1、提前部署Mysql主从(一主两从)
2、配置orch到所有机器的免密,配置好主机名/etc/hosts
3、安装orch
配置文件
{"Debug": true,"EnableSyslog": false, //是否把日志输出到系统日志里"ListenAddress": ":3000", "MySQLTopologyUser": "root", //orch管理mysql的用户"MySQLTopologyPassword": "abc123", //orch管理mysql的密码"MySQLTopologyCredentialsConfigFile": "","MySQLTopologySSLPrivateKeyFile": "","MySQLTopologySSLCertFile": "","MySQLTopologySSLCAFile": "","MySQLTopologySSLSkipVerify": true,"MySQLTopologyUseMutualTLS": false,"MySQLOrchestratorHost": "10.211.55.2", //orch元数据信息存放数据库host"MySQLOrchestratorPort": 4000, //orch元数据信息存放数据库port"MySQLOrchestratorDatabase": "orchestrator", //orch元数据信息存放数据库database"MySQLOrchestratorUser": "orchestrator", //orch元数据信息存放数据库user"MySQLOrchestratorPassword": "orchestrator", //orch元数据信息存放数据库password"MySQLOrchestratorCredentialsConfigFile": "","MySQLOrchestratorSSLPrivateKeyFile": "","MySQLOrchestratorSSLCertFile": "","MySQLOrchestratorSSLCAFile": "","MySQLOrchestratorSSLSkipVerify": true,"MySQLOrchestratorUseMutualTLS": false,"MySQLConnectTimeoutSeconds": 1,"DefaultInstancePort": 3306,"DiscoverByShowSlaveHosts": false, //通过show slave hosts自动发现slave,需在mysql配置文件中设置正确的report_host和report_port"InstancePollSeconds": 5, //每隔5s获取状态"DiscoveryIgnoreReplicaHostnameFilters": ["a_host_i_want_to_ignore[.]example[.]com",".*[.]ignore_all_hosts_from_this_domain[.]example[.]com","a_host_with_extra_port_i_want_to_ignore[.]example[.]com:3307"],"UnseenInstanceForgetHours": 240, "SnapshotTopologiesIntervalHours": 0,"InstanceBulkOperationsWaitTimeoutSeconds": 10, //在进行批量操作时, 等待单个实例的最大时间(秒)"HostnameResolveMethod": "default", //如何解析主机名,none: 直接返回传入的hostname,default: 直接返回传入hostname,cname: resolves an IP or hostname into a normalized valid CNAME,ip: 返回ip"MySQLHostnameResolveMethod": "@@hostname","SkipBinlogServerUnresolveCheck": true,"ExpiryHostnameResolvesMinutes": 60,"RejectHostnameResolvePattern": "","ReasonableReplicationLagSeconds": 0, //合理的复制滞后秒数. 高于这个值就是有问题的"ProblemIgnoreHostnameFilters": [],"VerifyReplicationFilters": false,"ReasonableMaintenanceReplicationLagSeconds": 20,"CandidateInstanceExpireMinutes": 60,"AuditLogFile": "","AuditToSyslog": false,"RemoveTextFromHostnameDisplay": ".mydomain.com:3306","ReadOnly": false,"AuthenticationMethod": "basic","HTTPAuthUser": "admin","HTTPAuthPassword": "admin","AuthUserHeader": "","PowerAuthUsers": ["*"],"ClusterNameToAlias": {"127.0.0.1": "test suite"},"ReplicationLagQuery": "", //提供ReplicationLagQuery 时, 计算出的复制延迟. 否则与SecondsBehindMaster 相同"DetectClusterAliasQuery": "SELECT SUBSTRING_INDEX(@@hostname, '.', 1)","DetectClusterDomainQuery": "","DetectInstanceAliasQuery": "","DetectPromotionRuleQuery": "","DataCenterPattern": "[.]([^.]+)[.][^.]+[.]mydomain[.]com","PhysicalEnvironmentPattern": "[.]([^.]+[.][^.]+)[.]mydomain[.]com","PromotionIgnoreHostnameFilters": [],"DetectSemiSyncEnforcedQuery": "","ServeAgentsHttp": false,"AgentsServerPort": ":3001","AgentsUseSSL": false,"AgentsUseMutualTLS": false,"AgentSSLSkipVerify": false,"AgentSSLPrivateKeyFile": "","AgentSSLCertFile": "","AgentSSLCAFile": "","AgentSSLValidOUs": [],"UseSSL": false,"UseMutualTLS": false,"SSLSkipVerify": false,"SSLPrivateKeyFile": "","SSLCertFile": "","SSLCAFile": "","SSLValidOUs": [],"URLPrefix": "","StatusEndpoint": "/api/status","StatusSimpleHealth": true,"StatusOUVerify": false,"AgentPollMinutes": 60,"UnseenAgentForgetHours": 6,"StaleSeedFailMinutes": 60,"SeedAcceptableBytesDiff": 8192,"PseudoGTIDPattern": "","PseudoGTIDPatternIsFixedSubstring": false,"PseudoGTIDMonotonicHint": "asc:","DetectPseudoGTIDQuery": "","BinlogEventsChunkSize": 10000,"SkipBinlogEventsContaining": [],"ReduceReplicationAnalysisCount": true,"FailureDetectionPeriodBlockMinutes": 1,"FailMasterPromotionOnLagMinutes": 0,"RecoveryPeriodBlockSeconds": 10, //一旦集群经历了恢复,那么在这段时间内将阻止自动恢复,以避免抖动"FailMasterPromotionIfSQLThreadNotUpToDate": false,"DelayMasterPromotionIfSQLThreadNotUpToDate": true, //等slave relay log apply完成"RecoveryIgnoreHostnameFilters": [],"RecoverMasterClusterFilters": [ "*"], //只对列表中正则表达式匹配的集群做故障恢复操作"RecoverIntermediateMasterClusterFilters": ["*"], //只对列表中正则表达式匹配的IntermediateMaster做故障恢复操作"OnFailureDetectionProcesses": ["echo 'Detected {failureType} on {failureCluster}. Affected replicas: {countSlaves}' >> /tmp/recovery.log"], //检测出故障时执行(在决定是否进行故障转移之前)"PreGracefulTakeoverProcesses": ["echo 'Planned takeover about to take place on {failureCluster}. Master will switch to read_only' >> /tmp/recovery.log" //在主变为只读之前立即执行],"PreFailoverProcesses": ["echo 'Will recover from {failureType} on {failureCluster}' >> /tmp/recovery.log"], //在执行恢复操作之前立即执行。任何这些进程的失败(非零退出代码)都会中止恢复。"PostFailoverProcesses": ["echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log","sh -x /usr/local/orchestrator/orch_hook.sh {failureType} {failureClusterAlias} {failedHost} {successorHost} >> /tmp/orch.log"], //成功恢复结束后,执行的脚本,这里调用切换vip的脚本"PostUnsuccessfulFailoverProcesses": [],"PostMasterFailoverProcesses": ["echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Promoted: {successorHost}:{successorPort}' >> /tmp/recovery.log"],"PostIntermediateMasterFailoverProcesses": ["echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log"], //在intermediate master(新主)恢复成功后执行的脚本"PostGracefulTakeoverProcesses": ["echo 'Planned takeover complete' >> /tmp/recovery.log","sh -x /usr/local/orchestrator/orch_hook.sh {failureType} {failureClusterAlias} {failedHost} {successorHost} >> /tmp/orch.log"], //在手动主从切换,旧的主节点挂在新的主节点上之后执行"CoMasterRecoveryMustPromoteOtherCoMaster": true, //双主的场景. 如果一个主库故障, 当该参数为true时, 只会提升另一个"主库"为新主库(看起来怪怪的), 否则集群中所有节点都可能提升为新主库"DetachLostSlavesAfterMasterFailover": true, //某些从库再恢复过程中可能会丢失。当为true时,Orchestrator将通过detach-replica命令将其强行中断复制"ApplyMySQLPromotionAfterMasterFailover": true, //当为true时,Orchestrator将会在新的master上执行:reset slave all 和 set read_only=0两条命令"PreventCrossDataCenterMasterFailover": false, //默认false,当为true时,Orchestrator只会使用同一个DC下的服务器进行恢复。如果在同一DC中找不到,那么恢复就会失败"PreventCrossRegionMasterFailover": false, //默认false,当为true时,Orchestrator将会在同一区域内的服务器上进行故障恢复,如果找不到,那么恢复就会失败"FailMasterPromotionOnLagMinutes": 0, "MasterFailoverDetachReplicaMasterHost": false, //当是true,Orchestrator将发出一个detach-replica-master-host命令到新的master上(确保新的master将不会复制旧的master)。 orchestrator将发出一个detach-replica-master-host升级的母版(这可以确保新的母版不会重生旧的母版)。默认值:false。如果ApplyMySQLPromotionAfterMasterFailover是true,那么该参数是无意义的。MasterFailoverDetachSlaveMasterHost是别名"MasterFailoverLostInstancesDowntimeMinutes": 0, //故障转移之后,所有的服务器的停机分钟数。默认为0"PostponeReplicaRecoveryOnLagMinutes": 0, //在故障恢复过程中,复制的延迟超过给定时间的从库,只有在选出master并且执行了所有process流程之后,才会在恢复的后期进行恢复。0为禁用。PostponeSlaveRecoveryOnLagMinutes是别名"OSCIgnoreHostnameFilters": [],"GraphiteAddr": "","GraphitePath": "","GraphiteConvertHostnameDotsToUnderscores": true,"ConsulAddress": "","ConsulAclToken": "","ConsulKVStoreProvider": "consul"
}
切换逻辑如下
逻辑如下:
1、分析mysql实例的故障类型并得到DeadCoMaster的故障
2、获取DeadCoMaster对应的处理函数,为checkAndRecoverDeadCoMaster()
3、登记failure detection记录到后端数据库并执行OnFailureDetectionProcesses的hook。执行成功则执行下面的流程,否则不执行下面所有流程1、执行PreFailoverProcesses的hook,成功则执行下面的子流程1、选择新主2、无论选择新主成功与否,清理failure detection的登记,将记录active设为0。2、选择新主成功且开启ApplyMySQLPromotionAfterMasterFailover配置时,将新主的read_only设为false3、选择新主成功情况下,执行PostMasterFailoverProcesses的hook4、如果上述的恢复成功,执行PostFailoverProcesses的hook。上述恢复执行失败则执行PostUnsuccessfulFailoverProcesses的hook
4、准备脚本
起停脚本
start.sh
#!/bin/bashnohup ./orchestrator --debug --config orchestrator.conf.json http > arch.log &
stop.sh
#!/bin/bashps -ef|grep orchestrator|grep http|awk '{print $2}'|xargs -i kill -9 {}
vip切换脚本
orch_hook.sh
#!/bin/bash
isitdead=$1
#cluster=$2
oldmaster=$3
newmaster=$4ssh=$(which ssh)logfile="/home/mysql/usr/local/orchestrator/orch.log"
#interface='enp0s3'
interface='eth0'
user=mysql
#VIP=$($ssh -tt ${user}@${oldmaster} "sudo ip address show dev enp0s3|grep -w 'inet'|tail -n 1|awk '{print \$2}'|awk -F/ '{print \$1}'")
VIP='10.37.129.10'
VIP_TEMP=$($ssh -tt ${user}@${oldmaster} "sudo ip address|sed -nr 's#^.*inet (.*)/32.*#\1#gp'")
#remove '\r' at the end $'192.168.56.200\r'
VIP_TEMP=$(echo $VIP_TEMP|awk -F"\\r" '{print $1}')if [ ${#VIP_TEMP} -gt 0 ]; thenVIP=$VIP_TEMP
fi
echo ${VIP}
echo ${interface}if [[ $isitdead == "DeadMaster" ]]; thenif [ !-z ${!VIP} ] ; thenecho $(date)echo "Revocering from: $isitdead"echo "New master is: $newmaster"echo "/home/mysql/usr/local/orchestrator/orch_vip.sh -d 1 -n $newmaster -i ${interface} -I $VIP -u ${user} -o ${oldmaster}"/home/mysql/usr/local/orchestrator/orch_vip.sh -d 1 -n $newmaster -i ${interface} -I $VIP -u ${user} -o ${oldmaster}elseecho "Cluster does not exist!" | tee $logfilefi
fi
[mysql@tidb-4 orchestrator]$ cat orch_hook.sh
#!/bin/bash
isitdead=$1
#cluster=$2
oldmaster=$3
newmaster=$4ssh=$(which ssh)logfile="/home/mysql/usr/local/orchestrator/orch.log"
interface='eth0'
user=mysql
VIP='10.37.129.10'
VIP_TEMP=$($ssh -tt ${user}@${oldmaster} "sudo ip address|sed -nr 's#^.*inet (.*)/32.*#\1#gp'")
#remove '\r' at the end $'192.168.56.200\r'
VIP_TEMP=$(echo $VIP_TEMP|awk -F"\\r" '{print $1}')if [ ${#VIP_TEMP} -gt 0 ]; thenVIP=$VIP_TEMP
fi
echo ${VIP}
echo ${interface}if [[ $isitdead == "DeadMaster" ]]; thenif [ !-z ${!VIP} ] ; thenecho $(date)echo "Revocering from: $isitdead"echo "New master is: $newmaster"echo "/home/mysql/usr/local/orchestrator/orch_vip.sh -d 1 -n $newmaster -i ${interface} -I $VIP -u ${user} -o ${oldmaster}"/home/mysql/usr/local/orchestrator/orch_vip.sh -d 1 -n $newmaster -i ${interface} -I $VIP -u ${user} -o ${oldmaster}elseecho "Cluster does not exist!" | tee $logfilefi
fi
[mysql@tidb-4 orchestrator]$ cat orch_vip.sh
#!/bin/bashfunction usage {cat << EOFusage: $0 [-h] [-d master is dead] [-o old master ] [-s ssh options] [-n new master] [-i interface] [-I] [-u SSH user]OPTIONS:-h Show this message-o string Old master hostname or IP address-d int If master is dead should be 1 otherweise it is 0-s string SSH options-n string New master hostname or IP address-i string Interface exmple eth0:1-I string Virtual IP-u string SSH user
EOF}while getopts ho:d:s:n:i:I:u: flag; docase $flag ino)orig_master="$OPTARG";;;d)isitdead="${OPTARG}";;;s)ssh_options="${OPTARG}";;;n)new_master="$OPTARG";;;i)interface="$OPTARG";;;I)vip="$OPTARG";;;u)ssh_user="$OPTARG";;;h)usage;exit 0;;;*)usage;exit 1;;;esac
doneif [ $OPTIND -eq 1 ]; thenecho "No options were passed";usage;
fishift $(( OPTIND - 1 ));# discover commands from our path
ssh=$(which ssh)
arping=$(which arping)
ip2util=$(which ip)
#ip2util='ip'# command for adding our vip
cmd_vip_add="sudo -n $ip2util address add $vip dev $interface"
# command for deleting our vip
cmd_vip_del="sudo -n $ip2util address del $vip/32 dev $interface"
# command for discovering if our vip is enabled
cmd_vip_chk="sudo -n $ip2util address show dev $interface to ${vip%/*}/32"
# command for sending gratuitous arp to announce ip move
cmd_arp_fix="sudo -n $arping -c 1 -I ${interface} ${vip%/*}"
# command for sending gratuitous arp to announce ip move on current server
#cmd_local_arp_fix="sudo -n $arping -c 1 -I ${interface} ${vip%/*}"
cmd_local_arp_fix="$arping -c 1 -I ${interface} ${vip%/*}"vip_stop() {rc=0echo $?echo "$ssh ${ssh_options} -tt ${ssh_user}@${orig_master} \\"[ -n \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_del} && \sudo -n ${ip2util} route flush cache || [ -z \"\$(${cmd_vip_chk})\" ]\""# ensure the vip is removed$ssh ${ssh_options} -tt ${ssh_user}@${orig_master} \"[ -n \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_del} && \sudo -n ${ip2util} route flush cache || [ -z \"\$(${cmd_vip_chk})\" ]"rc=$?return $rc
}vip_start() {rc=0# ensure the vip is added# this command should exit with failure if we are unable to add the vip# if the vip already exists always exit 0 (whether or not we added it)echo "$ssh ${ssh_options} -tt ${ssh_user}@${new_master} \\"[ -z \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_add} && ${cmd_arp_fix} || [ -n \"\$(${cmd_vip_chk})\" ]\""$ssh ${ssh_options} -tt ${ssh_user}@${new_master} \"[ -z \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_add} && ${cmd_arp_fix} || [ -n \"\$(${cmd_vip_chk})\" ]"rc=$?echo "vip started"#$cmd_local_arp_fixreturn $rc
}vip_status() {$arping -c 1 -I ${interface} ${vip%/*}echo "$arping -c 1 -I ${interface} ${vip%/*}"if ping -c 1 -W 1 "$vip"; thenreturn 0elsereturn 1fi
}
if [[ $isitdead == 0 ]]; thenecho "Online failover"if vip_stop; thenif vip_start; thenecho "$vip is moved to $new_master."elseecho "Can't add $vip on $new_master!"exit 1fielseecho $rcecho "Can't remove the $vip from orig_master!"exit 1fi
elif [[ $isitdead == 1 ]]; thenecho "Master is dead, failover"# make sure the vip is not availableif vip_status; thenif vip_stop; thenecho "$vip is removed from orig_master."elseecho $rcecho "Couldn't remove $vip from orig_master."exit 1fifiif vip_start; thenecho "$vip is moved to $new_master."elseecho "Can't add $vip on $new_master!"exit 1fi
elseecho "Wrong argument, the master is dead or live?"fi
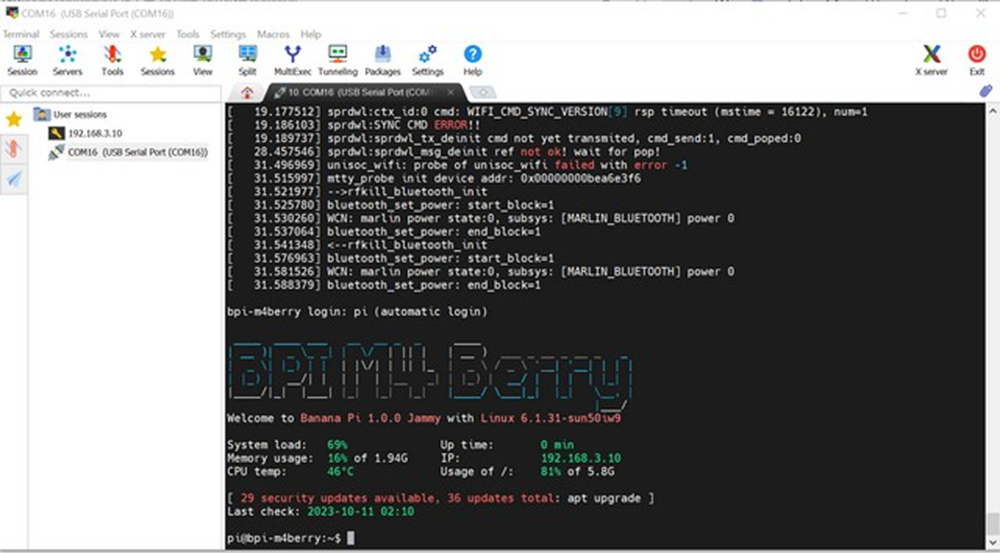
5、启动orch并检查拓扑
./start.sh$ orchestrator-client -c topology -i tidb-4.0-control:3306tidb-4-1:3306 [0s,ok,5.7.41-log,rw,ROW,>>,GTID,semi:master]
+ tidb-4-2:3306 [0s,ok,5.7.41-log,ro,ROW,>>,GTID,semi:master,semi:replica]
+ tidb-4.0-control:3306 [0s,ok,5.7.41-log,rw,ROW,>>,GTID,semi:master,semi:replica]6、手动平滑切换
orchestrator-client -c graceful-master-takeover -a tidb-4.0-control:3306 -d tidb-4-1:3306
注: -a 为旧主 , -d为新主。切换后旧主需手动start slave。
7、强制关闭主库切换
确保旧主库已经提前配置vip,如没配置需执行:
/usr/sbin/ip address add 10.37.129.10 dev eth0
停止主库:
mysql > shutdown;
自动重新change master,并且飘移vip.
该场景下的问题:在主从延迟的情况下,从库会立即提升为主库,新主库有数据不一致的问题。




![BUUCTF刷题:[DDCTF 2019]homebrew event loop](https://img2024.cnblogs.com/blog/3475290/202407/3475290-20240702095836538-575202661.png)
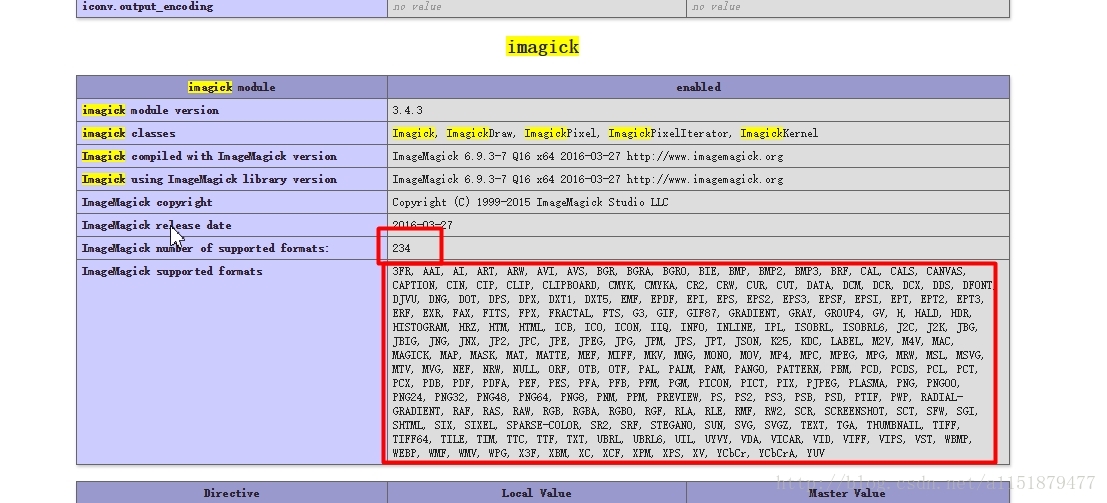
![PHP8.0正常,PHP7.2,PHP7.3报错Connection failed: SQLSTATE[HY000] [2054] The server re....](https://img2024.cnblogs.com/blog/962554/202407/962554-20240702095739054-324384355.png)