PyTorch 深度学习:60分钟快速入门
原文:https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html
作者: Soumith Chintala
https://www.youtube.com/embed/u7x8RXwLKcA
什么是 PyTorch?
PyTorch 是基于以下两个目的而打造的python科学计算框架:
- 无缝替换NumPy,并且通过利用GPU的算力来实现神经网络的加速。
- 通过自动微分机制,来让神经网络的实现变得更加容易。
本次教程的目标:
- 深入了解PyTorch的张量单元以及如何使用Pytorch来搭建神经网络。
- 自己动手训练一个小型神经网络来实现图像的分类。
注意
确保已安装torch和torchvision包。

张量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2HAMaOOB-1687942170716)(img/0a7a97c39d6dfc0e08d2701eb7a49231.png)]](https://img-blog.csdnimg.cn/7045eb57857d4a049be3242aa0c912d9.png)
torch.autograd的简要介绍
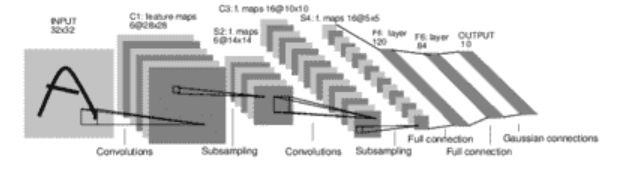
神经网络简介
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H3jt7p9i-1687942170719)(img/7a28f697e6bab9f3d9b1e8da4a5a5249.png)]](https://img-blog.csdnimg.cn/6b6de6921b7a40ceb4fc01daa278d844.png)
张量
原文: https://pytorch.org/tutorials/beginner/blitz/tensor_tutorial.html#sphx-glr-beginner-blitz-tensor-tutorial-py
张量如同数组和矩阵一样, 是一种特殊的数据结构。在PyTorch中, 神经网络的输入、输出以及网络的参数等数据, 都是使用张量来进行描述。
张量的使用和Numpy中的ndarrays很类似, 区别在于张量可以在GPU或其它专用硬件上运行, 这样可以得到更快的加速效果。如果你对ndarrays很熟悉的话, 张量的使用对你来说就很容易了。如果不太熟悉的话, 希望这篇有关张量API的快速入门教程能够帮到你。
import torch
import numpy as np
张量初始化
张量有很多种不同的初始化方法, 先来看看四个简单的例子:
1. 直接生成张量
由原始数据直接生成张量, 张量类型由原始数据类型决定。
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data)
2. 通过Numpy数组来生成张量
由已有的Numpy数组来生成张量(反过来也可以由张量来生成Numpy数组, 参考张量与Numpy之间的转换)。
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
3. 通过已有的张量来生成新的张量
新的张量将继承已有张量的数据属性(结构、类型), 也可以重新指定新的数据类型。
x_ones = torch.ones_like(x_data) # 保留 x_data 的属性
print(f"Ones Tensor: \n {x_ones} \n")x_rand = torch.rand_like(x_data, dtype=torch.float) # 重写 x_data 的数据类型int -> float
print(f"Random Tensor: \n {x_rand} \n")
显示:
Ones Tensor:tensor([[1, 1],[1, 1]])Random Tensor:tensor([[0.0381, 0.5780],[0.3963, 0.0840]])
4. 通过指定数据维度来生成张量
shape是元组类型, 用来描述张量的维数, 下面3个函数通过传入shape来指定生成张量的维数。
shape = (2,3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")
显示:
Random Tensor:tensor([[0.0266, 0.0553, 0.9843],[0.0398, 0.8964, 0.3457]])Ones Tensor:tensor([[1., 1., 1.],[1., 1., 1.]])Zeros Tensor:tensor([[0., 0., 0.],[0., 0., 0.]])
张量属性
从张量属性我们可以得到张量的维数、数据类型以及它们所存储的设备(CPU或GPU)。
来看一个简单的例子:
tensor = torch.rand(3,4)print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")
显示:
Shape of tensor: torch.Size([3, 4]) # 维数
Datatype of tensor: torch.float32 # 数据类型
Device tensor is stored on: cpu # 存储设备
张量运算
有超过100种张量相关的运算操作, 例如转置、索引、切片、数学运算、线性代数、随机采样等。更多的运算可以在这里查看。
所有这些运算都可以在GPU上运行(相对于CPU来说可以达到更高的运算速度)。如果你使用的是Google的Colab环境, 可以通过 Edit > Notebook Settings 来分配一个GPU使用。
# 判断当前环境GPU是否可用, 然后将tensor导入GPU内运行
if torch.cuda.is_available():tensor = tensor.to('cuda')
光说不练假把式, 接下来的例子一定要动手跑一跑。如果你对Numpy的运算非常熟悉的话, 那tensor的运算对你来说就是小菜一碟。
1. 张量的索引和切片
tensor = torch.ones(4, 4)
tensor[:,1] = 0 # 将第1列(从0开始)的数据全部赋值为0
print(tensor)
显示:
tensor([[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.]])
2. 张量的拼接
你可以通过torch.cat方法将一组张量按照指定的维度进行拼接, 也可以参考torch.stack方法。这个方法也可以实现拼接操作, 但和torch.cat稍微有点不同。
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)
显示:
tensor([[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.]])
3. 张量的乘积和矩阵乘法
# 逐个元素相乘结果
print(f"tensor.mul(tensor): \n {tensor.mul(tensor)} \n")
# 等价写法:
print(f"tensor * tensor: \n {tensor * tensor}")
显示:
tensor.mul(tensor):tensor([[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.]])tensor * tensor:tensor([[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.]])
下面写法表示张量与张量的矩阵乘法:
print(f"tensor.matmul(tensor.T): \n {tensor.matmul(tensor.T)} \n")
# 等价写法:
print(f"tensor @ tensor.T: \n {tensor @ tensor.T}")
显示:
tensor.matmul(tensor.T):tensor([[3., 3., 3., 3.],[3., 3., 3., 3.],[3., 3., 3., 3.],[3., 3., 3., 3.]])tensor @ tensor.T:tensor([[3., 3., 3., 3.],[3., 3., 3., 3.],[3., 3., 3., 3.],[3., 3., 3., 3.]])
4. 自动赋值运算
自动赋值运算通常在方法后有 _ 作为后缀, 例如: x.copy_(y), x.t_()操作会改变 x 的取值。
print(tensor, "\n")
tensor.add_(5)
print(tensor)
显示:
tensor([[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.]])tensor([[6., 5., 6., 6.],[6., 5., 6., 6.],[6., 5., 6., 6.],[6., 5., 6., 6.]])
注意:
自动赋值运算虽然可以节省内存, 但在求导时会因为丢失了中间过程而导致一些问题, 所以我们并不鼓励使用它。
Tensor与Numpy的转化
张量和Numpy array数组在CPU上可以共用一块内存区域, 改变其中一个另一个也会随之改变。
1. 由张量变换为Numpy array数组
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy()
print(f"n: {n}")
显示:
t: tensor([1., 1., 1., 1., 1.])
n: [1. 1. 1. 1. 1.]
修改张量的值,则Numpy array数组值也会随之改变。
t.add_(1)
print(f"t: {t}")
print(f"n: {n}")
显示:
t: tensor([2., 2., 2., 2., 2.])
n: [2. 2. 2. 2. 2.]
2. 由Numpy array数组转为张量
n = np.ones(5)
t = torch.from_numpy(n)
修改Numpy array数组的值,则张量值也会随之改变。
np.add(n, 1, out=n)
print(f"t: {t}")
print(f"n: {n}")
显示:
t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
n: [2. 2. 2. 2. 2.]
脚本的总运行时间:(0 分钟 0.045 秒)
下载 Python 源码:tensor_tutorial.py
下载 Jupyter 笔记本:tensor_tutorial.ipynb