Python序列
在Python中,序列类型包括字符串、列表、元组、集合和字典,这些序列支持以下几种通用的操作,但比较特殊的是,集合和字典不支持索引、切片、相加和相乘操作。
字符串也是一种常见的序列,它也可以直接通过索引访问字符串内的字符。
序列索引
序列中,每个元素都有属于自己的编号(索引)。从起始元素开始,索引值从 0 开始递增,如图 1 所示。

除此之外,Python 还支持索引值是负数,此类索引是从右向左计数,换句话说,从最后一个元素开始计数,从索引值 -1 开始,如图 2 所示。

注意,在使用负值作为列序中各元素的索引值时,是从 -1 开始,而不是从 0 开始。
使用如下的代码:
str="C语言中文网"
print(str[0],"==",str[-6])
print(str[5],"==",str[-1])
输出结果为:
C == C
网 == 网
序列切片
切片操作是访问序列中元素的另一种方法,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的序列。
序列实现切片操作的语法格式如下:
sname[start : end : step]
其中,各个参数的含义分别是:
sname:表示序列的名称;start:表示切片的开始索引位置(包括该位置),此参数也可以不指定,会默认为 0,也就是从序列的开头进行切片;end:表示切片的结束索引位置(不包括该位置),如果不指定,则默认为序列的长度;step:表示在切片过程中,隔几个存储位置(包含当前位置)取一次元素,也就是说,如果step的值大于 1,则在进行切片去序列元素时,会“跳跃式”的取元素。如果省略设置step的值,则最后一个冒号就可以省略。
对字符串“C语言中文网”进行切片:
str="C语言中文网"
#取索引区间为[0,2]之间(不包括索引2处的字符)的字符串
print(str[:2])
#隔 1 个字符取一个字符,区间是整个字符串
print(str[::2])
#取整个字符串,此时 [] 中只需一个冒号即可
print(str[:])
运行结果为:
C语
C言文
C语言中文网
序列相加
Python中,支持两种类型相同的序列使用“+”运算符做相加操作,它会将两个序列进行连接,但不会去除重复的元素。
这里所说的“类型相同”,指的是“+”运算符的两侧序列要么都是序列类型,要么都是元组类型,要么都是字符串。
用“+”运算符连接 2 个(甚至多个)字符串,如下所示:
str="c.biancheng.net"
print("C语言"+"中文网:"+str)
输出结果为:
C语言中文网:c.biancheng.net
序列相乘
Python中,使用数字n乘以一个序列会生成新的序列,其内容为原来序列被重复n次的结果。例如:
str="C语言中文网"
print(str*3)
输出结果为:
'C语言中文网C语言中文网C语言中文网'
检查元素是否包含在序列中
Python中,可以使用in关键字检查某元素是否为序列的成员,其语法格式为:
value in sequence
其中,value表示要检查的元素,sequence表示指定的序列。
例如,检查字符c是否包含在字符串c.biancheng.net中,可以执行如下代码:
str="c.biancheng.net"
print('c'in str)
运行结果为:
True
和序列相关的内置函数
Python提供了几个内置函数(表3所示),可用于实现与序列相关的一些常用操作。
| 函数 | 功能 |
|---|---|
| len() | 计算序列的长度,即返回序列中包含多少个元素。 |
| max() | 找出序列中的最大元素。注意,对序列使用sum()函数时,做加和操作的必须都是数字,不能是字符或字符串,否则该函数将抛出异常,因为解释器无法判定是要做连接操作(+运算符可以连接两个序列),还是做加和操作。 |
| min() | 找出序列中的最小元素。 |
| list() | 将序列转换为列表。 |
| str() | 将序列转换为字符串。 |
| sum() | 计算元素和。 |
| sorted() | 对元素进行排序。 |
| reversed() | 反向序列中的元素。 |
| enumerate() | 将序列组合为一个索引序列,多用在for循环中。 |
这里给大家给几个例子:
str="c.biancheng.net"
#找出最大的字符
print(max(str))
#找出最小的字符
print(min(str))
#对字符串中的元素进行排序
print(sorted(str))
输出结果为:
t
.
['.', '.', 'a', 'b', 'c', 'c', 'e', 'e', 'g', 'h', 'i', 'n', 'n', 'n', 't']
列表
Python中没有数组,但是加入了更加强大的列表,列表是Python中的内置看一遍序列,是包含若干元素额度有序连续内存空间。
从形式上看,列表会将所有元素都放在一对中括号[]中,相邻元素之间用逗号分隔。当列表增加或者删除元素时,列表对象自动进行内存的扩展或收缩,从而保证元素之间没有缝隙。也正因如此,其效率较低,并且对于某些操作可能会导致意外的错误结果。如下所示:
[element1,element2,element3,...,elementn]
格式中,element1~elementn表示列表中的元素,个数没有限制,只要是Python支持的数据类型就可以。
从内容上看,列表可以存储整数、实数、字符串、列表、元组等任何类型的数据,并且和数组不同的是,在同一个列表中元素的类型也可以不同。比如说:
["c.biancheng.net" , 1 , [2,3,4] , 3.0]
创建列表
在Python中,创建列表的方法可分为2种,下面分别进行介绍。
使用=运算符直接创建列表
和其他类型的Python变量一样,创建列表时,也可以使用赋值运算符=直接将一个列表赋值给变量,其语法格式如下:
listname = [element1 , element2 , element3 , ... , elementn]
其中,listname表示列表的名称,注意,在命名时既要符合Python命名规范,也要尽量避开与Python的内置函数重名。
下面定义的列表都是合法的:
num = [1,2,3,4,5,6,7]
name = ["C语言中文网","http://c.biancheng.net"]
program = ["C语言","Python","Java"]
emptylist = [] # emptylist 是一个空列表
使用list()函数创建列表
Python还提供了一个内置的list()函数来创建列表,它可用于将元组、区间(range)等对象转换为列表,例如:
a_tuple = ('crazyit', 20, -1.2)
# 将元组转换成列表
a_list = list(a_tuple)
print(a_list)
输出结果为:
['crazyit', 20, -1.2]
查询列表元素
根据索引查找元素
在Python中,如果想将列表的内容输出也比较简单,直接使用print()函数即可。
name = ["C语言中文网","http://c.biancheng.net"]
num = [1,2,3,4,5,6,7]
print(name)
# 通过列表的索引获取指定的元素
print(name[1])
# 通过切片操作实现一次性访问多个元素
print(num[2:4])
运行结果为:
['C语言中文网', 'http://c.biancheng.net']
http://c.biancheng.net
[3, 4]
统计列表元素个数count()
此方法用于统计列表中某个元素出现的次数,其基本语法格式为:
listname.count(obj)
其中,listname代表列表名,obj表示判断是否存在的元素。
下面代码示范了 count() 方法的用法:
a_list = [2, 30, 'a', [5, 30], 30]
# 计算列表中30的出现次数
print(a_list.count(30))
# 计算列表中[5, 30]的出现次数
print(a_list.count([5, 30]))
运行结果为:
2
1
定位元素的索引index()
index()方法用于定位某个元素在列表中出现的位置(也就是索引),如果该元素没有出现,则会引发ValueError错误。
此方法的基本语法格式为:
listname.index(obj,start,end)
同count()方法不同,index()方法还可传入start、end参数,用于在列表的指定范围内搜索元素。
a_list = [2, 30, 'a', 'b', 'crazyit', 30]
# 定位元素30的出现位置
print(a_list.index(30))
# 从索引2处开始、定位元素30的出现位置
print(a_list.index(30, 2))
# 从索引2处到索引4处之间定位元素30的出现位置,因为找不到该元素,会引发 ValueError 错误
print(a_list.index(30, 2, 4))
运行结果为:
1
5
Traceback (most recent call last):File "C:\Users\mengma\Desktop\1.py", line 7, in <module>print(a_list.index(30, 2, 4)) # ValueError
ValueError: 30 is not in list
列表添加元素
append()整体追加列表末尾
append()方法用于在列表的末尾追加元素,该方法的语法格式如下:
listname.append(obj)
其中,listname指的是要添加元素的列表;obj表示要添加到列表末尾的数据,它可以是单个元素,也可以是列表、元组等。
a_list = ['crazyit', 20, -2]
# 追加元素
a_list.append('fkit')
print(a_list)
a_tuple = (3.4, 5.6)
# 追加元组,元组被当成一个元素
a_list.append(a_tuple)
print(a_list)
# 追加列表,列表被当成一个元素
a_list.append(['a', 'b'])
print(a_list)
运行结果为:
['crazyit', 20, -2, 'fkit']
['crazyit', 20, -2, 'fkit', (3.4, 5.6)]
['crazyit', 20, -2, 'fkit', (3.4, 5.6), ['a', 'b']]
insert()整体指定插入列表
如果希望在列表中间增加元素,则可使用列表的insert()方法,此方法的语法格式为:
listname.insert(index , obj)
其中,index参数指的是将元素插入到列表中指定位置处的索引值。
c_list = list(range(1, 6))
print(c_list)
# 在索引3处插入字符串
c_list.insert(3, 'CRAZY' )
print(c_list)
# 在索引3处插入列表
c_list.insert(3, ["crazy"])
print(c_list)
输出结果为:
[1, 2, 3, 4, 5]
[1, 2, 3, 'CRAZY', 4, 5]
[1, 2, 3, ['crazy'], 'CRAZY', 4, 5]
extend()逐个追加列表末尾
当然,如果希望不将被追加的列表或元组当成一个整体,而是只追加列表中的元素,则可使用列表提供的 extend()方法。
extend()方法的语法格式如下:
listname.extend(obj)
例如:
b_list = ['a', 30]
# 追加元组中的所有元素
b_list.extend((-2, 3.1))
print(b_list)
# 追加列表中的所有元素
b_list.extend(['C', 'R', 'A'])
print(b_list)
# 追加区间中的所有元素
b_list.extend(range(97, 100))
print(b_list)
运行结果为:
['a', 30, -2, 3.1]
['a', 30, -2, 3.1, 'C', 'R', 'A']
['a', 30, -2, 3.1, 'C', 'R', 'A', 97, 98, 99]
删除列表及元素
删除列表
对于已经创建的列表,如果不再使用,可以使用del语句将其删除。
del listname
其中,listname表示要删除列表的名称。
删除前面创建的name列表,可以使用下面的代码 :
name = ["C语言中文网","http://c.biancheng.net"]
print(name)
del name
print(name)
运行结果为:
['C语言中文网', 'http://c.biancheng.net']
Traceback (most recent call last):File "C:\Users\mengma\Desktop\1.py", line 4, in <module>print(name)
NameError: name 'name' is not defined
删除列表元素
在列表中删除元素,主要分为以下 3 种应用场景:
- 根据目标元素所在位置的索引值进行删除,可使用
del语句; - 根据元素的值进行删除,可使用列表(
list类型)提供的remove()方法; - 将列表中所有元素全部删除,可使用列表(
list类型)提供的clear()方法。
指定索引值删除元素del
删除列表中指定元素,和删除列表类似,也可以使用del语句。del语句是Python中专门用于执行删除操作的语句,不仅可用于删除列表的元素,也可用于删除变量等。
例如,定义一个保存 3 个元素的列表,若指定删除最后一个元素,可以使用如下的代码:
a_list=[20,2.4,(3,4)]
b_list = ['crazyit', 20, -2.4, (3, 4), 'fkit']del a_list[-1]
print(a_list)# 删除第2个到第4个(不包含)元素
del b_list[1: 3]
print(b_list)
输出结果为:
[20, 2.4]
['crazyit', (3, 4), 'fkit']
指定索引删除元素pop()
pop()方法会移除列表中指定索引处的元素,如果不指定,默认会移除列表中最后一个元素。该方法的基本语法格式为:
listname.pop(index)
例如:
a_list=[1,2,3]
#移除列表的元素 3
print(a_list.pop())
print(a_list)
#移除列表中索引为 0 的元素1
print(a_list.pop(0))
print(a_list)
运行结果为:
3
[1, 2]
1
[2]
指定元素值删除元素remove()
除使用del语句之外,Python还提供了remove()方法 来删除列表元素,该方法并不是根据索引来删除元素的,而是根据元素本身的值来执行删除操作的。
remove()方法会删除第一个和指定值相同的元素,如果找不到该元素,该方法将会引发ValueError错误。
如下代码示范了使用remove()方法删除元素:
c_list = [20, 'crazyit', 30, -4, 'crazyit', 3.4]
# 删除第一次找到的30
c_list.remove(30)
print(c_list)
# 删除第一次找到的'crazyit'
c_list.remove('crazyit')
print(c_list)
#再次尝试删除 30,会引发 ValueEroor 错误
c_list.remove(30)
输出结果为:
[20, 'crazyit', -4, 'crazyit', 3.4]
[20, -4, 'crazyit', 3.4]
Traceback (most recent call last):File "C:\Users\mengma\Desktop\1.py", line 9, in <module>c_list.remove(30)
ValueError: list.remove(x): x not in list
删除列表所有元素clear()
list列表还包含一个clear()方法 ,正如它的名字所暗示的,该方法用于清空列表的所有元素。例如如下代码:
c_list = [20, 'crazyit', 30, -4, 'crazyit', 3.4]
c_list.clear()
print(c_list)
输出结果为:
[]
列表修改元素
直接赋值修改
可以对列表的元素赋值,这样即可修改列表的元素。
a_list = [2, 4, -3.4, 'crazyit', 23]
# 对第3个元素赋值
a_list[2] = 'fkit'
print(a_list) # [2, 4, 'fkit', 'crazyit', 23]
# 对倒数第2个元素赋值
a_list[-2] = 9527
print(a_list) # [2, 4, 'fkit', 9527, 23]
切片删除修改
对列表中间一段赋值:
b_list = list(range(1, 5))
print(b_list)
# 将第2个到第4个(不包含)元素赋值为新列表的元素
b_list[1: 3] = ['a', 'b']
print(b_list) # [1, 'a', 'b', 4]
对列表中空的slice赋值,就变成了为列表插入元素。
# 将第3个到第3个(不包含)元素赋值为新列表的元素,就是插入
b_list[2: 2] = ['x', 'y']
print(b_list) # [1, 'a', 'x', 'y', 'b', 4]
将列表其中一段赋值为空列表,就变成了从列表中删除元素。
# 将第3个到第6个(不包含)元素赋值为空列表,就是删除
b_list[2: 5] = []
print(b_list) # [1, 'a', 4]
list常用方法
反向存放列表元素reverse()
reverse()方法会将列表中所有元素反向存放。该方法的基本语法格式为:
listname.reverse()
例如:
a_list = list(range(1, 8))
# 将a_list列表元素反转
a_list.reverse()
print(a_list)
运行结果为:
[7, 6, 5, 4, 3, 2, 1]
排序列表元素sort()
sort()方法用于对列表元素进行排序,排序后原列表中的元素顺序会方发生改变。sort()方法的语法格式如下:
listname.sort(key=None, reserse=False)
可以看到,和其他方法不同,此方法中多了 2 个参数,它们的作用分别是:
key参数用于指定从每个元素中提取一个用于比较的键。例如,使用此方法时设置key=str.lower表示在排序时不区分字母大小写。reverse参数用于设置是否需要反转排序,默认False表示从小到大排序;如果将该参数设为True,将会改为从大到小排序。
例如如下代码:
a_list = [3, 4, -2, -30, 14, 9.3, 3.4]
# 对列表元素排序
a_list.sort()
print(a_list)
b_list = ['Python', 'Swift', 'Ruby', 'Go', 'Kotlin', 'Erlang']
# 对列表元素排序:默认按字符串包含的字符的编码大小比较
b_list.sort()
print(b_list) # ['Erlang', 'Go', 'Kotlin', 'Python', 'Ruby', 'Swift']
运行结果为:
[-30, -2, 3, 3.4, 4, 9.3, 14]
['Erlang', 'Go', 'Kotlin', 'Python', 'Ruby', 'Swift']
list添加元素的方法及区别
定义两个列表(分别是list1和list3),并分别使用+、extend()、append()对这两个list进行操作,其操作的结果赋值给list2。实例代码如下:
tt = 'hello'
#定义一个包含多个类型的 list
list1 = [1,4,tt,3.4,"yes",[1,2]]
print(list1,id(list1))print("1.----------------")#比较 list 中添加元素的几种方法的用法和区别
list3 = [6,7]
list2 = list1 + list3
print(list2,id(list2))print("2.----------------")list2 = list1.extend(list3)
print(list2,id(list2))
print(list1,id(list1))print("3.----------------")list2 = list1.append(list3)
print(list2,id(list2))
print(list1,id(list1))
输出结果为:
[1, 4, 'hello', 3.4, 'yes', [1, 2]] 2251638471496
1.----------------
[1, 4, 'hello', 3.4, 'yes', [1, 2], 6, 7] 2251645237064
2.----------------
None 1792287952
[1, 4, 'hello', 3.4, 'yes', [1, 2], 6, 7] 2251638471496
3.----------------
None 1792287952
[1, 4, 'hello', 3.4, 'yes', [1, 2], 6, 7, [6, 7]] 2251638471496
根据输出结果,可以分析出以下几个结论:
- 使用
“+”号连接的列表,是将list3中的元素放在list的后面得到的list2。并且list2的内存地址值与list1并不一样,这表明list2是一个重新生成的列表。 - 使用
extend处理后得到的list2是none。表明extend没有返回值,并不能使用链式表达式。即extend千万不能放在等式的右侧,这是编程时常犯的错误,一定要引起注意。 extend处理之后,list1的内容与使用“+”号生成的list2是一样的。但list1的地址在操作前后并没有变化,这表明extend的处理仅仅是改变了list1,而没有重新创建一个list。从这个角度来看,extend的效率要高于“+”号。- 从
append的结果可以看出,append的作用是将list3整体当成一个元素追加到list1后面,这与extend和“+”号的功能完全不同,这一点也需要注意。
range()快速初始化数字列表
range()函数的用法是:让Python从指定的第一个值开始,一直数到指定的第二个值停止,但不包含第二个值 。
for value in range(1,5):print(value)
输出结果为:
1
2
3
4
range()函数的返回值类型为range,而不是list。而如果想要得到range()函数创建的数字列表,还需要借助 list() 函数,比如:
>>> list(range(1,6))
[1, 2, 3, 4, 5]
list列表实现栈和队列
list实现队列
使用list列表模拟队列功能的实现方法是,定义一个list变量,存入数据时使用insert()方法,设置其第一个参数为 0,即表示每次都从最前面插入数据;读取数据时,使用pop()方法,即将队列的最后一个元素弹出。
如此 list 列表中数据的存取顺序就符合“先进先出”的特点。实现代码如下:
#定义一个空列表,当做队列
queue = []
#向列表中插入元素
queue.insert(0,1)
queue.insert(0,2)
queue.insert(0,"hello")
print(queue)
print("取一个元素:",queue.pop())
print("取一个元素:",queue.pop())
print("取一个元素:",queue.pop())
运行结果为:
['hello', 2, 1]
取一个元素: 1
取一个元素: 2
取一个元素: hello
list实现栈
使用list列表模拟栈功能的实现方法是,使用append()方法存入数据;使用pop()方法读取数据。
append()方法向list中存入数据时,每次都在最后面添加数据,这和前面程序中的insert()方法正好相反。
举个例子:
#定义一个空 list 当做栈
stack = []
stack.append(1)
stack.append(2)
stack.append("hello")
print(stack)
print("取一个元素:",stack.pop())
print("取一个元素:",stack.pop())
print("取一个元素:",stack.pop())
输出结果为:
[1, 2, 'hello']
取一个元素: hello
取一个元素: 2
取一个元素: 1
元组
元组是Python中另一个重要的序列结构,和列表类似,也是由一系列按特定顺序排序的元素组成。和列表不同的是,列表可以任意操作元素,是可变序列;而元组是不可变序列,即元组中的元素不可以单独修改。
元组可以看做是不可变的列表。通常情况下,元组用于保存不可修改的内容。
1、从形式上看,元组的所有元素都放在一对小括号()中,相邻元素之间用逗号,分隔,如下所示:
(element1, element2, ... , elementn)
其中element1~elementn表示元组中的各个元素,个数没有限制,且只要是Python支持的数据类型就可以。
2、从存储内容上看,元组可以存储整数、实数、字符串、列表、元组等任何类型的数据,并且在同一个元组中,元素的类型可以不同,例如:
("c.biancheng.net",1,[2,'a'],("abc",3.0))
在这个元组中,有多种类型的数据,包括整形、字符串、列表、元组。
创建元组
Python提供了多种创建元组的方法。
=运算符直接创建元组
在创建元组时,可以使用赋值运算符“=”直接将一个元组赋值给变量,其语法格式如下
tuplename = (element1,element2,...,elementn)
其中,tuplename表示创建的元组名,可以使用任何符合Python命名规则,且不和Python内置函数重名的标识符作为元组名。
下面定义的元组都是合法的:
num = (7,14,21,28,35)
a_tuple = ("C语言中文网","http://c.biancheng.net")
python = ("Python",19,[1,2],('c',2.0))# 元组通常都是使用一对小括号将所有元素括起来的,
# 但小括号不是必须的,只要将各元素用逗号隔开,Python 就会将其视为元组
a_tuple = "C语言中文网","http://c.biancheng.net"
print(a_tuple)
当创建的元组中只有一个元素时,此元组后面必须要加一个逗号“,”,否则Python解释器会将其误认为字符串。
#创建元组 a_typle
a_tuple =("C语言中文网",)
print(type(a_tuple))
print(a_tuple)#创建字符串 a
a = ("C语言中文网")
print(type(a))
print(a)
运行结果为:
<class 'tuple'> # a_tuple 才是元组类型
('C语言中文网',)
<class 'str'> # 变量 a 只是一个字符串
C语言中文网
使用tuple()函数创建元组
tuple函数的语法格式如下:
tuple(data)
其中,data 表示可以转化为元组的数据,其类型可以是字符串、元组、range 对象等。
# 将列表转换成元组
a_list = ['crazyit', 20, -1.2]
a_tuple = tuple(a_list)
print(a_tuple)# 使用range()函数创建区间(range)对象
a_range = range(1, 5)
print(a_range)
# 将区间转换成元组
b_tuple = tuple(a_range)
print(b_tuple)
# 创建区间时还指定步长
c_tuple = tuple(range(4, 20, 3))
print(c_tuple)
运行结果为:
('crazyit', 20, -1.2)
range(1, 5)
(1, 2, 3, 4)
(4, 7, 10, 13, 16, 19)
访问元组元素
想访问元组中的指定元素,可以使用元组中各元素的索引值获取, 也可以采用切片方式获取指定范围内的元素 。
a_tuple = ('crazyit', 20, -1.2)
print(a_tuple[1]) # 20b_tuple = ('crazyit', 20, -1.2)
#采用切片方式
print(b_tuple[:2]) # ('crazyit', 20)
修改元组元素
元组是不可变序列,元组中的元素不可以单独进行修改。但是,元组也不是完全不能修改。
我们可以对元组进行重新赋值:
a_tuple = ('crazyit', 20, -1.2)
print(a_tuple) # 输出是('crazyit', 20, -1.2)
#对元组进行重新赋值
a_tuple = ('c.biancheng.net',"C语言中文网")
print(a_tuple) # 输出是('c.biancheng.net', 'C语言中文网')
还可以通过连接多个元组的方式向元组中添加新元素。
a_tuple = ('crazyit', 20, -1.2)
print(a_tuple) # 输出是('crazyit', 20, -1.2)
#连接多个元组
a_tuple = a_tuple + ('c.biancheng.net',)
print(a_tuple) # 输出是('crazyit', 20, -1.2, 'c.biancheng.net')# 元组连接的内容必须都是元组,不能将元组和字符串或列表进行连接,否则或抛出 TypeError 错误。
a_tuple = ('crazyit', 20, -1.2)
#元组连接字符串
a_tuple = a_tuple + 'c.biancheng.net'
print(a_tuple)
# 结果为:
# Traceback (most recent call last):
# File "C:\Users\mengma\Desktop\1.py", line 4, in <module>
# a_tuple = a_tuple + 'c.biancheng.net'
# TypeError: can only concatenate tuple (not "str") to tuple
删除元组
当已经创建的元组确定不再使用时,可以使用del语句将其删除
a_tuple = ('crazyit', 20, -1.2)
print(a_tuple)
#删除a_tuple元组
del(a_tuple)
print(a_tuple)
运行结果为:
('crazyit', 20, -1.2)
Traceback (most recent call last):File "C:\Users\mengma\Desktop\1.py", line 4, in <module>print(a_tuple)
NameError: name 'a_tuple' is not defined
元组和列表的区别
元组和列表最大的区别就是,列表中的元素可以进行任意修改;而元组中的元素无法修改。
可以理解为,tuple 元组是一个只读版本的 list 列表。
需要注意的是,这样的差异势必会影响两者的存储方式,我们来直接看下面的例子:
>>> listdemo = []
>>> listdemo.__sizeof__()
40
>>> tupleDemo = ()
>>> tupleDemo.__sizeof__()
24
对于列表和元组来说,虽然它们都是空的,但元组却比列表少占用 16 个字节,这是为什么呢?
事实上,就是由于列表是动态的,它需要存储指针来指向对应的元素(占用 8 个字节)。另外,由于列表中元素可变,所以需要额外存储已经分配的长度大小(占用 8 个字节)。但是对于元组,情况就不同了,元组长度大小固定,且存储元素不可变,所以存储空间也是固定的。
通过对比列表和元组存储方式的差异,我们可以引申出这样的结论,即元组要比列表更加轻量级,所以从总体上来说,元组的性能速度要由于列表。
另外,Python会在后台,对静态数据做一些资源缓存。通常来说,因为垃圾回收机制的存在,如果一些变量不被使用了,Python就会回收它们所占用的内存,返还给操作系统,以便其他变量或其他应用使用。
但是对于一些静态变量(比如元组),如果它不被使用并且占用空间不大时,Python会暂时缓存这部分内存。这样的话,当下次再创建同样大小的元组时,Python就可以不用再向操作系统发出请求去寻找内存,而是可以直接分配之前缓存的内存空间,这样就能大大加快程序的运行速度。
算初始化一个相同元素的列表和元组分别所需的时间。我们可以看到,元组的初始化速度要比列表快 5 倍。
C:\Users\mengma>python -m timeit 'x=(1,2,3,4,5,6)'
20000000 loops, best of 5: 9.97 nsec per loop
C:\Users\mengma>python -m timeit 'x=[1,2,3,4,5,6]'
5000000 loops, best of 5: 50.1 nsec per loop
列表和元组的底层实现
list列表具体结构
typedef struct {PyObject_VAR_HEAD/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */PyObject **ob_item;/* ob_item contains space for 'allocated' elements. The number* currently in use is ob_size.* Invariants:* 0 <= ob_size <= allocated* len(list) == ob_size* ob_item == NULL implies ob_size == allocated == 0* list.sort() temporarily sets allocated to -1 to detect mutations.** Items must normally not be NULL, except during construction when* the list is not yet visible outside the function that builds it.*/Py_ssize_t allocated;
} PyListObject;
list本质上是一个长度可变的连续数组。其中ob_item是一个指针列表,里边的每一个指针都指向列表中的元素,而allocated则用于存储该列表目前已被分配的空间大小。
需要注意的是,allocated和列表的实际空间大小不同,列表实际空间大小,指的是len(list)返回的结果,也就是上边代码中注释中的ob_size,表示该列表总共存储了多少个元素。而在实际情况中,为了优化存储结构,避免每次增加元素都要重新分配内存,列表预分配的空间allocated往往会大于ob_size。
因此allocated和ob_size的关系是:allocated >= len(list) = ob_size >= 0。
如果当前列表分配的空间已满(即allocated == len(list)),则会向系统请求更大的内存空间,并把原来的元素全部拷贝过去。
元组的具体结构
typedef struct {PyObject_VAR_HEADPyObject *ob_item[1];/* ob_item contains space for 'ob_size' elements.* Items must normally not be NULL, except during construction when* the tuple is not yet visible outside the function that builds it.*/
} PyTupleObject;
tuple和list相似,本质也是一个数组,但是空间大小固定。不同于一般数组,Python的tuple做了许多优化,来提升在程序中的效率。
为了提高效率,避免频繁的调用系统函数free和malloc向操作系统申请和释放空间,tuple源文件中定义了一个free_list:
static PyTupleObject *free_list[PyTuple_MAXSAVESIZE];
所有申请过的,小于一定大小的元组,在释放的时候会被放进这个free_list中以供下次使用。也就是说,如果以后需要再去创建同样的tuple,Python就可以直接从缓存中载入。
字典
和列表相同,字典也是许多数据的集合,属于可变序列类型。不同之处在于,它是无序的可变序列,其保存的内容是以“键值对”的形式存放的。
字典类型是Python中唯一的映射类型。“映射”是数学中的术语,简单理解,它指的是元素之间相互对应的关系,即通过一个元素,可以唯一找到另一个元素。如图 1 所示。
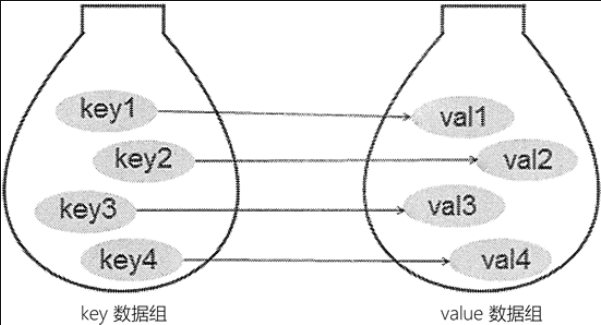
字典中,习惯将各元素对应的索引称为键(key),各个键对应的元素称为值(value),键及其关联的值称为“键值对”。
| 主要特征 | 解释 |
|---|---|
| 通过键而不是通过索引来读取元素 | 字典类型有时也称为关联数组或者散列表(hash)。它是通过键将一系列的值联系起来的,这样就可以通过键从字典中获取指定项,但不能通过索引来获取。 |
| 字典是任意数据类型的无序集合 | 和列表、元组不同,通常会将索引值 0 对应的元素称为第一个元素。而字典中的元素是无序的。 |
| 字典是可变的,并且可以任意嵌套 | 字典可以在原处增长或者缩短(无需生成一个副本),并且它支持任意深度的嵌套,即字典存储的值也可以是列表或其它的字典。 |
| 字典中的键必须唯一 | 字典中,不支持同一个键出现多次,否则,只会保留最后一个键值对。 |
| 字典中的键必须不可变 | 字典中的值是不可变的,只能使用数字、字符串或者元组,不能使用列表。 |
创建字典
创建字典的方式有很多,下面一一做介绍。
1) 花括号语法创建字典
由于字典中每个元素都包含 2 部分,分别是键和值,因此在创建字典时,键和值之间使用冒号分隔,相邻元素之间使用逗号分隔,所有元素放在大括号 {} 中。
字典类型的语法格式如下:
dictname = {'key':'value1','key2':'value2',...,'keyn':valuen}
其中dictname表示字典类型名,keyn : valuen表示各个元素的键值对。需要注意的是,同一字典中各个元素的键值必须唯一。
scores = {'语文': 89, '数学': 92, '英语': 93}
print(scores)
# 空的花括号代表空的dict
empty_dict = {}
print(empty_dict)
# 使用元组作为dict的key
dict2 = {(20, 30):'good', 30:[1,2,3]}
print(dict2)
运行结果为:
{'语文': 89, '数学': 92, '英语': 93}
{}
{(20, 30): 'good', 30: [1, 2, 3]}
2) 通过fromkeys()方法创建字典
Python中,还可以使用dict字典类型提供的fromkeys()方法创建所有键值为空的字典,使用此方法的语法格式为:
dictname = dict.fromkeys(list,value=None)
其中,list参数表示字典中所有键的列表,value参数默认为None,表示所有键对应的值。
knowledge = {'语文', '数学', '英语'}
scores = dict.fromkeys(knowledge)
print(scores)
运行结果为:
{'语文': None, '数学': None, '英语': None}
可以看到,knowledge列表中的元素全部作为了scores字典的键,而各个键对应的值都为空(None)。此种创建方式,通常用于初始化字典,设置value的默认值。
3) 通过dict()映射函数创建字典
通过dict()函数创建字典的写法有多种,表2罗列出了常用的几种方式,它们创建的都是同一个字典a。
-
方式一: 注意,其中的
one、two、three都是字符串,但使用此方式创建字典时,字符串不能带引号。a = dict(one=1,two=2,three=3) -
方式二: 向
dict()函数传入列表或元组,而它们中的元素又各自是包含 2 个元素的列表或元组,其中第一个元素作为键,第二个元素作为值。demo = [('two',2),('one',1),('three',3)] #方式1 demo = [['two',2],['one',1],['three',3]] #方式2 demo = (('two',2),('one',1),('three',3)) #方式3 demo = (['two',2],['one',1],['three',3]) #方式4 a = dict(demo) -
方式三: 通过应用
dict()函数和zip()函数,可将前两个列表转换为对应的字典。demokeys = ['one','two','three'] #还可以是字符串或元组 demovalues = [1,2,3] #还可以是字符串或元组 a = dict(zip(demokeys,demovalues))
访问字典
字典是通过键来访问对应的元素值。
因为字典中元素是无序的,所以不能像列表、元组那样,采用切片的方式一次性访问多个元素。
如果想访问刚刚建立的字典 a 中,获取元素 1,可以使用下面的代码; 如果键不存在,则会抛出异常 :
>>> a['one']
1
>>> a['four']
Traceback (most recent call last):File "<pyshell#2>", line 1, in <module>a['four']
KeyError: 'four'
Python更推荐使用dict类型提供的get()方法获取指定键的值。get()方法的语法格式为:
dict.get(key[,default])
其中,dict指的是所创建的字典名称;key表示指定的键;default用于指定要查询的键不存在时,此方法返回的默认值,如果不手动指定,会返回None。
>>> a = dict(one=1,two=2,three=3)
>>>a.get('two')
2
>>> a.get('four','字典中无此键')
'字典中无此键'
删除字典
和删除列表、元组一样,手动删除字典也可以使用del语句。例如:
>>> a = dict(one=1,two=2,three=3)
>>> a
{'one': 1, 'two': 2, 'three': 3}
>>> del(a)
>>> a
Traceback (most recent call last):File "<pyshell#16>", line 1, in <module>a
NameError: name 'a' is not defined
字典添加键值对
如果要为dict添加键值对,只需为不存在的key赋值即可。实现此操作的语法格式如下:
dict[key] = value
| 参数 | 含义 |
|---|---|
| dict | 表示字典名称。 |
| key | 表示要添加元素的键。注意,既然是添加新的元素,那么就要保证此元素的键和字典中现有元素的键互不相同。 |
| value | 表示要添加数据的值,只要是 Python 支持的数据类型就可以。 |
a = {'数学':95}
print(a)
#添加新键值对
a['语文'] = 89
print(a)
#再次添加新键值对
a['英语'] = 90
print(a)
运行结果为:
{'数学': 95}
{'数学': 95, '语文': 89}
{'数学': 95, '语文': 89, '英语': 90}
字典修改键值对
“修改键值对”并不是同时修改某一键值对的键和值,而只是修改某一键值对中的值。
由于在字典中,各元素的键必须是唯一的,因此,如果新添加元素的键与已存在元素的键相同,原来键所对应的值就会被新的值替换掉。例如:
a = {'数学': 95, '语文': 89, '英语': 90}
a['语文']=100
print(a)
运行结果为:
{'数学': 95, '语文': 100, '英语': 90}
字典删除键值对
如果要删除字典中的键值对,还是可以使用 del 语句。例如:
# 使用del语句删除键值对
a = {'数学': 95, '语文': 89, '英语': 90}
del a['语文']
del a['数学']
print(a)
运行结果为:
{'英语': 90}
判断字典中是否存在指定键值对
如果要判断字典中是否存在指定键值对,首先应判断字典中是否有对应的键。判断字典是否包含指定键值对的键,可以使用in或not in运算符。
需要指出的是,对于dict而言,in或not in运算符都是基于key来判断的。
a = {'数学': 95, '语文': 89, '英语': 90}
# 判断 a 中是否包含名为'数学'的key
print('数学' in a) # True
# 判断 a 是否包含名为'物理'的key
print('物理' in a) # False
运行结果为:
True
False
keys()、values()和items()方法
keys()方法用于返回字典中的所有键;values()方法用于返回字典中所有键对应的值;items()用于返回字典中所有的键值对。
a = {'数学': 95, '语文': 89, '英语': 90}
print(a.keys())
print(a.values())
print(a.items())
运行结果为:
dict_keys(['数学', '语文', '英语'])
dict_values([95, 89, 90])
dict_items([('数学', 95), ('语文', 89), ('英语', 90)])
注意,在Python 2.x中,这三个方法的返回值是列表类型。但在Python 3中,并不是我们常见的列表和元组类型,因为Python 3不希望用户直接操作这几个方法的返回值。 如果想使用返回的数据,有以下 2 种方法:
-
使用
list()函数,将它们返回的数据转换成列表,例如:a = {'数学': 95, '语文': 89, '英语': 90} b = list(a.keys()) print(b)运行结果为:
['数学', '语文', '英语'] -
也可以利用多重赋值的技巧,利用循环结构将键或值分别赋给不同的变量,比如说:
a = {'数学': 95, '语文': 89, '英语': 90} for k in a.keys():print(k,end=' ') print("\n---------------") for v in a.values():print(v,end=' ') print("\n---------------") for k,v in a.items():print("key:",k," value:",v)运行结果为:
数学 语文 英语 --------------- 95 89 90 --------------- key: 数学 value: 95 key: 语文 value: 89 key: 英语 value: 90
copy()方法
copy()方法用于返回一个具有相同键值对的新字典,例如:
a = {'one': 1, 'two': 2, 'three': [1,2,3]}
b = a.copy()
print(b)
运行结果为:
{'one': 1, 'two': 2, 'three': [1, 2, 3]}
注意,copy() 方法所遵循的拷贝原理,既有深拷贝,也有浅拷贝。 拿拷贝字典 a 为例,copy()方法只会对最表层的键值对进行深拷贝,也就是说,它会再申请一块内存用来存放{'one': 1, 'two': 2, 'three': []};而对于某些列表类型的值来说,此方法对其做的是浅拷贝,也就是说,b 中的[1,2,3]的值不是自己独有,而是和 a 共有。
a = {'one': 1, 'two': 2, 'three': [1,2,3]}
b = a.copy()
#向 a 中添加新键值对,由于b已经提前将 a 所有键值对都深拷贝过来,因此 a 添加新键值对,不会影响 b。
a['four']=100
print(a)
print(b)
#由于 b 和 a 共享[1,2,3](浅拷贝),因此移除 a 中列表中的元素,也会影响 b。
a['three'].remove(1)
print(a)
print(b)
运行结果为:
{'one': 1, 'two': 2, 'three': [1, 2, 3], 'four': 100}
{'one': 1, 'two': 2, 'three': [1, 2, 3]}
{'one': 1, 'two': 2, 'three': [2, 3], 'four': 100}
{'one': 1, 'two': 2, 'three': [2, 3]}
update()方法
update()方法可使用一个字典所包含的键值对来更新己有的字典。在执行update()方法时,如果被更新的字典中己包含对应的键值对,那么原 value 会被覆盖;如果被更新的字典中不包含对应的键值对,则该键值对被添加进去。
a = {'one': 1, 'two': 2, 'three': 3}
a.update({'one':4.5, 'four': 9.3})
print(a)
运行结果为:
{'one': 4.5, 'two': 2, 'three': 3, 'four': 9.3}
pop()方法
pop()方法用于获取指定key对应的value,并删除这个键值对。
a = {'one': 1, 'two': 2, 'three': 3}
print(a.pop('one'))
print(a)
运行结果为:
1
{'two': 2, 'three': 3}
popitem()方法
popitem()方法用于随机弹出字典中的一个键值对。此处的随机其实是假的,它和list.pop()方法一样,也是弹出字典中最后一个键值对。
a = {'one': 1, 'two': 2, 'three': 3}
print(a)
# 弹出字典底层存储的最后一个键值对
print(a.popitem())
print(a)
运行结果为:
{'one': 1, 'two': 2, 'three': 3}
('three', 3)
{'one': 1, 'two': 2}
setdefault()方法
setdefault()方法也用于根据key来获取对应value的值。 setdefault()方法总能返回指定key对应的 value;如果该键值对存在,则直接返回该key对应的value;如果该键值对不存在,则先为该key设置默认的value,然后再返回该key对应的value。
a = {'one': 1, 'two': 2, 'three': 3}
# 设置默认值,该key在dict中不存在,新增键值对
print(a.setdefault('four', 9.2))
print(a)
# 设置默认值,该key在dict中存在,不会修改dict内容
print(a.setdefault('one', 3.4))
print(a)
运行结果为:
9.2
{'one': 1, 'two': 2, 'three': 3, 'four': 9.2}
1
{'one': 1, 'two': 2, 'three': 3, 'four': 9.2}
使用字典格式化字符串
使用场景: 在格式化字符串时,如果要格式化的字符串模板中包含少量变量时,后面需要按顺序给出多个变量;但如果字符串模板中包含大量变量, 就要使用字典对字符串进行格式化输出 。
使用方法:在字符串模板中按key指定变量,然后通过字典为字符串模板中的key设置值。
# 字符串模板中使用key
temp = '教程是:%(name)s, 价格是:%(price)010.2f, 出版社是:%(publish)s'
book = {'name':'Python基础教程', 'price': 99, 'publish': 'C语言中文网'}
# 使用字典为字符串模板中的key传入值
print(temp % book)
book = {'name':'C语言小白变怪兽', 'price':159, 'publish': 'C语言中文网'}
# 使用字典为字符串模板中的key传入值
print(temp % book)
运行上面程序,可以看到如下输出结果:
教程是:Python基础教程, 价格是:0000099.00, 出版社是:C语言中文网
教程是:C语言小白变怪兽, 价格是:0000159.00, 出版社是:C语言中文网
集合
Python中的集合,用来保存不重复的元素,即集合中的元素都是唯一的,互不相同。
set集合
从形式上看,和字典类似,Python集合会将所有元素放在一对大括号{} 中,相邻元素之间用,分隔,如下所示:
{element1,element2,...,elementn}
其中,elementn表示集合中的元素,个数没有限制。
从内容上看,同一集合中,只能存储不可变的数据类型,包括整形、浮点型、字符串、元组,无法存储列表、字典、集合这些可变的数据类型,否则Python解释器会抛出TypeError错误。比如说:
>>> {{'a':1}}
Traceback (most recent call last):File "<pyshell#8>", line 1, in <module>{{'a':1}}
TypeError: unhashable type: 'dict'
>>> {[1,2,3]}
Traceback (most recent call last):File "<pyshell#9>", line 1, in <module>{[1,2,3]}
TypeError: unhashable type: 'list'
>>> {{1,2,3}}
Traceback (most recent call last):File "<pyshell#10>", line 1, in <module>{{1,2,3}}
TypeError: unhashable type: 'set'
集合对于每种数据元素,只会保留一份。例如:
>>> {1,2,1,(1,2,3),'c','c'}
{1, 2, 'c', (1, 2, 3)}
创建set集合
1) 使用{}创建
创建set集合直接将集合赋值给变量,从而实现创建集合的目的,其语法格式如下:
setname = {element1,element2,...,elementn}
其中,setname表示集合的名称,起名时既要符合Python命名规范,也要避免与Python内置函数重名。
a = {1,'c',1,(1,2,3),'c'}
print(a) # 结果为:{1, 'c', (1, 2, 3)}
2) set()函数创建集合
set()函数为Python的内置函数,其功能是将字符串、列表、元组、range对象等可迭代对象转换成集合。该函数的语法格式如下:
setname = set(iteration)
其中,iteration就表示字符串、列表、元组、range对象等数据。
set1 = set("c.biancheng.net")
set2 = set([1,2,3,4,5])
set3 = set((1,2,3,4,5))
print("set1:",set1)
print("set2:",set2)
print("set3:",set3)
运行结果为:
set1: {'a', 'g', 'b', 'c', 'n', 'h', '.', 't', 'i', 'e'}
set2: {1, 2, 3, 4, 5}
set3: {1, 2, 3, 4, 5}
访问set集合元素
由于集合中的元素是无序的,因此无法向列表那样使用下标访问元素。Python 中,访问集合元素最常用的方法是使用循环结构,将集合中的数据逐一读取出来。
a = {1,'c',1,(1,2,3),'c'}
for ele in a:print(ele,end=' ')
运行结果为:
1 c (1, 2, 3)
删除set集合
使用del()语句删除set集合,例如:
a = {1,'c',1,(1,2,3),'c'}
print(a)
del(a)
print(a)
运行结果为:
{1, 'c', (1, 2, 3)}
Traceback (most recent call last):File "C:\Users\mengma\Desktop\1.py", line 4, in <module>print(a)
NameError: name 'a' is not defined
向set集合中添加元素
set集合中添加元素,可以使用set类型提供的add()方法实现,该方法的语法格式为:
setname.add(element)
其中,setname表示要添加元素的集合,element表示要添加的元素内容。
使用add()方法添加的元素,只能是数字、字符串、元组或者布尔类型(True和False)值,不能添加列表、字典、集合这类可变的数据,否则Python解释器会报 TypeError错误。例如:
a = {1,2,3}
a.add((1,2))
print(a)
a.add([1,2])
print(a)
运行结果为:
{(1, 2), 1, 2, 3}
Traceback (most recent call last):File "C:\Users\mengma\Desktop\1.py", line 4, in <module>a.add([1,2])
TypeError: unhashable type: 'list'
从set集合中删除元素
删除现有set集合中的指定元素,可以使用 remove()方法,该方法的语法格式如下:
setname.remove(element)
使用此方法删除集合中元素,需要注意的是,如果被删除元素本就不包含在集合中,则此方法会抛出KeyError错误,例如:
a = {1,2,3}
a.remove(1)
print(a)
a.remove(1)
print(a)
#==============================
b = {1,2,3}
b.remove(1)
print(b)
b.discard(1) # discard() 方法当删除集合中元素失败时,此方法不会抛出任何错误
print(b)
运行结果为:
{2, 3}
Traceback (most recent call last):File "C:\Users\mengma\Desktop\1.py", line 4, in <module>a.remove(1)
KeyError: 1
#==============================
{2, 3}
{2, 3}
set集合做交集、并集、差集运算
有2个集合,分别为set1={1,2,3}和set2={3,4,5},它们既有相同的元素,也有不同的元素。以这两个集合为例,分别做不同运算的结果如表1所示。
| 运算操作 | Python运算符 | 含义 | 例子 |
|---|---|---|---|
| 交集 | & | 取两集合公共的元素 | >>> set1 & set2 |
| 并集 | | | 取两集合全部的元素 | >>> set1 | set2 |
| 差集 | - | 取一个集合中另一集合没有的元素 | >>> set1 - set2 {1,2} >>> set2 - set1 |
| 对称差集 | ^ | 取集合A和B中不属于A&B的元素 | >>> set1 ^ set2 |
字符串
字符串拼接
Python使用加号(+)作为字符串的拼接运算符,例如如下代码:
s2 = "Python "
s3 = "iS Funny"
#使用+拼接字符串
s4 = s2 + s3
print(s4)
字符串拼接数字
Python不允许直接拼接数字和字符串,程序必须先将数字转换成字符串。
为了将数字转换成字符串,可以使用str()或repr()函数,例如如下代码:
s1 = "这是数字: "
p = 99.8
#字符串直接拼接数值,程序报错
print(s1 + p)
#使用str()将数值转换成字符串
print(s1 + str(p))
#使用repr()将数值转换成字符串
print(s1 + repr(p))
截取字符串
Python字符串直接在方括号([])中使用索引即可获取对应的字符,其基本语法格式为:
string[index]
这里的string表示要截取的字符串,index表示索引值。Python规定,字符串中第一个字符的索引为 0、第二个字符的索引为 1,后面各字符依此类推。此外,Python也允许从后面开始计算索引,最后一个字符的索引为 -1,倒数第二个字符的索引为 -2,依此类推。
s = 'crazyit.org is very good'
# 获取s中索引2处的字符
print(s[2]) # 输出a
# 获取s中从右边开始,索引4处的字符
print(s[-4]) # 输出g
Python也可以在方括号中使用范围来获取字符串的中间“一段”(被称为子串),其基本语法格式为:
string[start : end : step]
此格式中,各参数的含义如下:
string:要截取的字符串;start:表示要截取的第一个字符所在的索引(截取时包含该字符)。如果不指定,默认为 0,也就是从字符串的开头截取;end:表示要截取的最后一个字符所在的索引(截取时不包含该字符)。如果不指定,默认为字符串的长度;step:指的是从start索引处的字符开始,每step个距离获取一个字符,直至end索引出的字符。step默认值为 1,当省略该值时,最后一个冒号也可以省略。
s = 'crazyit.org is very good'
# 获取s中从索引3处到索引5处(不包含)的子串
print(s[3: 5]) # 输出 zy
# 获取s中从索引3处到倒数第5个字符的子串
print(s[3: -5]) # 输出 zyit.org is very
# 获取s中从倒数第6个字符到倒数第3个字符的子串
print(s[-6: -3]) # 输出 y g
#每隔 1 个,取一个字符
print(s[::2]) # 输出 caytogi eygo
# 获取s中从索引5处到结束的子串
print(s[5: ]) # 输出it.org is very good
# 获取s中从倒数第6个字符到结束的子串
print(s[-6: ]) # 输出y good
# 获取s中从开始到索引5处的子串
print(s[: 5]) # 输出crazy
# 获取s中从开始到倒数第6个字符的子串
print(s[: -6]) #输出crazyit.org is ver
len()函数详解:获取字符串长度或字节数
Python中,要想知道一个字符串有多少个字符(获得字符串长度),或者一个字符串占用多少个字节,可以使用len函数。
len函数的基本语法格式为:
len(string)
其中string用于指定要进行长度统计的字符串。
>>> a='http://c.biancheng.net'
>>> len(a)
22
通过使用encode()方法,将字符串进行编码后再获取它的字节数。
>>> str1 = "人生苦短,我用Python"
>>> len(str1.encode())
27
因为汉字加中文标点符号共7个,占21个字节,而英文字母和英文的标点符号占6个字节,一共占用27个字节。
split()方法详解:分割字符串
split()方法可以实现将一个字符串按照指定的分隔符切分成多个子串,这些子串会被保存到列表中(不包含分隔符),作为方法的返回值反馈回来。该方法的基本语法格式如下:
str.split(sep,maxsplit)
此方法中各部分参数的含义分别是:
str:表示要进行分割的字符串;sep:用于指定分隔符,可以包含多个字符。此参数默认为None,表示所有空字符,包括空格、换行符“\n”、制表符“\t”等。maxsplit:可选参数,用于指定分割的次数,最后列表中子串的个数最多为maxsplit+1。如果不指定或者指定为 -1,则表示分割次数没有限制。
>>> str = "C语言中文网 >>> c.biancheng.net"
>>> str
'C语言中文网 >>> c.biancheng.net'
>>> list1 = str.split() #采用默认分隔符进行分割
>>> list1
['C语言中文网', '>>>', 'c.biancheng.net']
>>> list2 = str.split('>>>') #采用多个字符进行分割
>>> list2
['C语言中文网 ', ' c.biancheng.net']
>>> list3 = str.split('.') #采用 . 号进行分割
>>> list3
['C语言中文网 >>> c', 'biancheng', 'net']
>>> list4 = str.split(' ',4) #采用空格进行分割,并规定最多只能分割成 4 个子串
>>> list4
['C语言中文网', '>>>', 'c.biancheng.net']
>>> list5 = str.split('>') #采用 > 字符进行分割
>>> list5
['C语言中文网 ', '', '', ' c.biancheng.net']
>>>
# 当字符串中有连续的空格或其他空字符时,都会被视为一个分隔符对字符串进行分割
>>> str = "C语言中文网 >>> c.biancheng.net" #包含 3 个连续的空格
>>> list6 = str.split()
>>> list6
['C语言中文网', '>>>', 'c.biancheng.net']
>>>
join()方法:合并字符串
join()方法合并字符串时,它会将列表(或元组)中多个字符串采用固定的分隔符连接在一起。
join()方法的语法格式如下:
newstr = str.join(iterable)
此方法中各参数的含义如下:
newstr:表示合并后生成的新字符串;str:用于指定合并时的分隔符;iterable:做合并操作的源字符串数据,允许以列表、元组等形式提供。
>>> list = ['c','biancheng','net']
>>> '.'.join(list)
'c.biancheng.net'
>>> dir = '','usr','bin','env'
>>> type(dir)
<class 'tuple'>
>>> '/'.join(dir)
'/usr/bin/env'
count()方法:统计字符串出现的次数
count方法用于检索指定字符串在另一字符串中出现的次数,如果检索的字符串不存在,则返回 0,否则返回出现的次数。
count方法的语法格式如下:
str.count(sub[,start[,end]])
此方法中,各参数的具体含义如下:
str:表示原字符串;sub:表示要检索的字符串;start:指定检索的起始位置,也就是从什么位置开始检测。如果不指定,默认从头开始检索;end:指定检索的终止位置,如果不指定,则表示一直检索到结尾。
>>> str = "c.biancheng.net"
>>> str.count('.')
2
>>> str = "c.biancheng.net"
>>> str.count('.',1)
2
>>> str.count('.',2)
1
find()方法:检测字符串中是否包含某子串
find()方法用于检索字符串中是否包含目标字符串,如果包含,则返回第一次出现该字符串的索引;反之,则返回 -1。
find()方法的语法格式如下:
str.find(sub[,start[,end]])
此格式中各参数的含义如下:
str:表示原字符串;sub:表示要检索的目标字符串;start:表示开始检索的起始位置。如果不指定,则默认从头开始检索;end:表示结束检索的结束位置。如果不指定,则默认一直检索到结尾。
>>> str = "c.biancheng.net"
>>> str.find('.')
1
>>> str = "c.biancheng.net"
>>> str.find('.',2)
11
>>> str = "c.biancheng.net"
>>> str.find('.',2,-4)
-1
index()方法:检测字符串中是否包含某子串
index()方法也可以用于检索是否包含指定的字符串, 同 find() 方法相比,不同之处在于,当指定的字符串不存在时,index()方法会抛出异常。
index()方法的语法格式如下:
str.index(sub[,start[,end]])
此格式中各参数的含义分别是:
str:表示原字符串;sub:表示要检索的子字符串;start:表示检索开始的起始位置,如果不指定,默认从头开始检索;end:表示检索的结束位置,如果不指定,默认一直检索到结尾。
>>> str = "c.biancheng.net"
>>> str.index('.')
1
>>> str = "c.biancheng.net"
>>> str.index('z')
Traceback (most recent call last):File "<pyshell#49>", line 1, in <module>str.index('z')
ValueError: substring not found
字符串对齐方法
ljust()方法
ljust()方法的功能是向指定字符串的右侧填充指定字符,从而达到左对齐文本的目的。
ljust()方法的基本格式如下:
S.ljust(width[, fillchar])
其中各个参数的含义如下:
S:表示要进行填充的字符串;width:表示包括S本身长度在内,字符串要占的总长度;fillchar:作为可选参数,用来指定填充字符串时所用的字符,默认情况使用空格。
S = 'http://c.biancheng.net/python/'
addr = 'http://c.biancheng.net'
print(S.ljust(35))
print(addr.ljust(35))
print(S.ljust(35,'-'))
print(addr.ljust(35,'-'))
输出结果为:
http://c.biancheng.net/python/ # 该输出结果中除了明显可见的网址字符串外,其后还有空格字符存在,每行一共 35 个字符长度。
http://c.biancheng.net
http://c.biancheng.net/python/-----
http://c.biancheng.net-------------
rjust()方法
rjust()和ljust()方法类似,唯一的不同在于,rjust()方法是向字符串的左侧填充指定字符,从而达到右对齐文本的目的。
rjust()方法的基本格式如下:
S.rjust(width[, fillchar])
每行字符串都占用 35 个字节的位置,实现了整体的右对齐效果。
S = 'http://c.biancheng.net/python/'
addr = 'http://c.biancheng.net'
print(S.rjust(35))
print(addr.rjust(35))
print(S.rjust(35,'-'))
print(addr.rjust(35,'-'))
输出结果为:
http://c.biancheng.net/python/http://c.biancheng.net
-----http://c.biancheng.net/python/
-------------http://c.biancheng.net
center()方法
center()字符串方法与ljust()和rjust()的用法类似,但它让文本居中,而不是左对齐或右对齐。
center()方法的基本格式如下:
S.center(width[, fillchar])
【例 5】
S = 'http://c.biancheng.net/python/'
addr = 'http://c.biancheng.net'
print(S.center(35,))
print(addr.center(35,))
print(S.center(35,'-'))
print(addr.center(35,'-'))
输出结果为:
http://c.biancheng.net/python/http://c.biancheng.net
---http://c.biancheng.net/python/--
-------http://c.biancheng.net------
检查字符串开头结尾
startswith()方法
startswith()方法用于检索字符串是否以指定字符串开头,如果是返回True;反之返回False。此方法的语法格式如下:
str.startswith(sub[,start[,end]])
此格式中各个参数的具体含义如下:
str:表示原字符串;sub:要检索的子串;start:指定检索开始的起始位置索引,如果不指定,则默认从头开始检索;end:指定检索的结束位置索引,如果不指定,则默认一直检索在结束。
>>> str = "c.biancheng.net"
>>> str.startswith("c")
True
>>> str = "c.biancheng.net"
>>> str.startswith("http")
False
>>> str = "c.biancheng.net"
>>> str.startswith("b",2)
True
endswith()方法
endswith()方法用于检索字符串是否以指定字符串结尾,如果是则返回True;反之则返回False。该方法的语法格式如下:
str.endswith(sub[,start[,end]])
此格式中各参数的含义如下:
str:表示原字符串;sub:表示要检索的字符串;start:指定检索开始时的起始位置索引(字符串第一个字符对应的索引值为 0),如果不指定,默认从头开始检索。end:指定检索的结束位置索引,如果不指定,默认一直检索到结束。
>>> str = "c.biancheng.net"
>>> str.endswith("net")
True
字符串大小写转换
title()方法
title()方法用于将字符串中每个单词的首字母转为大写,其他字母全部转为小写,转换完成后,此方法会返回转换得到的字符串。如果字符串中没有需要被转换的字符,此方法会将字符串原封不动地返回。
title()方法的语法格式如下:
str.title()
其中,str表示要进行转换的字符串。
>>> str = "c.biancheng.net"
>>> str.title()
'C.Biancheng.Net'
>>> str = "I LIKE C"
>>> str.title()
'I Like C'
lower()方法
lower()方法用于将字符串中的所有大写字母转换为小写字母,转换完成后,该方法会返回新得到的字符串。如果字符串中原本就都是小写字母,则该方法会返回原字符串。
lower()方法的语法格式如下:
str.lower()
其中,str表示要进行转换的字符串。
>>> str = "I LIKE C"
>>> str.lower()
'i like c'
upper()方法
upper()的功能用于将字符串中的所有小写字母转换为大写字母,和以上两种方法的返回方式相同,即如果转换成功,则返回新字符串;反之,则返回原字符串。
upper()方法的语法格式如下:
str.upper()
其中,str表示要进行转换的字符串。
>>> str = "i like C"
>>> str.upper()
'I LIKE C'
去除字符串中空格
Python 中,字符串变量提供了3种方法来删除字符串中多余的空格和特殊字符,它们分别是:
strip():删除字符串前后(左右两侧)的空格或特殊字符。lstrip():删除字符串前面(左边)的空格或特殊字符。rstrip():删除字符串后面(右边)的空格或特殊字符。
注意,Python的str是不可变的(不可变的意思是指,字符串一旦形成,它所包含的字符序列就不能发生任何改变),因此这三个方法只是返回字符串前面或后面空白被删除之后的副本,并不会改变字符串本身。
strip()方法
strip()方法用于删除字符串左右两个的空格和特殊字符,该方法的语法格式为:
str.strip([chars])
其中,str表示原字符串,[chars]用来指定要删除的字符,可以同时指定多个,如果不手动指定,则默认会删除空格以及制表符、回车符、换行符等特殊字符。
>>> str = " c.biancheng.net \t\n\r"
>>> str.strip()
'c.biancheng.net'
>>> str.strip(" ,\r")
'c.biancheng.net \t\n'
>>> str # 通过 strip() 确实能够删除字符串左右两侧的空格和特殊字符,但并没有真正改变字符串本身。
' c.biancheng.net \t\n\r'
lstrip()方法
lstrip()方法用于去掉字符串左右的空格和特殊字符。该方法的语法格式如下:
str.lstrip([chars])
其中,str和chars参数的含义,分别同strip()语法格式中的str和chars完全相同。
>>> str = " c.biancheng.net \t\n\r"
>>> str.lstrip()
'c.biancheng.net \t\n\r'
rstrip()方法
rstrip()方法用于删除字符串右侧的空格和特殊字符,其语法格式为:
str.rstrip([chars])
str和chars参数的含义和前面 2 种方法语法格式中的参数完全相同。
>>> str = " c.biancheng.net \t\n\r"
>>> str.rstrip()
' c.biancheng.net'
格式化输出
占位符%格式化输出
输出标准:
%:表示格式说明的起始符号,不能省略- ``:有-b表示左对其输出,右边补空格,如省略表示右对齐,左边补空格
0:有0表示指定空格填0,如省略指定空格不填。m.n:·m·指域宽,即对应的输出项在输出设备上所占的字符数。n指精度,用于说明输出的实形数小数点位。未指定n,浮点型默认精度为n = 6位
格式符用以指定输出项的数据类型和输出格式
-
整数
%d格式:用来输出十进制整数。有以下用法:%d:按整形数据的实际长度输出%md:m为指定的输出字段的宽度。如果m>实际数据位数,左端补空格,如果m<实际数据位数,则按实际位数输出。
a=1000print("a : %d; b : %10d" % (a, a)) # 输出:a : 1000; b : 1000 -
字符串
%s格式:用来输出一个字符串%s:输出整个字符串%ms:输出的字符串占m列,如果字符串本身长度大于m,则全部输出,如果小于m,则左边补空格%-ms:如果串长小于m,则在m的范围内,字符串向左靠,右补空格%m.ns:输出占m列,但是只取字符串左端n个字符。这n个字符输出在m列的右侧,左边补空格。如果n > m,自动取n值,保证n个字符正常输出。%-m.ns:m,n含义同上,n个字符输出在m列范围的左侧,右补空格。如果n > m,自动取n值,保证n个字符正常输出。
a=1000 b="hellworld"print('a : %d; b : %10d' % (a, a)) # 输出:a : 1000; b : 1000 print("str1:%s;" % (b)) # 输出:str1:hellworld; print("str2:%12s; str3:%5s" % (b, b)) # 输出:str2: hellworld; str3:hellworld; print("str4:%-12s; str5:%-5s" % (b, b)) # 输出:str4:hellworld ; str5:hellworld; print("str6:%5.8s; str7:%5.3s" % (b, b)) # 输出:str6:hellworl; str7: hel; print("str8:%-5.8s; str9:%-5.3s" % (b, b)) # 输出:str8:hellworl; str9:hel ; -
浮点型
%f格式: 用来输出一个浮点型数值%f:不指定宽度,整数部分全部输出,并输出6个小数位。%m.nf:输出共占m列,其中有n个小数,若输出数值(即n+整数部分+小数点1)宽度小于m左侧补空格。%-m.nf:输出共占m列,其中有n位小数,若输出数值宽度(即n+整数部分+小数点1)小于m右端补空格。
c=1314.1415926 print("float1:%f" % (c)) # 输出:float1:1314.141593 print("float2:%8.2f; float3:%8.5f;" % (c, c)) # 输出:float2: 1314.14; float3:1314.14159; print("float4:%-8.2f; float5:%-8.5f;" % (c, c)) # 输出:float4:1314.14 ; float5:1314.14159;
format()格式化输出
基本格式
把传统的%替换为{}来实现格式化输出 。format()方法的语法格式如下:
str.format(args)
此方法中,str用于指定字符串的显示样式;args用于指定要进行格式转换的项,如果有多项,之间有逗号进行分割。
在创建str显示样式模板时,需要使用{}和:来指定占位符,其完整的语法格式为:
{ [index][ : [ [fill] align] [sign] [#] [width] [.precision] [type] ] }
注意,格式中用 [] 括起来的参数都是可选参数,即可以使用,也可以不使用。各个参数的含义如下:
-
index:指定:后边设置的格式要作用到args中第几个数据,数据的索引值从 0 开始。如果省略此选项,则会根据args中数据的先后顺序自动分配。 -
fill:指定空白处填充的字符。注意,当填充字符为逗号(,)且作用于整数或浮点数时,该整数(或浮点数)会以逗号分隔的形式输出,例如(1000000会输出 1,000,000)。 -
align:指定数据的对齐方式,具体的对齐方式如表 1 所示。align 含义 < 数据左对齐。 > 数据右对齐。 = 数据右对齐,同时将符号放置在填充内容的最左侧,该选项只对数字类型有效。 ^ 数据居中,此选项需和width参数一起使用。 -
sign:指定有无符号数,此参数的值以及对应的含义如表 2 所示。sign参数 含义 + 正数前加正号,负数前加负号。 - 正数前不加正号,负数前加负号。 空格 正数前加空格,负数前加负号。 # 对于二进制数、八进制数和十六进制数,使用此参数,各进制数前会分别显示0b、0o、0x前缀;反之则不显示前缀。 -
width:指定输出数据时所占的宽度。 -
.precision:指定保留的小数位数。 -
type:指定输出数据的具体类型,如表 3 所示。type类型值 含义 s 对字符串类型格式化。 d 十进制整数。 c 将十进制整数自动转换成对应的Unicode字符。 e或者E 转换成科学计数法后,再格式化输出。 g或G 自动在e和f(或E和F)中切换。 b 将十进制数自动转换成二进制表示,再格式化输出。 o 将十进制数自动转换成八进制表示,再格式化输出。 x或者X 将十进制数自动转换成十六进制表示,再格式化输出。 f或者F 转换为浮点数(默认小数点后保留 6 位),再格式化输出。 % 显示百分比(默认显示小数点后 6 位)。
代码示例
基本用法
print('{} {}'.format('hello', 'world')) # 最基本的print('{0} {1}'.format('hello', 'world')) # 通过位置参数print('{0} {1} {0}'.format('hello', 'world')) # 单个参数多次输出"""输出结果
hello world
hello world
hello world hello
"""
关键词定位
# 通过关键词参数
print('我的名字是{name},我今年{age}岁了。'.format(name='Linda', age='18'))# 与位置参数一样,单个参数也能多次输出
print('{name}说:"我的名字是{name},我今年{age}岁了。"'.format(name='linda', age='18'))"""输出结果
我的名字是linda,我今年18岁了。
linda说:"我的名字是Linda,我今年18岁了。"
"""
固定宽度/填充/对齐方式
data = [{'name': 'Mary', 'college': 'Tsinghua University'},{'name': 'Micheal', 'college': 'Harvard University'},{'name': 'James', 'college': 'Massachusetts Institute of Technology'}]print('{:-^50}'.format('居中'))
for item in data:print('{:^10}{:^40}'.format(item['name'], item['college']))print('{:-^50}'.format('左对齐'))
for item in data:print('{:<10}{:<40}'.format(item['name'], item['college']))print('{:-^50}'.format('右对齐'))
for item in data:print('{:>10}{:>40}'.format(item['name'], item['college']))"""输出结果
------------------------居中------------------------Mary Tsinghua UniversityMicheal Harvard UniversityJames Massachusetts Institute of Technology
-----------------------左对齐------------------------
Mary Tsinghua University
Micheal Harvard University
James Massachusetts Institute of Technology
-----------------------右对齐------------------------Mary Tsinghua UniversityMicheal Harvard UniversityJames Massachusetts Institute of Technology
"""
数字格式化
# 取小数点后两位
num = 3.1415926
print('小数点后两位:{:.2f}'.format(num)) # 输出结果 -> 小数点后两位:3.14# 带+/-输出
num = -3.1415926
print('带正/负符号:{:+.2f}'.format(num)) # 输出结果 -> 带正/负符号:-3.14# 转为百分比
num = 0.34534
print('百分比:{:.2%}'.format(num)) # 输出结果 -> 百分比:34.53%# 科学计数法
num = 12305800000
print('科学计数法:{:.2e}'.format(num)) # 输出结果 -> 科学计数法:1.23e+10# ,分隔
num = 12305800000
print('","分隔:{:,}'.format(num)) # 输出结果 -> ","分隔:12,305,800,000# 转为二进制
num = 15
print('二进制:{:b}'.format(num)) # 输出结果 -> 二进制:1111# 十六进制
num = 15
print('十六进制:{:x}'.format(num)) # 输出结果 -> 十六进制:f# 八进制
num = 15
print('八进制:{:o}'.format(num)) # 输出结果 -> 八进制:17
推导式
Python推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。它是一种强大且简洁的语法,适用于生成列表、字典、集合和生成器。同时,在使用推导式时,需要注意可读性,尽量保持表达式简洁,以免影响代码的可读性和可维护性。
列表推导式
列表推导式格式为:
[表达式 for 变量 in 列表]
[out_exp_res for out_exp in input_list]或者[表达式 for 变量 in 列表 if 条件]
[out_exp_res for out_exp in input_list if condition]
参数说明:
out_exp_res:列表生成元素表达式,可以是有返回值的函数。for out_exp in input_list:迭代input_list将out_exp传入到out_exp_res表达式中。if condition:条件语句,可以过滤列表中不符合条件的值。
字典推导式
字典推导基本格式:
{ key_expr: value_expr for value in collection }或{ key_expr: value_expr for value in collection if condition }
集合推导式
集合推导式基本格式:
{ expression for item in Sequence }
或
{ expression for item in Sequence if conditional }
元组推导式(生成器表达式)
元组推导式可以利用range区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
元组推导式基本格式:
(expression for item in Sequence )
或
(expression for item in Sequence if conditional )
元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 () 圆括号将各部分括起来,而列表推导式用的是中括号 [],另外元组推导式返回的结果是一个生成器对象。

![电影《抓娃娃》迅雷BT完整下载[MP4/2.12GB/5.38GB]高清版画质百度云资源[1080p]](https://img2024.cnblogs.com/blog/3033733/202407/3033733-20240713101028355-876455328.png)


![P2120 [ZJOI2007] 仓库建设](https://img2024.cnblogs.com/blog/3069332/202407/3069332-20240713093541803-2071893940.png)