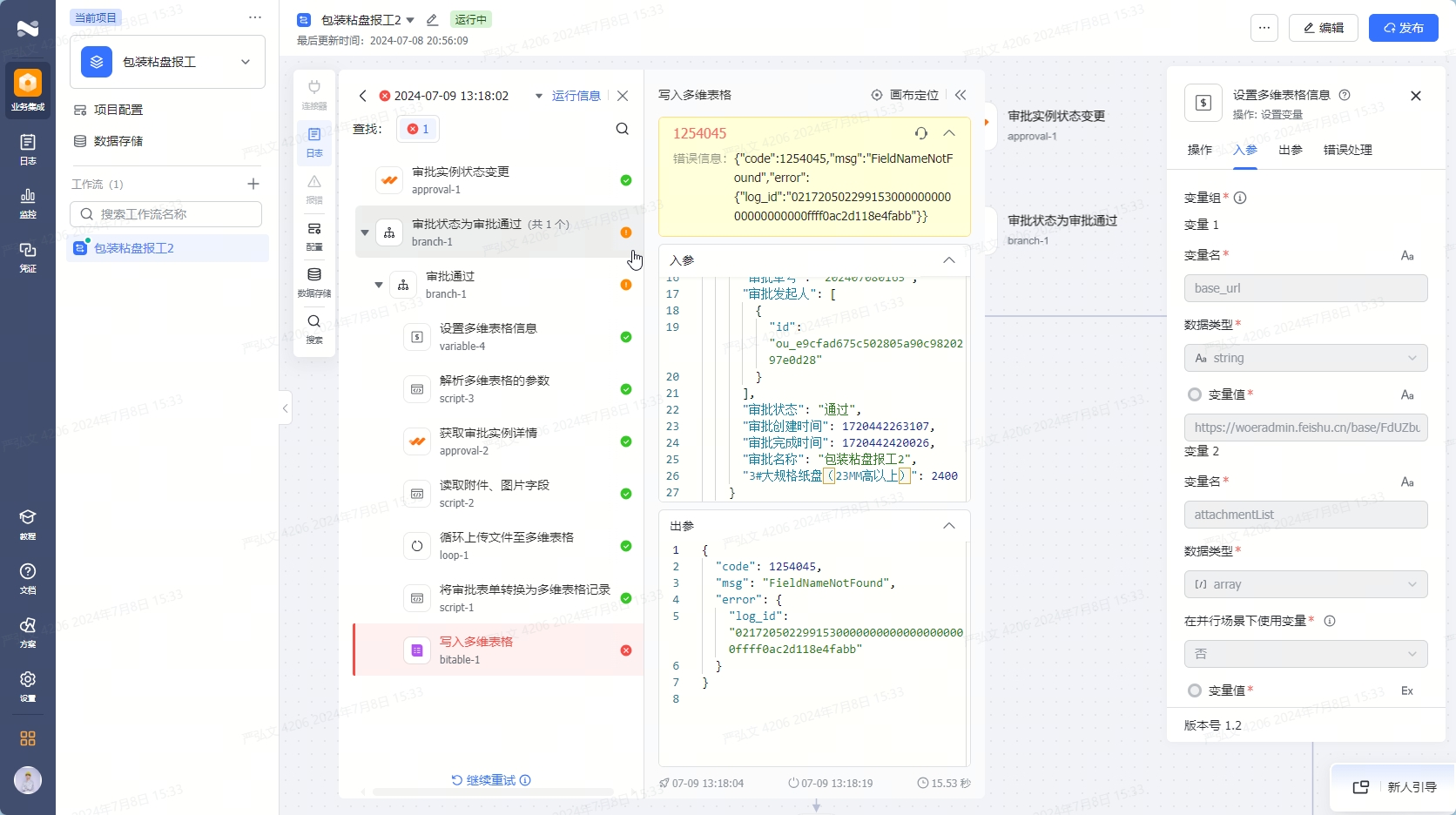
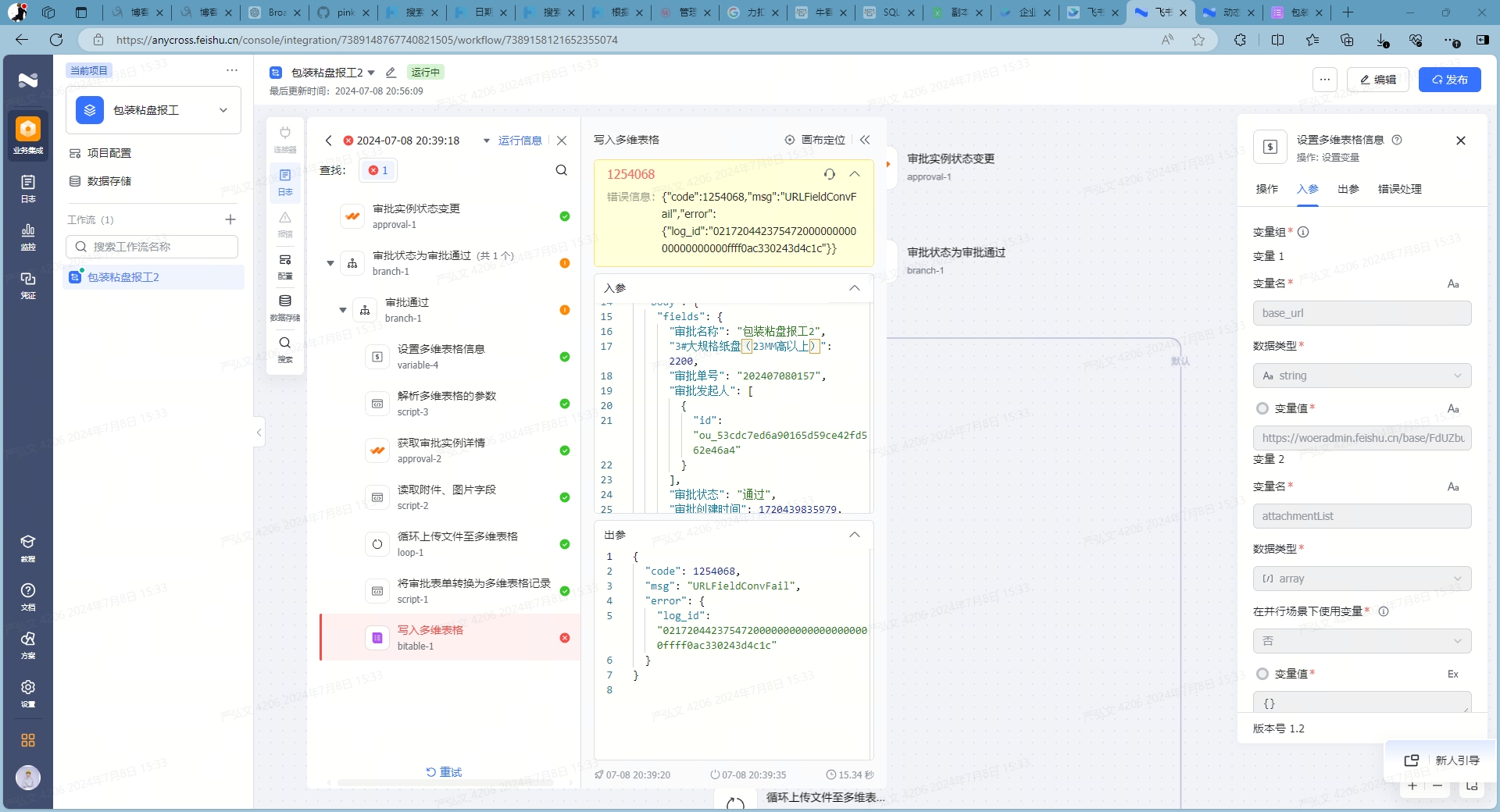
目的
本次演练旨在测试 Kubernetes 的 etcd 高可用性,检验是否能够在其中一个 etcd 节点发生故障的情况下,其他 etcd 节点能够接管其工作,确保集群仍能正常运行。
集群架构
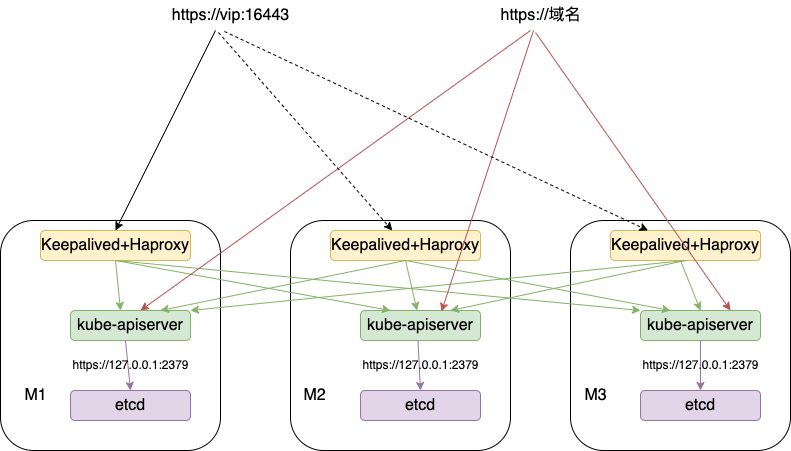
演练场景
在一个三节点的 Kubernetes 集群中,我们将模拟其中一个 etcd 节点的故障,观察剩余的 etcd 节点是否能够正常运行。
演练过程
-
确认集群当前健康状态
kubectl get componentstatuses # 确认所有组件状态均为正常 kubectl -n kube-system get endpoints | grep etcd # 确认 etcd Endpoints 列表 kubectl -n kube-system get pods | grep etcd # 确认 etcd Pod 的数量 # 确认etcd 集群状态 ETCD_CA_CERT="/etc/kubernetes/pki/etcd/ca.crt" ETCD_CERT="/etc/kubernetes/pki/etcd/server.crt" ETCD_KEY="/etc/kubernetes/pki/etcd/server.key" ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=https://127.0.0.1:2379 \--cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" member list ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=${HOST1},${HOST2},${HOST3} \--cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" endpoint health -
停止 M3 节点 etcd 服务
mkdir -p /home/clay/etcdbak mv /etc/kubernetes/manifests/etcd.yaml /home/clay/etcdbak/ -
确认剩余节点是否能正常提供服务
# 重复执行步骤一命令在其他 etcd 节点上执行 kubectl create 命令测试 Kubernetes 集群是否能够正常运行,例如 kubectl create deployment nginx
持续通过 vip + 域名两种方式,调用 apiserver 服务,统计影响时长
-
启动 M3 节点 etcd 服务
mv /home/clay/etcdbak/etcd.yaml /etc/kubernetes/manifests/ -
确认集群当前健康状态
# 重复执行步骤一命令
🐶 因为现有架构为 apiserver 调用本地 127.0.0.1 的 etcd 服务,所以当 M3 节点 etcd 服务停止后, M3 节点的 apiserver 也不能正常提供服务
所以 haproxy 和 nginx 都必要配置正确的健康检查策略,可以自动剔除故障节点
演练结果
在停止一个 etcd 节点的 etcd 进程后,其他 etcd 节点能够顺利接管其工作,确保 Kubernetes 集群的正常运行。当第一个 etcd 节点重新加入集群后,所有 etcd 节点均能够恢复到健康状态,集群仍然能够正常工作。演练结果证明 Kubernetes 的 etcd 子系统具有较高的可用性,可以有效地应对节点故障的情况。
总结
通过本次演练,我们验证了 Kubernetes 的 etcd 子系统的高可用性,并了解了在一个节点发生故障的情况下,其他节点是如何接管其工作的。在实际生产环境中,我们建议对 Kubernetes 集群的 etcd 子系统进行高可用性测试,以确保集群能够稳定、可靠地运行。此外,我们还应定期检查 Kubernetes 集群的各个组件状态,确保其正常运行,避免出现故障导致的服务中断。