本文目的在于训练一个模型,使其能对手写的数字图片进行分类识别,并不断优化使其准确度尽可能地提高
一、数据预处理
(1)运行时所需库
import numpy as np
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
import matplotlib.pyplot as plt
import os.path
(2)选择合适的设备进行训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
(3) 构建数据集
# 将图片转化为张量以及归一化处理
Trans = torchvision.transforms.Compose( [torchvision.transforms.ToTensor(), torchvision.transforms.Normalize(mean=[0.5], std=[0.5])]) # 下载MNIST对应的训练和测试数据集
training_data = datasets.MNIST( root="data", train=True, download=True, transform=Trans,
) test_data = datasets.MNIST( root="data", train=False, download=True, transform=Trans,
) # 设定batch大小
batch_size = 64 # 构建用于训练和测试的数据集的dataloader
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size) for X, y in test_dataloader: print("Shape of X [N,C,H,W]:", X.shape) print("Shape of y: ", y.shape, y.dtype) break
二、训练和测试
(1)模型网络构建
三层的全连接层网络
class NeuralNetwork(nn.Module): def __init__(self): super(NeuralNetwork, self).__init__() self.flatten = nn.Flatten() self.linear_relu_stack = nn.Sequential( nn.Linear(28 * 28, 512), nn.ReLU(), nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 10), nn.ReLU() ) def forward(self, x): x = self.flatten(x) logits = self.linear_relu_stack(x) return logits model = NeuralNetwork().to(device)
if os.path.exists(filename): model.load_state_dict(torch.load(filename))
print(model)
(2)定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
(3)定义训练函数
def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) for batch, (X, y) in enumerate(dataloader): X, y = X.to(device), y.to(device) pred = model(X) loss = loss_fn(pred, y) optimizer.zero_grad() loss.backward() optimizer.step() if batch % 100 == 0: loss, current = loss.item(), batch * len(X) print(f"loss:{loss:>7f} [{current:>5d}/{size:>5d}]")
(4)定义测试函数
def test(dataloader, model): size = len(dataloader.dataset) model.eval() test_loss, correct = 0, 0 global ok with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() if ok: ok = False L = X.cpu() R = y.cpu() M = pred.argmax(1).cpu() plot_images_labels_prediction(np.array(L), np.array(R), np.array(M), 10, 25) test_loss /= size correct /= size history['Test Loss'].append(test_loss) history['Test Accuracy'].append(correct * 100) print(f"Test Error: \nAccuracy:{(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
三、主函数和权值保存
(1)主函数
if __name__ == '__main__': epochs = 10 for t in range(epochs): print(f"Epoch {t + 1}\n------------------") train(train_dataloader, model, loss_fn, optimizer) test(test_dataloader, model) print("Done!")
(2)保存和恢复网络权值
model = NeuralNetwork().to(device)
if os.path.exists(filename): model.load_state_dict(torch.load(filename))
print(model)torch.save(model.state_dict(), filename)
print("Save PyTorch Model State to " + filename)
四、可视化
(1)显示图片以及预测结果
def plot_images_labels_prediction(images, labels, prediction, index, num=10): fig = plt.gcf() # 获取当前图表 fig.set_size_inches(10, 12) # 显示成英寸(1英寸等于2.54cm) if num > 25: num = 25 # 最多显示25幅图片 for i in range(0, num): ax = plt.subplot(5, 5, i + 1) # 画多个子图(5*5) ax.imshow(np.reshape(images[index], (28, 28)), cmap='binary') # 显示第index张图像 title = "label=" + str(labels[index]) # 构建图片上要显示的title if len(prediction) > 0: title += ", predict=" + str(prediction[index]) ax.set_title(title, fontsize=10) ax.set_xticks([]) # 不显示坐标轴 ax.set_yticks([]) index += 1 plt.show()if ok: ok = False L = X.cpu() R = y.cpu() M = pred.argmax(1).cpu() plot_images_labels_prediction(np.array(L), np.array(R), np.array(M), 10, 25)
(2)Acc和loss的变化曲线
history = {'Test Loss': [], 'Test Accuracy': []}plt.plot(history['Test Loss'], label='Test Loss')
plt.legend(loc='best')
plt.grid(True)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show() plt.plot(history['Test Accuracy'], color='red', label='Test Accuracy')
plt.legend(loc='best')
plt.grid(True)
plt.xlabel('Epoch')
plt.ylabel('Accuracy%')
plt.show()
五、实验结果展示
当学习率选择0.1时,10次训练后手写图片预测情况:

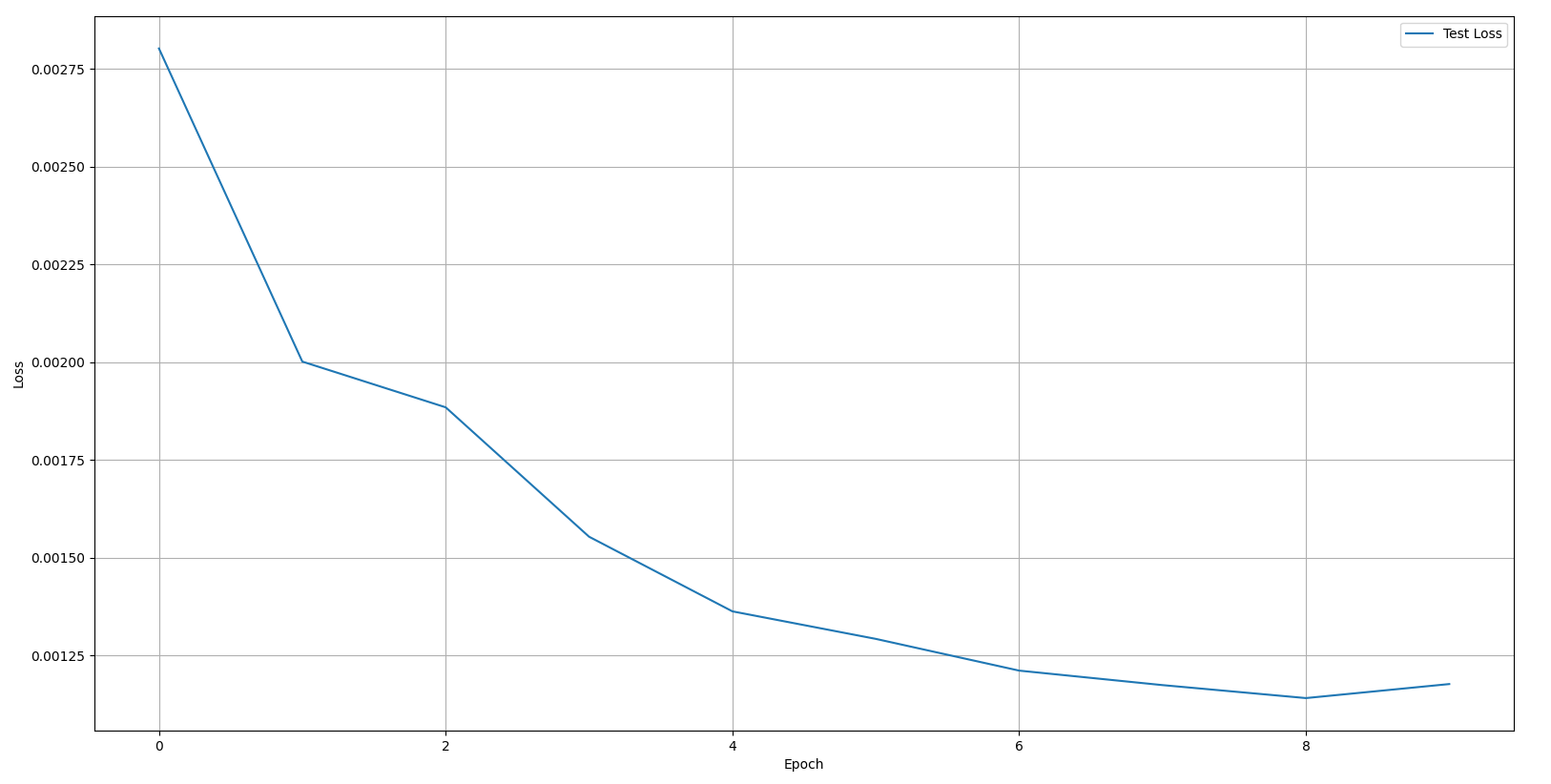
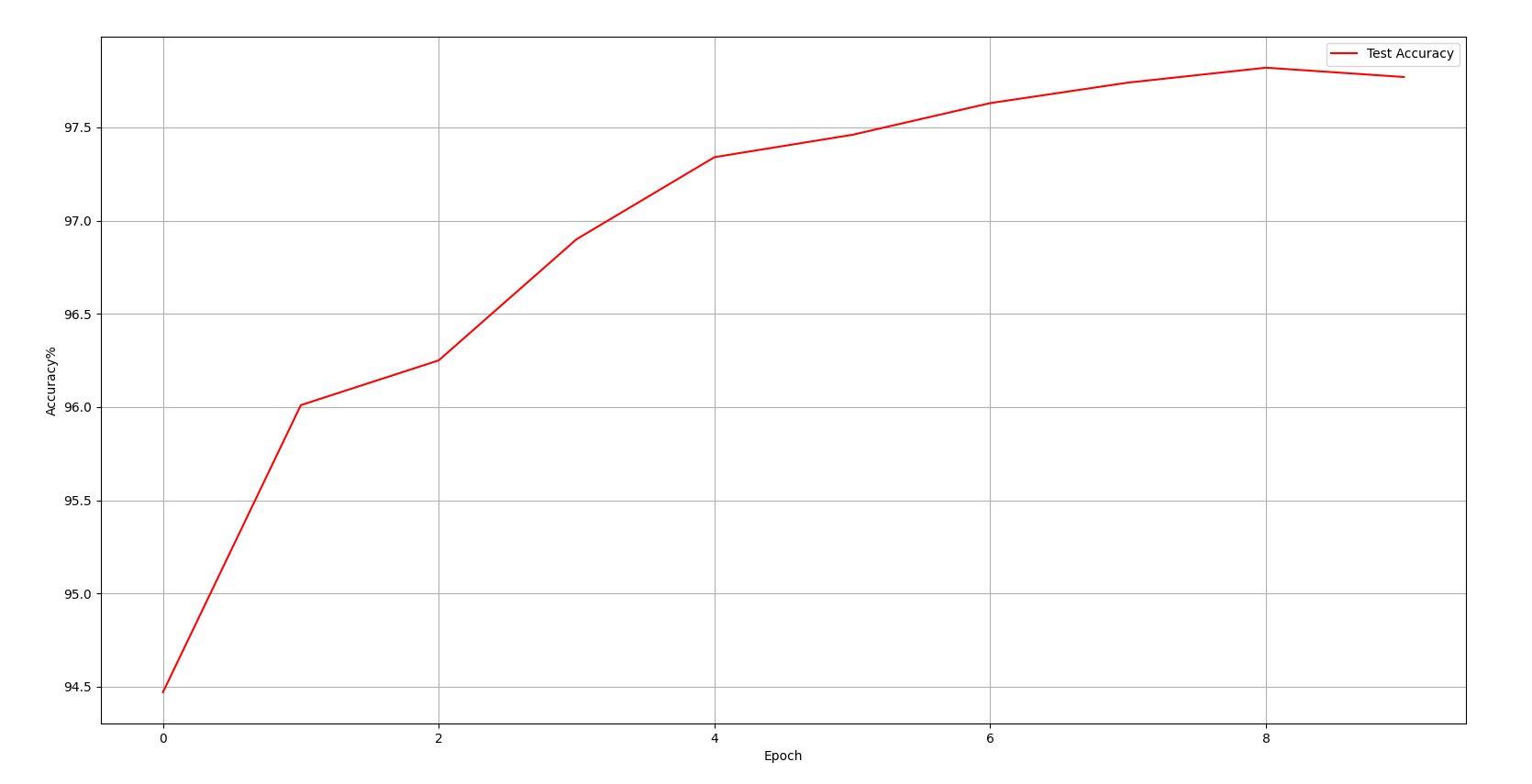
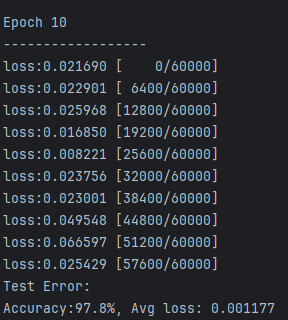
六、优化与参数调整
(1)调整优化器的学习率
在 learningrate = 1e-3 时训练结果:
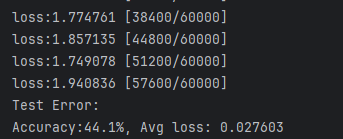
在多次尝试的经验选择下
调整为 learningrate = 0.1 后的效果如上图实验结果所示
(2)保存模型,同时将学习率逐步减小以趋近极值点
考虑到局部最优解的原理,我们将 lr = 0.1 的模型保存后(目的为了加快求得解),之后加载模型,采用 lr = 1e-3 去多轮训练,最终得到结果:
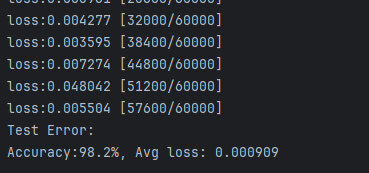
但是可以见得由于 lr = 0.1 下解已然十分逼近最优,在此优化下提升已经不多。
Code:
import numpy as np
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
import matplotlib.pyplot as plt
import os.path device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 将图片转化为张量以及归一化处理
Trans = torchvision.transforms.Compose( [torchvision.transforms.ToTensor(), torchvision.transforms.Normalize(mean=[0.5], std=[0.5])]) # 下载MNIST对应的训练和测试数据集
training_data = datasets.MNIST( root="data", train=True, download=True, transform=Trans,
) test_data = datasets.MNIST( root="data", train=False, download=True, transform=Trans,
) # 设定batch大小
batch_size = 64 # 构建用于训练和测试的数据集的dataloader
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size) for X, y in test_dataloader: print("Shape of X [N,C,H,W]:", X.shape) print("Shape of y: ", y.shape, y.dtype) break class NeuralNetwork(nn.Module): def __init__(self): super(NeuralNetwork, self).__init__() self.flatten = nn.Flatten() self.linear_relu_stack = nn.Sequential( nn.Linear(28 * 28, 512), nn.ReLU(), nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 10), nn.ReLU() ) def forward(self, x): x = self.flatten(x) logits = self.linear_relu_stack(x) return logits filename = "model.pth" model = NeuralNetwork().to(device)
if os.path.exists(filename): model.load_state_dict(torch.load(filename))
print(model) loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) history = {'Test Loss': [], 'Test Accuracy': []} def plot_images_labels_prediction(images, labels, prediction, index, num=10): fig = plt.gcf() # 获取当前图表 fig.set_size_inches(10, 12) # 显示成英寸(1英寸等于2.54cm) if num > 25: num = 25 # 最多显示25幅图片 for i in range(0, num): ax = plt.subplot(5, 5, i + 1) # 画多个子图(5*5) ax.imshow(np.reshape(images[index], (28, 28)), cmap='binary') # 显示第index张图像 title = "label=" + str(labels[index]) # 构建图片上要显示的title if len(prediction) > 0: title += ", predict=" + str(prediction[index]) ax.set_title(title, fontsize=10) ax.set_xticks([]) # 不显示坐标轴 ax.set_yticks([]) index += 1 plt.show() def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) for batch, (X, y) in enumerate(dataloader): X, y = X.to(device), y.to(device) pred = model(X) loss = loss_fn(pred, y) optimizer.zero_grad() loss.backward() optimizer.step() if batch % 100 == 0: loss, current = loss.item(), batch * len(X) print(f"loss:{loss:>7f} [{current:>5d}/{size:>5d}]") ok = False def test(dataloader, model): size = len(dataloader.dataset) model.eval() test_loss, correct = 0, 0 global ok with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() if ok: ok = False L = X.cpu() R = y.cpu() M = pred.argmax(1).cpu() plot_images_labels_prediction(np.array(L), np.array(R), np.array(M), 10, 25) test_loss /= size correct /= size history['Test Loss'].append(test_loss) history['Test Accuracy'].append(correct * 100) print(f"Test Error: \nAccuracy:{(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") if __name__ == '__main__': epochs = 10 for t in range(epochs): if t == epochs - 1: ok = True print(f"Epoch {t + 1}\n------------------") train(train_dataloader, model, loss_fn, optimizer) test(test_dataloader, model) print("Done!") plt.plot(history['Test Loss'], label='Test Loss') plt.legend(loc='best') plt.grid(True) plt.xlabel('Epoch') plt.ylabel('Loss') plt.show() plt.plot(history['Test Accuracy'], color='red', label='Test Accuracy') plt.legend(loc='best') plt.grid(True) plt.xlabel('Epoch') plt.ylabel('Accuracy%') plt.show() torch.save(model.state_dict(), filename)
print("Save PyTorch Model State to " + filename)