开心一刻
去年在抖音里谈了个少妇,骗了我 9 万
后来我发现了,她怕我报警
她把她表妹介绍给我
然后她表妹又骗了我 7 万

DataX
DataX 是什么,有什么用,怎么用
不做介绍,大家自行去官网(DataX)看,Gitee 上也有(DataX)

你们别不服,我这是为了逼迫你们去自学,是为了你们好!
文档很详细,也是开源的,我相信你们都能看懂,也能很快上手用起来
那这篇文章到此结束,大家各自去忙吧
但是等等,我想带你们去改造改造datax
挺有意思的,我们慢慢往下看
去 Python
根据官方的 Quick Start

是依赖 Python 来启动的
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
如果要去掉 Python 依赖,你们会怎么做?
是不是梳理清楚 datax.py 的代码逻辑就行了?
datax.py
这个代码不长,但是如果没有一点 Python 底子,datax.py 是看不懂的
所以我们换个方式,去寻找我们需要的信息就行了
DataX 的业务代码是 java 实现的,然后你们再往上看看 System Requirements
你们觉得该如何启动 JVM 进程来执行 DataX 的 java 代码?
是不是只能用 JDK 的 java 命令了?
所以我们直接在 datax.py 中搜索 java 即可
你们会发现只有如下这一行表示 java 命令
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (DEFAULT_PROPERTY_CONF, CLASS_PATH)
Python 中的 % 就相当于 java 中的 String.format 方法

也就说,datax.py 是通过 java -server 命令来启动 JVM 进程的
那么我们是不是可以绕过 Python,直接在 cmd 调用 java -server 来启动了?
java -server
这个命令还真不眼熟,因为我们接触到的往往是 java -jar
我们用 java -h 看下 java 命令的说明

发现了什么?
-server 是 option 之一,与 -jar 并不是 非此即彼 的关系
所以不要去拿 java -server 与 java -jar 做对比了,没意义!!!
在Java中,JVM有两种运行模式:客户端模式和服务器模式。这两种模式是为了优化不同场景下的JVM性能而设计的。服务器模式:这种模式适用于长时间运行的应用程序,如Web服务器或数据库服务器。服务器模式下的JVM会进行更多的优化,以减少长时间运行的性能开销。例如,它会进行更深入的即时编译(JIT compilation),以提高代码的执行效率。客户端模式:默认情况下,JVM运行在客户端模式。这种模式适用于较短时间运行的应用程序,如桌面应用或命令行工具。客户端模式下的JVM会更快地启动,但可能不如服务器模式那样高效。使用-server选项启动JVM时,您告诉JVM在服务器模式下运行。这通常意味着JVM将使用更多的系统资源,但可以提供更好的性能,特别是在长时间运行的应用程序中
我们先下载 DataX 工具包

解压之后,我的 DataX 的根目录是:G:\datax-tool\datax

我们不通过 datax.py 来启动,而是直接在 cmd 下通过 java 命令来启动
java -server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=G:\datax-tool\datax\log -Dfile.encoding=GBK -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=G:\datax-tool\datax -Dlogback.configurationFile=G:\datax-tool\datax\conf\logback.xml -classpath G:\datax-tool\datax\lib\* com.alibaba.datax.core.Engine -mode standalone -jobid -1 -job G:\datax-tool\datax\job\job.json
注意:上述 java 命令中的相关路径需要替换成你们自己的路径!
不出意外的话,会执行成功

为什么依赖 Python
如果你们去看了 DataX 工具包的目录结构,或者 DataX 的源码
你们会发现 DataX 就是用 java 实现的,Python 仅仅只是作为一个启动脚本(另外两个脚本你们自己去研究)

仅仅为了一个启动,而这个启动又不是非 Python 不可,就引入了 Python 环境依赖,试问这合理吗?

不要急着下结论,我们理智分析一波
DataX 正式投入使用的时候,会部署到什么系统上,请你们大声的告诉我

不说全部,绝大部分是部署在 Linux 上,对此我相信你们都没异议吧
那么重点来了:目前主流的 Linux 系统,都自带 Python !!!
也就是不用再额外的是安装 Python,直接可以用,那为什么不用呢?
那如果是部署在 Windows 上,而又不想安装 Python,该如何启动了?
如果你们还能问出这样的问题,我只想给你们来上一枪

前面不是刚讲吗,在 cmd 直接用 java 命令来启动 DataX 不就行了?
java 启动 DataX
说的更详细点,是通过 java 代码去启动 DataX 的 JVM 进程
我相信你们都会,直接上代码
private static final String DATAX_COMMAND = "java -server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=G:\\datax-tool\\datax\\log -Dfile.encoding=GBK -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=G:\\datax-tool\\datax -Dlogback.configurationFile=G:\\datax-tool\\datax\\conf\\logback.xml -classpath G:\\datax-tool\\datax\\lib\\* com.alibaba.datax.core.Engine -mode standalone -jobid -1 -job G:\\datax-tool\\datax\\job\\job.json";public static void main(String[] args) {try {Process process = Runtime.getRuntime().exec(DATAX_COMMAND);// 等待命令执行完成int i = process.waitFor();if (i == 0) {System.out.println("job执行完成");} else {System.out.println("job执行失败");}} catch (Exception e) {throw new RuntimeException(e);}
}
是不是很简单?
执行下,你会发现卡住了!!!

出师不利呀,要不放弃?

当 Runtime 对象调用 exec(cmd) 后,JVM 会启动一个子进程,该进程会与 JVM 进程建立三个管道连接:标准输入,标准输出 和 标准错误流
假设子进程不断在向标准输出流和标准错误流写数据,而 JVM 进程不读取的话,当缓冲区满之后将无法继续写入数据,最终造成阻塞在 waitfor()
所以改造下就好了
private static final String SYSTEM_ENCODING = System.getProperty("sun.jnu.encoding");
private static final String DATAX_COMMAND = "java -server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=G:\\datax-tool\\datax\\log -Dfile.encoding=GBK -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=G:\\datax-tool\\datax -Dlogback.configurationFile=G:\\datax-tool\\datax\\conf\\logback.xml -classpath G:\\datax-tool\\datax\\lib\\* com.alibaba.datax.core.Engine -mode standalone -jobid -1 -job G:\\datax-tool\\datax\\job\\job.json";public static void main(String[] args) {try {Process process = Runtime.getRuntime().exec(DATAX_COMMAND);// 另启线程读取new Thread(() -> {try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream(), SYSTEM_ENCODING))) {String line;while ((line = reader.readLine()) != null) {System.out.println(line);}} catch (IOException e) {throw new RuntimeException(e);}}).start();new Thread(() -> {try (BufferedReader errorReader = new BufferedReader(new InputStreamReader(process.getErrorStream(), SYSTEM_ENCODING))) {String line;while ((line = errorReader.readLine()) != null) {System.out.println(line);}} catch (IOException e) {throw new RuntimeException(e);}}).start();// 等待命令执行完成int i = process.waitFor();if (i == 0) {System.out.println("job执行完成");} else {System.out.println("job执行失败");}} catch (Exception e) {throw new RuntimeException(e);}
}
还是比较简单的吧,相信你们都能看懂
总结
-
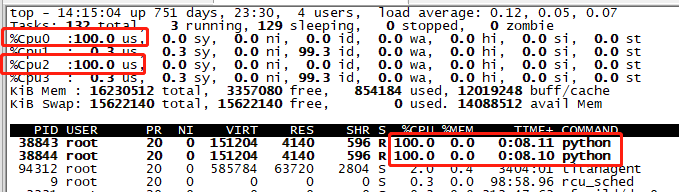
DataX是进程级别的,而Job下的Task是线程级别的
为什么
DataX要实现成进程级别,而不是线程级别?小数据量的同步,实现方式往往很多
但大数据量的同步,情况就不一样了,那么此时进程和线程的区别还大吗
-
Linux系统基本自带Python环境,所以大家不要再纠结为什么依赖Python了去掉
Python依赖也很简单,文中已有演示 -
DataX+datax-web这个组合已经基本够用datax-web 基于 XXL-JOB,基本满足我们日常的调度要求了