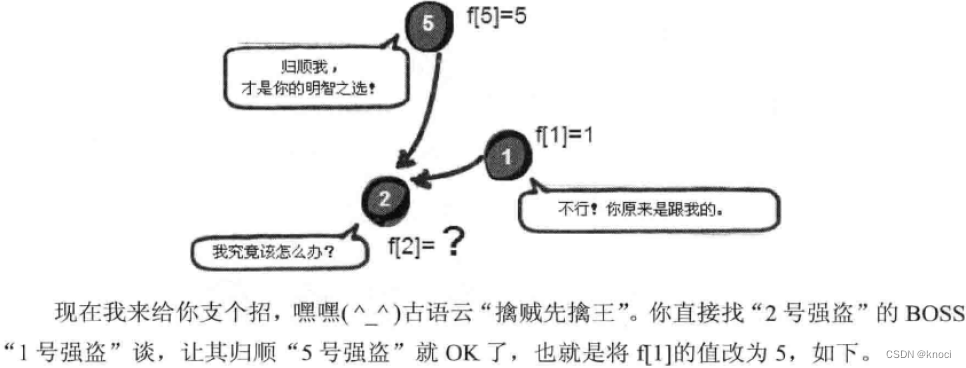
要想解决这个问题, 首先我们假设这10个强盗相互是不认识的, 他们各自为政, 每个人都是首领, 他们只听从自己的。之后我们将通过警方提供的线索,一步步地来“ 合并同伙"。


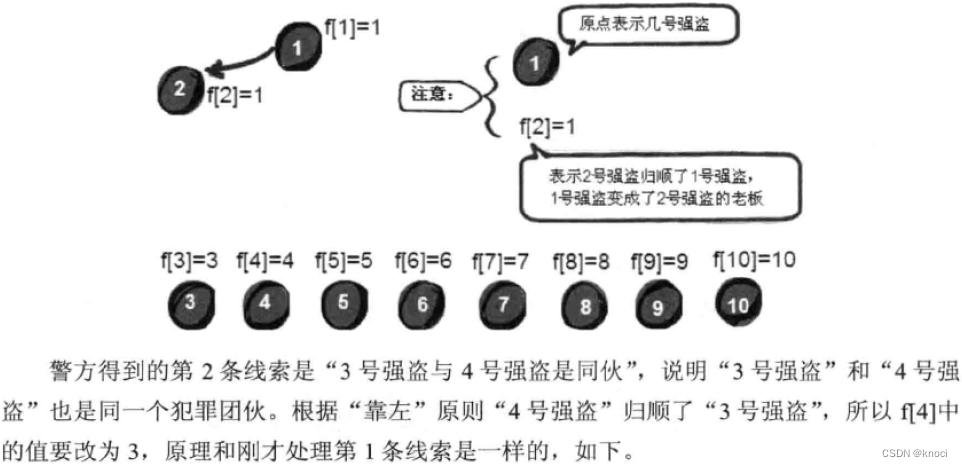
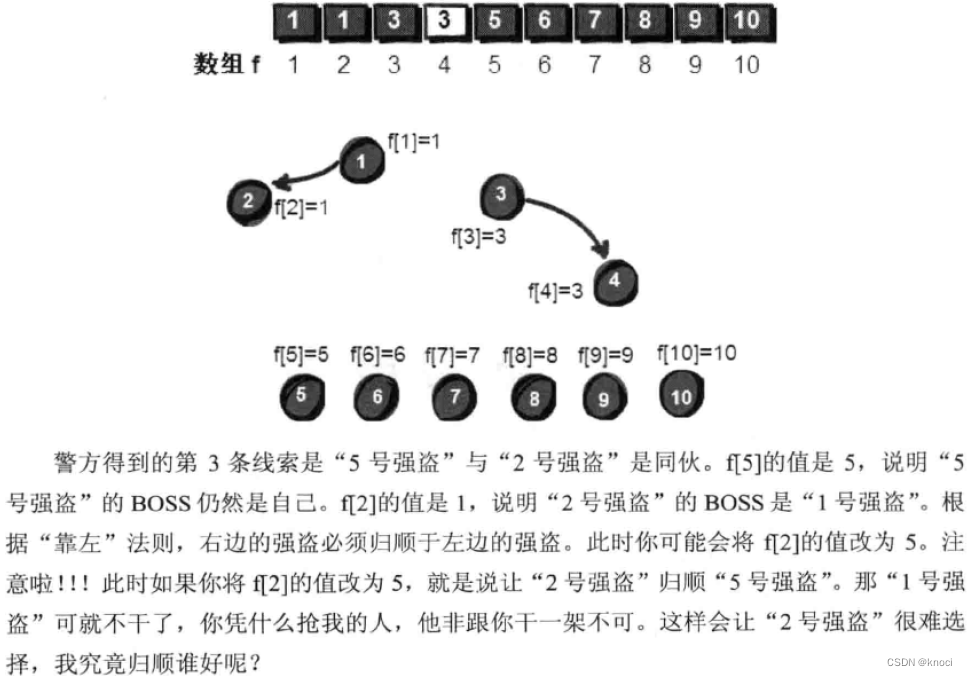

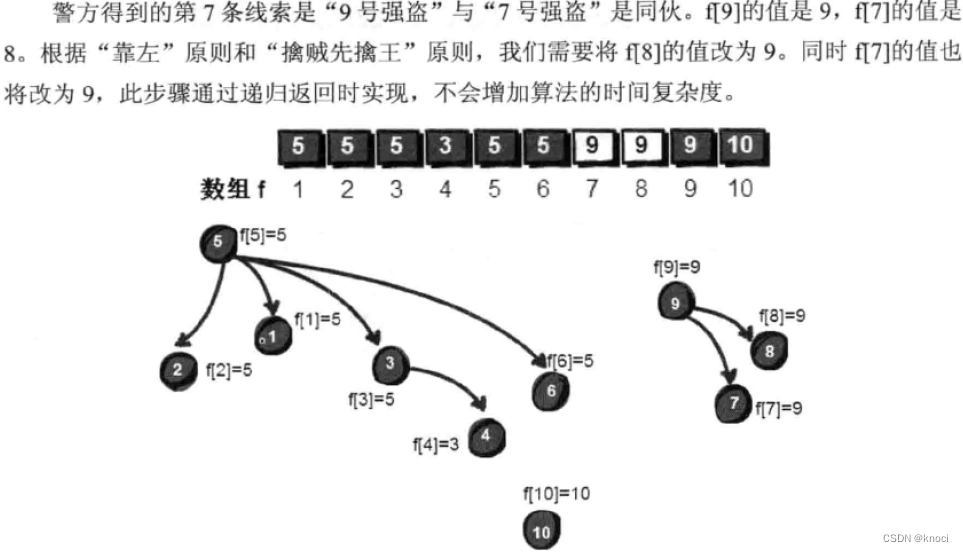



#include <stdio.h>int f[1000] = {0}, n, m, k, sum = 0;// 这里是初始化,非常地重要,数组里面存的是自己数组下标的编号就好了。
void init() {int i;for (i = 1; i <= n; i++) {f[i] = i;}
}// 这是找爹的递归函数,不停地去找爹,直到找到祖宗为止,其实就是去找犯罪团伙的最高领导人,“擒贼先擒王”原则。
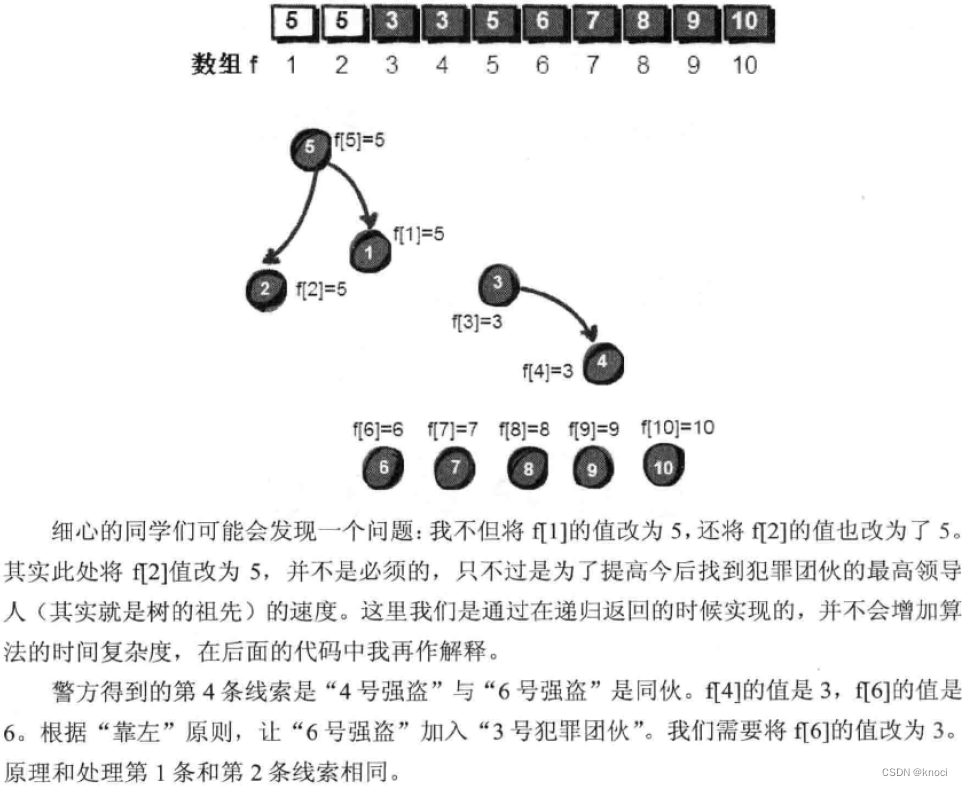
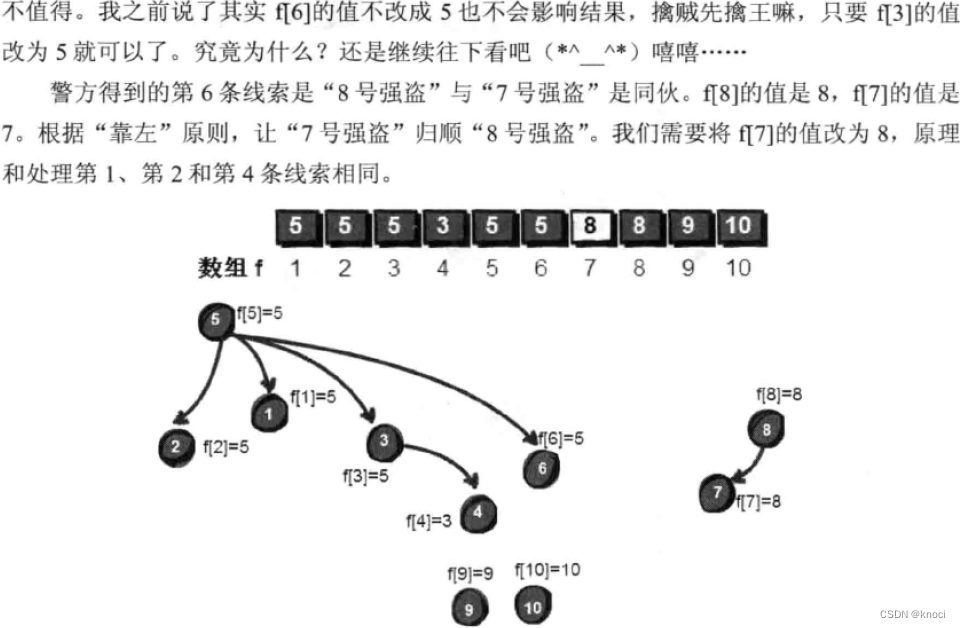
int getf(int v) {if (f[v] == v) {return v;} else {// 这里是路径压缩,每次在函数返回的时候,顺带把路上遇到的v的“BOSS”改为最后找到的祖宗编号,// 也就是犯罪团伙的最高领导人编号。这样可以提高今后找到犯罪团伙的最高领导人(其实就是树的祖先)的速度。f[v] = getf(f[v]);return f[v];}
}// 这里是合并两子集合的函数
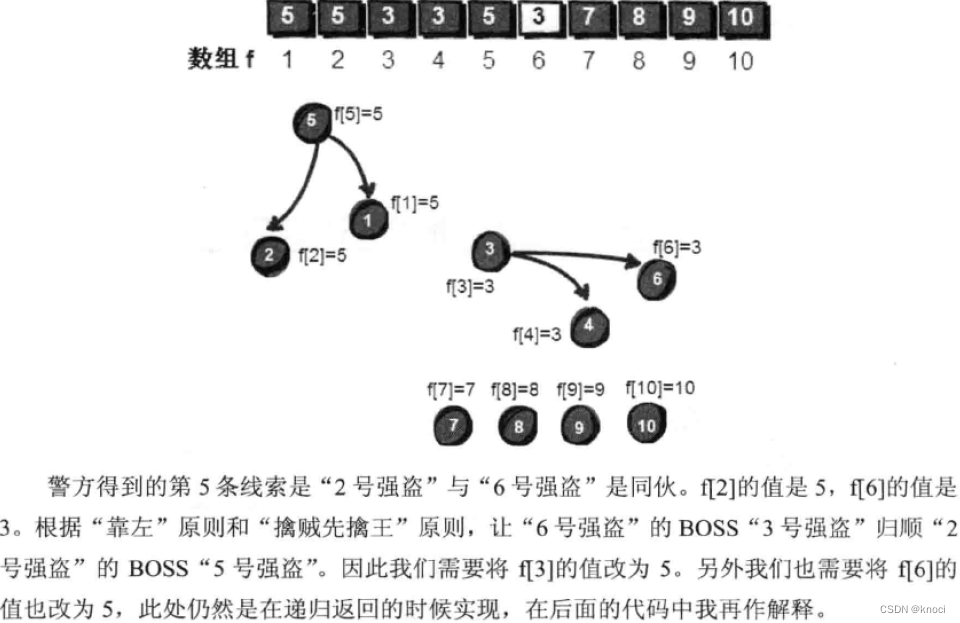
void merge(int v, int u) {int t1, t2;t1 = getf(v);t2 = getf(u);if (t1 != t2) { // 判断两个结点是否在同一个集合中,即是否为问一个祖先。f[t2] = t1;// “靠左”原则,左边变成右边的BOSS。即把右边的集合,作为左边集合的子集合。// 经过路径压缩以后,将f[u]的根的值也赋值为v的祖先f[t1]。}
}// 请从此处开始阅读程序,从主函数开始阅读程序是一个好习惯。
int main() {int i, x, y;scanf("%d %d", &n, &m);// 初始化是必须的init();for (i = 1; i <= m; i++) {// 开始合并犯罪团伙scanf("%d %d", &x, &y);merge(x, y);}// 最后扫描有多少个独立的犯罪团伙for (i = 1; i <= n; i++) {if (f[i] == i) {sum++;}}getchar(); // 清除输入缓冲区getchar(); // 清除输入缓冲区printf("%d\n", sum); // 输出独立团伙数量return 0;
}并查集也称为不相交集数据结构。此算法的发展经历了十多年, 研究它的人也很多, 其中Robert E. Tarjan做出了很大的贡献。在此之前John E. Hopcroft和Jeffrey D. Ullman也进行了大量的分析。你是不是又感觉Robert E. Tarjan和John E. Hopcroft很熟悉?没错, 就是发明了深度优先搜索的两个人一1986年的图灵奖得主。你看牛人们从来都不闲着的。他们到处交流, 寻找合作伙伴,一起改变世界。