pandas agg函数的详细介绍与应用
参考:pandas agg
Pandas 是一个强大的 Python 数据处理库,提供了广泛的方法来进行数据分析。其中,agg 函数是一个非常有用的工具,它允许用户对数据进行多种聚合操作,可以极大地简化数据处理过程。本文将详细介绍 agg 函数的使用方法,并通过多个示例展示其在实际数据处理中的应用。
1. agg函数简介
agg 函数(也称为聚合函数)是 pandas 中 DataFrame 和 Series 对象的一个方法,用于对数据集合进行一系列的聚合操作。这些操作可以是统计总结,如求和、平均值、最大值、最小值等。agg 函数的灵活性在于它可以接受多种输入格式,如字符串、函数或者函数列表,并且可以同时对数据应用多个聚合操作。
2. agg函数的基本用法
示例代码 1: 单个聚合操作
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 对列 A 应用 sum 聚合函数
result = df['A'].agg('sum')
print(result)
Output:
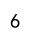
示例代码 2: 多个聚合操作
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 对列 A 应用多个聚合函数
result = df['A'].agg(['sum', 'mean'])
print(result)
Output:

示例代码 3: 对整个 DataFrame 应用聚合
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 对整个 DataFrame 应用 sum 聚合函数
result = df.agg('sum')
print(result)
Output:

示例代码 4: 对 DataFrame 应用多个聚合函数
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 对整个 DataFrame 应用多个聚合函数
result = df.agg(['sum', 'mean'])
print(result)
Output:

示例代码 5: 对不同列应用不同的聚合函数
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 对不同列应用不同的聚合函数
result = df.agg({'A': 'sum', 'B': 'mean'})
print(result)
Output:

3. 使用自定义函数进行聚合
示例代码 6: 使用自定义函数进行聚合
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 定义一个自定义聚合函数
def my_custom_function(x):return x.max() - x.min()# 应用自定义聚合函数
result = df.agg(my_custom_function)
print(result)
Output:

示例代码 7: 对特定列使用自定义函数进行聚合
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 应用自定义聚合函数到特定列
result = df['A'].agg(my_custom_function)
print(result)
4. 在 groupby 操作中使用 agg
示例代码 8: 在 groupby 中使用单个聚合函数
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'Key': ['A', 'B', 'A', 'B', 'A', 'B'],'Value': [10, 20, 30, 40, 50, 60]
})# 使用 groupby 和 agg
grouped = df.groupby('Key')
result = grouped.agg('sum')
print(result)
Output:

示例代码 9: 在 groupby 中使用多个聚合函数
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'Key': ['A', 'B', 'A', 'B', 'A', 'B'],'Value': [10, 20, 30, 40, 50, 60]
})# 使用 groupby 和多个聚合函数
grouped = df.groupby('Key')
result = grouped.agg(['sum', 'mean'])
print(result)
Output:
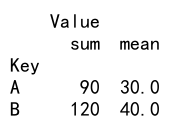
示例代码 10: 在 groupby 中对不同列使用不同的聚合函数
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'Key': ['A', 'B', 'A', 'B', 'A', 'B'],'Value1': [10, 20, 30, 40, 50, 60],'Value2': [100, 200, 300, 400, 500, 600]
})# 使用 groupby 和对不同列使用不同的聚合函数
grouped = df.groupby('Key')
result = grouped.agg({'Value1': 'sum', 'Value2': 'mean'})
print(result)
Output:

5. 结合使用 agg 和其他 pandas 功能
示例代码 11: 结合使用 agg 和 filter
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],'B': [5, 4, 3, 2, 1]
})# 使用 filter 和 agg
filtered = df[df['A'] > 2]
result = filtered.agg('sum')
print(result)
Output:

示例代码 12: 结合使用 agg 和 apply
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],'B': [5, 4, 3, 2, 1]
})# 使用 apply 和 agg
result = df.apply(lambda x: x * 2).agg('sum')
print(result)
Output:

示例代码 13: 结合使用 agg 和 sort_values
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [5, 3, 1, 4, 2],'B': [1, 2, 3, 4, 5]
})# 使用 agg 计算总和后排序
result = df.agg('sum').sort_values(ascending=False)
print(result)
Output:

示例代码 14: 使用 agg 进行条件聚合
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [10, 20, 30, 40, 50],'B': [100, 200, 300, 400, 500]
})# 定义条件聚合函数
def custom_agg(x):return x[x > 25].sum()# 应用自定义聚合函数
result = df['A'].agg(custom_agg)
print(result)
Output:
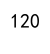
示例代码 15: 使用 agg 和 rename 结合改变结果列名
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],'B': [5, 4, 3, 2, 1]
})# 使用 agg 计算总和并重命名列
result = df.agg({'A': 'sum', 'B': 'sum'}).rename({'A': 'Total_A', 'B': 'Total_B'})
print(result)
Output:

示例代码 16: 使用 agg 结合 lambda 函数进行复杂聚合
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [10, 20, 30, 40, 50],'B': [100, 200, 300, 400, 500]
})# 使用 lambda 函数进行聚合
result = df.agg(lambda x: (x.max() - x.min()) / x.mean())
print(result)
Output:

示例代码 17: 在 groupby 后使用 agg 应用多个自定义函数
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'Key': ['A', 'B', 'A', 'B', 'A', 'B'],'Value': [10, 20, 30, 40, 50, 60]
})# 定义多个自定义聚合函数
def range_func(x):return x.max() - x.min()def average_func(x):return x.mean()# 使用 groupby 和多个自定义聚合函数
grouped = df.groupby('Key')
result = grouped.agg([range_func, average_func])
print(result)
Output:
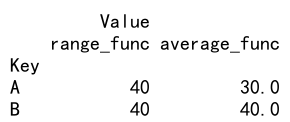
示例代码 18: 使用 agg 结合 numpy 函数
import pandas as pd
import numpy as np# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],'B': [5, 4, 3, 2, 1]
})# 使用 numpy 函数进行聚合
result = df.agg(np.sum)
print(result)
示例代码 19: 使用 agg 进行时间序列数据的聚合
import pandas as pd# 创建一个时间序列示例 DataFrame
df = pd.DataFrame({'Date': pd.date_range(start='20230101', periods=5),'Value': [1, 2, 3, 4, 5]
})# 设置日期为索引
df.set_index('Date', inplace=True)# 使用 resample 和 agg 进行时间序列聚合
result = df.resample('M').agg('sum')
print(result)
示例代码 20: 结合使用 agg 和 pivot_table
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'Category': ['A', 'A', 'B', 'B', 'C', 'C'],'Value': [10, 15, 10, 20, 30, 25]
})# 使用 pivot_table 和 agg 进行数据透视和聚合
pivot_result = df.pivot_table(index='Category', values='Value', aggfunc='sum')
print(pivot_result)
Output:
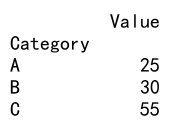
通过这些示例,我们可以看到 agg 函数在处理各种数据聚合需求时的强大能力和灵活性。无论是简单的总结统计还是复杂的自定义聚合,agg 函数都能提供有效的解决方案,帮助数据分析师在日常工作中更加高效地处理和分析数据。
参考链接:
- QQDocs pandas agg
- Yuque Pandas agg
- Nowcoder pandas agg
- Kdocs pandas agg
- 51CTO pandas agg
- Gitee pandas agg
- Developer Weixin pandas agg
- Leetcode Pandas agg