Python 机器学习 基础 之 监督学习 [ 神经网络(深度学习)] 算法 的简单说明
目录
Python 机器学习 基础 之 监督学习 [ 神经网络(深度学习)] 算法 的简单说明
一、简单介绍
二、监督学习 算法 说明前的 数据集 说明
三、监督学习 之 神经网络(深度学习)
1、神经网络模型
2、神经网络调参
3、优点、缺点和参数
附录
一、如果报错 ModuleNotFoundError: No module named 'graphviz'
二、参考文献
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
Python 机器学习是利用 Python 编程语言中的各种工具和库来实现机器学习算法和技术的过程。Python 是一种功能强大且易于学习和使用的编程语言,因此成为了机器学习领域的首选语言之一。Python 提供了丰富的机器学习库,如Scikit-learn、TensorFlow、Keras、PyTorch等,这些库包含了许多常用的机器学习算法和深度学习框架,使得开发者能够快速实现、测试和部署各种机器学习模型。
Python 机器学习涵盖了许多任务和技术,包括但不限于:
- 监督学习:包括分类、回归等任务。
- 无监督学习:如聚类、降维等。
- 半监督学习:结合了有监督和无监督学习的技术。
- 强化学习:通过与环境的交互学习来优化决策策略。
- 深度学习:利用深度神经网络进行学习和预测。
通过 Python 进行机器学习,开发者可以利用其丰富的工具和库来处理数据、构建模型、评估模型性能,并将模型部署到实际应用中。Python 的易用性和庞大的社区支持使得机器学习在各个领域都得到了广泛的应用和发展。
二、监督学习 算法 说明前的 数据集 说明
相关说明可见如下链接的 < 二、监督学习 算法 说明前的 数据集 说明 >,这里不在赘述:
数据集 说明:Python 机器学习 基础 之 监督学习 K-NN (K-邻近)算法 的简单说明
三、监督学习 之 神经网络(深度学习)
一类被称为神经网络的算法最近以“深度学习”的名字再度流行。虽然深度学习在许多机器学习应用中都有巨大的潜力,但深度学习算法往往经过精确调整,只适用于特定的使用场景。这里只讨论一些相对简单的方法,即用于分类和回归的多层感知机 (multilayer perceptron,MLP),它可以作为研究更复杂的深度学习方法的起点。MLP 也被称为(普通)前馈神经网络,有时也简称为神经网络。
神经网络,也称为人工神经网络,是一种受生物神经系统启发而设计的计算模型,它由大量互相连接的神经元单元组成,可以用来学习复杂的非线性关系和模式。
深度学习是一种基于神经网络的机器学习方法,它通过多层次的非线性变换来学习数据的表示。每一层都将输入数据转换成更高级的表示形式,最终得到能够解决复杂任务的模型。
神经网络的基本组成部分包括:
输入层(Input Layer):接收原始数据输入的层,每个输入神经元对应一个特征。
隐藏层(Hidden Layer):在输入层和输出层之间的层次,用于学习数据的抽象表示。可以有多个隐藏层,每个隐藏层包含多个神经元单元。
输出层(Output Layer):输出模型的预测结果的层,可以是单个神经元(用于二元分类问题)或多个神经元(用于多类分类或回归问题)。
神经网络通过学习权重和偏置参数来调整网络中的连接,从而使网络能够适应给定的数据和任务。学习过程通常通过反向传播算法来实现,该算法通过计算损失函数的梯度来更新网络的参数,从而最小化预测值与真实值之间的差距。
深度学习中的一些常见神经网络模型包括:
多层感知机(Multilayer Perceptron, MLP):具有多个隐藏层的前馈神经网络,用于解决分类和回归问题。
卷积神经网络(Convolutional Neural Network, CNN):专门用于处理具有网格结构数据(如图像)的神经网络,通过卷积操作来提取空间特征,用于图像识别、物体检测等任务。
循环神经网络(Recurrent Neural Network, RNN):具有循环连接的神经网络,用于处理序列数据(如文本、时间序列),具有记忆性,可以学习长期依赖关系。
长短期记忆网络(Long Short-Term Memory, LSTM):一种特殊的循环神经网络结构,通过门控机制来解决梯度消失和梯度爆炸等问题,用于处理长序列数据的学习和预测。
神经网络和深度学习在各种领域中取得了巨大的成功,包括计算机视觉、自然语言处理、语音识别、推荐系统等。随着计算硬件和算法的不断进步,深度学习的应用范围和性能将继续提升。
1、神经网络模型
MLP 可以被视为广义的线性模型,执行多层处理后得到结论。
还记得线性回归的预测公式为:
![]()
简单来说, 是输入特征 x [0] 到 x [p ] 的加权求和,权重为学到的系数 w [0] 到 w [p ]。我们可以将这个公式可视化,如下图所示。
import mglearn
import matplotlib.pyplot as plt
import graphviz
import os
os.environ["PATH"] += os.pathsep + r'D:\Program Files\Graphviz\bin/'display(mglearn.plots.plot_logistic_regression_graph())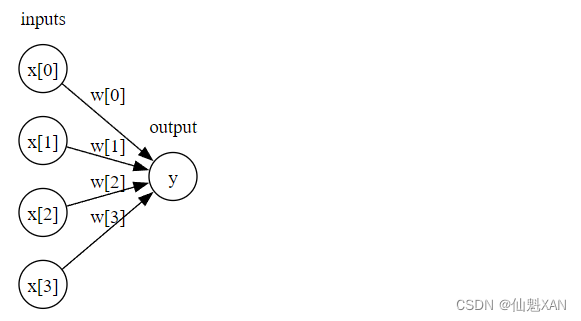
图中,左边的每个结点代表一个输入特征,连线代表学到的系数,右边的结点代表输出,是输入的加权求和。
在 MLP 中,多次重复这个计算加权求和的过程,首先计算代表中间过程的隐单元 (hidden unit),然后再计算这些隐单元的加权求和并得到最终结果
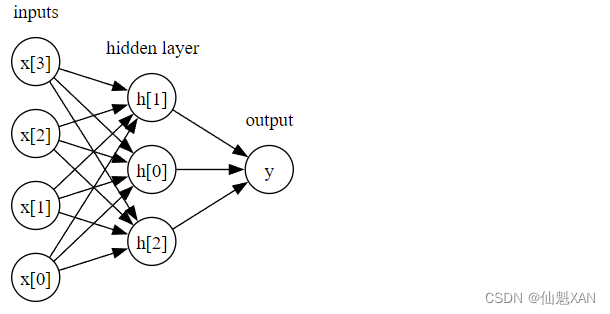
这个模型需要学习更多的系数(也叫作权重):在每个输入与每个隐单元(隐单元组成了隐层 )之间有一个系数,在每个隐单元与输出之间也有一个系数。
从数学的角度看,计算一系列加权求和与只计算一个加权求和是完全相同的,因此,为了让这个模型真正比线性模型更为强大,我们还需要一个技巧。在计算完每个隐单元的加权求和之后,对结果再应用一个非线性函数——通常是校正非线性 (rectifying nonlinearity,也叫校正线性单元或 relu)或正切双曲线(tangens hyperbolicus,tanh)。然后将这个函数的结果用于加权求和,计算得到输出 。这两个函数的可视化效果见图 2-46。relu 截断小于 0 的值,而 tanh 在输入值较小时接近 -1,在输入值较大时接近 +1。有了这两种非线性函数,神经网络可以学习比线性模型复杂得多的函数。
line = np.linspace(-3, 3, 100)
plt.plot(line, np.tanh(line), label="tanh")
plt.plot(line, np.maximum(line, 0), label="relu")
plt.legend(loc="best")
plt.xlabel("x")
plt.ylabel("relu(x), tanh(x)")
plt.savefig('Images/07NeuralNetwork-01.png', bbox_inches='tight')
plt.show()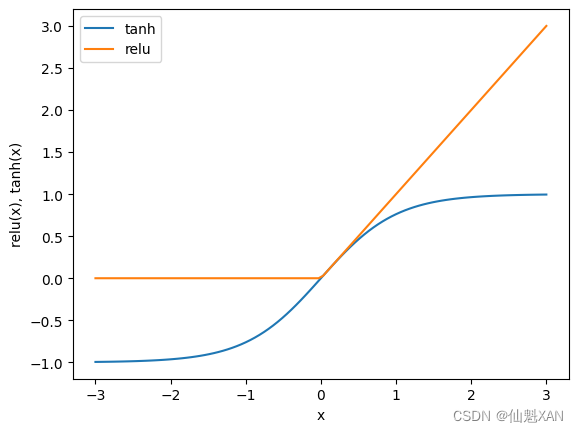
对于之前图所示的小型神经网络,计算回归问题的 的完整公式如下(使用 tanh 非线性):
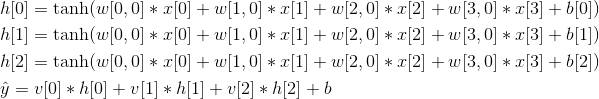
其中,w 是输入 x 与隐层 h 之间的权重,v 是隐层 h 与输出 之间的权重。权重 w 和 v 要从数据中学习得到,x 是输入特征,
是计算得到的输出,h 是计算的中间结果。需要用户设置的一个重要参数是隐层中的结点个数。对于非常小或非常简单的数据集,这个值可以小到 10;对于非常复杂的数据,这个值可以大到 10 000。也可以添加多个隐层,如下图所示。
mglearn.plots.plot_two_hidden_layer_graph()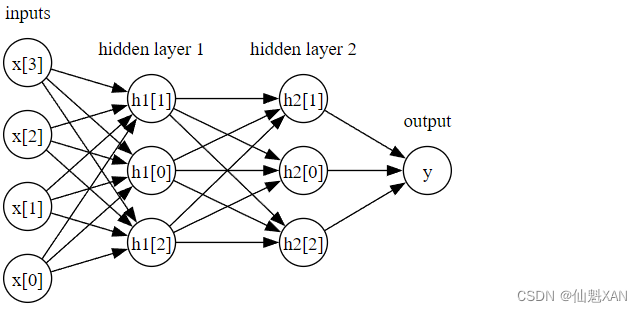
这些由许多计算层组成的大型神经网络,正是术语“深度学习”的灵感来源。
2、神经网络调参
我们将 MLPClassifier 应用到本章前面用过的 two_moons 数据集上,以此研究 MLP 的工作原理。结果如下图所示。
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_splitX, y = make_moons(n_samples=100, noise=0.25, random_state=3)X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y,random_state=42)mlp = MLPClassifier(solver='lbfgs', random_state=0).fit(X_train, y_train)
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.savefig('Images/07NeuralNetwork-02.png', bbox_inches='tight')
plt.show()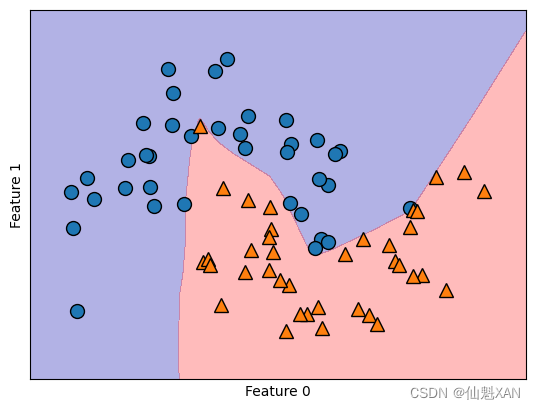
如你所见,神经网络学到的决策边界完全是非线性的,但相对平滑。我们用到了 solver='lbfgs' ,这一点稍后会讲到。
默认情况下,MLP 使用 100 个隐结点,这对于这个小型数据集来说已经相当多了。我们可以减少其数量(从而降低了模型复杂度),但仍然得到很好的结果(如下图):
mlp = MLPClassifier(solver='lbfgs', random_state=0, hidden_layer_sizes=[10])
mlp.fit(X_train, y_train)
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.savefig('Images/07NeuralNetwork-03.png', bbox_inches='tight')
plt.show()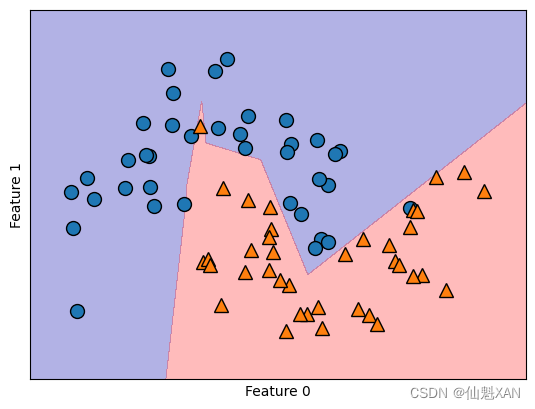
只有 10 个隐单元时,决策边界看起来更加参差不齐。默认的非线性是 relu,如上图所示。如果使用单隐层,那么决策函数将由 10 个直线段组成。如果想得到更加平滑的决策边界,可以添加更多的隐单元(见上图)、添加第二个隐层(见下图)或者使用 tanh 非线性(见下下图)。
# 使用2个隐层,每个包含10个单元
mlp = MLPClassifier(solver='lbfgs', random_state=0,hidden_layer_sizes=[10, 10])
mlp.fit(X_train, y_train)
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.savefig('Images/07NeuralNetwork-04.png', bbox_inches='tight')
plt.show()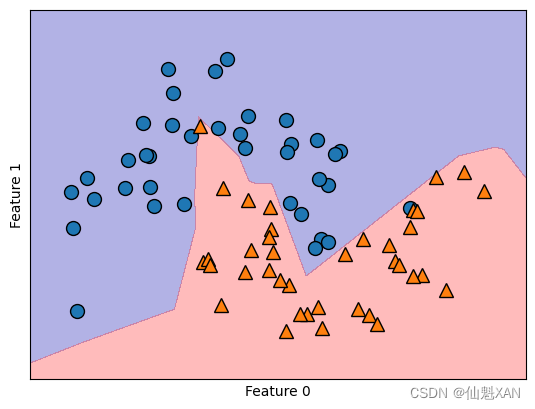
# 使用2个隐层,每个包含10个单元,这次使用tanh非线性
mlp = MLPClassifier(solver='lbfgs', activation='tanh',random_state=0, hidden_layer_sizes=[10, 10])
mlp.fit(X_train, y_train)
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.savefig('Images/07NeuralNetwork-05.png', bbox_inches='tight')
plt.show()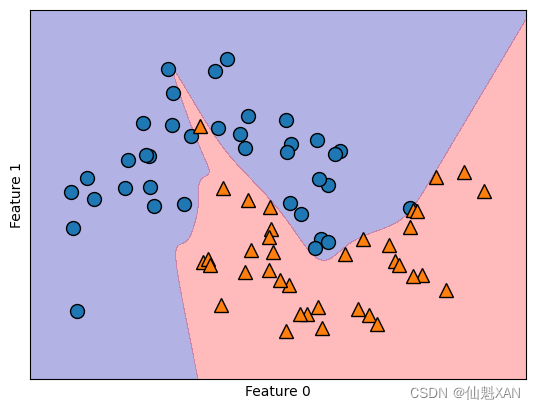
最后,我们还可以利用 L2 惩罚使权重趋向于 0,从而控制神经网络的复杂度,正如我们在岭回归和线性分类器中所做的那样。MLPClassifier 中调节 L2 惩罚的参数是 alpha (与线性回归模型中的相同),它的默认值很小(弱正则化)。下图显示了不同 alpha 值对 two_moons 数据集的影响,用的是 2 个隐层的神经网络,每层包含 10 个或 100 个单元:
fig, axes = plt.subplots(2, 4, figsize=(20, 8))
for axx, n_hidden_nodes in zip(axes, [10, 100]):for ax, alpha in zip(axx, [0.0001, 0.01, 0.1, 1]):mlp = MLPClassifier(solver='lbfgs', random_state=0,hidden_layer_sizes=[n_hidden_nodes, n_hidden_nodes],alpha=alpha)mlp.fit(X_train, y_train)mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3, ax=ax)mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train, ax=ax)ax.set_title("n_hidden=[{}, {}]\nalpha={:.4f}".format(n_hidden_nodes, n_hidden_nodes, alpha))plt.savefig('Images/07NeuralNetwork-06.png', bbox_inches='tight')
plt.show()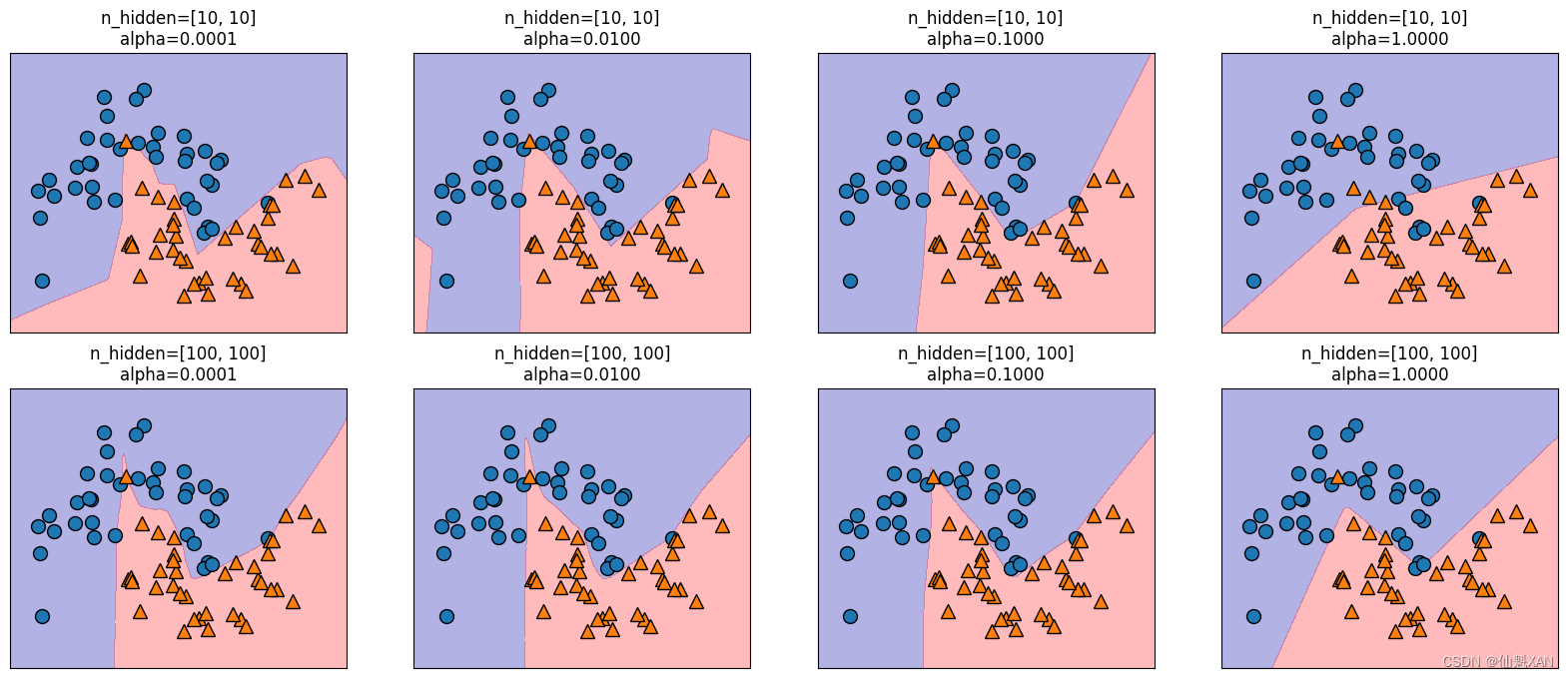
现在你可能已经认识到了,控制神经网络复杂度的方法有很多种:隐层的个数、每个隐层中的单元个数与正则化(alpha )。实际上还有更多,但这里不再过多介绍。
神经网络的一个重要性质是,在开始学习之前其权重是随机设置的,这种随机初始化会影响学到的模型。也就是说,即使使用完全相同的参数,如果随机种子不同的话,我们也可能得到非常不一样的模型。如果网络很大,并且复杂度选择合理的话,那么这应该不会对精度有太大影响,但应该记住这一点(特别是对于较小的网络)。下图 显示了几个模型的图像,所有模型都使用相同的参数设置进行学习:
fig, axes = plt.subplots(2, 4, figsize=(20, 8))
for i, ax in enumerate(axes.ravel()):mlp = MLPClassifier(solver='lbfgs', random_state=i,hidden_layer_sizes=[100, 100])mlp.fit(X_train, y_train)mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3, ax=ax)mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train, ax=ax)plt.savefig('Images/07NeuralNetwork-07.png', bbox_inches='tight')
plt.show()
为了在现实世界的数据上进一步理解神经网络,我们将 MLPClassifier 应用在乳腺癌数据集上。首先使用默认参数:
from sklearn.datasets import load_breast_cancercancer = load_breast_cancer()
print("Cancer data per-feature maxima:\n{}".format(cancer.data.max(axis=0)))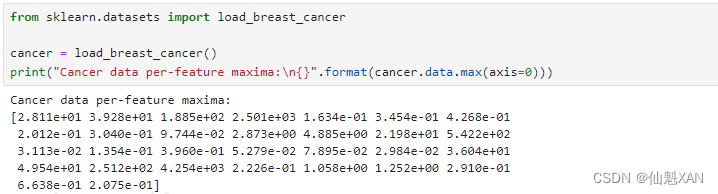
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=0)mlp = MLPClassifier(random_state=42)
mlp.fit(X_train, y_train)print("Accuracy on training set: {:.2f}".format(mlp.score(X_train, y_train)))
print("Accuracy on test set: {:.2f}".format(mlp.score(X_test, y_test)))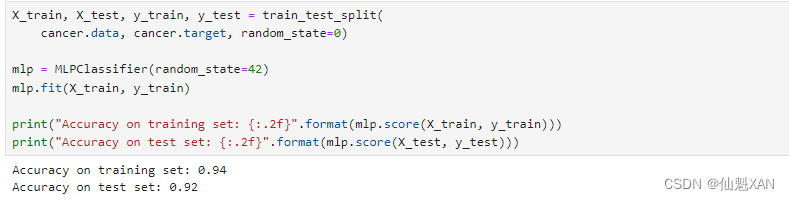
MLP 的精度相当好,但没有其他模型好。与较早的 SVC 例子相同,原因可能在于数据的缩放。神经网络也要求所有输入特征的变化范围相似,最理想的情况是均值为 0、方差为 1。我们必须对数据进行缩放以满足这些要求。同样,我们这里将人工完成,但在第 3 章将会介绍用 StandardScaler 自动完成:
# 计算训练集中每个特征的平均值
mean_on_train = X_train.mean(axis=0)
# 计算训练集中每个特征的标准差
std_on_train = X_train.std(axis=0)# 减去平均值,然后乘以标准差的倒数
# 如此运算之后,mean=0,std=1
X_train_scaled = (X_train - mean_on_train) / std_on_train
# 对测试集做相同的变换(使用训练集的平均值和标准差)
X_test_scaled = (X_test - mean_on_train) / std_on_trainmlp = MLPClassifier(random_state=0)
mlp.fit(X_train_scaled, y_train)print("Accuracy on training set: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))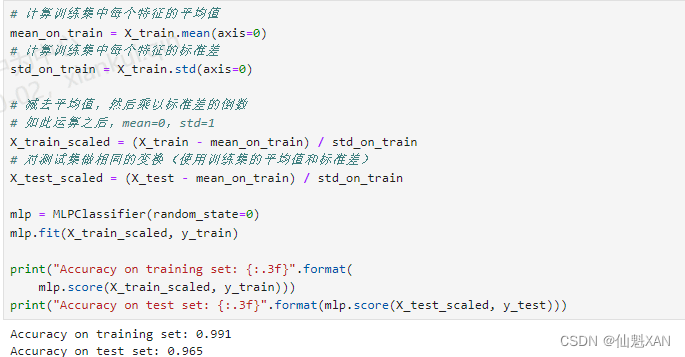
缩放之后的结果要好得多,而且也相当有竞争力。不过模型给出了一个警告,告诉我们已经达到最大迭代次数。这是用于学习模型的 adam 算法的一部分,告诉我们应该增加迭代次数:
mlp = MLPClassifier(max_iter=1000, random_state=0)
mlp.fit(X_train_scaled, y_train)print("Accuracy on training set: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))
增加迭代次数仅提高了训练集性能,但没有提高泛化性能。不过模型的表现相当不错。由于训练性能和测试性能之间仍有一些差距,所以我们可以尝试降低模型复杂度来得到更好的泛化性能。这里我们选择增大 alpha 参数(变化范围相当大,从 0.0001 到 1 ),以此向权重添加更强的正则化:
mlp = MLPClassifier(max_iter=1000, alpha=1, random_state=0)
mlp.fit(X_train_scaled, y_train)print("Accuracy on training set: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))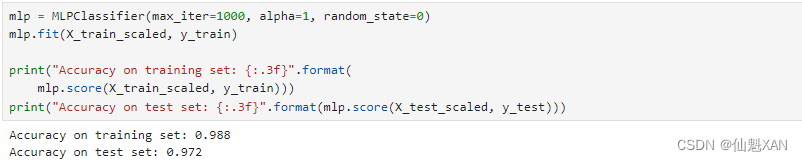
这得到了与我们目前最好的模型相同的性能。
虽然可以分析神经网络学到了什么,但这通常比分析线性模型或基于树的模型更为复杂。要想观察模型学到了什么,一种方法是查看模型的权重。你可以在 scikit-learn 示例库中查看这样的一个示例(Visualization of MLP weights on MNIST — scikit-learn 1.4.2 documentation )。对于乳腺癌数据集,这可能有点难以理解。下面这张图(下图)显示了连接输入和第一个隐层之间的权重。图中的行对应 30 个输入特征,列对应 100 个隐单元。浅色代表较大的正值,而深色代表负值。
plt.figure(figsize=(20, 5))
plt.imshow(mlp.coefs_[0], interpolation='none', cmap='viridis')
plt.yticks(range(30), cancer.feature_names)
plt.xlabel("Columns in weight matrix")
plt.ylabel("Input feature")
plt.colorbar()
plt.savefig('Images/07NeuralNetwork-08.png', bbox_inches='tight')
plt.show()
我们可以推断,如果某个特征对所有隐单元的权重都很小,那么这个特征对模型来说就“不太重要”。可以看到,与其他特征相比,“mean smoothness”“mean compactness”以及“smoothness error”和“fractal dimension error”之间的特征的权重都相对较小。这可能说明这些特征不太重要,也可能是我们没有用神经网络可以使用的方式来表示这些特征。
我们还可以将连接隐层和输出层的权重可视化,但它们更加难以解释。
虽然 MLPClassifier 和 MLPRegressor 为最常见的神经网络架构提供了易于使用的接口,但它们只包含神经网络潜在应用的一部分。如果你有兴趣使用更灵活或更大的模型,我们建议你看一下除了 scikit-learn 之外的很棒的深度学习库。对于 Python 用户来说,最为完善的是 keras 、lasagna 和 tensor-flow 。lasagna 是基于 theano 库构建的,而 keras 既可以用 tensor-flow 也可以用 theano 。这些库提供了更为灵活的接口,可以用来构建神经网络并跟踪深度学习研究的快速发展。所有流行的深度学习库也都允许使用高性能的图形处理单元(GPU),而 scikit-learn 不支持 GPU。使用 GPU 可以将计算速度加快 10 到 100 倍,GPU 对于将深度学习方法应用到大型数据集上至关重要。
3、优点、缺点和参数
在机器学习的许多应用中,神经网络再次成为最先进的模型。它的主要优点之一是能够获取大量数据中包含的信息,并构建无比复杂的模型。给定足够的计算时间和数据,并且仔细调节参数,神经网络通常可以打败其他机器学习算法(无论是分类任务还是回归任务)。
这就引出了下面要说的缺点。神经网络——特别是功能强大的大型神经网络——通常需要很长的训练时间。它还需要仔细地预处理数据,正如我们这里所看到的。与 SVM 类似,神经网络在“均匀”数据上的性能最好,其中“均匀”是指所有特征都具有相似的含义。如果数据包含不同种类的特征,那么基于树的模型可能表现得更好。神经网络调参本身也是一门艺术。调节神经网络模型和训练模型的方法有很多种,我们只是蜻蜓点水地尝试了几种而已。
估计神经网络的复杂度 。最重要的参数是层数和每层的隐单元个数。你应该首先设置 1 个或 2 个隐层,然后可以逐步增加。每个隐层的结点个数通常与输入特征个数接近,但在几千个结点时很少会多于特征个数。
在考虑神经网络的模型复杂度时,一个有用的度量是学到的权重(或系数)的个数。如果你有一个包含 100 个特征的二分类数据集,模型有 100 个隐单元,那么输入层和第一个隐层之间就有 100 * 100 = 10 000 个权重。在隐层和输出层之间还有 100 * 1 = 100 个权重,总共约 10 100 个权重。如果添加含有 100 个隐单元的第二个隐层,那么在第一个隐层和第二个隐层之间又有 100 * 100 = 10 000 个权重,总数变为约 20 100 个权重。如果你使用包含 1000 个隐单元的单隐层,那么在输入层和隐层之间需要学习 100 * 1000 = 100 000 个权重,隐层到输出层之间需要学习 1000 * 1 = 1000 个权重,总共 101 000 个权重。如果再添加第二个隐层,就会增加 1000 * 1000 = 1 000 000 个权重,总数变为巨大的 1 101 000 个权重,这比含有 2 个隐层、每层 100 个单元的模型要大 50 倍。
神经网络调参的常用方法是,首先创建一个大到足以过拟合的网络,确保这个网络可以对任务进行学习。知道训练数据可以被学习之后,要么缩小网络,要么增大 alpha 来增强正则化,这可以提高泛化性能。
在我们的实验中,主要关注模型的定义:层数、每层的结点个数、正则化和非线性。这些内容定义了我们想要学习的模型。还有一个问题是,如何 学习模型或用来学习参数的算法,这一点由 solver 参数设定。solver 有两个好用的选项。默认选项是 'adam' ,在大多数情况下效果都很好,但对数据的缩放相当敏感(因此,始终将数据缩放为均值为 0、方差为 1 是很重要的)。另一个选项是 'lbfgs' ,其鲁棒性相当好,但在大型模型或大型数据集上的时间会比较长。还有更高级的 'sgd' 选项,许多深度学习研究人员都会用到。'sgd' 选项还有许多其他参数需要调节,以便获得最佳结果。你可以在用户指南中找到所有这些参数及其定义。当你开始使用 MLP 时,我们建议使用 'adam' 和 'lbfgs' 。
fit会重置模型
scikit-learn模型的一个重要性质就是,调用fit总会重置模型之前学到的所有内容。因此,如果你在一个数据集上构建模型,然后在另一个数据集上再次调用fit,那么模型会“忘记”从第一个数据集中学到的所有内容。你可以对一个模型多次调用fit,其结果与在“新”模型上调用fit是完全相同的。
附录
一、如果报错 ModuleNotFoundError: No module named 'graphviz'
如下图:
1)Graphviz的官网下载:Download | Graphviz,下载后按照提示进行安装就可以了
下载地址:Download | Graphviz
2)可以安装 graphviz 解决: pip install graphviz

3)配置路径 PATH
如果运行时报错的话,配置一下安装路径
4)如果还报错,最后代码中添加如下代码
import os
os.environ["PATH"] += os.pathsep + r'你的Graphviz/bin路径位置' # 例如:D:\Program Files\Graphviz\bin/二、参考文献
参考文献:[德] Andreas C. Müller [美] Sarah Guido 《Python Machine Learning Basics Tutorial》