selenium介绍
开发使用有头浏览器,部署使用无界面浏览器
selenium工作原理
利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件,配置证书之类的)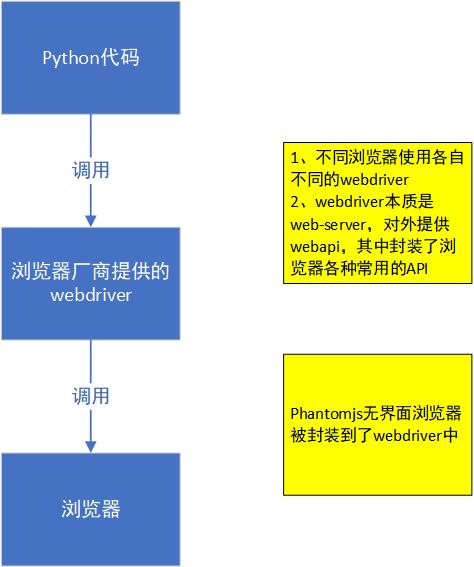
selenium模块与driver的安装
- 安装 Selenium 模块
pip install selenium
- 下载浏览器驱动
Selenium 需要一个浏览器驱动程序来与浏览器进行通信。以下是一些常用浏览器的驱动程序下载地址:
ChromeDriver(用于 Google Chrome): ChromeDriver 下载链接
EdgeDriver(用于 Microsoft Edge): EdgeDriver 下载链接
下载合适的驱动程序后,将其解压并放置在你的系统 PATH 中,或者记下其路径以便稍后使用。
- 设置并启动浏览器
安装好 Selenium 模块和浏览器驱动后,可以编写脚本来启动浏览器。以下是一个简单的示例,展示如何使用 ChromeDriver 启动 Chrome 浏览器:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys# 指定 ChromeDriver 的路径(如果不在系统 PATH 中) driver_path = 'path/to/chromedriver'# 初始化 Chrome 浏览器 driver = webdriver.Chrome(executable_path=driver_path)# 访问一个网站 driver.get('http://www.google.com')# 查找搜索框元素,并输入一些文本 search_box = driver.find_element(By.NAME, 'q') search_box.send_keys('Selenium') search_box.send_keys(Keys.RETURN)# 关闭浏览器 driver.quit()
- 添加驱动路径到系统 PATH(可选)
如果不想每次都指定驱动路径,可以将驱动程序的路径添加到系统 PATH 中:
Windows
- 右键点击“此电脑”,选择“属性”。
- 点击“高级系统设置”。
- 点击“环境变量”。
- 在“系统变量”中,找到
Path,并点击“编辑”。 - 点击“新建”,并输入驱动程序的路径。
- 确认并保存所有对话框。
driver属性和方法
属性
| 属性 | 描述 | 示例 |
|---|---|---|
current_url |
获取当前页面的 URL | url = driver.current_url |
title |
获取当前页面的标题 | title = driver.title |
page_source |
获取当前页面的源代码 | page_source = driver.page_source |
current_window_handle |
获取当前窗口的句柄 | current_window = driver.current_window_handle |
window_handles |
获取所有打开窗口的句柄 | windows = driver.window_handles |
方法
| 方法 | 描述 | 示例 |
|---|---|---|
get(url) |
打开指定的 URL | driver.get('http://www.example.com') |
find_element(by, value) |
查找单个元素 | element = driver.find_element(By.ID, 'element_id') |
find_elements(by, value) |
查找多个元素 | elements = driver.find_elements(By.CLASS_NAME, 'element_class') |
close() |
关闭当前窗口 | driver.close() |
quit() |
关闭所有窗口并退出浏览器 | driver.quit() |
back() |
导航到浏览器历史记录中的前一个页面 | driver.back() |
forward() |
导航到浏览器历史记录中的下一个页面 | driver.forward() |
refresh() |
刷新当前页面 | driver.refresh() |
execute_script(script, *args) |
在当前页面上执行 JavaScript | driver.execute_script("alert('Hello World!');") |
get_screenshot_as_file(filename) |
截取当前页面的截图并保存到文件中 | driver.get_screenshot_as_file('screenshot.png') |
switch_to |
切换到不同的上下文(如 iframe 或窗口) | driver.switch_to.frame('frame_name')<br>driver.swit |
元素定位
定位方式
| 定位方式 | 描述 | 示例 |
|---|---|---|
By.ID |
通过元素的 id 属性定位 |
element = driver.find_element(By.ID, 'element_id') |
By.NAME |
通过元素的 name 属性定位 |
element = driver.find_element(By.NAME, 'element_name') |
By.CLASS_NAME |
通过元素的 class 属性定位 |
element = driver.find_element(By.CLASS_NAME, 'class_name') |
By.TAG_NAME |
通过元素的标签名定位 | element = driver.find_element(By.TAG_NAME, 'tag_name') |
By.LINK_TEXT |
通过元素的链接文本定位 | element = driver.find_element(By.LINK_TEXT, 'link_text') |
By.PARTIAL_LINK_TEXT |
通过元素的部分链接文本定位 | element = driver.find_element(By.PARTIAL_LINK_TEXT, 'partial_text') |
By.CSS_SELECTOR |
通过 CSS 选择器定位元素 | element = driver.find_element(By.CSS_SELECTOR, 'css_selector') |
By.XPATH |
通过 XPath 表达式定位元素 | element = driver.find_element(By.XPATH, 'xpath_expression') |
示例代码
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keysdriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)# 打开 Google driver.get('http://www.google.com')# 通过 ID 定位 search_box_by_id = driver.find_element(By.ID, 'lst-ib')# 通过 Name 定位 search_box_by_name = driver.find_element(By.NAME, 'q')# 通过 Class Name 定位 search_box_by_class_name = driver.find_element(By.CLASS_NAME, 'gsfi')# 通过 Tag Name 定位 input_elements_by_tag_name = driver.find_elements(By.TAG_NAME, 'input')# 通过 Link Text 定位 link_by_text = driver.find_element(By.LINK_TEXT, 'About')# 通过 Partial Link Text 定位 link_by_partial_text = driver.find_element(By.PARTIAL_LINK_TEXT, 'Abo')# 通过 CSS Selector 定位 search_box_by_css_selector = driver.find_element(By.CSS_SELECTOR, 'input[name="q"]')# 通过 XPath 定位 search_box_by_xpath = driver.find_element(By.XPATH, '//input[@name="q"]')# 输入搜索关键字 search_box_by_name.send_keys('Selenium') search_box_by_name.send_keys(Keys.RETURN)# 关闭浏览器 driver.quit()
定位多个元素
有时需要定位页面上的多个元素,使用 find_elements 方法:
# 定位所有的输入框 input_boxes = driver.find_elements(By.TAG_NAME, 'input')for box in input_boxes:print(box.get_attribute('name'))
元素操作
常见操作
| 操作 | 描述 | 示例 |
|---|---|---|
click() |
点击元素 | element.click() |
send_keys(*value) |
向元素发送文本或键盘输入 | element.send_keys('text') |
clear() |
清除元素中的内容(通常用于输入框) | element.clear() |
submit() |
提交表单(通常用于表单中的输入框或按钮) | element.submit() |
get_attribute(name) |
获取元素的属性值 | value = element.get_attribute('attribute_name') |
get_property(name) |
获取元素的属性值(区别于 get_attribute) |
value = element.get_property('property_name') |
text |
获取元素的文本内容 | text = element.text |
is_displayed() |
判断元素是否可见 | is_visible = element.is_displayed() |
is_enabled() |
判断元素是否可用 | is_enabled = element.is_enabled() |
is_selected() |
判断元素是否被选中(通常用于复选框或单选按钮) | is_selected = element.is_selected() |
screenshot(filename) |
截取元素的截图并保存到文件 | element.screenshot('element.png') |
示例代码
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keysdriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)# 打开 Google driver.get('http://www.google.com')# 通过 Name 定位搜索框 search_box = driver.find_element(By.NAME, 'q')# 清除搜索框中的内容 search_box.clear()# 向搜索框发送文本 search_box.send_keys('Selenium')# 模拟回车键提交搜索 search_box.send_keys(Keys.RETURN)# 等待搜索结果加载并获取第一个结果 driver.implicitly_wait(10) first_result = driver.find_element(By.XPATH, '//h3')# 获取第一个结果的文本 result_text = first_result.text print(result_text)# 点击第一个结果 first_result.click()# 截取当前页面截图 driver.save_screenshot('search_result.png')# 关闭浏览器 driver.quit()
标签切换
在使用 Selenium 进行浏览器自动化时,有时需要在多个标签页(或窗口)之间切换。Selenium 提供了一些方法,可以帮助你处理这些操作。以下是关于如何在标签页之间切换的详细指南:
获取当前窗口句柄
每个窗口或标签页都有一个唯一的句柄,可以使用 driver.current_window_handle 获取当前窗口的句柄。
current_handle = driver.current_window_handle print(current_handle)
获取所有窗口句柄
可以使用 driver.window_handles 获取所有打开的窗口句柄。
handles = driver.window_handles print(handles)
切换到指定窗口
使用 driver.switch_to.window(handle) 方法可以切换到指定的窗口。
# 获取所有窗口句柄 handles = driver.window_handles# 切换到新窗口 driver.switch_to.window(handles[1])# 切换回原窗口 driver.switch_to.window(handles[0])
示例代码
以下是一个示例代码,展示如何打开一个新标签页并在标签页之间切换:
from selenium import webdriver from selenium.webdriver.common.by import By import timedriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)# 打开第一个网站 driver.get('http://www.google.com')# 获取当前窗口句柄 main_window = driver.current_window_handle# 打开一个新标签页 driver.execute_script("window.open('http://www.bing.com', '_blank');")# 等待新标签页加载 time.sleep(3)# 获取所有窗口句柄 handles = driver.window_handles# 切换到新标签页 driver.switch_to.window(handles[1])# 在新标签页中执行操作 search_box = driver.find_element(By.NAME, 'q') search_box.send_keys('Selenium') search_box.send_keys(u'\ue007') # 模拟回车键# 等待搜索结果加载 time.sleep(3)# 截取新标签页的截图 driver.save_screenshot('bing_search_result.png')# 切换回原窗口 driver.switch_to.window(main_window)# 截取原窗口的截图 driver.save_screenshot('google_home.png')# 关闭浏览器 driver.quit()
关闭指定窗口
可以使用 driver.close() 关闭当前窗口,并使用 driver.quit() 关闭所有窗口。
# 切换到新窗口并关闭它 driver.switch_to.window(handles[1]) driver.close()# 切换回原窗口 driver.switch_to.window(main_window)
高级用法:处理特定窗口
有时需要根据窗口的标题或 URL 来切换到特定的窗口,可以遍历所有窗口句柄并检查每个窗口的属性:
for handle in driver.window_handles:driver.switch_to.window(handle)if "Bing" in driver.title:break# 在特定窗口执行操作 driver.save_screenshot('specific_window.png')
窗口切换
在使用 Selenium 进行浏览器自动化时,窗口切换是一个常见且重要的操作。可以在多个窗口(或标签页)之间进行切换。
基本步骤
- 获取当前窗口的句柄:使用
driver.current_window_handle获取当前窗口的句柄。 - 获取所有窗口的句柄:使用
driver.window_handles获取所有打开的窗口句柄。 - 切换到指定窗口:使用
driver.switch_to.window(handle)方法切换到指定的窗口。 - 执行操作后切换回原窗口:可以在其他窗口执行操作后,切换回原来的窗口。
示例代码
以下是一个示例代码,展示如何在多个窗口之间进行切换并执行操作:
from selenium import webdriver from selenium.webdriver.common.by import By import timedriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)# 打开第一个网站 driver.get('http://www.google.com')# 获取当前窗口句柄 main_window = driver.current_window_handle print("Main window handle:", main_window)# 打开一个新标签页 driver.execute_script("window.open('http://www.bing.com', '_blank');")# 等待新标签页加载 time.sleep(3)# 获取所有窗口句柄 handles = driver.window_handles print("All window handles:", handles)# 切换到新标签页 for handle in handles:if handle != main_window:driver.switch_to.window(handle)break# 在新标签页中执行操作 search_box = driver.find_element(By.NAME, 'q') search_box.send_keys('Selenium') search_box.send_keys(u'\ue007') # 模拟回车键# 等待搜索结果加载 time.sleep(3)# 截取新标签页的截图 driver.save_screenshot('bing_search_result.png')# 切换回原窗口 driver.switch_to.window(main_window)# 截取原窗口的截图 driver.save_screenshot('google_home.png')# 关闭浏览器 driver.quit()
关闭指定窗口
可以使用 driver.close() 关闭当前窗口,而不是关闭所有窗口。
# 切换到新窗口并关闭它 driver.switch_to.window(handles[1]) driver.close()# 切换回原窗口 driver.switch_to.window(main_window)
根据窗口属性切换
有时需要根据窗口的标题或 URL 切换到特定的窗口,可以遍历所有窗口句柄并检查每个窗口的属性:
for handle in driver.window_handles:driver.switch_to.window(handle)if "Bing" in driver.title:break# 在特定窗口执行操作 driver.save_screenshot('specific_window.png')
使用 WebDriverWait 进行等待
在实际操作中,等待新窗口加载完成是很重要的。可以使用 WebDriverWait 进行显式等待:
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC# 等待新窗口打开 new_window = WebDriverWait(driver, 10).until(EC.new_window_is_opened(handles) )# 获取所有窗口句柄 handles = driver.window_handles# 切换到新窗口 driver.switch_to.window(handles[-1])
通过这些方法,你可以在 Selenium 中灵活地处理多个窗口或标签页的操作,确保自动化脚本能够正确地在不同窗口之间切换并执行相应的任务。
cookies操作
在 Selenium 中,可以使用浏览器的 cookies 来管理会话和用户数据。以下是有关如何添加、获取、删除和清除 cookies 的详细指南及示例代码:
常用操作
| 操作 | 描述 | 示例 |
|---|---|---|
add_cookie(cookie_dict) |
添加一个 cookie | driver.add_cookie({'name': 'key', 'value': 'value'}) |
get_cookie(name) |
获取一个 cookie | cookie = driver.get_cookie('key') |
get_cookies() |
获取所有 cookies | cookies = driver.get_cookies() |
delete_cookie(name) |
删除一个 cookie | driver.delete_cookie('key') |
delete_all_cookies() |
删除所有 cookies | driver.delete_all_cookies() |
示例代码
以下是一些操作 cookies 的示例代码:
from selenium import webdriverdriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)# 打开一个网站 driver.get('http://www.example.com')# 添加一个 cookie driver.add_cookie({'name': 'test_cookie', 'value': 'test_value'})# 获取并打印所有 cookies cookies = driver.get_cookies() print("All cookies:", cookies)# 获取并打印指定的 cookie cookie = driver.get_cookie('test_cookie') print("Specific cookie:", cookie)# 删除指定的 cookie driver.delete_cookie('test_cookie')# 获取并打印所有 cookies cookies = driver.get_cookies() print("Cookies after deletion:", cookies)# 删除所有 cookies driver.delete_all_cookies()# 获取并打印所有 cookies cookies = driver.get_cookies() print("Cookies after clearing:", cookies)# 关闭浏览器 driver.quit()
高级操作示例
有时可能需要在浏览器启动之前设置 cookies。以下是一个示例,展示如何在浏览器启动之前加载 cookies:
from selenium import webdriver# 设置启动选项 options = webdriver.ChromeOptions()# 启动 Chrome driver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path, options=options)# 打开一个网站以初始化会话 driver.get('http://www.example.com')# 添加 cookies cookies = [{'name': 'cookie1', 'value': 'value1'},{'name': 'cookie2', 'value': 'value2'} ]for cookie in cookies:driver.add_cookie(cookie)# 刷新页面以应用 cookies driver.refresh()# 获取并打印所有 cookies all_cookies = driver.get_cookies() print("Cookies after adding:", all_cookies)# 关闭浏览器 driver.quit()
通过这些方法,可以灵活地管理 Selenium 中的 cookies,确保自动化脚本能够正确处理会话和用户数据。
执行js
在 Selenium 中,你可以使用 execute_script 方法来执行 JavaScript 代码。这个方法非常强大,可以用来执行任意的 JavaScript 代码,并与网页元素进行交互。以下是一些常见的使用场景和示例代码:
基本用法
execute_script(script, *args) 方法执行 JavaScript 代码,其中 script 是要执行的 JavaScript 代码,*args 是传递给脚本的参数。
示例代码
以下是一些常见的使用示例:
1. 执行简单的 JavaScript 代码
from selenium import webdriverdriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)# 打开一个网站 driver.get('http://www.example.com')# 执行简单的 JavaScript 代码 driver.execute_script("alert('Hello, world!');")# 等待用户关闭 alert 弹窗 driver.switch_to.alert.accept()# 关闭浏览器 driver.quit()
2. 获取网页标题
title = driver.execute_script("return document.title;") print("Page title is:", title)
3. 滚动页面
# 滚动到页面底部 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")# 滚动到页面顶部 driver.execute_script("window.scrollTo(0, 0);")
4. 操作元素
# 查找元素并隐藏 element = driver.find_element(By.ID, 'element_id') driver.execute_script("arguments[0].style.display = 'none';", element)# 查找元素并修改其内容 element = driver.find_element(By.ID, 'element_id') driver.execute_script("arguments[0].innerText = 'New text';", element)
5. 获取元素属性
element = driver.find_element(By.ID, 'element_id') value = driver.execute_script("return arguments[0].getAttribute('value');", element) print("Element value is:", value)
6. 传递参数给 JavaScript
result = driver.execute_script("return arguments[0] + arguments[1];", 10, 20) print("Result is:", result)
综合示例
以下是一个综合示例,展示了如何使用 execute_script 方法来执行各种操作:
from selenium import webdriver from selenium.webdriver.common.by import By import timedriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)# 打开一个网站 driver.get('http://www.example.com')# 获取页面标题 title = driver.execute_script("return document.title;") print("Page title is:", title)# 滚动到页面底部 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(2)# 滚动到页面顶部 driver.execute_script("window.scrollTo(0, 0);") time.sleep(2)# 修改元素内容 element = driver.find_element(By.ID, 'element_id') driver.execute_script("arguments[0].innerText = 'New text';", element)# 隐藏元素 driver.execute_script("arguments[0].style.display = 'none';", element)# 显示一个 alert driver.execute_script("alert('Script executed successfully!');")# 等待用户关闭 alert 弹窗 driver.switch_to.alert.accept()# 关闭浏览器 driver.quit()
页面等待
在使用 Selenium 进行浏览器自动化时,页面等待是一个重要的概念。它可以确保网页加载完成或特定元素出现后再继续执行操作,从而避免脚本运行错误或失败。Selenium 提供了三种主要的等待机制:隐式等待、显式等待和自定义等待。
隐式等待
隐式等待会设置一个全局的等待时间。在查找元素时,如果元素立即不可用,Selenium 会在指定的时间内不断地尝试查找,直到超时。
from selenium import webdriverdriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)# 设置隐式等待时间为10秒 driver.implicitly_wait(10)driver.get('http://www.example.com')# 查找元素 element = driver.find_element(By.ID, 'element_id')# 关闭浏览器 driver.quit()
显式等待
显式等待会在指定条件满足时继续执行。如果条件在超时时间内没有满足,则会抛出超时异常。常用的显式等待条件包括元素可见、元素可点击、元素存在等。
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as ECdriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)driver.get('http://www.example.com')# 显式等待,等待指定元素出现,最长等待时间为10秒 element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'element_id')) )# 继续进行后续操作 element.click()# 关闭浏览器 driver.quit()
自定义等待
有时可能需要自定义等待条件,可以通过编写自定义的等待函数来实现。
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as ECdriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)driver.get('http://www.example.com')# 自定义等待函数,等待页面加载完成 def wait_for_page_load(driver):WebDriverWait(driver, 10).until(lambda d: d.execute_script('return document.readyState') == 'complete')wait_for_page_load(driver)# 查找元素 element = driver.find_element(By.ID, 'element_id')# 关闭浏览器 driver.quit()
综合示例
以下是一个综合示例,展示如何结合使用隐式等待和显式等待来确保页面加载和元素可用:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as ECdriver_path = 'path/to/chromedriver' driver = webdriver.Chrome(executable_path=driver_path)# 设置隐式等待时间为10秒 driver.implicitly_wait(10)driver.get('http://www.example.com')# 显式等待,等待指定元素可见 element = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, 'element_id')) )# 继续进行后续操作 element.click()# 自定义等待,等待页面加载完成 def wait_for_page_load(driver):WebDriverWait(driver, 10).until(lambda d: d.execute_script('return document.readyState') == 'complete')wait_for_page_load(driver)# 关闭浏览器 driver.quit()
通过这些等待机制,你可以确保在页面完全加载或元素可用之后再执行后续操作,从而提高自动化脚本的稳定性和可靠性。
配置对象
在 Selenium 中,可以通过配置浏览器选项对象来开启无界面模式和使用代理 IP。以下是详细的步骤和示例代码。
开启无界面模式
无界面模式(headless mode)允许你在没有图形界面的环境中运行浏览器。这在服务器环境中非常有用。
from selenium import webdriver from selenium.webdriver.chrome.options import Options# 实例化配置对象 chrome_options = Options()# 配置对象添加开启无界面模式的命令 chrome_options.add_argument("--headless")# 配置对象添加禁用GPU命令 chrome_options.add_argument("--disable-gpu")# 实例化带有配置对象的driver对象 driver = webdriver.Chrome(options=chrome_options)# 打开一个网站 driver.get('http://www.example.com')# 截取屏幕截图 driver.save_screenshot('example.png')# 关闭浏览器 driver.quit()
使用代理 IP
使用代理 IP 可以帮助绕过 IP 限制,或者模拟来自不同地区的访问。
from selenium import webdriver from selenium.webdriver.chrome.options import Options# 实例化配置对象 chrome_options = Options()# 配置对象添加使用代理的命令 proxy = "http://proxy_server:port" chrome_options.add_argument(f'--proxy-server={proxy}')# 实例化带有配置对象的driver对象 driver = webdriver.Chrome(options=chrome_options)# 打开一个网站 driver.get('http://www.example.com')# 打印页面标题 print(driver.title)# 关闭浏览器 driver.quit()