# 免责声明:本文内容主要是肥清大神的视频以及自己收集学习内容的整理笔记,目是主要是为了让博主这样的老白能更好的学习编程,如有侵权,请联系博主进行删除。
10. 封装的故事
# 封装在面向对象开发里是最基础的一环* 传统的开发会遇到不注重封装的情况* 对这类的 legacy 的代码维护就会麻烦很多* 容易产生意大利面条式的凌乱纠缠不清的代码* 不要说维护, 阅读都难
# 封装也体现了开发人员在业务领域的专业度, 对业务理解的程度越深, 封装就越到位, 内聚性就越高* 这些都是需要时间来积累的
10.1. 类的封闭
# 通过封装, 可以把业务知识内聚在类里面, 对外暴露较少知识的接口* 方便调用* 提高了代码的维护性/可读性/扩展性
# 通过封装, 可以做到高内聚, 也容易达到低耦合的境界
10.1.1. 实例对比
10.1.1.1. 要求
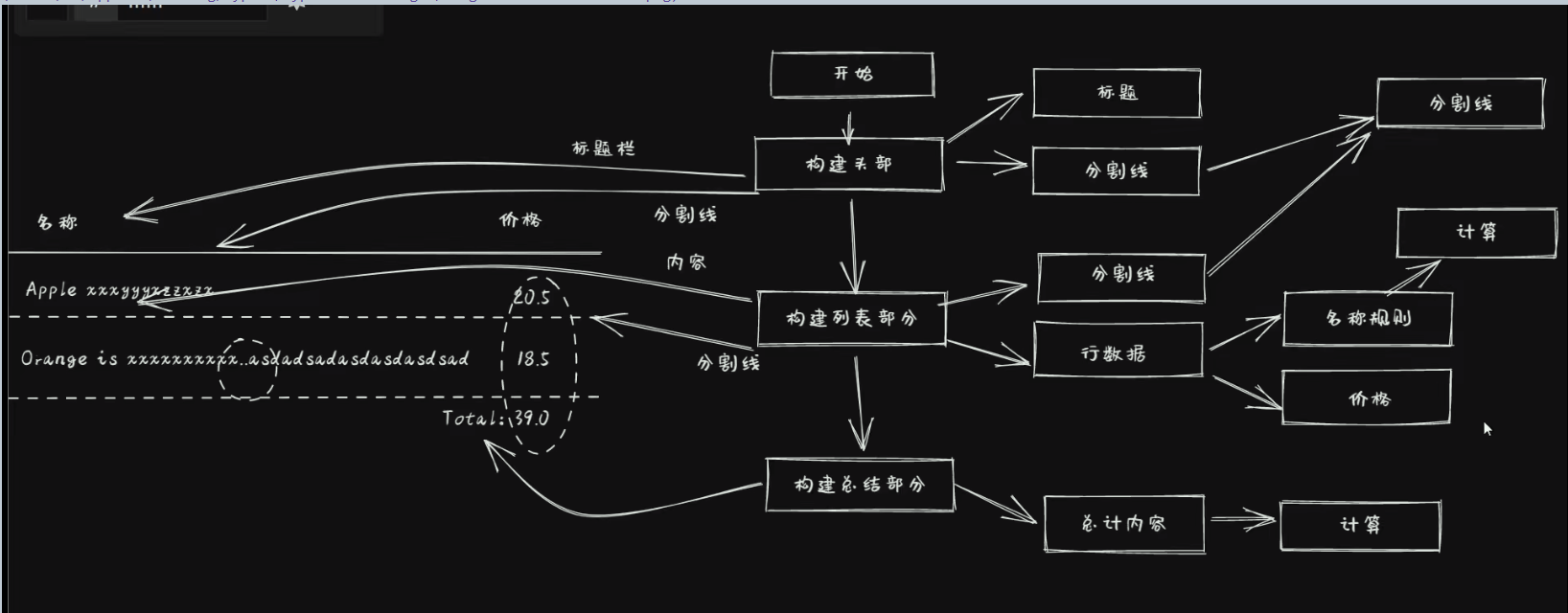
10.1.1.2. 坏味道
from typing import Optionalclass Product:def __init__(self, name: str, price: float) -> None:self.name = nameself.price = pricedef generate_repoart(products: list[Product],name_list_length: Optional[int] = 40,price_length: Optional[int] = 10,
) -> None:'''承担了太多职能可读性/可维护性/可扩展太差'''total_length = name_list_length + price_length# 1. 输出头部header = f'{"名称":^{name_list_length}}{"价格":^{price_length}}'header_spliter = '_' * total_lengthprint(header)print(header_spliter)# 2. 输出列表主体for product in products:half_text_width = int((name_list_length/2)-1)name_length = len(product.name)left_text = product.name[:half_text_width]right_text = product.name[-half_text_width:]name = f'{left_text}..{right_text}' \if name_length > name_list_length else product.nameprice = str(product.price)print(f'{name:<{name_list_length}}{price:>{price_length}}')line_spliter = '-' * total_lengthprint(line_spliter)# 3. 输出统计结果sumerize_price = sum([product.price for product in products])total_price = f'Totla: {sumerize_price}'print(f'{total_price:>{total_length}}')data = ({'name': 'Apple is a super good fruit','price': 45.3,},{'name': 'Orange is xxxxxxxxxxxxxxxxxxxxxxx','price': 18.5,},
)products = [Product(**item) for item in data]
generate_repoart(products, name_list_length=20, price_length=20)
10.1.1.3. 美味
# ProductReporter 例子的输出器部分的重构渗透了不要过多预先设计的坏习惯
# 任何技术的变更都应该服务于业务, 以业务为中心的原则 from typing import Optionalclass Product:def __init__(self, name: str, price: float) -> None:self.name = nameself.price = priceclass ProductReporter:# 限定值最好都定义成常量# 有问题时好修改# 下端代码不用修改NAME_LIST_LENGTH: int = 40PRICE_LENGTH: int = 10COL_NAME: str = 'NAME'COL_PRICE: str = 'PRICE'HEADER_SPLITER_CHARACTER = '_'LINE_SPLITER_CHARACTER = '-'def __init__(self,products: list[Product],name_list_length: Optional[int] = NAME_LIST_LENGTH,price_length: Optional[int] = PRICE_LENGTH,col_name: Optional[str] = COL_NAME,col_price: Optional[str] = COL_PRICE,header_spliter_character: Optional[str] = HEADER_SPLITER_CHARACTER,line_spliter_character: Optional[str] = LINE_SPLITER_CHARACTER) -> None:self.products = productsself.name_list_length = name_list_lengthself.price_length = price_lengthself.col_name = col_nameself.col_price = col_priceself.header_spliter_character = header_spliter_characterself.line_spliter_character = line_spliter_character# 获取分隔线的公共方法def _get_spliter(self, spliter_character: str) -> str:size = self.name_list_length + self.price_lengthreturn spliter_character * size# 以下用于输出总计def _get_sumerize(self, total_price: float) -> str:return f'Total: {total_price:>{self.price_length}}'def _get_total_price(self) -> float:return sum([product.price for product in self.products])def _output_sumerize(self) -> None:# 1. 获取总价total_price = self._get_total_price()# 2. 产生输出内容字符串sumerize_content = self._get_sumerize(total_price)# 3. 输出total_length = self.name_list_length + self.price_lengthprint(f'{sumerize_content:>{total_length}}')# 以上总计# 以下输出列表内容def _get_line_spliter(self) -> str:return self._get_spliter(self.line_spliter_character)def _get_line_item(self, name: str, price: str) -> str:return f'{name:<{self.name_list_length}}{price:>{self.price_length}}'def _output_line_item(self, name: str, price: str) -> None:# 1. 获取每行的输出字符串line_item = self._get_line_item(name, price)print(line_item)# 2. 获取分隔符spliter = self._get_line_spliter()print(spliter)@staticmethoddef _handle_product_price(product: Product) -> str:return str(product.price)def _handle_product_name(self, product: Product) -> str:name_length = len(product.name)half_text_width = int((self.name_list_length / 2) - 1)left_characters = product.name[:half_text_width]right_characters = product.name[-half_text_width:]# TODO: 产品名称长于规定长度时, 左右各取规定长度, 中间用 <..>连接name = f'{left_characters}..{right_characters}' \if name_length > self.name_list_length else product.namereturn namedef _output_list_item(self) -> None:for product in self.products:# 1. 处理名称, 控制字符在40个(或规定长度), 按照规则处理name = self._handle_product_name(product)# 2. 处理价格price = self._handle_product_price(product)# 3. 输出self._output_line_item(name, price)# 以上列表内容# 以下输出头部def _get_header_spliter(self) -> str:return self._get_spliter(self.header_spliter_character)def _get_header(self) -> str:return f'{self.col_name:^{self.name_list_length}}' \f'{self.col_price:^{self.price_length}}'def _output_header(self) -> None:# 获取标题内容header = self._get_header()# 输出print(header)# 获取分割线spliter = self._get_header_spliter()print(spliter)# 以上用于头部输出# 用户接口def report(self):# 1. 输出头部self._output_header()# 2. 输出列表内容self._output_list_item()# 3. 输出统计部分self._output_sumerize()data = ({'name': 'Apple is a super good fruit','price': 45.3,},{'name': 'Orange is xxxxxxxxxxxxxxxxxxxxxxx','price': 18.5,},
)products = [Product(**item) for item in data]product_reporter = ProductReporter(products)
product_reporter.report()
10.2. 类的解耦
# 高内聚, 低耦合是理想的系统设计的目标
# 低耦合也就是解耦的工作* 需要坚持的原则是依赖抽象, 不依赖实现* 上次 ProductReporter 例子的输出器部分的重构让大家看到如何去做解耦的方式与思路* 健状的业务模块要独立于任何系统(有点难????)* 例子中的输出依靠 print() 语句就是对系统的强依赖* 注意 YAGNI * You arn't gonna need it
10.2.1. 实例要求
# 继续使用上例, 增加需要求* 要求能增加输出到其他目标的功能* OutPuter 这一部分使用了 工厂方法模式
10.2.2. 实现 UML
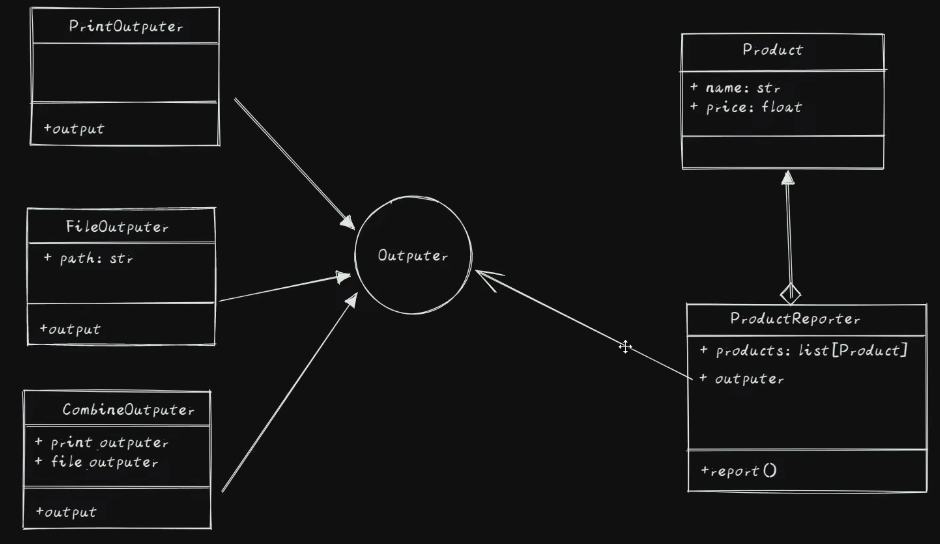
10.2.3. 实现代码
import json
from typing import Optionalfrom outputer_factory import OutputerFactory
from outputer_product import (Outputer,PrintOutputer,FileOutputer,CombineOutputer,
)class Product:def __init__(self, name: str, price: float) -> None:self.name = nameself.price = priceclass ProductReporter:# 限定值最好都定义成常量# 有问题时好修改# 下端代码不用修改NAME_LIST_LENGTH: int = 40PRICE_LENGTH: int = 10COL_NAME: str = 'NAME'COL_PRICE: str = 'PRICE'HEADER_SPLITER_CHARACTER = '_'LINE_SPLITER_CHARACTER = '-'def __init__(self,products: list[Product],outputer: Outputer,name_list_length: Optional[int] = NAME_LIST_LENGTH,price_length: Optional[int] = PRICE_LENGTH,col_name: Optional[str] = COL_NAME,col_price: Optional[str] = COL_PRICE,header_spliter_character: Optional[str] = HEADER_SPLITER_CHARACTER,line_spliter_character: Optional[str] = LINE_SPLITER_CHARACTER) -> None:self.products = productsself.outputer = outputerself.name_list_length = name_list_lengthself.price_length = price_lengthself.col_name = col_nameself.col_price = col_priceself.header_spliter_character = header_spliter_characterself.line_spliter_character = line_spliter_character# 定义输出的公共方法def _output(self, content: str) -> None:self.outputer.output(content)# 获取分隔线的公共方法def _get_spliter(self, spliter_character: str) -> str:size = self.name_list_length + self.price_lengthreturn spliter_character * size# 以下用于输出总计def _get_sumerize(self, total_price: float) -> str:return f'Total: {total_price:>{self.price_length}}'def _get_total_price(self) -> float:return sum([product.price for product in self.products])def _output_sumerize(self) -> None:# 1. 获取总价total_price = self._get_total_price()# 2. 产生输出内容字符串sumerize_content = self._get_sumerize(total_price)# 3. 输出total_length = self.name_list_length + self.price_lengthself._output(f'{sumerize_content:>{total_length}}')# 以上总计# 以下输出列表内容def _get_line_spliter(self) -> str:return self._get_spliter(self.line_spliter_character)def _get_line_item(self, name: str, price: str) -> str:return f'{name:<{self.name_list_length}}{price:>{self.price_length}}'def _output_line_item(self, name: str, price: str) -> None:# 1. 获取每行的输出字符串line_item = self._get_line_item(name, price)self._output(line_item)# 2. 获取分隔符spliter = self._get_line_spliter()self._output(spliter)@staticmethoddef _handle_product_price(product: Product) -> str:return str(product.price)def _handle_product_name(self, product: Product) -> str:name_length = len(product.name)half_text_width = int((self.name_list_length / 2) - 1)left_characters = product.name[:half_text_width]right_characters = product.name[-half_text_width:]name = f'{left_characters}..{right_characters}' \if name_length > self.name_list_length else product.namereturn namedef _output_list_item(self) -> None:for product in self.products:# 1. 处理名称, 控制字符在40个(或规定长度), 按照规则处理name = self._handle_product_name(product)# 2. 处理价格price = self._handle_product_price(product)# 3. 输出self._output_line_item(name, price)# 以上列表内容# 以下输出头部def _get_header_spliter(self) -> str:return self._get_spliter(self.header_spliter_character)def _get_header(self) -> str:return f'{self.col_name:^{self.name_list_length}}' \f'{self.col_price:^{self.price_length}}'def _output_header(self) -> None:# 获取标题内容header = self._get_header()# 输出self._output(header)# 获取分割线spliter = self._get_header_spliter()self._output(spliter)# 以上用于头部输出# 用户接口def report(self):# 1. 输出头部self._output_header()# 2. 输出列表内容self._output_list_item()# 3. 输出统计部分self._output_sumerize()# 定义配置文件
def load_setting_from_json(filename: str = 'outputer_setting_json.json'):with open(filename) as f:return json.load(f)def main(setting_data:dict) -> None:data = ({'name': 'Apple is a super good fruit','price': 45.3,},{'name': 'Orange is xxxxxxxxxxxxxxxxxxxxxxx','price': 18.5,},)_setting_data = setting_data.copy()outputer_factory = OutputerFactory()outputer_factory.register('print', PrintOutputer)outputer_factory.register('file', FileOutputer)for args in _setting_data['outputer']:outputer = outputer_factory.create_outputer(args)print(outputer)products = [Product(**item) for item in data]product_reporter = ProductReporter(products, outputer)product_reporter.report()if __name__ == "__main__":setting_data = load_setting_from_json()main(setting_data)
# outputer_setting_json.json
# list 有 copy() 方法{"outputer": [{"kind": "print"}]}
# outputer_product.pyfrom abc import ABC, abstractmethod
from typing import Optionalclass Outputer(ABC):@abstractmethoddef output(self, content: str) -> None:""" 输出给定的内容 """passclass PrintOutputer(Outputer):def output(self, content: str) -> None:print(content)class FileOutputer(Outputer):DEFAULT_PATH: str = 'outputer_product_report.txt'def __init__(self, path: Optional[str] = DEFAULT_PATH) -> None:self.path = pathdef output(self, content: str) -> None:with open(self.path, 'a') as f:f.write(f'{content}\n')class CombineOutputer(Outputer):def __init__(self) -> None:self._print_outputer = PrintOutputer()self._file_outputer = FileOutputer()def output(self, content: str) -> None:self._print_outputer.output(content)self._file_outputer.output(content)
# outputer_factory.pyfrom abc import ABC, abstractmethod
from typing import Any
from collections.abc import Callablefrom outputer_product import Outputer, PrintOutputer, FileOutputer, CombineOutputerclass IFactory(ABC):def __init__(self):self.outputer_create_functions: dict[str, Callable[..., Player]] = {}@abstractmethoddef register(self) -> None:pass@abstractmethoddef unregister(self) -> None:pass@abstractmethoddef create_outputer(self):passclass OutputerFactory(IFactory):def register(self, kind: str, creation_function: Callable[..., Outputer]) -> None:self.outputer_create_functions[kind] = creation_functiondef unregister(self, kind: str) -> None:self.outputer_create_functions.pop(kind, None)def create_outputer(self, args: dict[str, Any]) -> Outputer:# 一个编程习惯# 防止原参数修改后产生不利影响# 对原参数的一种保护# 参数尽可能都是只读的_args = args.copy()_kind = _args['kind']try:create_function = self.outputer_create_functions[_kind]return create_function()except KeyError:raise ValueError(f'未知的输出目标 {_kind}') from None
10.3. 恰如其分的封装
# Python 将模块视为封装单元, 而不是实际的类
# 通过类来封装有业务意义的模型* 有属性* 有行为* 有状态记忆
# 对于没有状态且不共享的, 但是又和业务有关联的工具类* 可以聚合在类之中, 成为类的方法或静态方法* 归属类管理, 方便维护和阅读* 避免多余的外部 import
# 将<无状态的><通用的><功能性的>工具封装在模块内, 通过提供相应的方法来完成工具功能* 模块把无状态组合的函数组合* 有行为* 无属性* 无状态* 无记忆* 用完即抛
10.3.1. Java 方式
# 过度封装
# NetworkUtils 可使用模块来代替
class NetworkUtils:HOST_NAME: str = 'xxxxxx'@classmethoddef ping(cls, ip: str) -> None:print(f'ping {ip}')@classmethoddef scan(cls, ip_range) -> None:print(f'scan {ip_range}')class SomeBusiness:def some_method(self) -> None:NetworkUtils.ping('xxx.xxx.xxx.xxx')NetworkUtils.scan('xxx.xxx.xxx.xxx')
10.3.2. pythonic
# 通用工具模块化
# network_utils.pydef ping(ip: str) -> None:print(f'ping {ip}')def scan(ip_range: str) -> None:print(f'scan {ip_range}')
from network_utils import ping, scanclass SomeBusiness:def some_method(self) -> None:ping('xxx.xxx.xxx.xxx')scan('xxx.xxx.xxx.xxx')
10.4. 分离关注点
10.4.1. MVP 模式
# 对于 UI 关联的代码, 很多 Legacy 的项目都会把所有的关注点如数据处理 | UI呈现 | 协调处理器 | 安全处理 | 验证 | 日志等等的关注点混合在一起实现, 写在很长的代码段中实现* 虽然代码可以运行, 但是潜在的风险很大, 而且不易于维护扩展, 对测试的编写也不友好
# 做好分离关注点的工作, 可以提高代码的质量, 增强代码的健壮性, 可维护性, 可测试性* 关注点: 具体要做的专业层面的事情* UI* Dataplayer* Security* Validation* Logging
# 通过 MVP 模式进行分离关注点, 可以达到解耦与单一职责的目的
* model-view-presenter* 无论对测试还是代码质量以及维护性、扩展性都是质的飞跃
# MVP模式多用于UI的端应用, 也可以用于某些Web的框架* 譬如移动端* PC 端的客户端程序
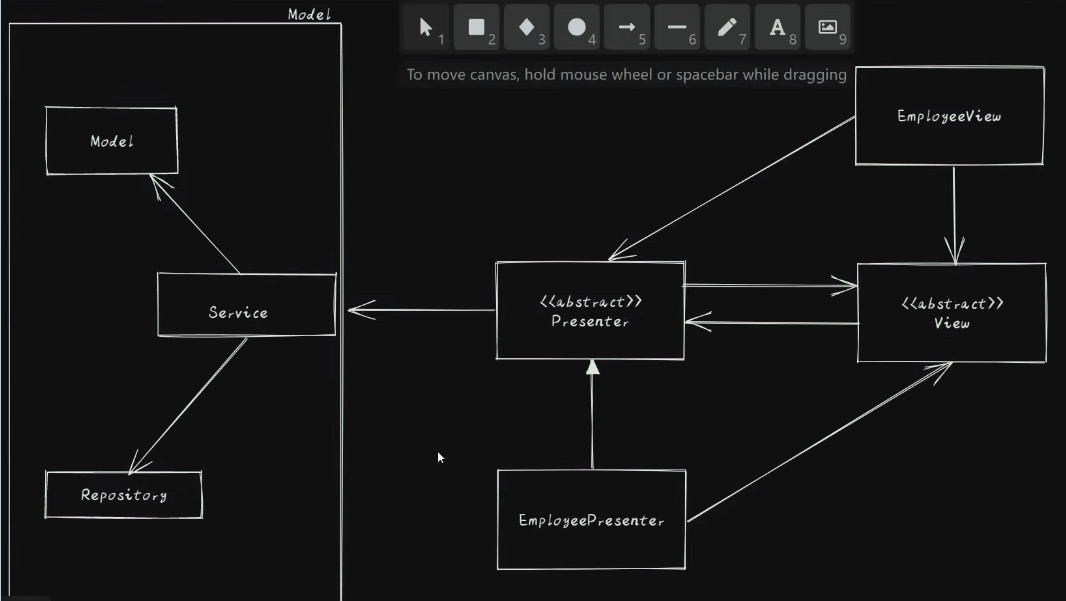
10.4.1.1. 模式图
# MVP<Model View Presenterf>模式是 MVC 的一个演化版本* 解除 View 与 Model 的耦合* 分离显示层与逻辑层* 以上两部分之间通过接口进行通讯以降低耦合
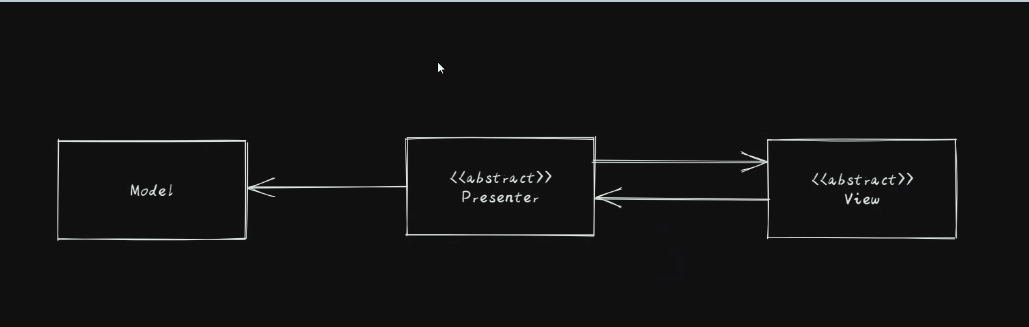
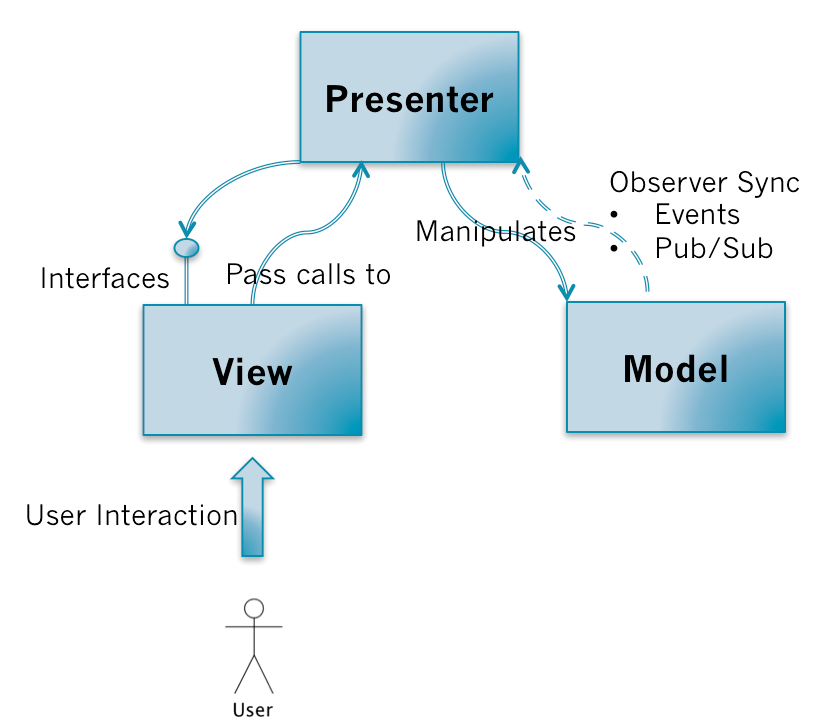
10.4.1.2. 核心组件
10.4.1.2.1. Presenter
# 交互中间人: 沟通View与Model的桥梁* 从 Model 层检索出数据后返回给 View 层* 使得 View 与 Model 之间没有耦合
10.4.1.2.2. View
# 用户界面: 通常是指 Activity | Fragment 或者某个 View 控件* 含有一个 Presenter 成员变量* 通常需要实现一个逻辑接口* 将 View 的操作转交给 Presenter 进行实现* Presenter 通过调用 View 逻辑接口将结果返回给 View 元素
10.4.1.2.3. Model
# 数据存取: 封装了数据库 DAO | 网络获取数据的角色, 负责数据存取* Presenter 通过 Model 层存储获取数据* Model 就像一个数据仓库* 对应用程序的业务逻辑无知* 只保存数据结构和提供数据操作的接口
10.4.1.3. 实现
10.4.1.3.1. 要求
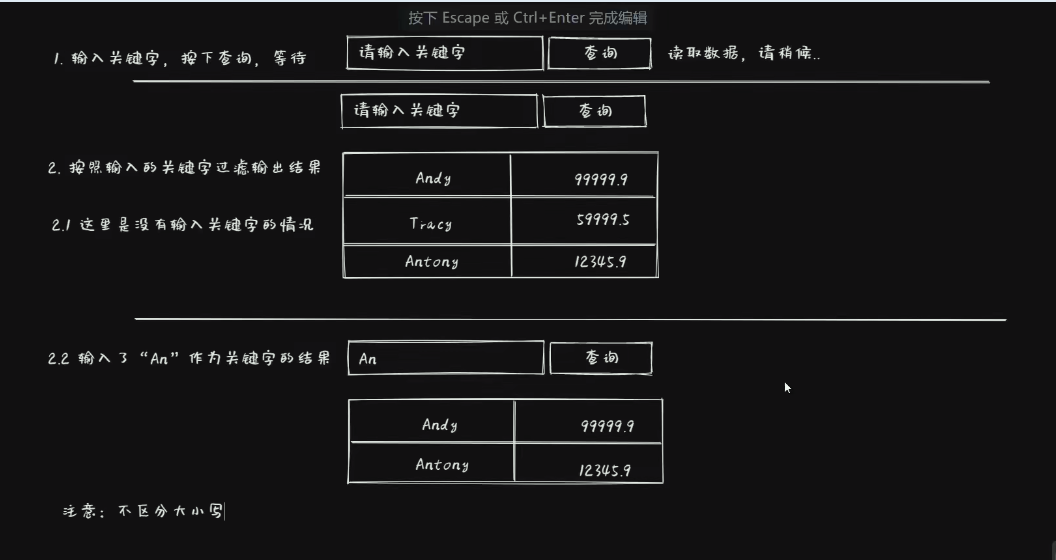
10.4.1.3.2. 关键

10.4.1.3.3. 坏味道
import timefrom pandas import DataFrame
from ipywidgets import Text, Button, Label, HBox, Output
from IPython.display import display
from collections import defaultdictclass Employee:def __init__(self, name: str, salary: float) -> None:self.name = nameself.salary = salaryclass Application:def __init__(self, employees: list[Employee]) -> None:self._employees = employeesself._container: HBox = Noneself._keyword_textbox: Text = Noneself._search_button: Button = Noneself._status: Label = Noneself._output: Output = Noneself._initialize_view()def _query_employees(self) -> dict[str, list[str, float]]:result = defaultdict(list)for employee in self.employees:if self._keyword_textbox.value.lower() in employee.name.lower():result['name'].append(employee.name)result['salary'].append(employee.salary)# 模拟获取数据的延迟time.sleep(1)return resultdef _on_click(self, *args) -> None:# 显示进度信息self._status.value = '读取数据, 请稍候...'# 获取数据data = self._query_employees()# 隐藏进度信息self._status.value = ''# 绑定列表df = DataFrame(data)# 呈现列表with self._output:self._output.clear_output()display(df)def _bind_event(self) -> None:self._search_button.on_click(self._on_click)def _initialize_view(self) -> None:self._keyword_textbox = Text(value = '',placeholder = '请输入关键字',description = '关键字')self._search_button = Button(descripton = '查询',button_style = 'info',tooltip = '查询',icon = 'search')self._status = Label()self._container = HBox((self._keyword_textbox, self._search_button, self._status))self._output = Output()self._bind_event()def run(self) -> None:display(self._container, self._output)data = [('Andy', 99999.9), ('Tracy', 55555.8), ('Antony', 12345.9)]
employees = [Employee(*entry) for entry in data]app = Application(employees)
app.run()
10.4.1.3.4. 美味
import timefrom pandas import DataFrame
from ipywidgets import Text, Button, Label, HBox, Output
from IPython.display import display
from collections import defaultdict
from abc import ABC, abstractmethodclass Employee:def __init__(self, name: str, salary: float) -> None:self.name = nameself.salary = salaryclass EmployeeRepository(ABC):''' 数据查询结果的抽象 '''@abstractmethoddef query_employees(self, keyword: str) -> list[Employee]:passclass MemoryEmployeeRepository(EmployeeRepository):'''在 employees 数据源里进按 keyword 进行查询返回符合要求的 Employee 列表'''employees: list[Employee] = [Employee('Andy', 99999.9),Employee('Tracy', 55555.9),Employee('Antony', 12345.8)]def query_employees(self, keyword: str) -> list[Employee]:# 返回符合姓名要求的结果return [employee for employee in self.employeesif keyword.lower() in employee.name.lower()]class EmployeeService:''' 返回符合要求的 defaultdict '''def __init__(self, employee_respository: EmployeeRepository) -> None:# 实际代入的是 MemoryEmployeeReposity# 这就是依赖抽象吗??self._employee_respository = employee_respositorydef query_employees_data(self, keyword: str) -> dict[str, list[str, float]]:employees = self._employee_respository.query_employees(keyword)result = defaultdict(list)for employee in employees:result['name'].append(employee.name)result['salary'].append(employee.salary)return resultclass Presenter(ABC):''' 中间层 抽象 '''@property@abstractmethoddef employee_view(self):'''通过此方法与 View 层 相关联'''pass@employee_view.setterdef employee_view(self, view):pass@abstractmethoddef search(self, keyword: str) -> None:'''通过此方法联系 View 层和 Model 层接收 View 层的请求数据将此请求传递给 Model接收 Model 层传递回的结果数据将此结果传递给 View 进行显示'''raise NotImplemented('search() method must be overridden!')@abstractmethoddef display(self) -> None:'''用于显示 View 层 UI'''passclass EmployeePresenter(Presenter):def __init__(self, employee_service: EmployeeService) -> None:self._employee_service = employee_serviceself._employee_view = None@propertydef employee_view(self):return self._employee_view@employee_view.setterdef employee_view(self, view):self._employee_view = viewdef search(self, keyword: str) -> None:# 显示进度信息self.employee_view.show_status()# 获取数据data = self._employee_service.query_employees_data(keyword)# 模拟延迟time.sleep(1)# 隐藏进度信息self.employee_view.hide_status()# 绑定和呈现列表self.employee_view.show_employees(data)def display(self) -> None:self.employee_view.display()class View(ABC):@property@abstractmethoddef employee_presenter(self):pass@employee_presenter.setter@abstractmethoddef employee_presenter(self, presenter):pass@abstractmethoddef show_employees(self, data: dict[str, list[str, float]]):pass@abstractmethoddef display(self):pass@abstractmethoddef show_status(self):pass@abstractmethoddef hide_status(self):passclass EmployeeView(View):def __init__(self):self._employee_presenter: Presenter = Noneself._container: HBox = Noneself._keyword_textbox: Text = Noneself._search_button: Button = Noneself._status: Label = Noneself._output: Output = Noneself._initialize_view()def _on_click(self, *args) -> None:keyword = self._keyword_textbox.valueself.employee_presenter.search(keyword)def _bind_event(self) -> None:self._search_button.on_click(self._on_click)def _initialize_view(self) -> None:self._keyword_textbox = Text(value = '',placeholder = '请输入关键字',description = '关键字')self._search_button = Button(descripton = '查询',button_style = 'info',tooltip = '查询',icon = 'search')self._status = Label()self._container = HBox((self._keyword_textbox, self._search_button, self._status))self._output = Output()self._bind_event()@propertydef employee_presenter(self):return self._employee_presenter@employee_presenter.setterdef employee_presenter(self, presenter):self._employee_presenter = presenterdef show_employees(self, data: dict[str, list[str, float]]) -> None:df = DataFrame(data)with self._output:self._output.clear_output()display(df)def display(self):display(self._container, self._output,)def show_status(self) -> None:self._status.value = '读取数据, 请稍候...'def hide_status(self):self._status.value = ''if __name__ == "__main__":# import objgraphemployee_respository = MemoryEmployeeRepository()employee_service = EmployeeService(employee_respository)employee_presenter = EmployeePresenter(employee_service)employee_view = EmployeeView()employee_presenter.employee_view = employee_viewemployee_view.employee_presenter = employee_presenter# objgraph.show_refs(# [employee_presenter, employee_view], filename='pv.png', max_depth=2)employee_presenter.display()
10.4.1.3.4.1. Model 层
# 这一部分采用了<依赖注入>* 继承自 EmployeeRepository 类的子类的实例都可以注入到 EmployeeService 的实例中 class EmployeeRepository(ABC):''' 数据查询结果的抽象 '''@abstractmethoddef query_employees(self, keyword: str) -> list[Employee]:passclass MemoryEmployeeRepository(EmployeeRepository):'''在 employees 数据源里进按 keyword 进行查询返回符合要求的 Employee 列表'''employees: list[Employee] = [Employee('Andy', 99999.9),Employee('Tracy', 55555.9),Employee('Antony', 12345.8)]def query_employees(self, keyword: str) -> list[Employee]:# 返回符合姓名要求的结果return [employee for employee in self.employeesif keyword.lower() in employee.name.lower()]class EmployeeService:''' 返回符合要求的 defaultdict '''def __init__(self, employee_respository: EmployeeRepository) -> None:# 实际代入的是 MemoryEmployeeReposity# 这就是依赖抽象吗??self._employee_respository = employee_respositorydef query_employees_data(self, keyword: str) -> dict[str, list[str, float]]:employees = self._employee_respository.query_employees(keyword)result = defaultdict(list)for employee in employees:result['name'].append(employee.name)result['salary'].append(employee.salary)return result
10.4.1.3.4.2. Presenter 层
class Presenter(ABC):''' 中间层 抽象 '''@property@abstractmethoddef employee_view(self):'''通过此方法与 View 层 相关联'''pass@employee_view.setterdef employee_view(self, view):pass@abstractmethoddef search(self, keyword: str) -> None:'''通过此方法联系 View 层和 Model 层接收 View 层的请求数据将此请求传递给 Model接收 Model 层传递回的结果数据将此结果传递给 View 进行显示'''pass@abstractmethoddef display(self) -> None:'''用于显示 View 层 UI'''passclass EmployeePresenter(Presenter):def __init__(self, employee_service: EmployeeService) -> None:self._employee_service = employee_serviceself._employee_view = None@propertydef employee_view(self):return self._employee_view@employee_view.setterdef employee_view(self, view):self._employee_view = viewdef search(self, keyword: str) -> None:# 显示进度信息self.employee_view.show_status()# 获取数据data = self._employee_service.query_employees_data(keyword)# 模拟延迟time.sleep(1)# 隐藏进度信息self.employee_view.hide_status()# 绑定和呈现列表self.employee_view.show_employees(data)def display(self) -> None:self.employee_view.display()
10.4.1.3.4.3. View 层
class View(ABC):@property@abstractmethoddef employee_presenter(self):pass@employee_presenter.setter@abstractmethoddef employee_presenter(self, presenter):pass@abstractmethoddef show_employees(self, data: dict[str, list[str, float]]):pass@abstractmethoddef display(self):pass@abstractmethoddef show_status(self):pass@abstractmethoddef hide_status(self):passclass EmployeeView(View):def __init__(self):self._employee_presenter: Presenter = Noneself._container: HBox = Noneself._keyword_textbox: Text = Noneself._search_button: Button = Noneself._status: Label = Noneself._output: Output = Noneself._initialize_view()def _on_click(self, *args) -> None:keyword = self._keyword_textbox.valueself.employee_presenter.search(keyword)def _bind_event(self) -> None:self._search_button.on_click(self._on_click)def _initialize_view(self) -> None:self._keyword_textbox = Text(value = '',placeholder = '请输入关键字',description = '关键字')self._search_button = Button(descripton = '查询',button_style = 'info',tooltip = '查询',icon = 'search')self._status = Label()self._container = HBox((self._keyword_textbox, self._search_button, self._status))self._output = Output()self._bind_event()@propertydef employee_presenter(self):return self._employee_presenter@employee_presenter.setterdef employee_presenter(self, presenter):self._employee_presenter = presenterdef show_employees(self, data: dict[str, list[str, float]]) -> None:df = DataFrame(data)with self._output:self._output.clear_output()display(df)def display(self):display(self._container, self._output,)def show_status(self) -> None:self._status.value = '读取数据, 请稍候...'def hide_status(self):self._status.value = ''
10.4.1.3.4.4. 调用方法
employee_respository = MemoryEmployeeRepository()
创建了 雇员数据仓库Query_employee() 可用于返回符合条件的雇员列表employee_service = EmployeeService(employee_respository)
创建了 雇员服务
Query_employees_data() 可用于返回一个符合要求的 defaultdictemployee_presenter = EmployeePresenter(employee_service)
创建 雇员中间人 同时沟通 employee_view 和 employee_serviceSearch()方法 用于执行 搜索Display() 用于执行 employee_view的 display()方法
employee_view = EmployeeView()
用于创建 用户交互界面
employee_presenter.employee_view = employee_view
雇员中间人 与 雇员视图 相联系
employee_view.employee_presenter = employee_presenter
雇员视图 与 雇员中间人 相联系
employee_presenter.display()
10.4.1.4. 优点
# 将View与Model解耦, 方便进行单元测试
# 结构清晰, 易于维护
# activity 和 fragment 不再是 controller 层, 而是纯粹的 view 层
10.4.1.5. 缺点
# 类与接口将会增多, 增加了代码量
# 每个功能都得新增接口, presenter难以复用* 如该页面有许多网络请求, 每个网络请求都得新增一个接口。后面新增一个页面发现只需要一个跟上个页面一样的接口, 这时候如果复用上一个页面的presenter, 那么就得实现其它用不到 的接口。
10.4.2. 循环引用的那些事
# MVP 模式的一个缺点就是 view 和 presenter 之间的循环引用* Python的垃圾回收机制很好的解决了这个问题
# Python的垃圾回收机制除了特有的引用计数器之外, 还有通过3个世代的过渡, 来决定对象在堆内的生命周期* 这3个世代分别是 generation0, generation1, generation2* generation0 是新生代* gc的阀值高<700>, 对应生命周期短的对象* generation1 阀值为10* generation2 阀值也是10* 为后续的性能调优提供了基础保障
# Python 的垃圾回收机制通过扫描的方式借助双向链表和不定区来解决循环引用的孤岛对象问题, 使得这些对象在确定没有被外部引用, 没有价值的时候, 就进行清理* 为 MVP 模式的缺点做出了有力的补充, 使得不需要额外去实现清理现场的操作* 也演示了 MVP 轻松切换视图的模式特点, 向大家印证了分离关注点落地的优势
10.5. 依赖注入
# 对象之间需要合作才能做好事情, 对象依赖的管理就显示很重要了* 对象要完成既定的任务, 通常不可能单凭一个<孤岛对象>就可以完成, 需要和其他专业对象合作才能在专注的领域完成专注的事情
# 依赖反转是对象依赖管理的一种实用的思想* 依赖高层次的抽象而不是依赖低层次的实现, 会让代码的维护性提高* 依赖抽象的好处是可以在运行时中替换或者插入实现的对象, 将对象实例化等操作的管理权移交给上层, 而不是业务对象自己去了解无关的知识来自我维护* 颠覆了传统依赖的对象管理的观念, 是好莱坞原则的一种体现* 好莱坞原则: Don't call us, we' ll call you* 梦想进入好莱坞的人, 不要找好莱坞, 让好莱坞来找你!
# 依赖注入作为依赖反转实现的一种手段, 借助工具可以实现依赖对象的管理, 让业务对象摆脱无关的工作从而职责更专一, 更容易维护
# 例子中使用到了 Python 的 DI 框架 Python-Dependency-Injector 的开源框架, 简化了流程
10.5.1. 概念
# 依赖注入<Dependency Injection>: 软件工程中使用的一种设计模式, 创建对象由外部的依赖关系完成, 类自己直接使用这些依赖关系* 依赖: 可被方法调用的事物* 调用方不再直接使用<依赖>, 取而代之的是<注入>* 编程的角度: * 调用方通常是对象和类* 依赖通常是变量* 提供服务的角度: * 调用方是客户端* 依赖通常是服务* 注入: 将<依赖>传递给调用方的过程
10.5.2. 理解

10.5.3. 作用
# 作用: * 创建对象* 知道哪些类需要哪些对象* 提供所需要的对象
# 特性: * 对象的任何修改都不应影响到使用它的类* 依赖注入会对这些修改进行调查* 为类提供正确的对象
10.5.4. 类型
10.5.4.1. 常规模式
# 构造函数注入: 依赖关系通过 class 构造器提供
# setter 注入: 注入程序用客户端的 setter 方法注入依赖项
# 接口注入: 依赖项提供一个注入方法* 注入方法将依赖项注入到传递给它的任何客户端中* 客户端必须实现一个接口* 该接口的 setter() 接收依赖
10.5.4.1.1. 构造函数注入
# 构造函数注入是最常见的一种依赖注入方式, 将依赖关系传递给一个类, 通过在对象的构造函数中接受依赖对象作为参数, 从而实现依赖注入* 允许该类将依赖关系存储为实例变量, 使它们对其方法可用
from abc import ABC, abstractmethod
from collections.abc import Iteratorclass User:def __init__(self, name: str, age: int) -> None:self.name = nameself.age = ageclass DBAccess(ABC):@abstractmethoddef query_all_users(self) -> dict:passclass SQLiteDB(DBAccess):def query_all_users(self) -> dict:print('Query all users by sqlite.')users = [{'name': 'Steven','age': 23,},{'name': 'Laura','age': 33,}]return usersclass UserRepository(ABC):@abstractmethoddef query_all_users(self) -> Iterator[User]:passclass DBUserRepository(UserRepository):def __init__(self, db:DBAccess) -> None:self.db = dbdef query_all_users(self) -> Iterator[User]:for entry in self.db.query_all_users():user = User(**entry)yield userclass UserService:# 客户端# 实现了构造函数注入def __init__(self, user_repository: UserRepository) -> None:# 构造函数注入 self.user_repository = user_repositorydef query_all_users(self) -> list[User]:print('UserService query all users from UserRepository')return [user for user in self.user_repository.query_all_users()]def main():db: DBAccess = SQLiteDB()user_respository = DBUserRrpository(db)user_service = UserService(user_respository)users = user_service.query_all_users()for user in users:print(user.name, user.age)if __name__ == '__main__':main()
10.5.4.1.2. setter 注入
# setter 注入: 通过类本身提供的一个方法用来注入不同类型的对象来设置自身对象和其他对象的依赖关系
# -*- coding: UTF-8 -*-
# version: python3.12class Test:''' 继承接口 '''def injection(self, testOject):''' 实现接口方法 '''self.object = testOjectdef show(self):print(self.object)class A:''' 测试用类 '''def __str__(self) -> str:return 'class A'class B:''' 测试用类 '''def __str__(self) -> str:return 'class B'test = Test()
test.injection(A())
test.show()test.injection(B())
test.show()
10.5.4.1.3. 接口注入
# 接口注入: 先定义一个接口类,然后在继承了该接口的类中实现特定的接口方法,而在接口方法中根据传入参数的不同做出不同的行为
# -*- coding: UTF-8 -*-
# version: python3.12class Itest:''' 接口类 '''def injection(self, testClass):'''接口方法'''raise NotImplemented("This method must be implemented.")class Test(Itest):''' 继承接口 '''def injection(self, testOject):''' 实现接口方法 '''self.object = testOjectdef show(self):print(self.object)class A:''' 测试用类 '''def __str__(self) -> str:return 'class A'class B:''' 测试用类 '''def __str__(self) -> str:return 'class B'test = Test()
test.injection(A())
test.show()test.injection(B())
test.show()
10.5.4.2. 框架模式
Python中有多个优秀的依赖注入框架,如Django、Flask和Pyramid等
10.5.5. 优势
# 改善可测试性
# 减少组件之间的耦合* 通过将对象与它们的依赖关系解耦, 可以更容易地进行更改而不影响系统的其他部分
# 提高软件设计的灵活性和模块化
10.5.6. 劣势
# 过度使用会导致管理问题和其他问题
# 许多编译时错误被推送到运行时
# 依赖注入框架的反射或动态编程这可能会妨碍 IDE 自动化的使用* 例如 <查找引用>|<显示调用层次结构>和安全重构






![[BSidesCF 2019]SVGMagic 1](https://img2024.cnblogs.com/blog/3335050/202407/3335050-20240716065911902-1734581167.png)

