- 环境依赖
- 配置SSH
- 克隆代码
- 训练定制
- 代码结构
- 数据标注
- 准备语料库
- 数据标注
- 导出数据
- 数据转换
- doccano
- Label Studio
- 模型微调
- 问题处理
- 找不到 'paddlenlp.trainer'
- 找不到
- GPU
- protobuf==3.20.2
- CUDA/cuDNN/paddle
PaddleNLP UIE 实体关系抽取
PaddlePaddle用户可领取免费Tesla V100在线算力资源,训练模型更高效。每日登陆即送8小时,前往使用免费算力。
随便找个项目如:https://aistudio.baidu.com/projectdetail/1639963 打开后 Fork 一下。
环境依赖
https://gitee.com/paddlepaddle/PaddleNLP/tree/release/2.8#环境依赖
- python >= 3.7
- PandleNLP 2.7.2
- paddlepaddle-gpu >= 2.5.2 # 涉及模型微调,必须 带GPU
### 升级
pip install --upgrade paddlepaddle-gpu==2.5.2
pip install --upgrade paddlenlp==2.7.2aistudio@jupyter-2631487-6335886:~$ pip show paddlepaddle-gpu
Name: paddlepaddle-gpu
Version: 2.5.2
Summary: Parallel Distributed Deep Learning
Home-page: https://www.paddlepaddle.org.cn/
Author:
Author-email: Paddle-better@baidu.com
License: Apache Software License
Location: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages
Requires: astor, decorator, httpx, numpy, opt-einsum, Pillow, protobuf
Required-by: aistudio@jupyter-2631487-6335886:~$ pip show paddlenlp
Name: paddlenlp
Version: 2.7.2
Summary: Easy-to-use and powerful NLP library with Awesome model zoo, supporting wide-range of NLP tasks from research to industrial applications, including Neural Search, Question Answering, Information Extraction and Sentiment Analysis end-to-end system.
Home-page: https://github.com/PaddlePaddle/PaddleNLP
Author: PaddleNLP Team
Author-email: paddlenlp@baidu.com
License: Apache 2.0
Location: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages
Requires: aistudio-sdk, colorama, colorlog, datasets, dill, fastapi, Flask-Babel, huggingface-hub, jieba, jinja2, multiprocess, onnx, paddle2onnx, paddlefsl, protobuf, rich, safetensors, sentencepiece, seqeval, tool-helpers, tqdm, typer, uvicorn, visualdl
Required-by: paddlehub
aistudio@jupyter-2631487-6335886:~$
配置SSH
AI Studio 不能访问 gitee 下载代码,因此可以跳过此小结 直接跳至 代码上传
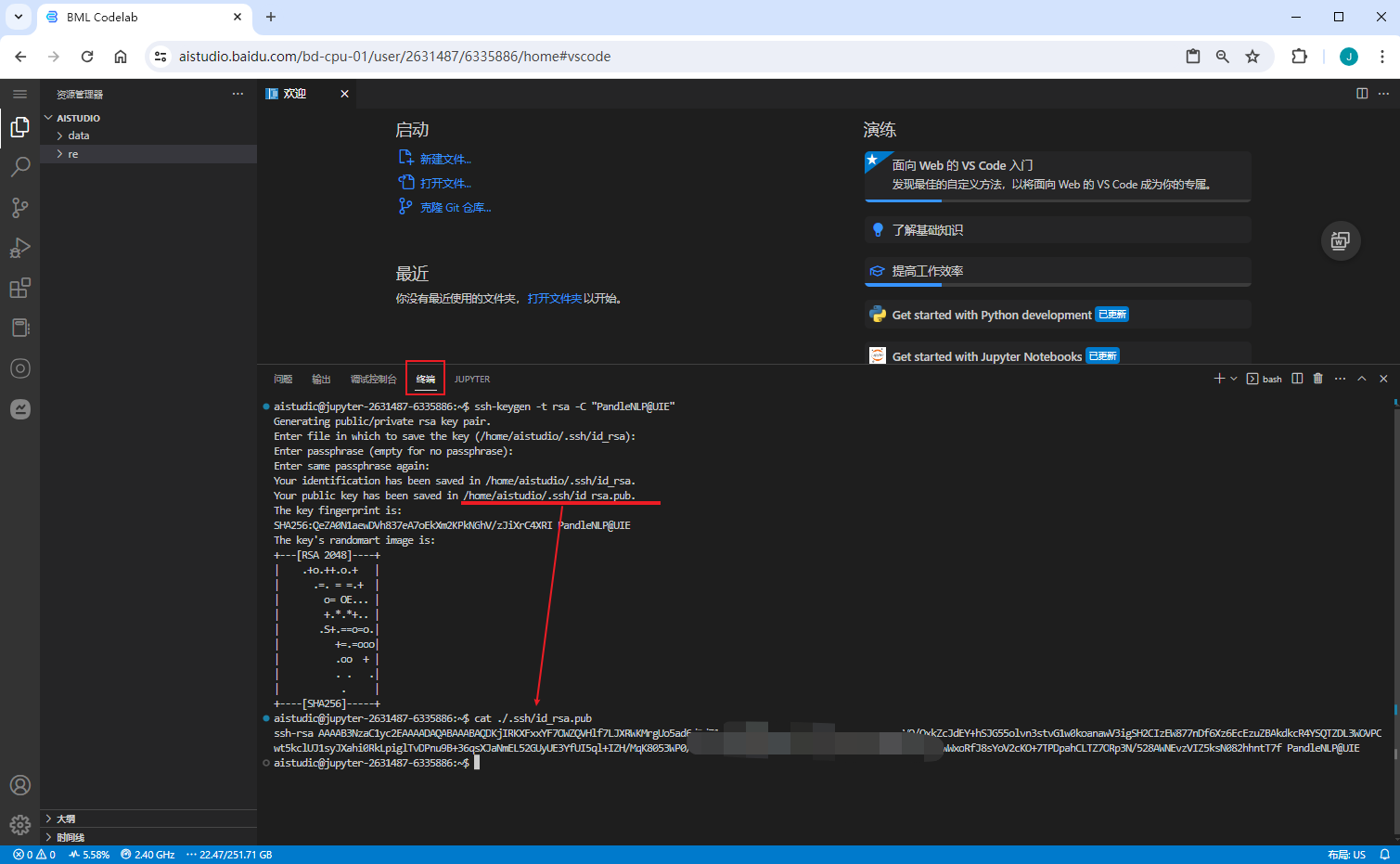
生成SSH
ssh-keygen -t rsa -C "PandleNLP@UIE"
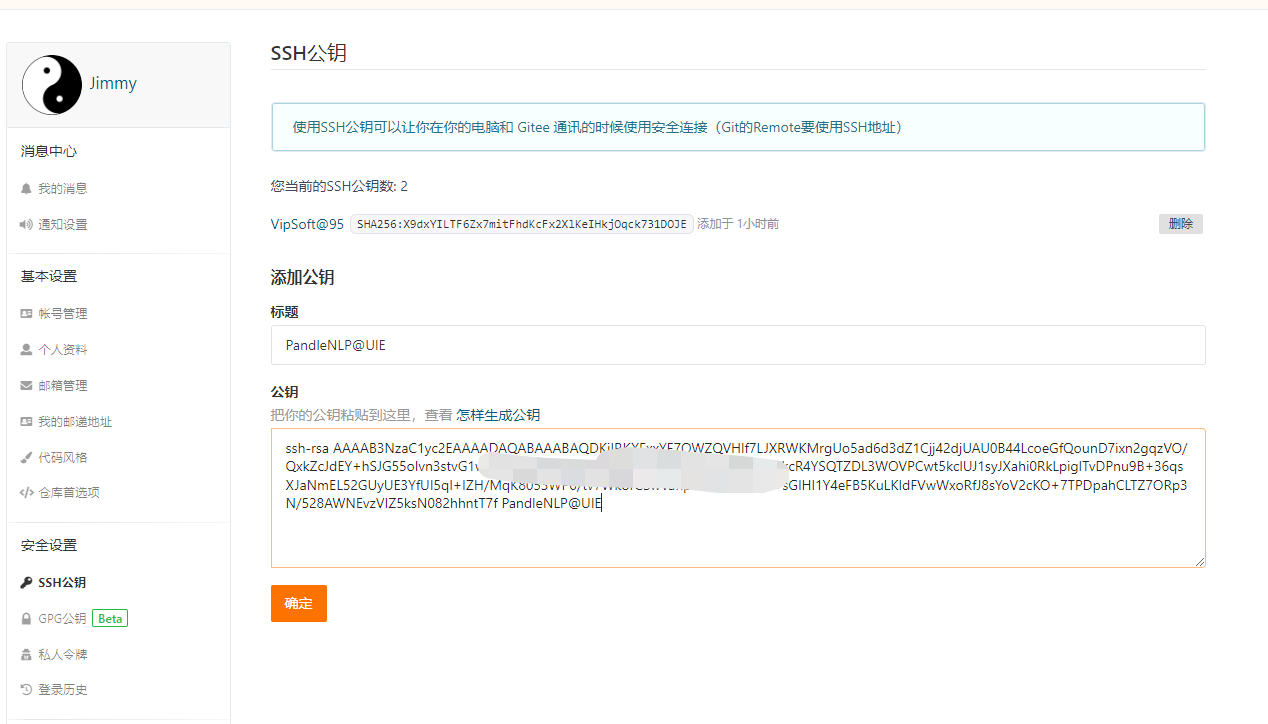
配置公钥
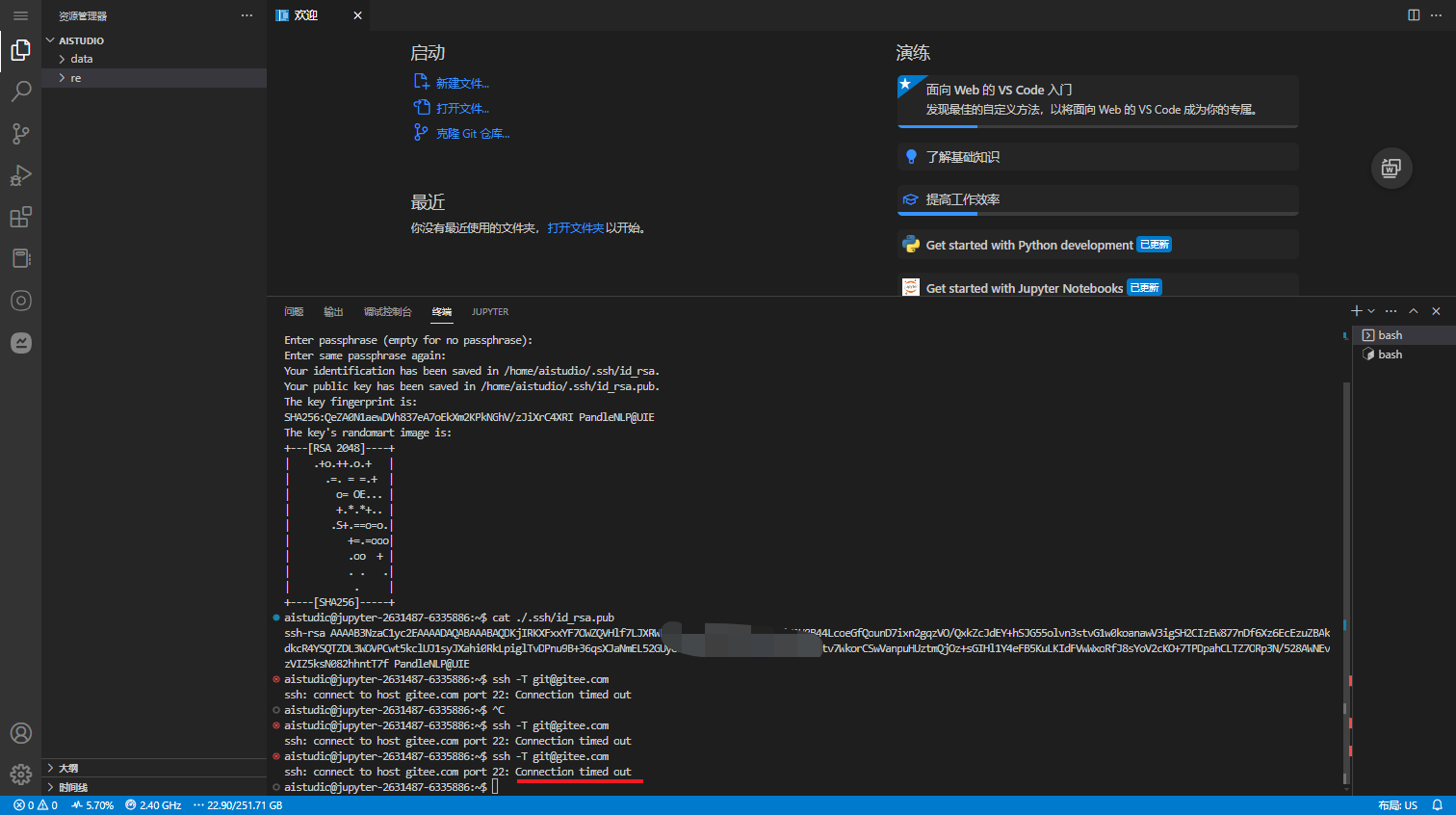
验证
ssh -T git@gitee.com
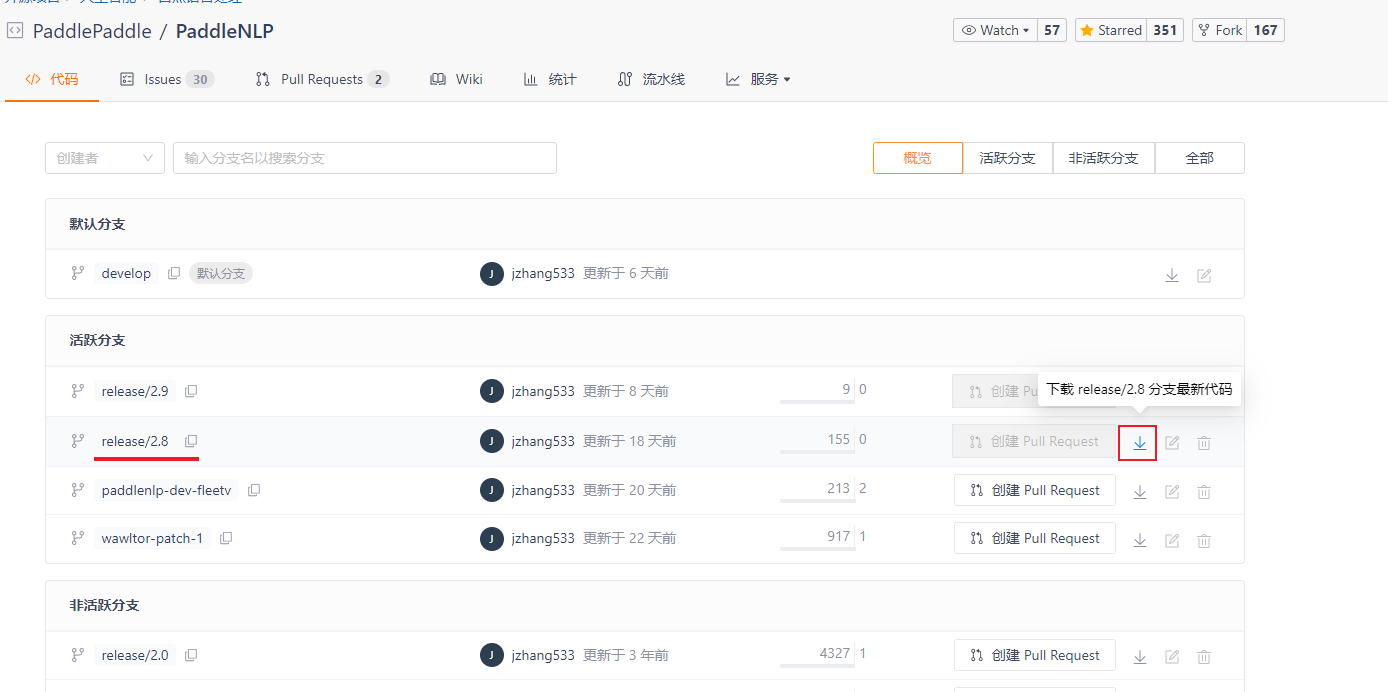
克隆代码
AI Studio 不能访问 gitee.com ,通过本地下载。再上传的方式操作
下载 V2.8
上传代码
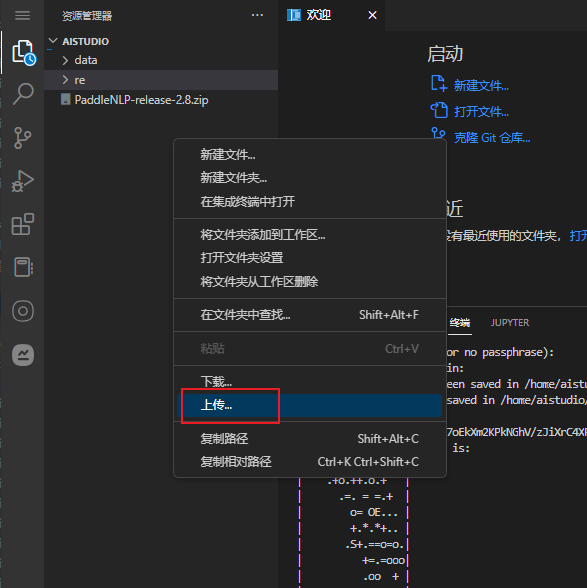
解压代码
unzip -cxvf PaddleNLP-release-2.8.zip
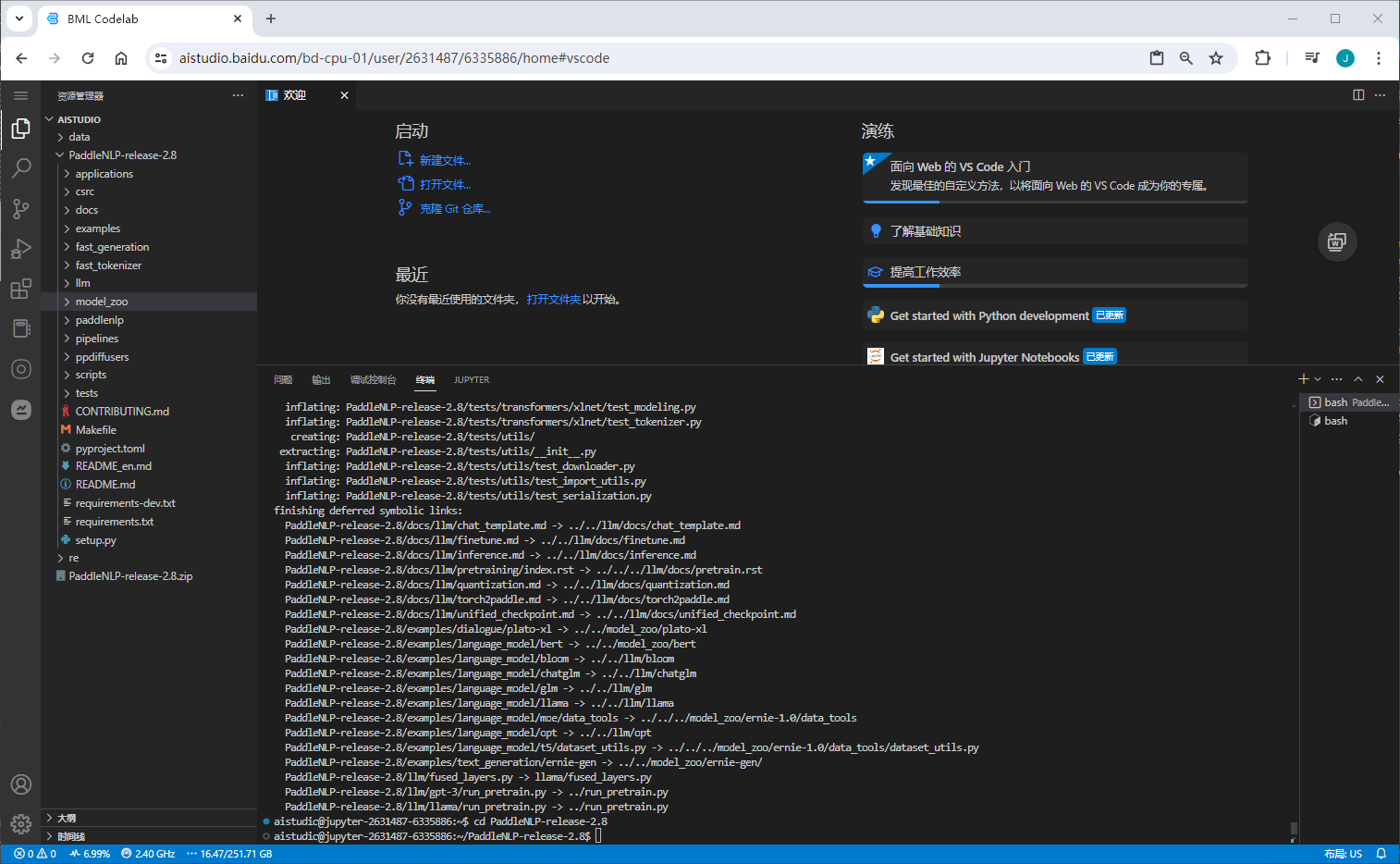
训练定制
代码结构
model_zoo/uie 目录代码文件说明如下:
.
├── utils.py # 数据处理工具
├── model.py # 模型组网脚本
├── doccano.py # 数据标注脚本 => 下面数据转换时会用到
├── doccano.md # 数据标注文档
├── finetune.py # 模型微调、压缩脚本
├── evaluate.py # 模型评估脚本
└── README.md
对于细分场景推荐使用轻定制功能(标注少量数据进行模型微调)以进一步提升效果
schema =['药品名称','用法','用量','频次']
ie = Taskflow('information_extraction',schema=schema)
pprint(ie("布洛芬分散片,口服或加水分散后服用。用于成人及12岁以上儿童,推荐剂里为一次0.2~0.4(1~2片)一日3次,或遵医嘱"))
如图:只能提取出药品名称,接下来,通过训练数据进行UIE模型微调

数据标注
详细过程参考 数据标注工具 doccano | 命名实体识别(Named Entity Recognition,简称NER)
准备语料库
准备语料库、每一行为一条待标注文本,示例:corpus.txt
布洛芬分散片,口服或加水分散后服用。用于成人及12岁以上儿童,推荐剂里为一次0.2~0.4(1~2片)一日3次,或遵医嘱
白加黑(氨酚伪麻美芬片Ⅱ氨麻苯美片),口服。一次1~2片,一日3次(早、中各1~2白片,夜晚1~2片黑片),儿童遵医嘱
氯雷他定片,口服,规格为10mg的氯雷他定片,通常成人及12岁以上儿童1天1次,1次1片
扶他林(双氯芬酸二乙胺乳胶剂),外用。按照痛处面积大小,使用本品适量,轻轻揉搓,使本品渗透皮肤,一日3-4次
七叶洋地黄双苷,外用。用于黄斑变性时,每日3次,每次1滴,滴入眼结膜囊内(近耳侧外眼角)
数据标注
定义标签
Demo简单的定了 "药品名称、通用名、规格、用法、用量、频次"
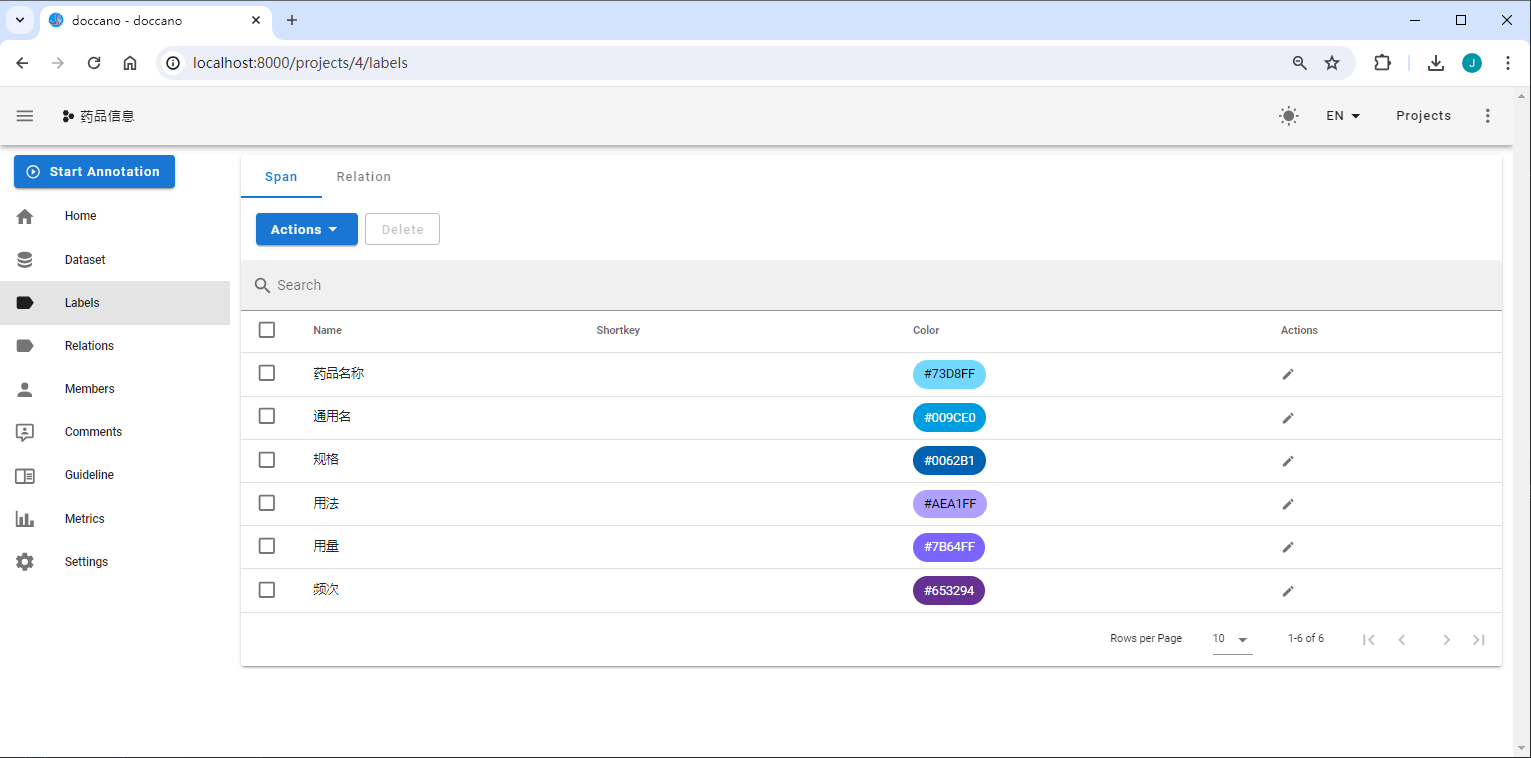
数据标注
在doccano平台上,创建一个类型为序列标注的标注项目。
定义实体标签类别,上例中需要定义的实体标签有[ 药品名称、通用名、规格、用法、用量、频次 ]。
使用以上定义的标签开始标注数据,下面展示了一个doccano标注示例:
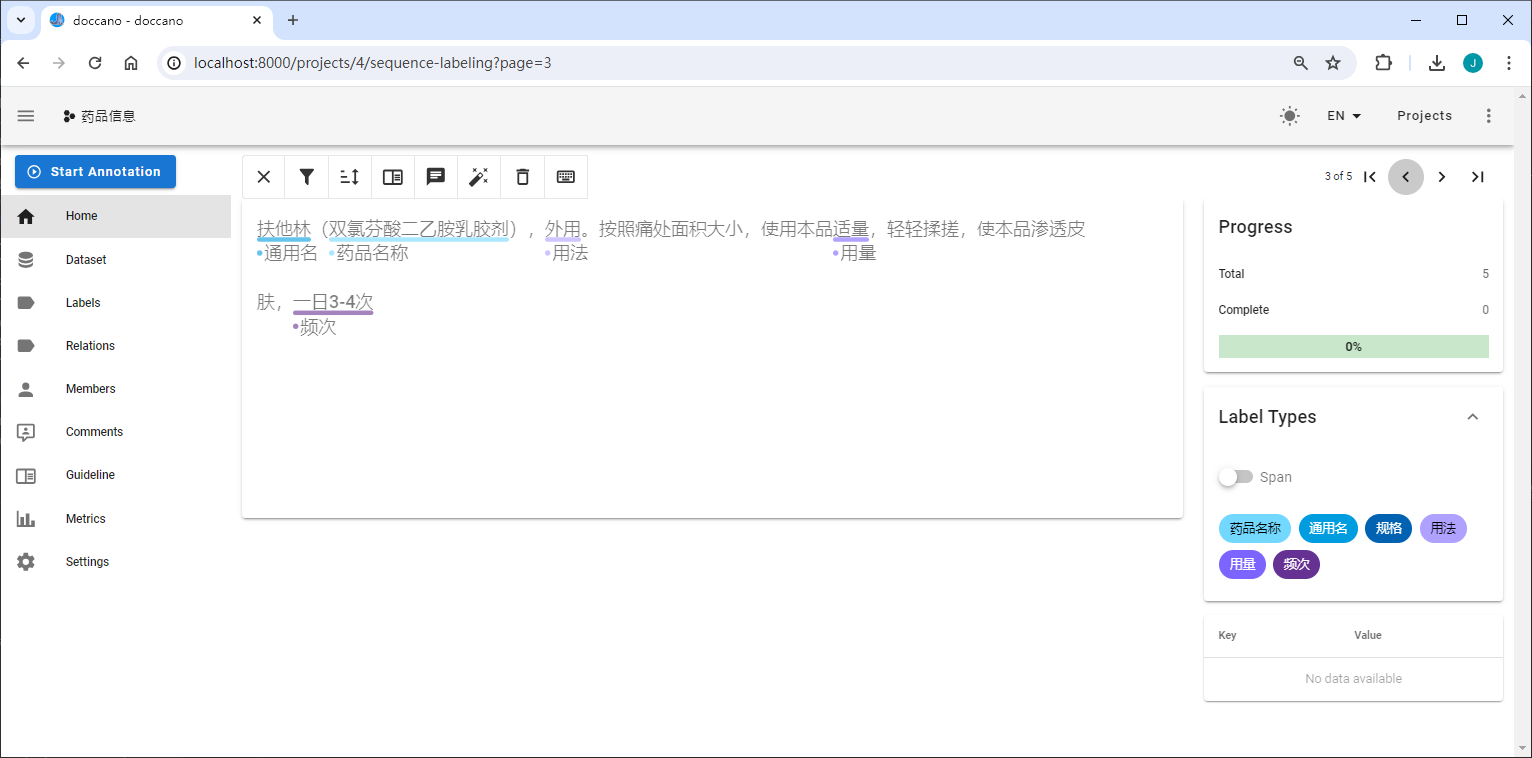
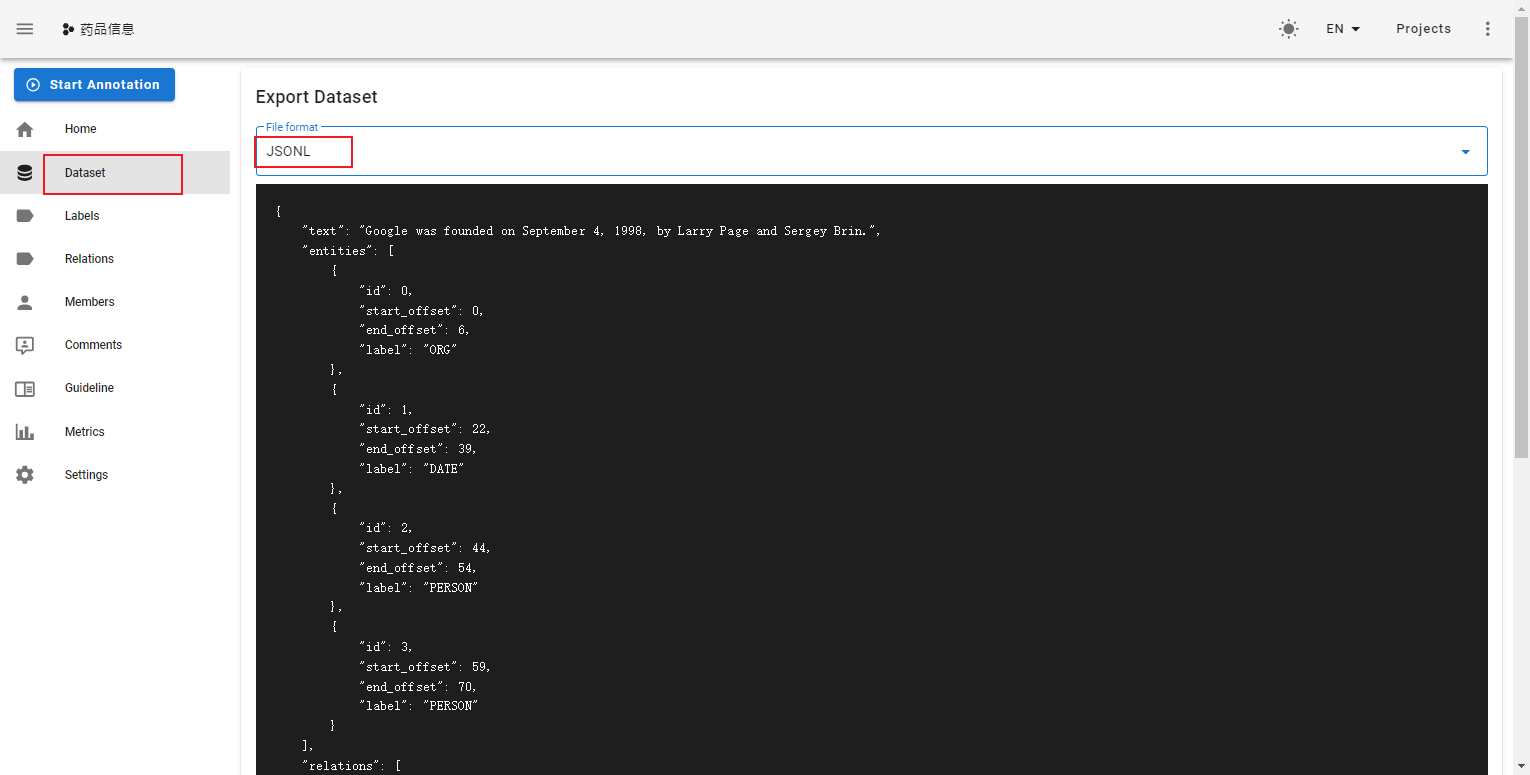
导出数据
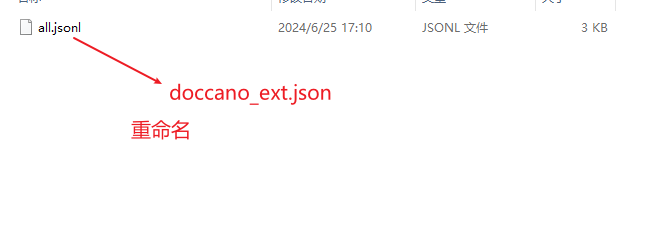
标注完成后,在doccano平台上导出文件,并将其重命名为doccano_ext.json后,放入./data目录下
数据转换
在这一步最好换成GPU环境,否则切换到GPU环境后,还需要安装 paddlepaddle 等操作
## 模型微调必须使用GPU
pip install --upgrade paddlepaddle-gpu==2.5.2
pip install --upgrade paddlenlp==2.7.2
doccano
在 AI Studio 环境中创建 data 目录,将 doccano_ext.json 放入data目录中
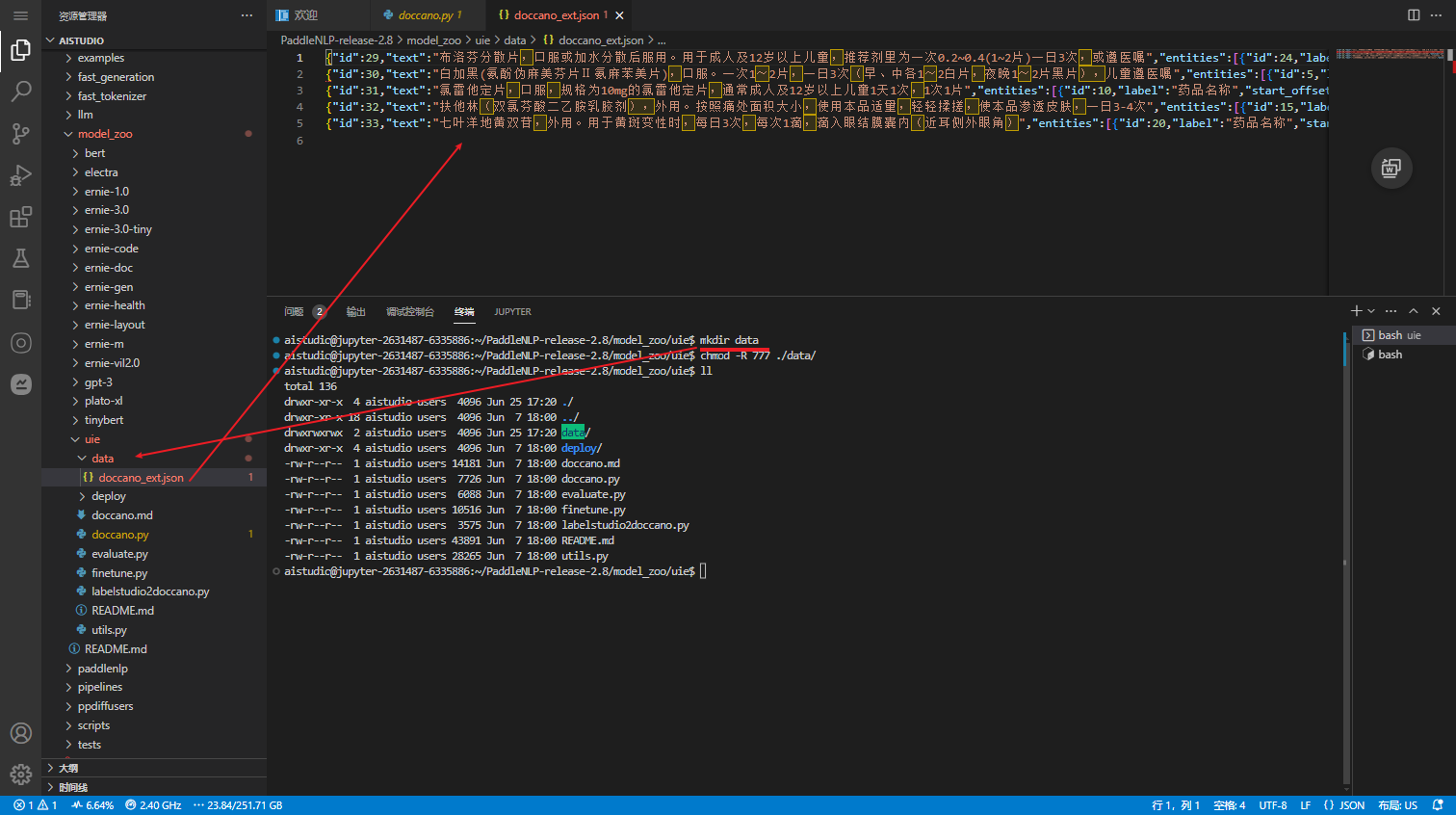
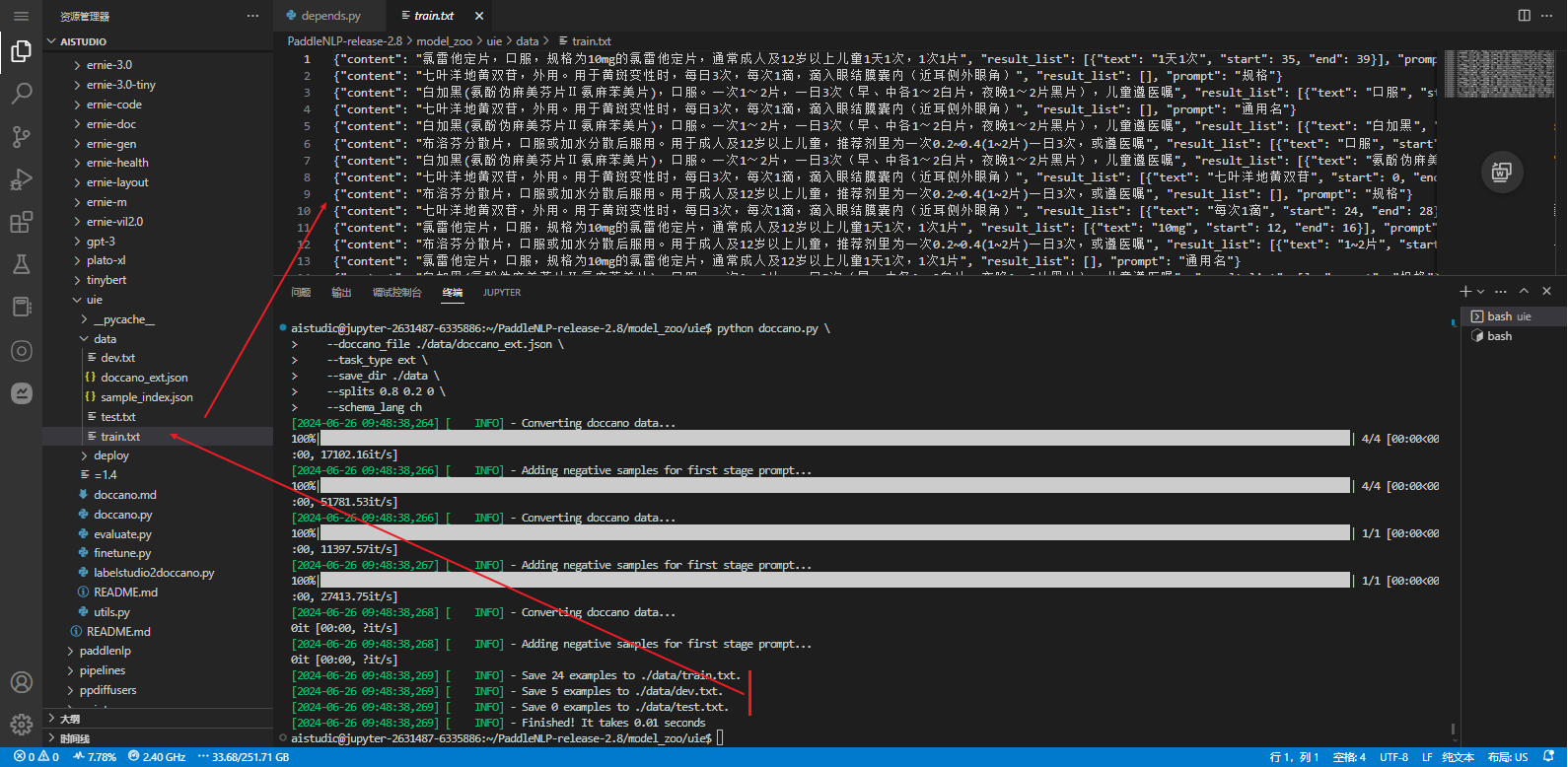
执行以下脚本进行数据转换,执行后会在./data目录下生成训练/验证/测试集文件。
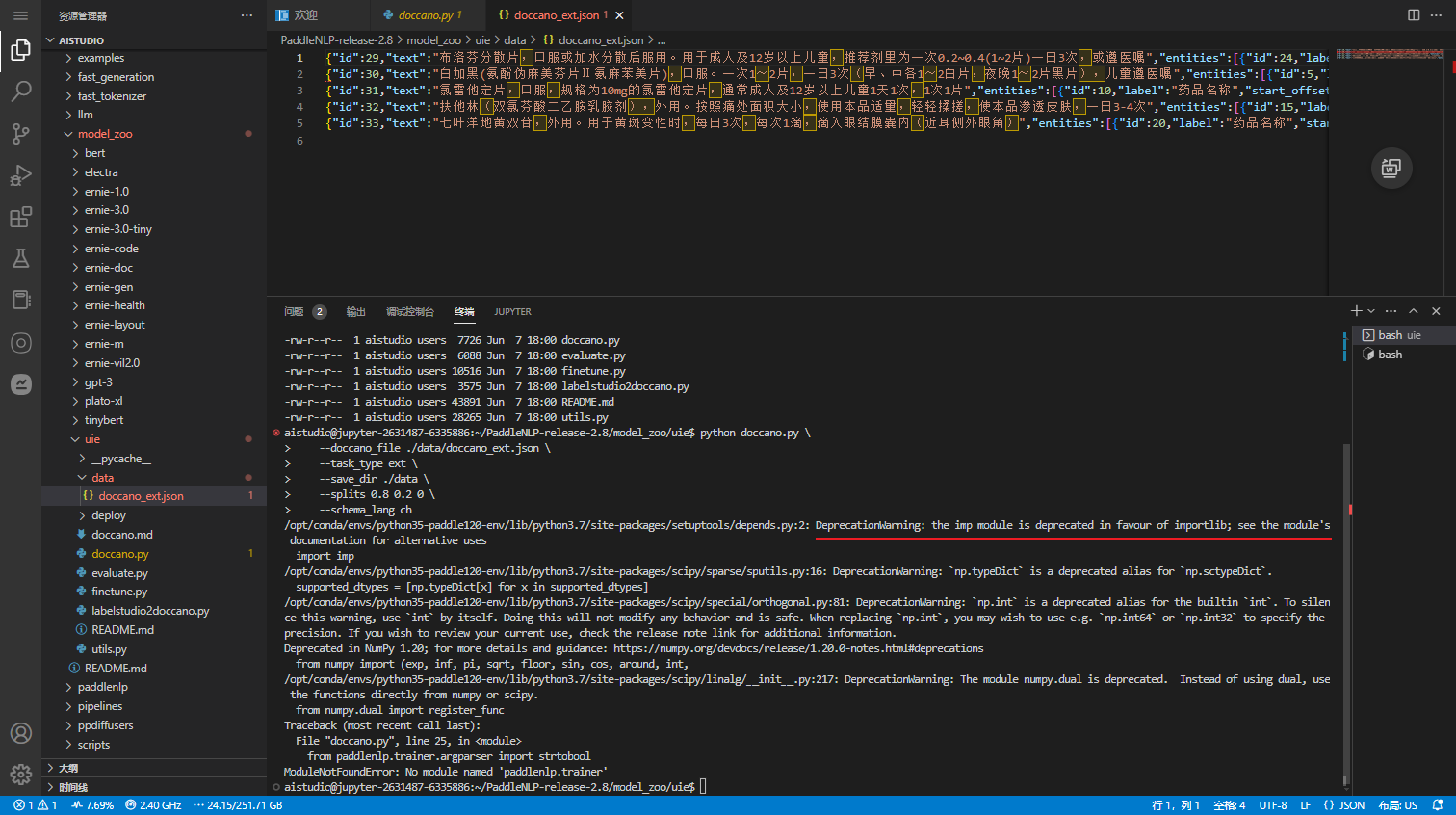
python doccano.py \--doccano_file ./data/doccano_ext.json \--task_type ext \--save_dir ./data \--splits 0.8 0.2 0 \--schema_lang ch
# 执行后会在./data目录下生成训练/验证/测试集文件。
[2024-06-26 09:48:38,269] [ INFO] - Save 24 examples to ./data/train.txt.
[2024-06-26 09:48:38,269] [ INFO] - Save 5 examples to ./data/dev.txt.
[2024-06-26 09:48:38,269] [ INFO] - Save 0 examples to ./data/test.txt.
可配置参数说明:
doccano_file: 从doccano导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为["正向", "负向"]。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为"##"。schema_lang: 选择schema的语言,可选有ch和en。默认为ch,英文数据集请选择en。
备注:
- 默认情况下 doccano.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过
negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。 - 对于从doccano导出的文件,默认文件中的每条数据都是经过人工正确标注的。
Label Studio
也可以通过数据标注平台 Label Studio 进行数据标注。 labelstudio2doccano.py 脚本,将 label studio 导出的 JSON 数据文件格式转换成 doccano 导出的数据文件格式,后续的数据转换与模型微调等操作不变。
python labelstudio2doccano.py --labelstudio_file label-studio.json
可配置参数说明:
labelstudio_file: label studio 的导出文件路径(仅支持 JSON 格式)。doccano_file: doccano 格式的数据文件保存路径,默认为 "doccano_ext.jsonl"。task_type: 任务类型,可选有抽取("ext")和分类("cls")两种类型的任务,默认为 "ext"。
模型微调
必须使用GPU pip install --upgrade paddlepaddle-gpu==2.5.2推荐使用 Trainer API 对模型进行微调。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调和模型压缩等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。
使用下面的命令,使用 uie-base 作为预训练模型进行模型微调,将微调后的模型保存至$finetuned_model:
单卡启动:
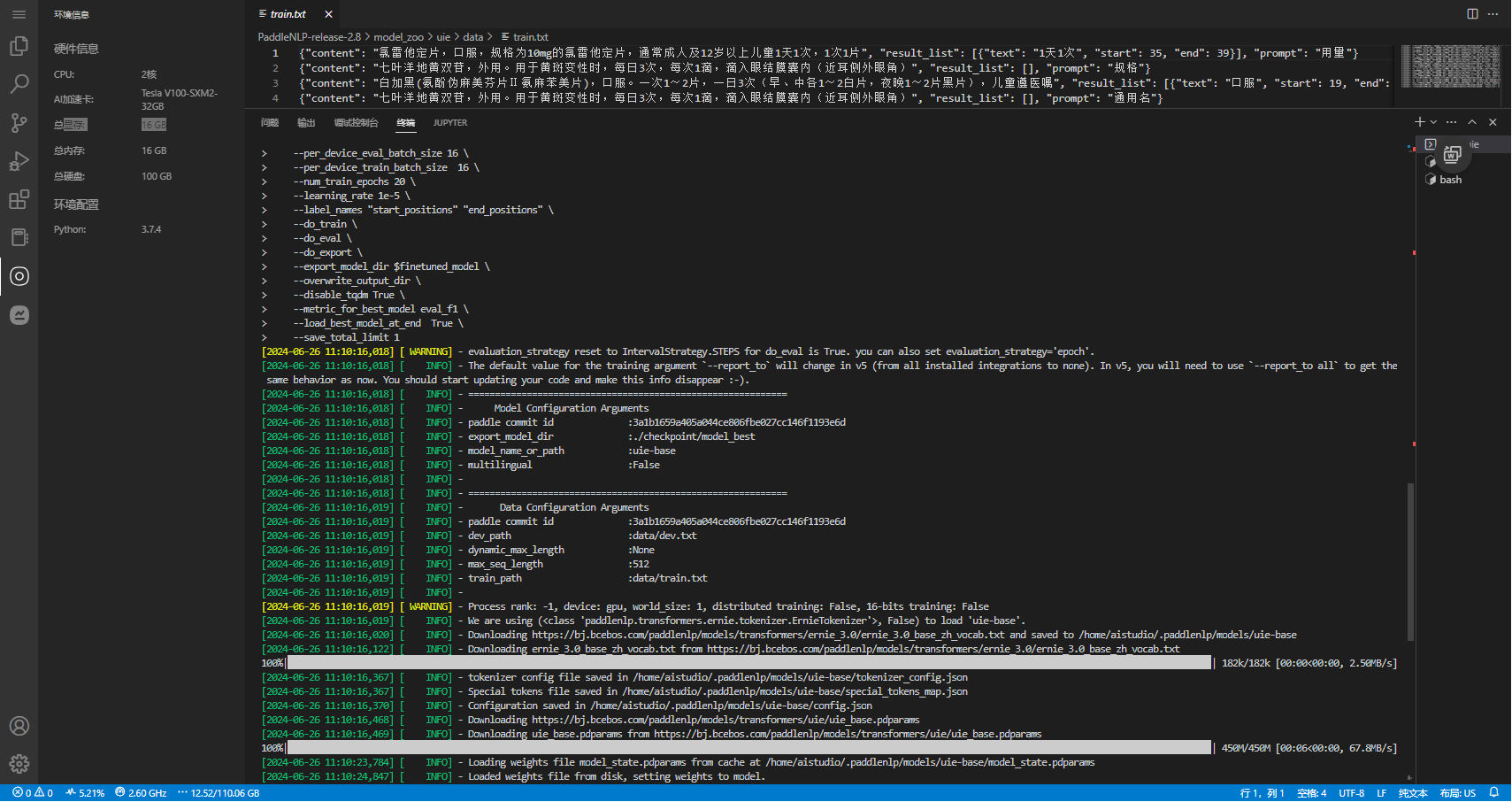
export finetuned_model=./checkpoint/model_bestpython finetune.py \--device gpu \--logging_steps 10 \--save_steps 100 \--eval_steps 100 \--seed 42 \--model_name_or_path uie-base \--output_dir $finetuned_model \--train_path data/train.txt \--dev_path data/dev.txt \--per_device_eval_batch_size 16 \--per_device_train_batch_size 16 \--num_train_epochs 20 \--learning_rate 1e-5 \--label_names "start_positions" "end_positions" \--do_train \--do_eval \--do_export \--export_model_dir $finetuned_model \--overwrite_output_dir \--disable_tqdm True \--metric_for_best_model eval_f1 \--load_best_model_at_end True \--save_total_limit 1注意:如果模型是跨语言模型 UIE-M,还需设置 --multilingual。
可配置参数说明:
model_name_or_path:必须,进行 few shot 训练使用的预训练模型。可选择的有 "uie-base"、 "uie-medium", "uie-mini", "uie-micro", "uie-nano", "uie-m-base", "uie-m-large"。multilingual:是否是跨语言模型,用 "uie-m-base", "uie-m-large" 等模型进微调得到的模型也是多语言模型,需要设置为 True;默认为 False。output_dir:必须,模型训练或压缩后保存的模型目录;默认为None。device: 训练设备,可选择 'cpu'、'gpu' 、'npu'其中的一种;默认为 GPU 训练。per_device_train_batch_size:训练集训练过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。per_device_eval_batch_size:开发集评测过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。learning_rate:训练最大学习率,UIE 推荐设置为 1e-5;默认值为3e-5。num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。logging_steps: 训练过程中日志打印的间隔 steps 数,默认100。save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。weight_decay:除了所有 bias 和 LayerNorm 权重之外,应用于所有层的权重衰减数值。可选;默认为 0.0;do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。do_eval:是否进行评估,设置该参数表示进行评估。
该示例代码中由于设置了参数 --do_eval,因此在训练完会自动进行评估。
问题处理
找不到 'paddlenlp.trainer'
报找不到模块:ModuleNotFoundError: No module named 'paddlenlp.trainer'
import imp
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/sparse/sputils.py:16: DeprecationWarning: `np.typeDict` is a deprecated alias for `np.sctypeDict`.supported_dtypes = [np.typeDict[x] for x in supported_dtypes]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/special/orthogonal.py:81: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecationsfrom numpy import (exp, inf, pi, sqrt, floor, sin, cos, around, int,
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/linalg/__init__.py:217: DeprecationWarning: The module numpy.dual is deprecated. Instead of using dual, use the functions directly from numpy or scipy.from numpy.dual import register_func
Traceback (most recent call last):File "doccano.py", line 25, in <module>from paddlenlp.trainer.argparser import strtobool
ModuleNotFoundError: No module named 'paddlenlp.trainer'
pip show paddlepaddle
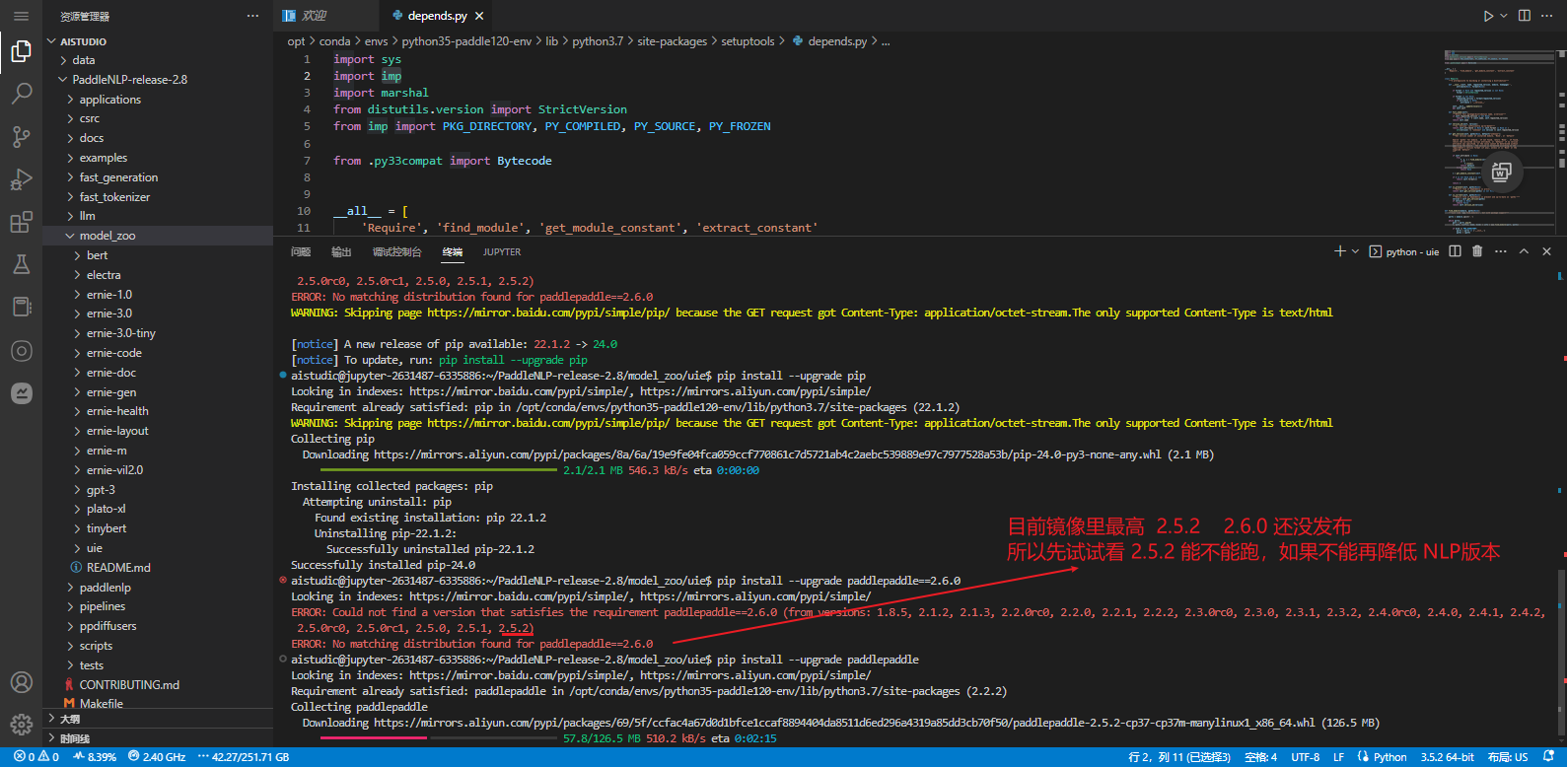
Name: paddlepaddle
Version: 2.2.2 # 环境中是2.2.2 https://gitee.com/paddlepaddle/PaddleNLP/tree/release/2.8 要求 paddlepaddle >=2.6.0
Summary: Parallel Distributed Deep Learning
Home-page: UNKNOWN
Author:
Author-email: Paddle-better@baidu.com
License: Apache Software License
Location: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages
Requires: astor, decorator, numpy, Pillow, protobuf, requests, six
Required-by:
升级Paddlepaddle
pip install --upgrade paddlepaddle-gpu==2.5.2
pip install --upgrade paddlenlp==2.7.2
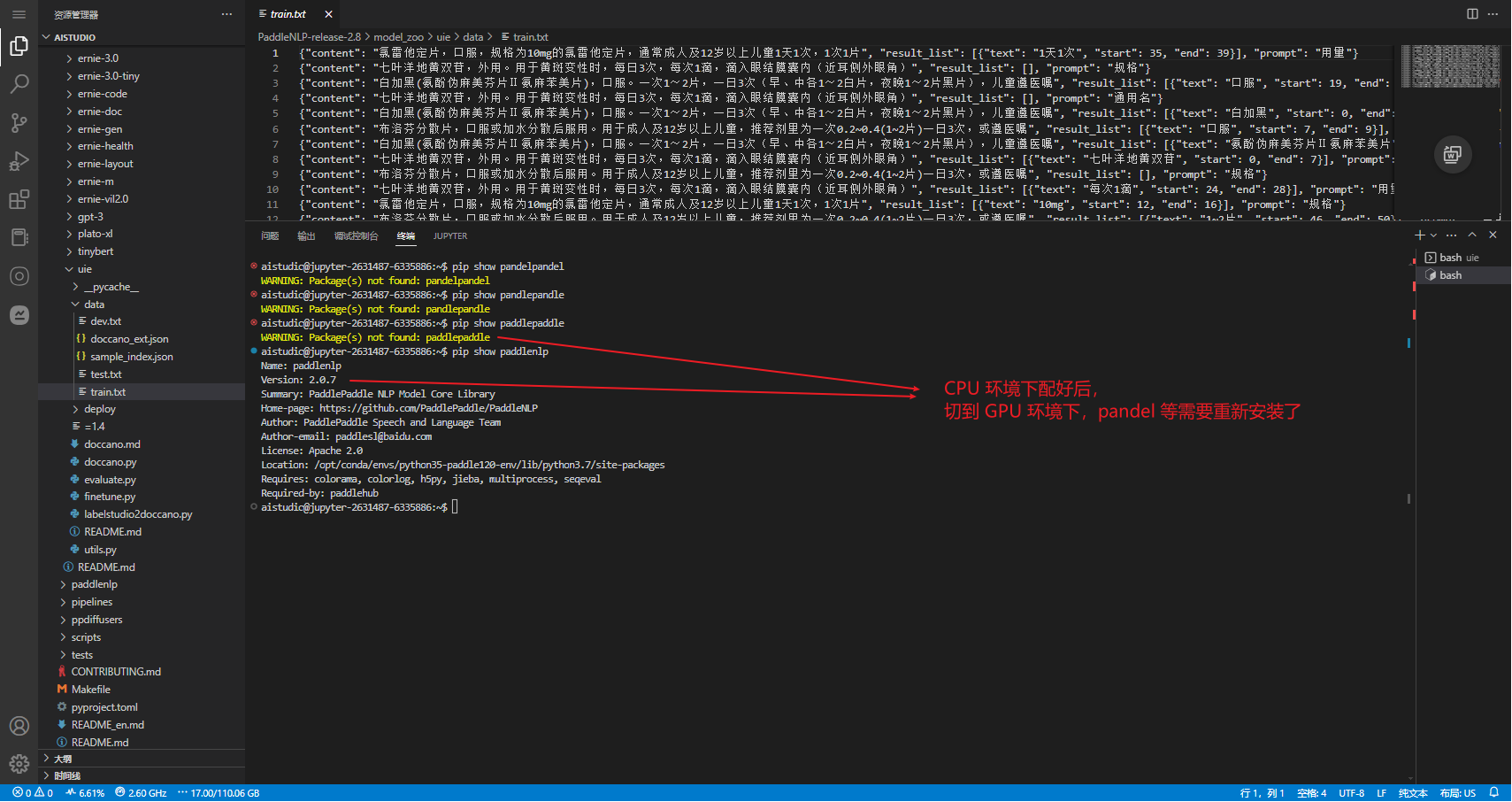
找不到
ModuleNotFoundError: No module named ‘paddle.fluid.layers.utils
升级 PaddleNLP ,环境中有安装,所以先升下级,其实已经下了源代码。理论上可以卸载 PaddleNLP 直接跑源码的。
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
streamlit 1.13.0 requires importlib-metadata>=1.4, but you have importlib-metadata 0.23 which is incompatible.
streamlit 1.13.0 requires protobuf!=3.20.2,<4,>=3.12, but you have protobuf 4.24.4 which is incompatible.flake8 4.0.1 requires importlib-metadata<4.3; python_version < "3.8", but you have importlib-metadata 6.7.0 which is incompatible.
python-lsp-server 1.5.0 requires ujson>=3.0.0, but you have ujson 1.35 which is incompatible.
streamlit 1.13.0 requires protobuf!=3.20.2,<4,>=3.12, but you have protobuf 4.24.4 which is incompatible
根据提示升级
# importlib-metadata
pip install --upgrade importlib-metadata==1.4
# protobuf
pip install --upgrade protobuf>=1.4
pip install --upgrade ujson==3.0.0
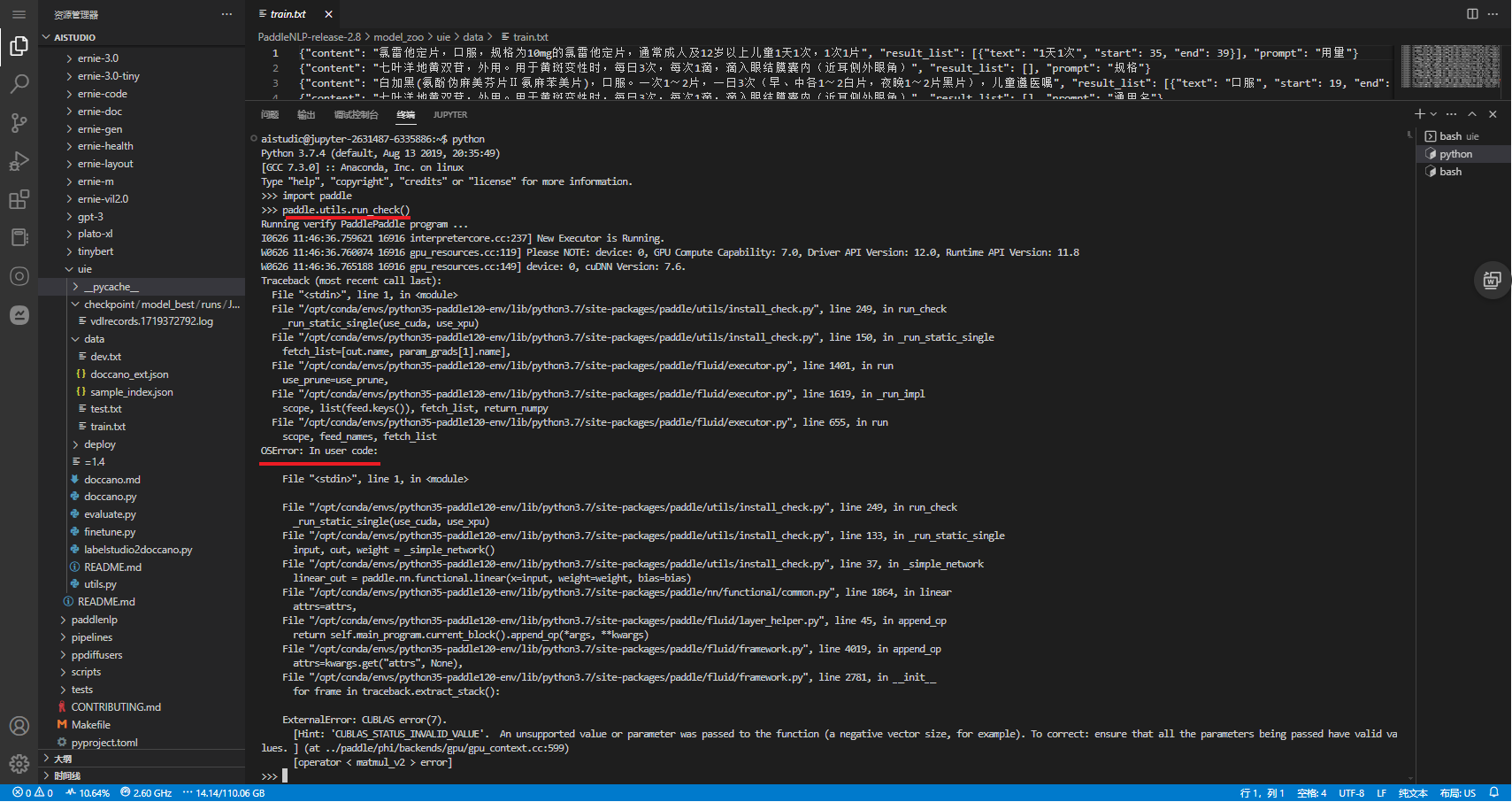
GPU
模型微调需使用GPU
Traceback (most recent call last):File "finetune.py", line 262, in <module>main()File "finetune.py", line 98, in mainpaddle.set_device(training_args.device)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/device/__init__.py", line 266, in set_deviceplace = _convert_to_place(device)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/device/__init__.py", line 181, in _convert_to_place"The device should not be 'gpu', "
ValueError: The device should not be 'gpu', since PaddlePaddle is not compiled with CUDA
在这一步最好换成GPU环境,否则切换到GPU环境后,还需要安装 paddlepaddle 等操作
protobuf==3.20.2
[2024-06-26 11:16:18,349] [ INFO] - All the weights of UIE were initialized from the model checkpoint at uie-base.
If your task is similar to the task the model of the checkpoint was trained on, you can already use UIE for predictions without further training.
[2024-06-26 11:16:18,371] [ INFO] - The global seed is set to 42, local seed is set to 43 and random seed is set to 42.
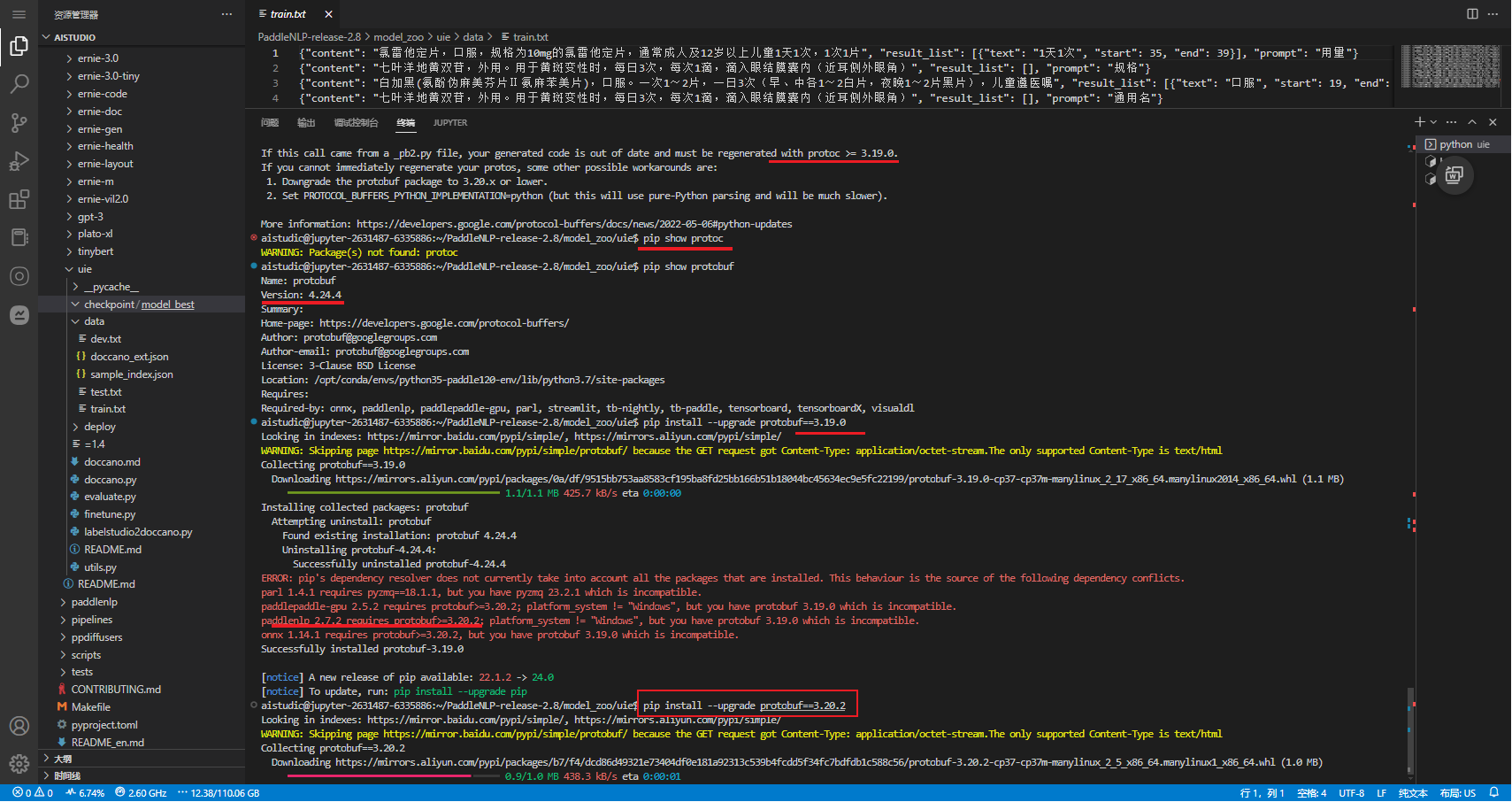
Traceback (most recent call last):File "finetune.py", line 262, in <module>main()File "finetune.py", line 179, in maincompute_metrics=compute_metrics,File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/trainer/trainer.py", line 344, in __init__callbacks, self.model, self.tokenizer, self.optimizer, self.lr_schedulerFile "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/trainer/trainer_callback.py", line 307, in __init__self.add_callback(cb)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/trainer/trainer_callback.py", line 324, in add_callbackcb = callback() if isinstance(callback, type) else callbackFile "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/trainer/integrations.py", line 74, in __init__from visualdl import LogWriterFile "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/visualdl/__init__.py", line 20, in <module>from visualdl.writer.writer import LogWriter # noqa: F401File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/visualdl/writer/writer.py", line 19, in <module>from visualdl.writer.record_writer import RecordFileWriterFile "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/visualdl/writer/record_writer.py", line 18, in <module>from visualdl.proto import record_pb2File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/visualdl/proto/record_pb2.py", line 40, in <module>serialized_options=None, file=DESCRIPTOR),File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/google/protobuf/descriptor.py", line 561, in __new___message.Message._CheckCalledFromGeneratedFile()
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:1. Downgrade the protobuf package to 3.20.x or lower.2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
# 降低 Protobuf 版本
pip install --upgrade protobuf==3.20.2
CUDA/cuDNN/paddle
[2024-06-26 11:43:01,264] [ DEBUG] - Number of trainable parameters = 117,946,370 (per device)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py:2541: FutureWarning: The `max_seq_len` argument is deprecated and will be removed in a future version, please use `max_length` instead.FutureWarning,
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py:1944: FutureWarning: The `pad_to_max_length` argument is deprecated and will be removed in a future version, use `padding=True` or `padding='longest'` to pad to the longest sequence in the batch, or use `padding='max_length'` to pad to a max length. In this case, you can give a specific length with `max_length` (e.g. `max_length=45`) or leave max_length to None to pad to the maximal input size of the model (e.g. 512 for Bert).FutureWarning,
Traceback (most recent call last):File "finetune.py", line 262, in <module>main()File "finetune.py", line 193, in maintrain_result = trainer.train(resume_from_checkpoint=checkpoint)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/trainer/trainer.py", line 924, in traintr_loss_step = self.training_step(model, inputs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/trainer/trainer.py", line 1955, in training_steploss = self.compute_loss(model, inputs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/trainer/trainer.py", line 1899, in compute_lossoutputs = model(**inputs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/layers.py", line 1254, in __call__return self.forward(*inputs, **kwargs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/distributed/parallel.py", line 531, in forwardoutputs = self._layers(*inputs, **kwargs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/layers.py", line 1254, in __call__return self.forward(*inputs, **kwargs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/ernie/modeling.py", line 1275, in forwardreturn_dict=return_dict,File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/layers.py", line 1254, in __call__return self.forward(*inputs, **kwargs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/ernie/modeling.py", line 363, in forwardreturn_dict=return_dict,File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/layers.py", line 1254, in __call__return self.forward(*inputs, **kwargs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/model_outputs.py", line 312, in _transformer_encoder_fwdoutput_attentions=output_attentions,File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/layers.py", line 1254, in __call__return self.forward(*inputs, **kwargs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/model_outputs.py", line 83, in _transformer_encoder_layer_fwdattn_outputs = self.self_attn(src, src, src, src_mask, cache)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/layers.py", line 1254, in __call__return self.forward(*inputs, **kwargs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/transformer.py", line 418, in forwardq, k, v = self._prepare_qkv(query, key, value, cache)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/transformer.py", line 242, in _prepare_qkvq = self.q_proj(query)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/layers.py", line 1254, in __call__return self.forward(*inputs, **kwargs)File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/common.py", line 175, in forwardx=input, weight=self.weight, bias=self.bias, name=self.nameFile "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/functional/common.py", line 1842, in linearreturn _C_ops.linear(x, weight, bias)
OSError: (External) CUBLAS error(7). [Hint: 'CUBLAS_STATUS_INVALID_VALUE'. An unsupported value or parameter was passed to the function (a negative vector size, for example). To correct: ensure that all the parameters being passed have valid values. ] (at ../paddle/phi/backends/gpu/gpu_context.cc:599)[operator < linear > error]
aistudio@jupyter-2631487-6335886:~/PaddleNLP-release-2.8/model_zoo/uie$
aistudio@jupyter-2631487-6335886:~$ python
Python 3.7.4 (default, Aug 13 2019, 20:35:49)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import paddle
>>> paddle.utils.run_check()
未完待续