一、准备工作
- 主机规划
| 节点 | IP |
| k8s-master1 | 192.168.2.245 |
| k8s-master2 | 192.168.2.246 |
| k8s-master3 | 192.168.2.247 |
| k8s-node1 | 192.168.2.248 |
| NFS、Rancher | 192.168.2.251 |
注意:本文采用三主三从集群模式。redis集群至少要有6个节点,由于资源限制无法部署那么多node节点,所以6个pod都只能跑在node1节点上。
- 版本介绍
| 服务 | 版本 |
| centos | 7.9 |
| Rancher(单节点) | 2.5.12 |
| kubernetes | 1.20.15 |
| Redis | 7.0.11 |
二、逻辑图
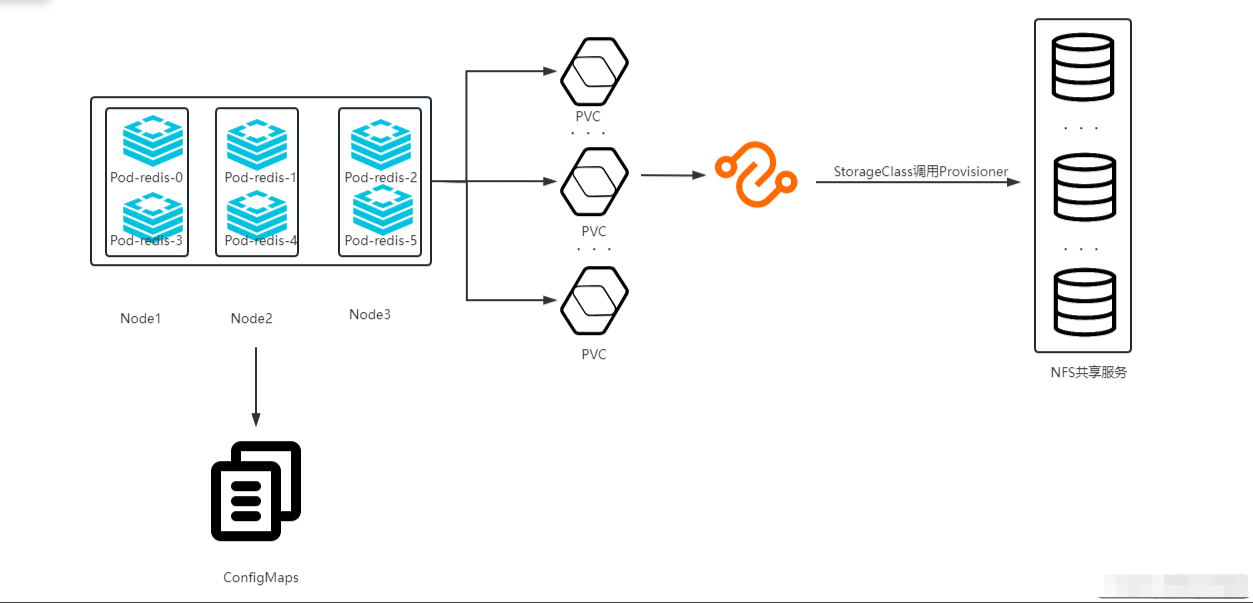
本次创建6个Redis服务,并使用configmap持久化redis配置文件;需要注意的是,本文没有使用传统的pv,pvc方式做持久化数据存储,而是使用storageclass调用provisioner,自动给pod创建的pvc分配pv并绑定,从而达到持久化存储的效果。
简单直观看下图:
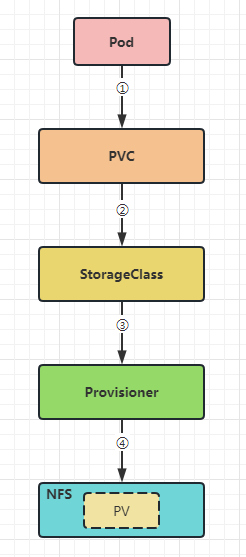
接下来我们就一起来部署redis集群吧!
概念解释:
Provisioner:Provisioner是StorageClass中必须的一个资源,它是存储资源自动调配器,可以将其看作是后端存储驱动。对于NFS类型,K8S没有提供内部Provisioner,但可以使用外部的Provisioner。Provisioner必须符合存储卷的开发规范(CSI)。本文档中使用NFS提供的Provisioner。
三、部署Redis集群
1. 安装NFS服务
NFS Server IP(服务端):192.168.2.251
NFS Client IP(客户端):192.168.2.245
- NFS Server端安装NFS
操作主机:NFS、Rancher|192.168.2.251
# 1.安装nfs与rpc
yum install -y nfs-utils rpcbind
# 查看是否安装成功
rpm -qa | grep nfs
rpm -qa | grep rpcbind
# 2.创建共享存储文件夹,并授权
mkdir -p /nfs/k8s_data
chmod 777 /nfs/k8s_data/# 3.配置nfs
vim /etc/exports
/nfs/k8s_data 192.168.2.0/24(rw,no_root_squash,no_all_squash,sync)注:
rw read-write 读写
ro read-only 只读
sync 请求或写入数据时,数据同步写入到NFS server的硬盘后才返回。数据安全,但性能降低了
async 优先将数据保存到内存,硬盘有空档时再写入硬盘,效率更高,但可能造成数据丢失。
root_squash 当NFS 客户端使用root用户访问时,映射为NFS 服务端的匿名用户
no_root_squash 当NFS 客户端使用root 用户访问时,映射为NFS服务端的root 用户
all_squash 不论NFS 客户端使用任何帐户,均映射为NFS 服务端的匿名用户# 4.启动服务
systemctl start nfs
systemctl start rpcbind
#添加开机自启
systemctl enable nfs
systemctl enable rpcbind# 5.配置生效
exportfs -r# 6.查看挂载情况
showmount -e localhost
#输出下面信息表示正常
Export list for localhost:
/nfs/k8s_data 192.168.2.0/24- NFS Client安装NFS
操作主机:除了NFS server,其他所有主机
yum -y install nfs-utils
2. 修改API配置
Kubernetes v1.20 (opens new window)开始,默认停用了 metadata.selfLink 字段,并计划在 1.21 版本中删除该字段,然而,部分应用仍然依赖于这个字段,例如 nfs-client-provisioner。如果仍然要继续使用这些应用,将需要重新启用该字段。
由于我们后面要使用nfs-client-provisioner,所以,如果你的Kubernetes版本是1.20.x版本,需要提前修改api 配置,重启metadata.selfLink字段。
# 添加方式:
vim /etc/kubernetes/manifests/kube-apiserver.yaml# 把下面配置增加进去
--feature-gates=RemoveSelfLink=false
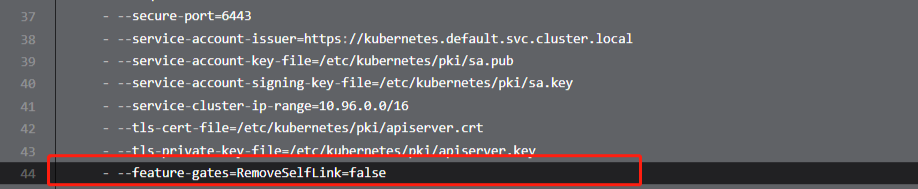
如果没有修改配置,后面我们查看nfs-client-provisioner服务日志时,可能会出现报错:unexpected error getting claim reference: selfLink was empty, can’t make reference,就是由于没有开启这个字段导致的。
3. 创建持久卷PVC
当有很多的数据卷需要创建或者管理时,Kubernetes解决这个问题的方法是提供动态配置PV的方法,可以自动创建PV。管理员可以部署PV配置器(provisioner),然后定义对应的StorageClass,这样开发者在创建PVC的时候就可以选择需要创建存储的类型,PVC会把StorageClass传递给PV provisioner,由provisioner自动创建PV。
参考k8s官网:https://kubernetes.io/zh-cn/docs/concepts/storage/storage-classes/#provisioner
参考Github开源组件:https://github.com/kubernetes-retired/external-storage/blob/master/nfs-client/deploy/
参考文章:https://dongweizhen.blog.csdn.net/article/details/130651727?spm=1001.2014.3001.5502
所以这里使用了StorageClass的类型当做就持久化方案。
1. 创建ServiceAccount账号
vim nfs-serviceaccount.yaml
#复制以下内容:apiVersion: v1
kind: ServiceAccount
metadata:name: nfs-client-provisionernamespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: nfs-client-provisioner-runner
rules:- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get", "list", "watch", "create", "delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: run-nfs-client-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: default
roleRef:kind: ClusterRolename: nfs-client-provisioner-runnerapiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: default
rules:- apiGroups: [""]resources: ["endpoints"]verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: default
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: default
roleRef:kind: Rolename: leader-locking-nfs-client-provisionerapiGroup: rbac.authorization.k8s.io
# 创建资源
kubectl create -f nfs-serviceaccount.yaml2. 创建provisioner
(也可称为供应者、置备程序、存储分配器)
vim nfs-client-provisioner.yaml
# 复制以下内容:apiVersion: apps/v1
kind: Deployment
metadata:name: nfs-client-provisionerlabels:app: nfs-client-provisionernamespace: default
spec:replicas: 1strategy:type: Recreateselector:matchLabels:app: nfs-client-provisionertemplate:metadata:labels:app: nfs-client-provisionerspec:serviceAccountName: nfs-client-provisioner #这个serviceAccountName就是上面创建ServiceAccount账号containers:- name: nfs-client-provisionerimage: quay.io/external_storage/nfs-client-provisioner:latestvolumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAME #PROVISIONER_NAME的值就是本清单的顶部定义的namevalue: nfs-client-provisioner- name: NFS_SERVER #这个NFS_SERVER参数的值就是nfs服务器的IP地址value: 192.168.2.251- name: NFS_PATH #这个NFS_PATH参数的值就是nfs服务器的共享目录value: /nfs/k8s_datavolumes:- name: nfs-client-rootnfs: #这里就是配置nfs服务器的ip地址和共享目录server: 192.168.2.251path: /nfs/k8s_data
# 创建资源
kubectl create -f nfs-client-provisioner.yaml3. 创建StorageClass
vim nfs-storageclass.yaml
# 复制以下内容:apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: nfs-storageclass
provisioner: nfs-client-provisioner #provisioner参数定义置备程序
reclaimPolicy: Retain #回收策略,默认是Delete
parameters:archiveOnDelete: "false"
# 创建资源:
kubectl create -f nfs-storageclass.yaml 4. 创建Redis服务
1. 创建redis配置文件
这里使用的是k8s的configmap类型创建的
vim redis.conf
# 复制以下内容,提示:复制配置文件的时候最好把后面的注释全部去掉,否则后面可能会报错!!!!!!!bind 0.0.0.0
protected-mode yes
port 6360 #redis端口,为了安全设置为6360端口
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize no #redis是否以后台模式运行,必须设置no
supervised no
pidfile /data/redis.pid #redis的pid文件,放到/data目录下
loglevel notice
logfile /data/redis_log #redis日志文件,放到/data目录下
databases 16
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb #这个文件会放在dir定义的/data目录
dir /data #数据目录
masterauth iloveyou #redis集群各节点相互认证的密码,必须配置和下面的requirepass一致
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
replica-priority 100
requirepass iloveyou #redis的密码
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
appendonly no
appendfilename "appendonly.aof" #这个文件会放在dir定义的/data目录
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
lua-time-limit 5000
cluster-enabled yes #是否启用集群模式,必须去掉注释设为yes
cluster-config-file nodes.conf #这个文件会放在dir定义的/data目录
cluster-node-timeout 15000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
创建configmap:
#创建cm,名称为redis-conf,key为redis.conf,,value为以上创建的redis.conf配置文件。
!!!再次提示:创建前,需要把配置文件中的注释都删除掉,要不然会报错wrong number of arguments
# 创建configmap
kubectl create configmap redis-conf --from-file=redis.conf=redis.conf
2. 创建statefulset类型的Redis集群
这里使用statefulsets有状态应用来创建redis,创建sts有状态应用需要有一个headless service,同时在sts中挂载configmap卷,使用动态分配pv用于redis数据持久化。
vim redis-cluster-sts.yaml
# 复制以下内容:---
apiVersion: v1
kind: Service #先创建一个无头service
metadata:labels: #service本身的标签app: redis-svcname: redis-svc #service的名称,下面创建的StatefulSet就要引用这个service名称
spec:ports:- port: 6360 #service本身的端口protocol: TCPtargetPort: 6360 #目标端口6360,redis默认端口是6379,这里为了安全改成了6360selector:app: redis-sts #标签选择器要与下面创建的pod的标签一样type: ClusterIPclusterIP: None #clusterIP为None表示创建的service为无头service
---
apiVersion: apps/v1
kind: StatefulSet #创建StatefulSet资源
metadata:labels: #StatefulSet本身的标签app: redis-stsname: redis-sts #资源名称namespace: default #资源所属命名空间
spec:selector: #标签选择器,要与下面pod模板定义的pod标签保持一致matchLabels:app: redis-stsreplicas: 6 #副本数为6个,redis集群模式最少要为6个节点,构成3主3从serviceName: redis-svc #指定使用service为上面我们创建的无头service的名称template: metadata:labels: #pod的标签,上面的无头service的标签选择器和sts标签选择器都要与这个相同app: redis-stsspec:
# affinity:
# podAntiAffinity: #定义pod反亲和性,目的让6个pod不在同一个主机上,实现均衡分布,这里我的node节点不够,所以不定义反亲和性
# preferredDuringSchedulingIgnoredDuringExecution:
# - weight: 100
# podAffinityTerm:
# labelSelector:
# matchExpressions:
# - key: app
# operator: In
# values:
# - redis-sts
# topologyKey: kubernetes.io/hostnamecontainers:- name: redis #容器名称image: redis:latest #redis镜像imagePullPolicy: IfNotPresent #镜像拉取策略command: #定义容器的启动命令和参数- "redis-server"args:- "/etc/redis/redis.conf"- "--cluster-announce-ip" #这个参数和下面的这个参数- "$(POD_IP)" #这个参数是为了解决pod重启ip变了之后,redis集群状态无法自动同步问题env:- name: POD_IP #POD_IP值引用自status.podIPvalueFrom:fieldRef:fieldPath: status.podIP ports: #定义容器端口- name: redis-6360 #为端口取个名称为httpcontainerPort: 6360 #容器端口volumeMounts: #挂载点- name: "redis-conf" #引用下面定义的redis-conf卷mountPath: "/etc/redis" #redis配置文件的挂载点- name: "redis-data" #指定使用的卷名称,这里使用的是下面定义的pvc模板的名称mountPath: "/data" #redis数据的挂载点- name: localtime #挂载本地时间mountPath: /etc/localtimereadOnly: truerestartPolicy: Alwaysvolumes:- name: "redis-conf" #挂载一个名为redis-conf的configMap卷,这个cm卷已经定义好了configMap:name: "redis-conf"items:- key: "redis.conf"path: "redis.conf"- name: localtime #挂载本地时间hostPath:path: /etc/localtime
# type: FilevolumeClaimTemplates: #定义创建pvc的模板- metadata:name: "redis-data" #模板名称spec:resources: #资源请求requests:storage: 100M #需要100M的存储空间accessModes: - ReadWriteOnce #访问模式为RWOstorageClassName: "nfs-storageclass" #指定使用的存储类,实现动态分配pv
# 创建资源
kubectl create -f redis-cluster-sts.yaml # 查看状态:
kubectl get sts,pvc,pv
服务全部就绪,数据卷也已绑定完成。
4. 组建Redis集群
介绍两种组建集群的方法,分为手动和自动,选择自己喜欢的一个方式操作。
这里使用了域名的方式让他们相互通信,这样可以避免pod被重启ip变化,导致集群出现问题。
根据K8s机制,<pod-name>.<svc-name>.<namespace>.svc.cluster.local这个 DNS 记录,正是 Kubernetes 项目为 Pod 分配的唯一的可解析身份,这样Pod就可以通过名字编号进行区分了,并且可以相互访问。
1. 自动组建集群
这种方式,Redis会自动分配主节点和从节点,不需要手工指定。
kubectl exec -it redis-sts-0 -- redis-cli -a iloveyou --cluster create --cluster-replicas 1 $(kubectl get pods -l app=redis-sts -o jsonpath='{range.items[*]}{.metadata.name}.redis-svc:6360 {end}')
输入yes,正式开始组建redis集群
最后返回:
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
2. 手动组建集群
查看下Pod的信息:
[root@k8s-master01 redis]# kubectl get pod -l app=redis-sts
NAME READY STATUS RESTARTS AGE
redis-sts-0 1/1 Running 0 61m
redis-sts-1 1/1 Running 0 61m
redis-sts-2 1/1 Running 0 61m
redis-sts-3 1/1 Running 0 61m
redis-sts-4 1/1 Running 0 61m
redis-sts-5 1/1 Running 0 61m
手动创建redis集群的master节点,指定redis-sts-0、redis-sts-2、redis-sts-4的pod为master节点,同样适用DNS解析域名的方式。
kubectl exec -it redis-sts-0 -- redis-cli -a iloveyou --cluster create redis-sts-0.redis-svc:6360 redis-sts-2.redis-svc:6360 redis-sts-4.redis-svc:6360
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing hash slots allocation on 3 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
M: 0708f2d7db318bc8651dd422d28627957756472d redis-sts-0.redis-svc:6360 #0708f2d7db318bc8651dd422d28627957756472d集群IDslots:[0-5460] (5461 slots) master
M: 0b5c2c8d2907dbb56c6e40baf0272917e59d960f redis-sts-2.redis-svc:6360 #同上slots:[5461-10922] (5462 slots) master
M: 8ace82454363dc760fe856712fc0fbb220b2e2d5 redis-sts-4.redis-svc:6360 # 同上slots:[10923-16383] (5461 slots) master
Can I set the above configuration? (type 'yes' to accept): yes #输入yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
..
>>> Performing Cluster Check (using node redis-sts-0.redis-svc:6360)
M: 0708f2d7db318bc8651dd422d28627957756472d redis-sts-0.redis-svc:6360slots:[0-5460] (5461 slots) master
M: 0b5c2c8d2907dbb56c6e40baf0272917e59d960f 10.42.2.38:6360slots:[5461-10922] (5462 slots) master
M: 8ace82454363dc760fe856712fc0fbb220b2e2d5 10.42.3.71:6360slots:[10923-16383] (5461 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
为每一个master节点添加slave节点
# redis-sts-0 主 >> redis-sts-1 从
kubectl exec -it redis-sts-0 -- redis-cli -a iloveyou --cluster add-node redis-sts-1.redis-svc:6360 redis-sts-0.redis-svc:6360 --cluster-slave --cluster-master-id 0708f2d7db318bc8651dd422d28627957756472d# redis-sts-2 主 >> redis-sts-3 从
kubectl exec -it redis-sts-0 -- redis-cli -a iloveyou --cluster add-node redis-sts-3.redis-svc:6360 redis-sts-2.redis-svc:6360 --cluster-slave --cluster-master-id 0b5c2c8d2907dbb56c6e40baf0272917e59d960f# redis-sts-4 主 >> redis-sts-5 从
kubectl exec -it redis-sts-0 -- redis-cli -a iloveyou --cluster add-node redis-sts-5.redis-svc:6360 redis-sts-4.redis-svc:6360 --cluster-slave --cluster-master-id 8ace82454363dc760fe856712fc0fbb220b2e2d5
注:
–cluster add-node 参数指定要加入的slave节点
–cluster-master-id 参数指定该slave节点对应的master节点的id
5. 验证集群
使用下面这条命令验证集群状态,注意–cluster check 后面仅需指定任意一个节点ip即可,这里的range.items[0]就表示指定第一个redis-sts-0的ip,如下所示,集群状态正常
[root@k8s-master01 redis]# kubectl exec -it redis-sts-0 -- redis-cli -a iloveyou --cluster check $(kubectl get pods -l app=redis-sts -o jsonpath='{range.items[0]}{.metadata.name}:6360 {end}')
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
redis-sts-0:6360 (0708f2d7...) -> 0 keys | 5461 slots | 1 slaves.
10.42.3.71:6360 (8ace8245...) -> 0 keys | 5461 slots | 1 slaves.
10.42.2.38:6360 (0b5c2c8d...) -> 0 keys | 5462 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node redis-sts-0:6360)
M: 0708f2d7db318bc8651dd422d28627957756472d redis-sts-0:6360slots:[0-5460] (5461 slots) master1 additional replica(s)
M: 8ace82454363dc760fe856712fc0fbb220b2e2d5 10.42.3.71:6360slots:[10923-16383] (5461 slots) master1 additional replica(s)
M: 0b5c2c8d2907dbb56c6e40baf0272917e59d960f 10.42.2.38:6360slots:[5461-10922] (5462 slots) master1 additional replica(s)
S: 9683517103c33656e8fb1b666064011d74addf52 10.42.1.16:6360slots: (0 slots) slavereplicates 0b5c2c8d2907dbb56c6e40baf0272917e59d960f
S: 6f17691791b9755956868d14b7fc0e1c59bf4fb2 10.42.0.25:6360slots: (0 slots) slavereplicates 8ace82454363dc760fe856712fc0fbb220b2e2d5
S: 22038a5bb2e31d385ce016ba1cd9d8f13eb4e0d8 10.42.0.24:6360slots: (0 slots) slavereplicates 0708f2d7db318bc8651dd422d28627957756472d
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
参考文章:
部署Redis7.0集群6节点三主三从(完整版)
Redis6节点集群搭建
K8s搭建nfs-storageclass
K8s搭建nfs-storageclass
Kuboard官网文档
Kubernetes官网文档