格式化NameNode
当第一次启动HDFS时要进行格式化,将NameNode上的数据清零,否则会缺失DataNode。以后启动无需再格式化,只要运行过Hadoop集群,其工作目录(/usr/local/src/hadoop/tmp)中就会有数据。如果需要重新格式化,则在重新格式化之前一定要先删除工作目录下的数据,否则格式化时会出问题,并且缺失DataNode进程。
在master节点上进行格式化,执行以下命令
hdfs namenode -format
格式化的过程比较长,一般需要1Min,该过程会在屏幕上不断地刷新。等待格式化完成后,Hadoop3.1.4版本会提示格式化成功信息。
启动和关闭Hadoop集群
针对Hadoop集群的启动,需要启动HDFS集群YARN集群两个框架,启动方式可以逐个启动,也可以使用脚本一键启动。
1. 逐个启动
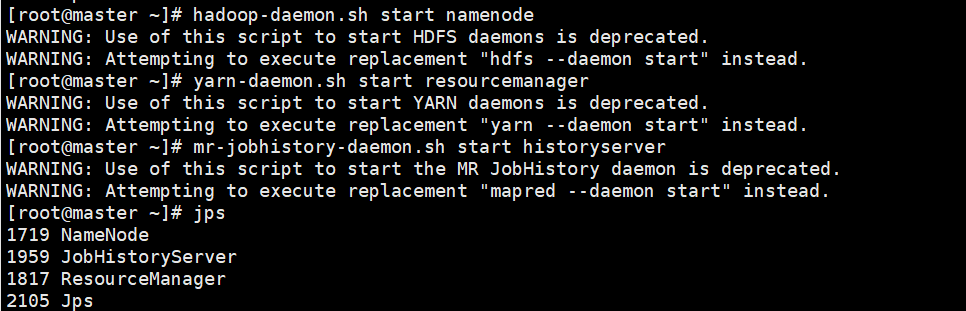
在master节点上启动HDFS NameNode进程、YARN ResourceManager进程和HistoryServer进程。启动后可以使用"jps"命令查看进程,执行以下命令
hadoop-daemon.sh start namenode
yarn-daemon.sh start resourcemanager
mr-jobhistory-daemon.sh start historyserver
jps
使用jps命令查看NameNode 和ResourceManager两个进程,如下图
在slave节点中启HDFS DataNode进程、YARN NodeManager进程,执行以下命令
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
jps
启动后可以使用jps命令查看进程,slave1和slave2情况以下,如下图

2.脚本一键启动
执行以下命令
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
jps
以上是启动进程的各种方法,Hadoop集群的关闭和启动的顺序是相反的,即倒序关闭。如果要关闭相应的进程,则执行以下命令,先关闭HistoryServer进程,然后关闭YARN进程,最后关闭HDFS。
mr-jobhistory-daemon.sh start historyserver
start-yarn.sh
start-dfs.sh
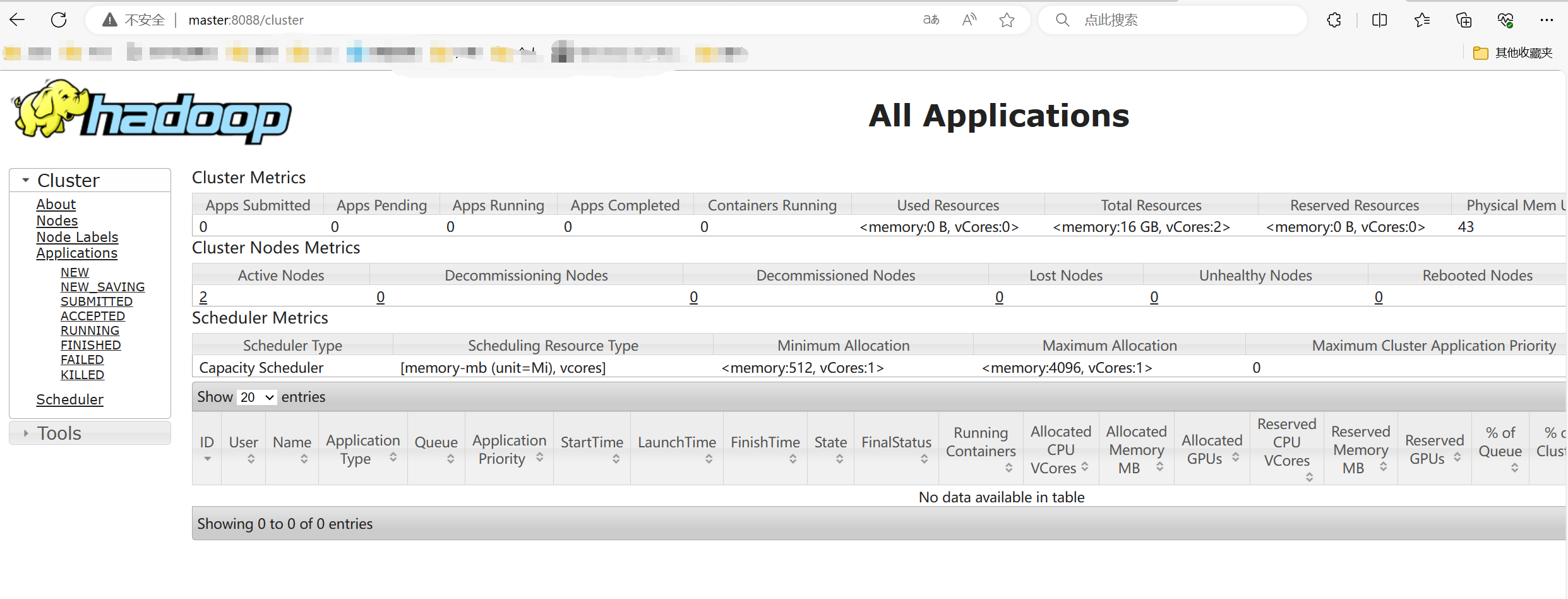
使用浏览器查看节点状态
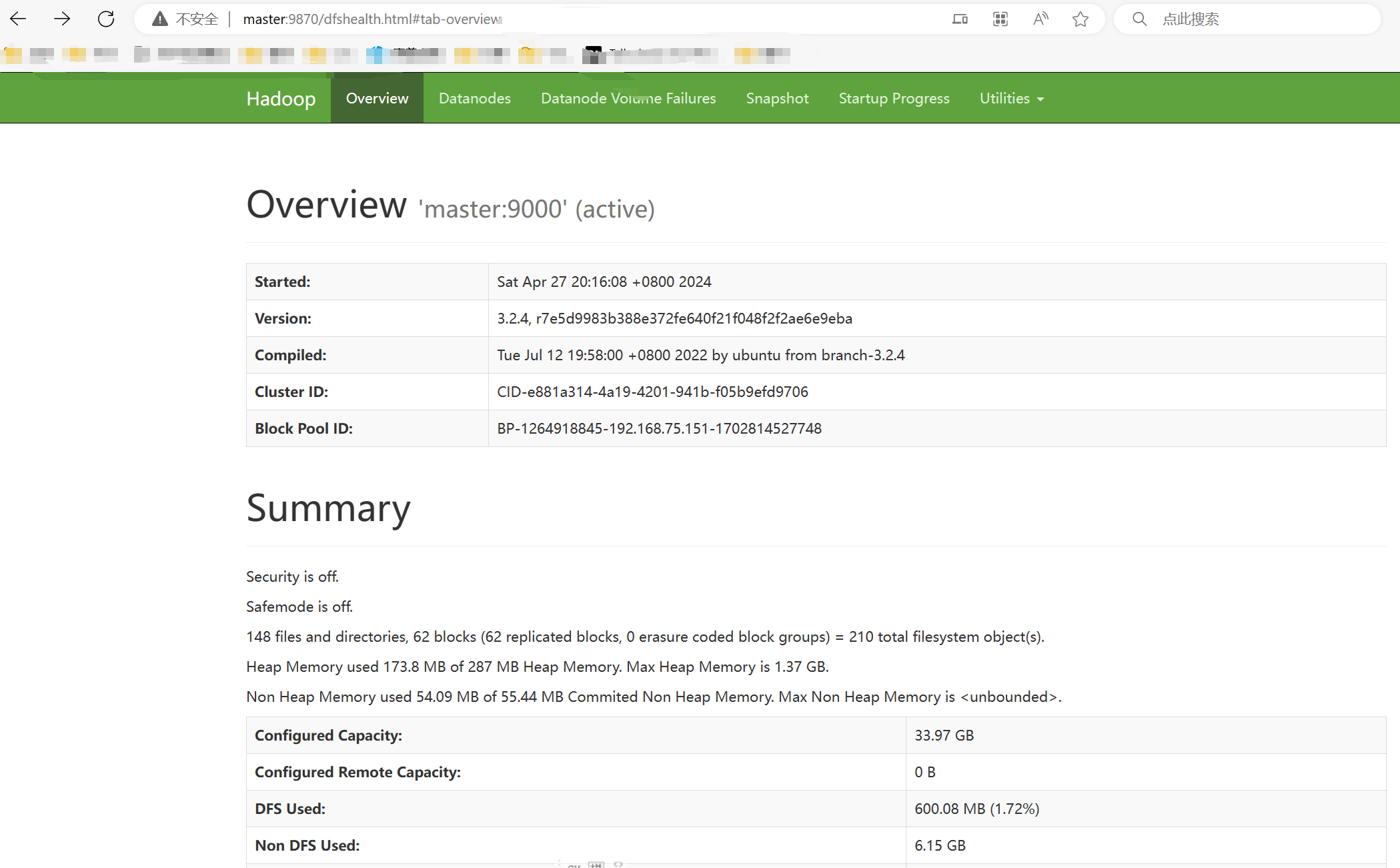
Hadoop集群启动后,通过Web页面可以方便地进行集群的管理和查看,只需在本地操作系统的浏览器的地址栏中输入集群服务器的节点名称(或ip地址)和相应的端口号。在浏览器中输入http://master:9870,如图所示
在浏览器中输入http://master:8088, 进入页面,可以查看SecondaryNameNode信息,如下图