如何使用来自不同分布的数据,进行训练和测试
深度学习算法对训练数据的胃口很大,当收集到足够多带标签的数据构成训练集时,算法效果最好,这导致很多团队用尽一切办法收集数据,然后把它们堆到训练集里,让训练的数据量更大,即使有些数据,甚至是大部分数据都来自和开发集、测试集不同的分布。在深度学习时代,越来越多的团队都用来自和开发集、测试集分布不同的数据来训练,这里有一些微妙的地方,一些最佳做法来处理训练集和测试集存在差异的情况。

假设在开发一个手机应用,用户会上传他们用手机拍摄的照片,想识别用户从应用中上传的图片是不是猫。现在有两个数据来源,一个是真正关心的数据分布,来自应用上传的数据,比如右边的应用,这些照片一般更业余,取景不太好,有些甚至很模糊,因为它们都是业余用户拍的。另一个数据来源就是可以用爬虫程序挖掘网页直接下载,就这个样本而言,可以下载很多取景专业、高分辨率、拍摄专业的猫图片。如果应用用户数还不多,也许只收集到10,000张用户上传的照片,但通过爬虫挖掘网页,可以下载到海量猫图,也许从互联网上下载了超过20万张猫图。而真正关心的算法表现是最终系统处理来自应用程序的这个图片分布时效果好不好,因为最后用户会上传类似右边这些图片,分类器必须在这个任务中表现良好。现在就陷入困境了,因为有一个相对小的数据集,只有10,000个样本来自那个分布,而还有一个大得多的数据集来自另一个分布,图片的外观和真正想要处理的并不一样。但又不想直接用这10,000张图片,因为这样训练集就太小了,使用这20万张图片似乎有帮助。但是,困境在于,这20万张图片并不完全来自想要的分布,那么可以怎么做呢?
这里有一种选择,可以做的一件事是将两组数据合并在一起,这样就有21万张照片,可以把这21万张照片随机分配到训练、开发和测试集中。为了说明观点,假设已经确定开发集和测试集各包含2500个样本,所以训练集有205000个样本。现在这么设立数据集有一些好处,也有坏处。好处在于,训练集、开发集和测试集都来自同一分布,这样更好管理。但坏处在于,这坏处还不小,就是如果观察开发集,看看这2500个样本其中很多图片都来自网页下载的图片,那并不是真正关心的数据分布,真正要处理的是来自手机的图片。

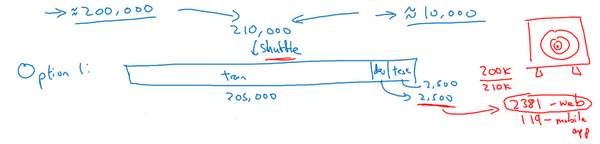
所以结果数据总量,这200,000个样本,就用\(200k\)缩写表示,把那些是从网页下载的数据总量写成\(210k\),所以对于这2500个样本,数学期望值是:\(2500\times \frac{200k}{210k} =2381\),有2381张图来自网页下载,这是期望值,确切数目会变化,取决于具体的随机分配操作。但平均而言,只有119张图来自手机上传。要记住,设立开发集的目的是告诉团队去瞄准的目标,而瞄准目标的方式,大部分精力都用在优化来自网页下载的图片,这其实不是想要的。所以真的不建议使用第一个选项,因为这样设立开发集就是告诉团队,针对不同于实际关心的数据分布去优化,所以不要这么做。
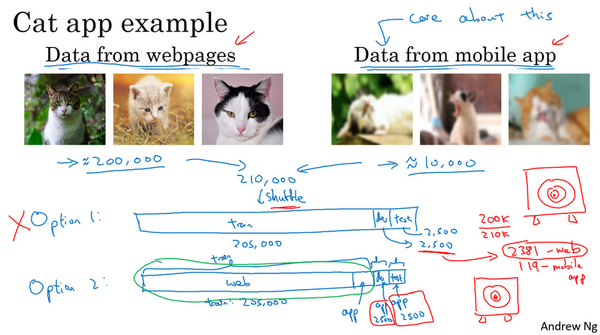
建议走另外一条路,就是这样,训练集,比如说还是205,000张图片,训练集是来自网页下载的200,000张图片,然后如果需要的话,再加上5000张来自手机上传的图片。然后对于开发集和测试集,这数据集的大小是按比例画的,开发集和测试集都是手机图。而训练集包含了来自网页的20万张图片,还有5000张来自应用的图片,开发集就是2500张来自应用的图片,测试集也是2500张来自应用的图片。这样将数据分成训练集、开发集和测试集的好处在于,现在瞄准的目标就是想要处理的目标,告诉团队,开发集包含的数据全部来自手机上传,这是真正关心的图片分布。试试搭建一个学习系统,让系统在处理手机上传图片分布时效果良好。缺点在于,当然了,现在训练集分布和开发集、测试集分布并不一样。但事实证明,这样把数据分成训练、开发和测试集,在长期能给带来更好的系统性能。以后会讨论一些特殊的技巧,可以处理训练集的分布和开发集和测试集分布不一样的情况。

来看另一个样本,假设正在开发一个全新的产品,一个语音激活汽车后视镜,这在中国是个真实存在的产品,它正在进入其他国家。但这就是造一个后视镜,把这个小东西换掉,现在就可以和后视镜对话了,然后只需要说:“亲爱的后视镜,请帮找找到最近的加油站的导航方向”,然后后视镜就会处理这个请求。所以这实际上是一个真正的产品,假设现在要为自己的国家研制这个产品,那么怎么收集数据去训练这个产品语言识别模块呢?
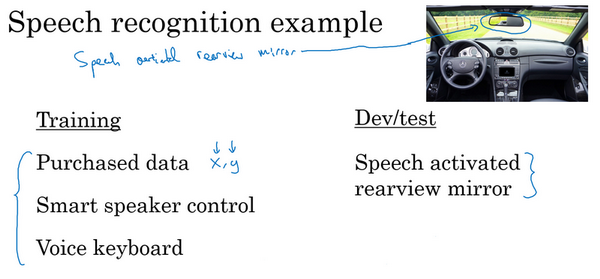
嗯,也许已经在语音识别领域上工作了很久,所以有很多来自其他语音识别应用的数据,它们并不是来自语音激活后视镜的数据。现在讲讲如何分配训练集、开发集和测试集。对于训练集,可以将拥有的所有语音数据,从其他语音识别问题收集来的数据,比如这些年从各种语音识别数据供应商买来的数据,今天可以直接买到成\(x\),\(y\)对的数据,其中\(x\)是音频剪辑,\(y\)是听写记录。或者也许研究过智能音箱,语音激活音箱,所以有一些数据,也许做过语音激活键盘的开发之类的。
举例来说,也许从这些来源收集了500,000段录音,对于开发集和测试集也许数据集小得多,比如实际上来自语音激活后视镜的数据。因为用户要查询导航信息或试图找到通往各个地方的路线,这个数据集可能会有很多街道地址,对吧?“请帮导航到这个街道地址”,或者说:“请帮助导航到这个加油站”,所以这个数据的分布和左边大不一样,但这真的是关心的数据,因为这些数据是产品必须处理好的,所以就应该把它设成开发和测试集。

在这个样本中,应该这样设立训练集,左边有500,000段语音,然后开发集和测试集,把它简写成\(D\)和\(T\),可能每个集包含10,000段语音,是从实际的语音激活后视镜收集的。或者换种方式,如果觉得不需要将20,000段来自语音激活后视镜的录音全部放进开发和测试集,也许可以拿一半,把它放在训练集里,那么训练集可能是51万段语音,包括来自那里的50万段语音,还有来自后视镜的1万段语音,然后开发集和测试集也许各自有5000段语音。所以有2万段语音,也许1万段语音放入了训练集,5000放入开发集,5000放入测试集。所以这是另一种将数据分成训练、开发和测试的方式。这样训练集大得多,大概有50万段语音,比只用语音激活后视镜数据作为训练集要大得多。
见到几组样本,让训练集数据来自和开发集、测试集不同的分布,这样就可以有更多的训练数据。在这些样本中,这将改善学习算法。