(1)HashMap底层实现原理
在 JDK 1.7 版本之前, HashMap 数据结构是数组和链表,HashMap 通过哈希算法将元素的键 (Key) 映射到数组中的槽位 (Bucket)。如果多个键映射到同一个槽位,它们会以链表的形式存储在同一个槽位上,因为链表的查询时间是 O(n),所以冲突很严重,一个索引上的链表非常长,效率就很低了。
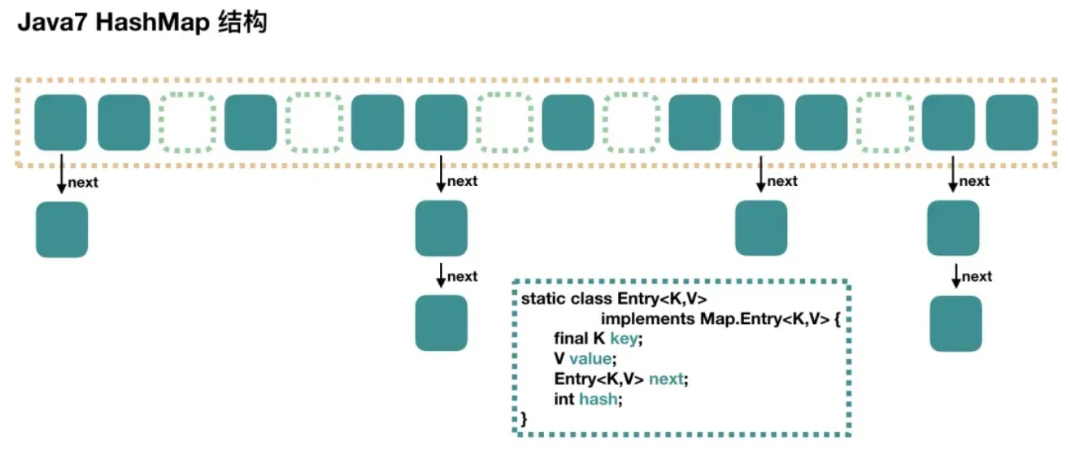
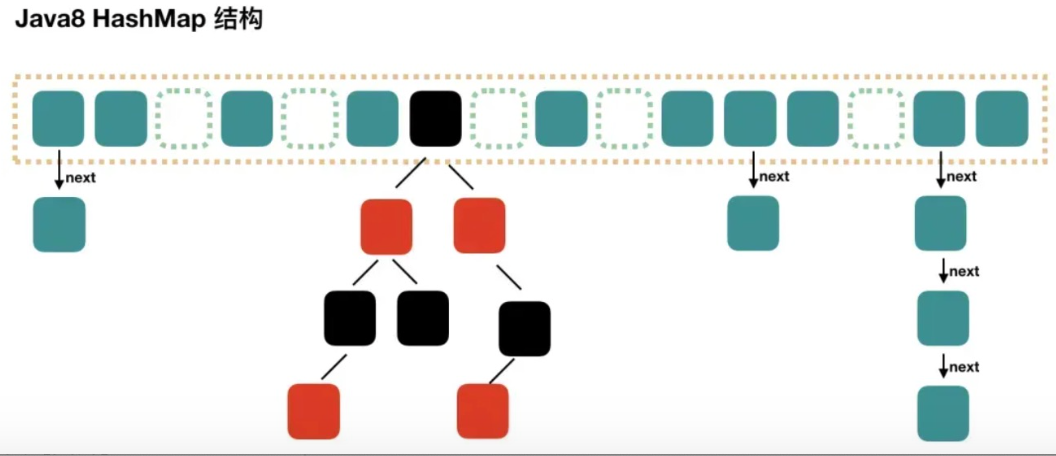
所以在 JDK 1.8 版本的时候做了优化,当一个链表的长度超过8的时候就转换数据结构,不再使用链表存储,而是使用红黑树,查找时使用红黑树,时间复杂度 O(logn),可以提高查询性能,但是在数量较少时,即数量小于6时,会将红黑树转换回链表。
(2)ConcurrentHashMap
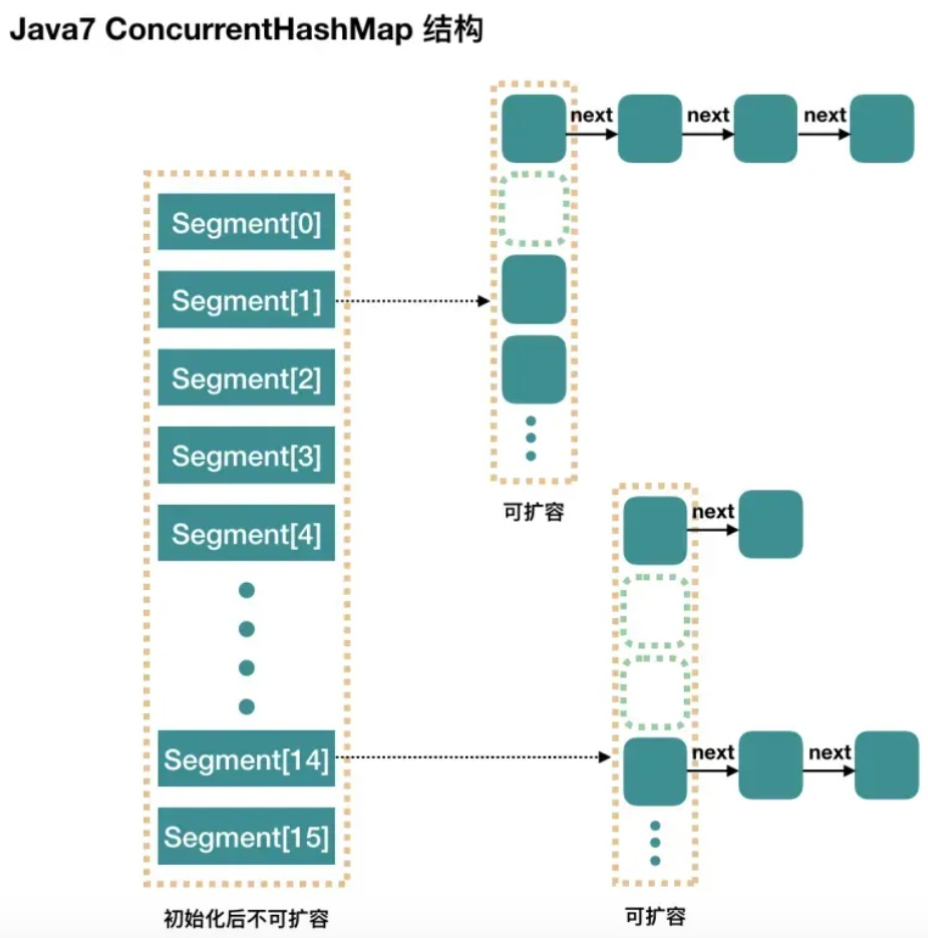
在 JDK1.7 中它使用的是数组加链表的形式实现的,而数组又分为:大数组 Segment 和小数组 HashEntry。Segment 是一种可重入锁 (ReentrantLock),在 ConcurrentHashMap 里扮演锁的角色;HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素。简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 Segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
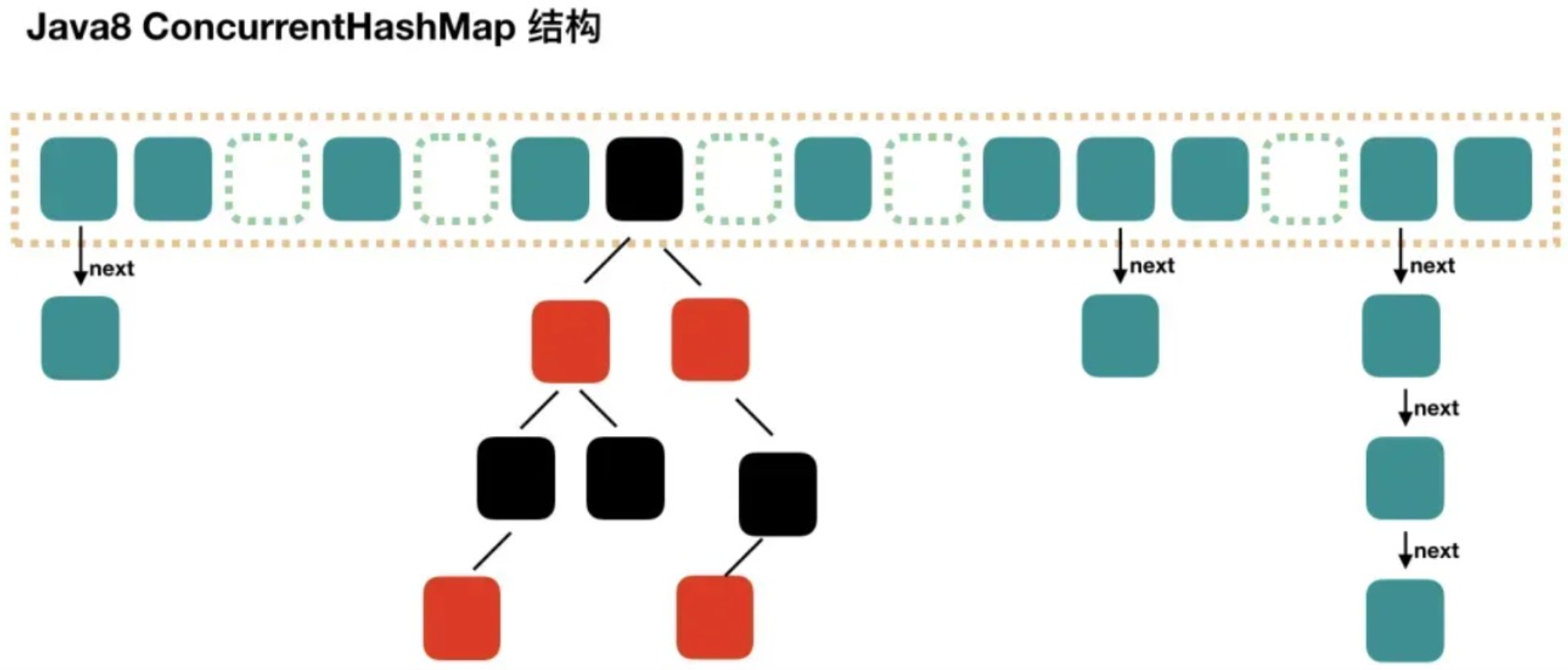
JDK1.8 也引入了红黑树,优化了之前的固定链表,那么当数据量比较大的时候,查询性能也得到了很大的提升,从之前的 O(n) 优化到了 O(logn) 的时间复杂度。ConcurrentHashMap 主要通过 volatile + CAS 或者 synchronized 来实现的线程安全的,ConcurrentHashMap 通过对头结点加锁来保证线程安全的,锁的粒度相比 Segment 来说更小了,发生冲突和加锁的频率降低了,并发操作的性能就提高了。





![HAJX[2024] 15Day游记](https://img.zcool.cn/community/01d0155da69a02a801209e1fd6db36.gif)