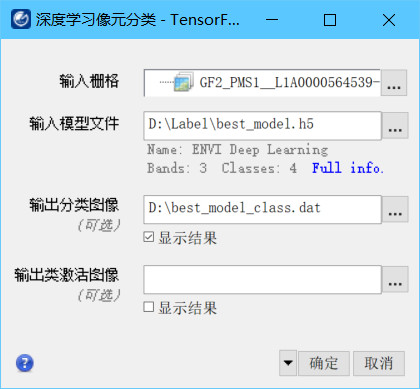
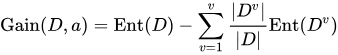DPP能够对目标检测proposal进行非统一处理,根据proposal选择不同复杂度的算子,加速整体推理过程。从实验结果来看,效果非常不错
来源:晓飞的算法工程笔记 公众号
论文: Should All Proposals be Treated Equally in Object Detection?

- 论文地址:https://arxiv.org/abs/2207.03520
- 论文代码:https://github.com/liyunsheng13/dpp
Introduction
在目标检测中,影响速度的核心主要是密集的proposal设计。所以,Faster RCNN → Cascade RCNN → DETR → Sparse RCNN的演变都是为了稀疏化proposal密度。虽然Sparse R-CNN成功地将proposal数量从几千个减少到几百个,但更复杂deation head导致减少proposal数量带来的整体计算收益有限。
复杂的deation head结构虽然能带来准确率的提升,但会抹杀轻量级设计带来的计算增益。对于仅有300个proposal的Sparse RCNN,deation head的计算量是主干网络MobileNetV2的4倍(25 GFLOPS 与 5.5 GFLOPS)。
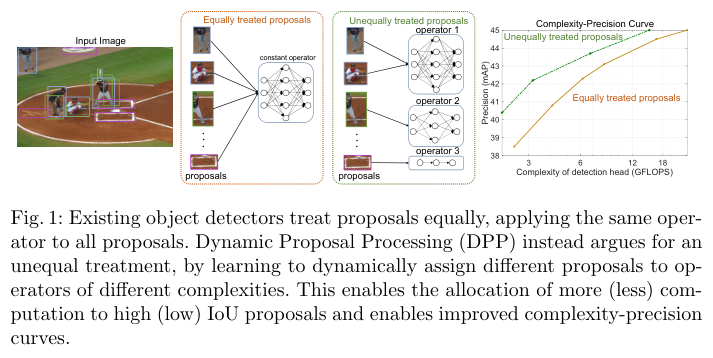
为此,作者研究是否有可能在降低deation head计算成本的同时保留精度增益和proposal稀疏性。现有检测算法采用相同复杂度的操作处理所有proposal,在高质量proposal上花费大量的计算是合适的,但将相同的资源分配给低质量的proposal则是一种浪费。由于每个proposal的IoU在训练期间是已知的,所以可以让检测器学习为不同的proposal分配不同的计算量。
由于在推理时没有IoU,网络需要学习如何根据proposal本身进行资源分配。为此,作者提出了dynamic proposal processing(DPP),将detection head使用的单一算子替换为一个包含不同复杂度算子的算子集,允许检测器在复杂度-精度之间进行权衡。算子的选择通过增加一个轻量级选择模型来实现,该模型在网络的每个阶段选择适用于每个proposal的最佳算子。
Complexity and Precision of Proposals
假设主干网络产生了一组proposal\(X = \{x_1, x_2, \cdots, x_N \}\),计算消耗主要来源于detection head而主干的计算消耗可忽略,并且将deation head的计算进一步分解为per-proposal的算子h(网络结构)以及对应的proposal间处理组件p(NMS操作或proposal之间的的自注意机制)。
-
Complexity of unequally treated proposals
在之前的检测器中,所有的proposal都由同一个算子h处理:
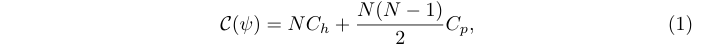
其中\(\psi = \{h, p\}\),\(C_h\) 和 \(C_p\) 分别是h和p的 per-proposal 复杂度。
-
Complexity of unequally treated proposals
与其将相同的算子h应用于所有proposal,作者建议使用包含J个具有不同复杂度算子的算子集\(\mathcal{G} = \{h_j\}^J_{j=1}\),由动态选择器s选择具体的算子分配给proposal \(x_i\):
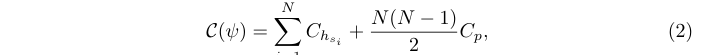
其中\(s_i = s(x_i)\), \(h_{s_i}\in \mathcal{G}\) 表示来自 \(\mathcal{G}\) 的算子,由选择器s分配给的proposal \(x_i\),\(\psi = \{\{h_{s_i}\}_i, s, p\}\),\(C_{h_{s_i}}\)为整个per-proposal操作的计算复杂度。为简单起见,p的复杂度仍然视为常数。
-
Precision over proposals
当deation head对proposal非统一处理时,给定复杂性约束C的最佳检测器精度可以通过优化算子对proposal的分配来提升:
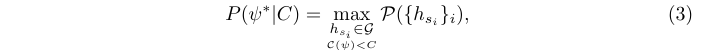
其中\(\mathcal{P}(\{h_{s_i}\}_i)\)是分配的特定运算符\(\{h_{s_i}\}_i\)的精度。随着C的变化,\(P(\psi^{∗}|C)\)构建了复杂度-精度(C-P)曲线,该曲线表示了可使用\(\mathcal{G}\)实现的目标检测器在成本和精度之间trade-off的最佳性能。
Dynamic Proposal Processing
基于上面的背景,作者提出了一个动态proposal处理(DPP)。假设detection head由多个阶段(\(\psi = \phi_1 \circ \cdots \circ \phi_K\))依次处理proposal,每个阶段\(\varphi_K\)由选择器s从\(\mathcal{G}\)中选择的运算符实现。为了最小化复杂性,选择器每次只应用于阶段子集\(k \in K \subset \{1,\cdots,K\}\),其余阶段使用上一次处理选择的运算符,即\(\phi_k = \phi_{k−1}, \forall k\notin K\)。
Operator Set
作者提出了由三个计算成本差异较大的算子组成的算子集合\(\mathcal{G} = \{g_0, g_1, g_2\}\):
- \(g_0\)是高复杂度的算子,由一个参数与proposal相关的动态卷积层(DyConv)和一个前馈网络(FFN)来实现,类似于Sparse R-CNN采用的动态Head结构。
- \(g_1\)是一个中等复杂度的算子,由FFN实现。
- \(g_2\)是一个由identity block构建的轻量级算子,只是简单地传递proposal而无需进一步提取特征。
Selector
在DPP中,通过控制操作符对proposal的分配,选择器是控制精度和复杂性之间权衡的关键组件。定义\(z^k_i\)是proposal \(x_i\)在阶段\(\phi_k\)的输入特征,选择器由3层MLP实现,输出与关联\(z^k_i\)的3维向量\(\epsilon^k_i \in [0, 1]^3\):
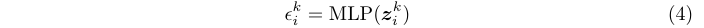
其中\(\epsilon^k_{i,j}\)是\(\epsilon^k_i\)中的选择变量,代表将操作\(g_j\)分配给proposal \(x_i\)的权重:
- 在训练期间,选择向量是包含三个变量one hot编码,将Gumble-Softmax函数作为MLP的激活函数,用于生成选择向量。
- 在推理中,选择向量包含三个连续值,选择值最大的变量对应的操作。
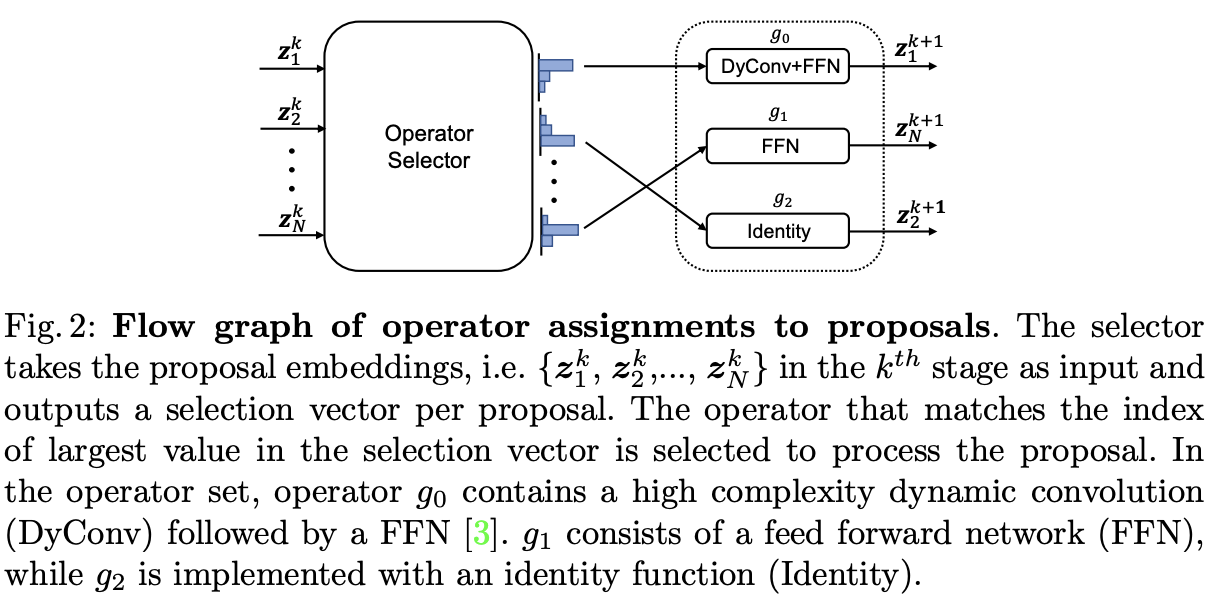
分配过程如图2所示,整体开销非常小(100个proposal仅需4e-3 GFLOPS),与detection head相比可以忽略不计。
从公式4可以看出,不同的proposal和阶段选择的算子都有变化,从而能够进行动态处理。
此外,虽然\(\mathcal{G}\)仅有三个候选项,但潜在的detection head网络结构有\(3^{|K|}\)种。最后,由于选择器是可训练的,所以整体结构可以端到端学习。
Loss Functions
为了确保在给定复杂度的情况下,DPP能为每个proposal选择最优的操作序列,作者增加了选择器损失,包含两个目标:
-
首先,应该将复杂的算子(\(g_0\)和\(g_1\))分配给高质量的proposal(高IoU):
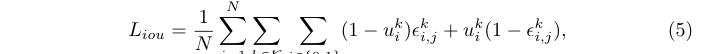
其中\(u_k\)是第i个proposal在第k阶段的 IoU。当IoU小于0.5时,\(L_{iou}\)推动选择器将\(\epsilon^k_{i,0}\)和\(\epsilon^k_{i,1}\)变为0,反之则变为1,鼓励在阶段 k 中使用更复杂的算子来获得高质量的proposal。此外,损失的大小是由IoU值决定的,为高IoU proposal选择简单结构或为低IoU proposal选择复杂结构均会产生大梯度值。 -
其次,选择器应该知道每张图像中的实例总数,并根据总数调整整体复杂度,在实例密集时选择更复杂的算子:
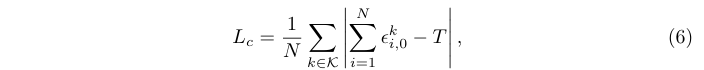
其中T是特定图像选择\(g_0\)算子目标次数,定义为\(T = \alpha M\),即图像中M个实例的倍数。此外,\(T\in [T_{min}, N ]\)需通过根据预先指定的下限\(T_{min}\)和由总体proposal数N给出的上限对\(\alpha M\)进行裁剪。下界防止对高复杂度算子进行过于稀疏的选择,然后\(\alpha\)则是根据实例数调整选择器。
最终的整体选择器损失为:
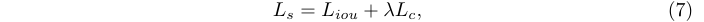
选择器损失是一种即插即用损失,可以应用于不同的对象检测器。在实现时,与应用DPP的原始检测器的所有损失相结合,包括交叉熵损失和边界框回归损失。
Experiments
DPP的主干网络使用MobileNet V2或ResNet-50,使用特征金字塔网络(FPN)生成多维特征,在其之上使用Sparse R-CNN的策略学习初始proposal。为简单起见,选择器仅应用于阶段 \(K = \{2, 4, 6\}\)。
对于损失函数,设置\(\lambda=1\),\(T_{min}=1\),\(\alpha=2\),\(N=100\)。
Proposal processing by DPP
-
Contribution of Each Operator
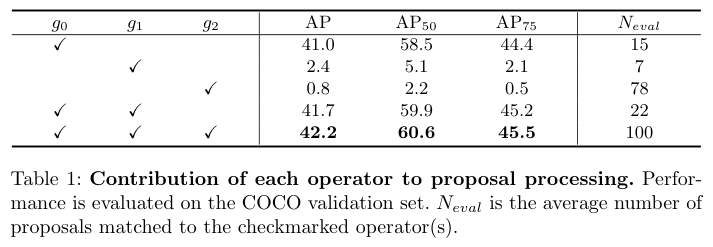
不同候选算子对性能的贡献。
-
Performance of Each Stage in DPP
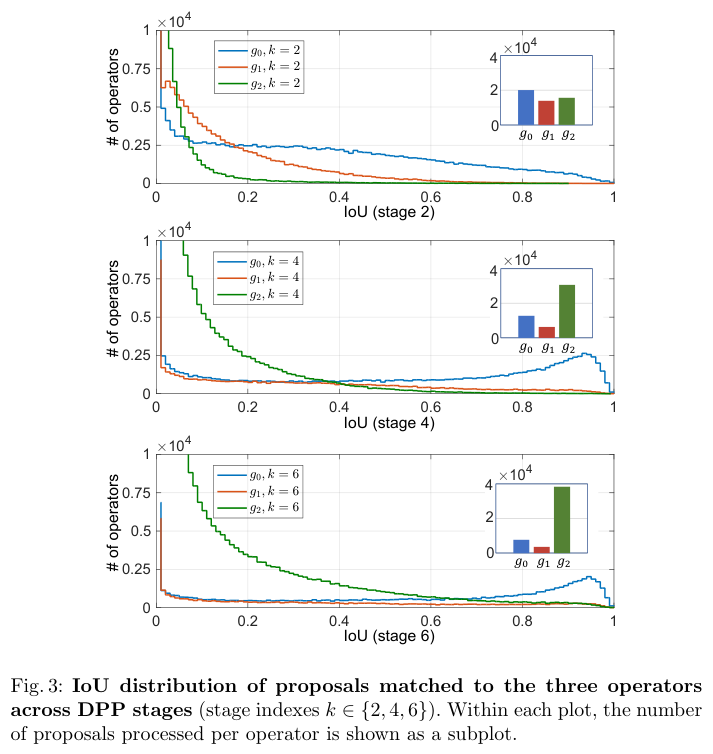
阶段1∼6的AP分别为\(\{15.6, 32.1, 39.3, 41.7, 42.0, 42.2\}\),精度在前 4 个阶段迅速增加,然后达到饱和。较后的阶段,复杂算子占比越少,这说明 DPP 如何在复杂性与精度之间取得相当成功。
-
Visualization

阶段4和阶段6中,\(g_0\)的预测结果。
Main Results
-
ResNet
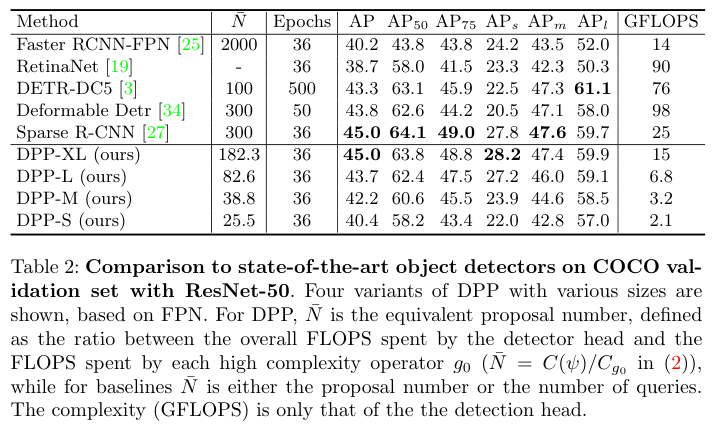
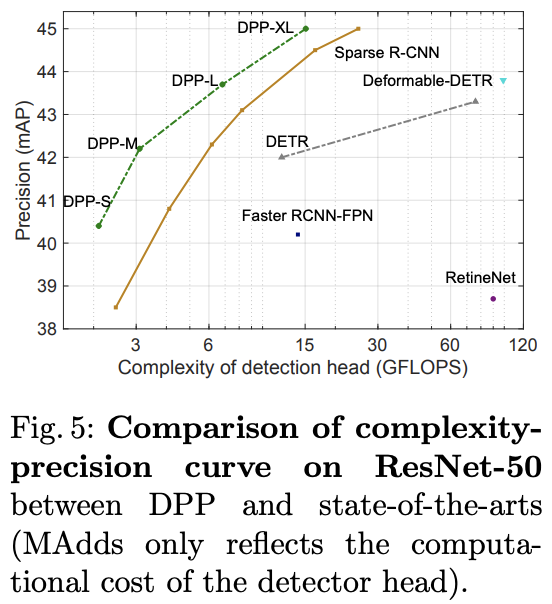
基于ResNet50与SOTA算法对比。

-
MobileNetV2
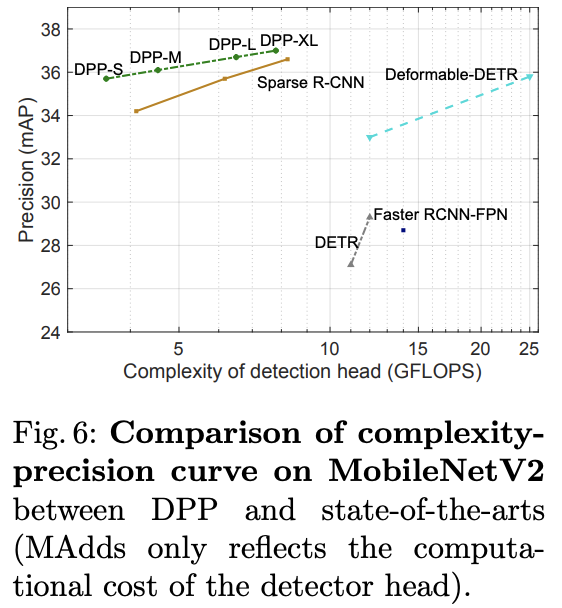
基于MobileNetV2与SOTA算法对比。
-
Inference speed
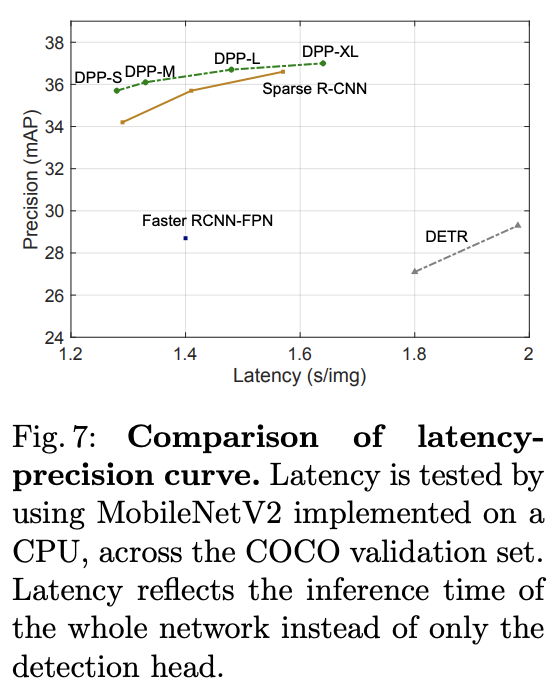
推理速度对比。
Ablation Study
-
Selection loss

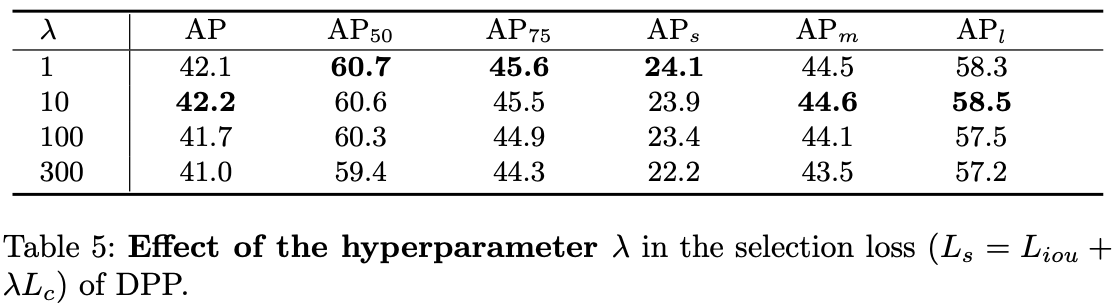
选择器损失的作用。
-
Target number of heavy operators
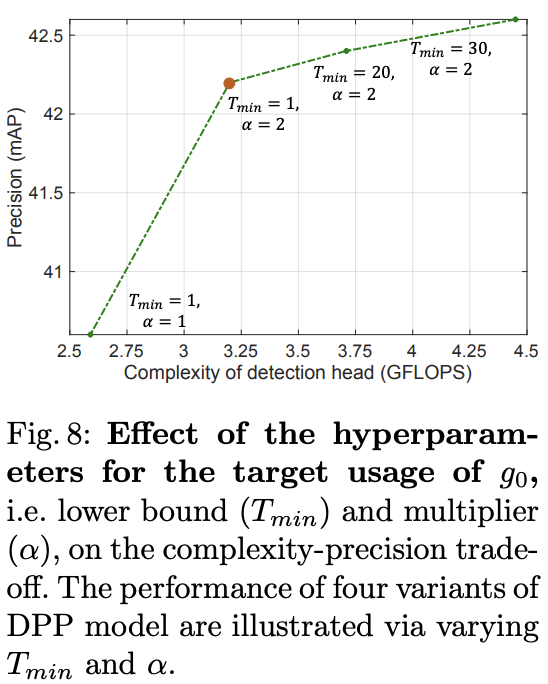
复杂算子预期数量的作用。
Conclusion
DPP能够对目标检测proposal进行非统一处理,根据proposal选择不同复杂度的算子,加速整体推理过程。从实验结果来看,效果非常不错。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】