awk
3.4.2 功能
过滤 取行 取列 统计计算 数组 函数
3.4.3 格式
awk 条件 动作 (找谁 干啥)
awk [options] 'commands' filenames
awk [options] -f awk-script-file filenames
3.4.4 awk处理数据的方式:
1、进行逐行扫描文件,从第一行到最后一行
2、寻找匹配的特定模式的行,在行上进行操作
3、如果没有指定处理动作,则把匹配的行显示到标准输出
4、如果没有指定模式,则所有被操作的行都被处理
要点:awk里面不会默认输出,需要加print进行输出
3.4.5 参数:
print -----打印输出内容在awk里满足条件之后默认执行的工作时(print $0)显示内容
$n -----取第n列内容
$0 -----一整行内容
$NF -----最后一列
NR -----记录输出文件的编号(行号)
FNR -----当前输入文件的编号(行号)
NR==n -----第n行
NF -----统计文件列数
-F(FS)-----创建分隔符,字段分隔符在awk里默认的分隔符为单个空格 连续空格 tab键
-RS -----记录分隔符,每一行结束标记
-v -----修改或创建awk变量,传递变量
&& -----并且
^ -----以……开头的列
$ -----以……结尾的列
~ -----包含,匹配
BEGIN{} ----命令处理前执行
END{} ----命令处理后执行
ORS -----输出记录分隔符(默认值是一个换行符)
OFS -----修改输出字段分隔符(默认值是一个空格)
ARGV -----包含命令参数的属组
FIELDWIDTHS -字段宽度列表(用空格键隔开)
substr(s,i[,n]) -----把字符串s中的从i个字符开始级以后的n个字符截取
比较表达式:
格式运算符 含义 示例
< 小于 x<y
<= 小于或等于 x<=y
== 等于 x==y
!= 不等于 x!=y
>= 大于等于 x>=y
> 大于 x>y
3.4.6 参数示例:
查询-取行
$0: 所有内容
NR:记录输出文件的编号(行号)
FNR`当前输入文件的编号(行号)
输出所有内容
//输出文件全部内容
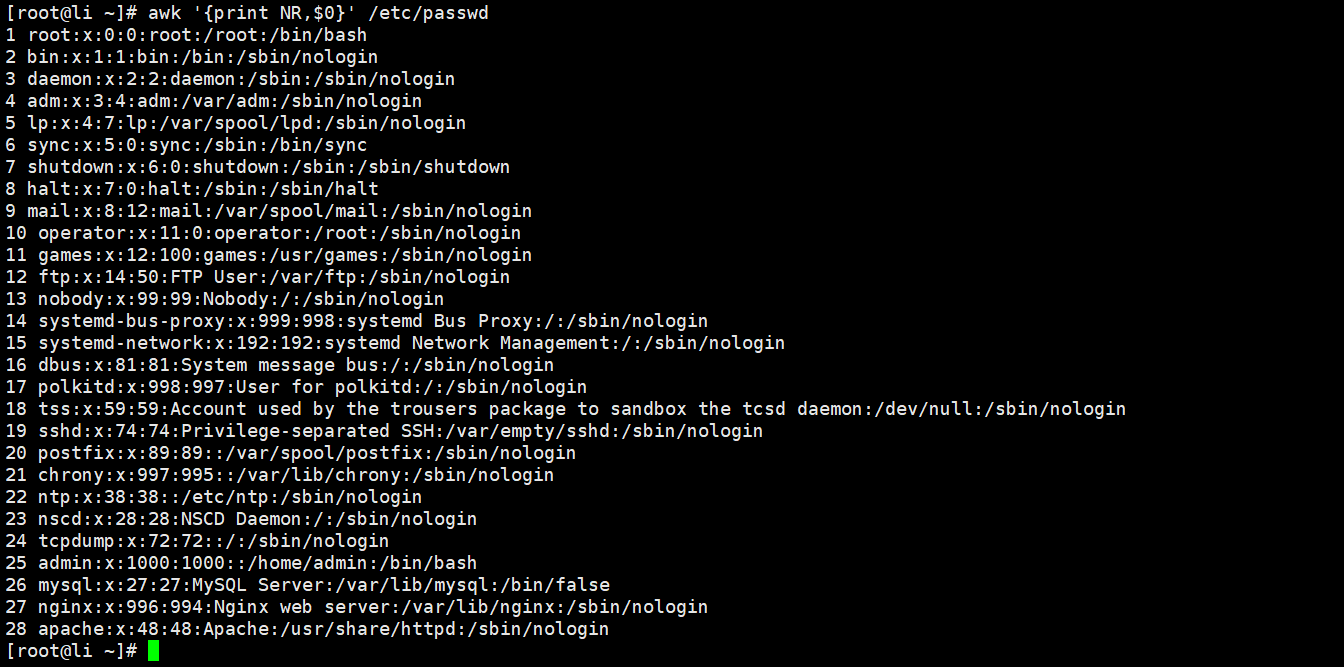
[root@Shell ~]# awk '{print $0}' /etc/passwd//输出文件全部内容并且加上每一行的行号
[root@Shell ~]# awk '{print NR,$0}' /etc/passwd//将该文件前三行内容取出来
[root@Shell ~]# awk 'NR<=3' /etc/passwd//一次输出两个文件的内容并且加上行号
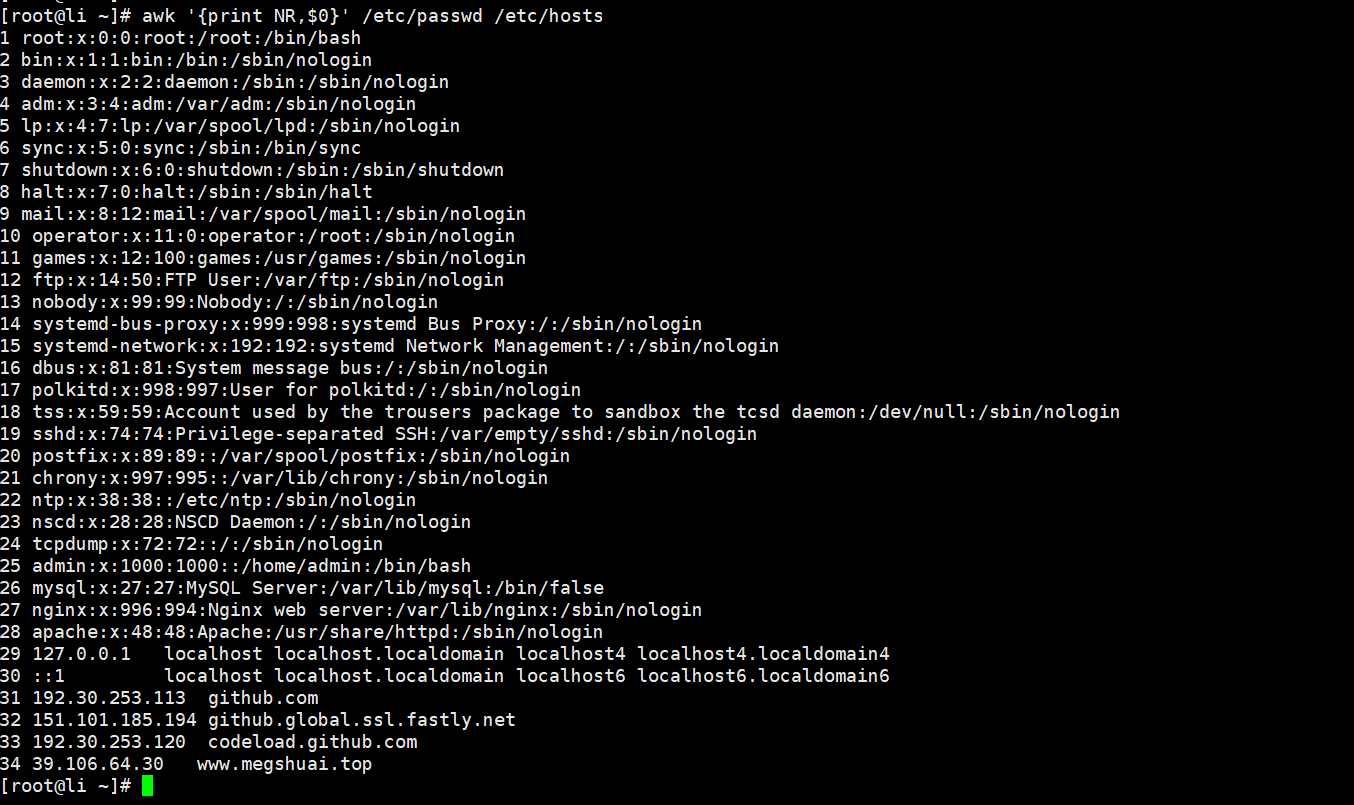
[root@Shell ~]# awk '{print NR,$0}' /etc/passwd /etc/hosts//一次输出两个文件的内容,给每个文件内容加上行号
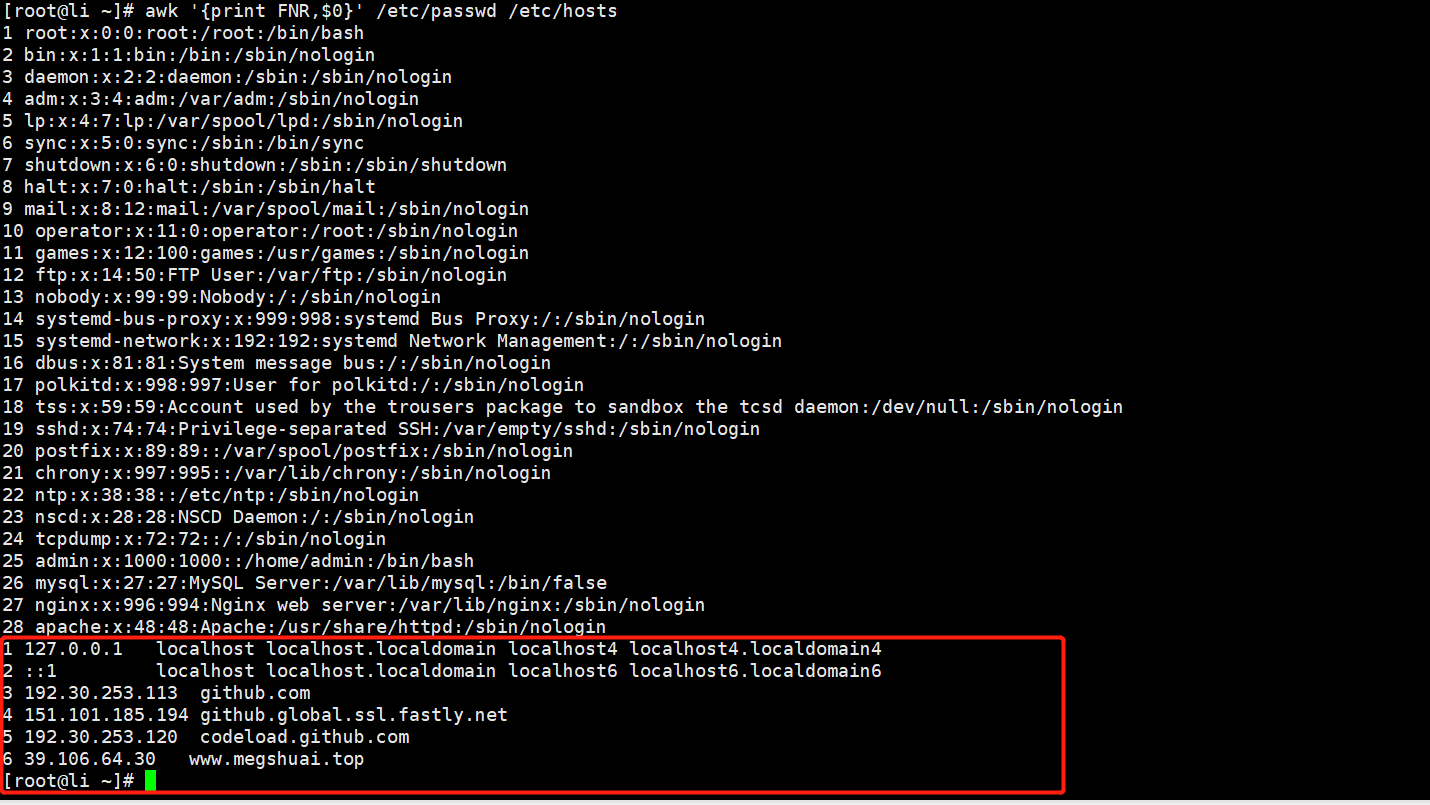
[root@Shell ~]# awk '{print FNR,$0}' /etc/passwd /etc/hosts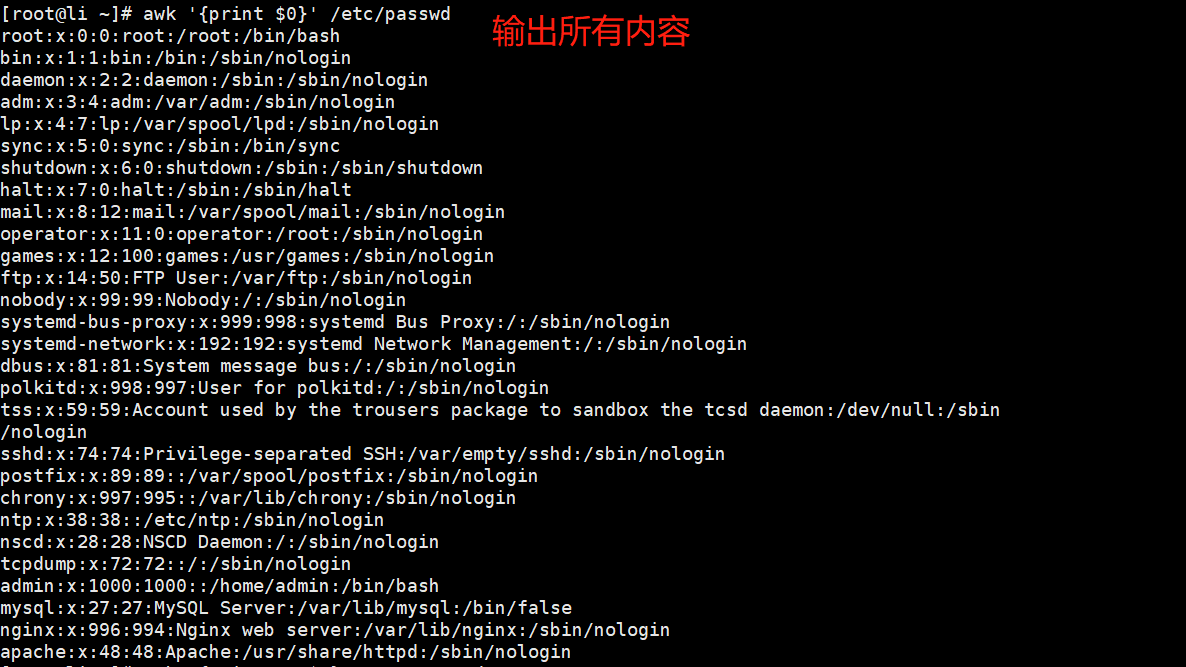

取行
NR==n 取文件第N行内容
NR:显示输出文件编号
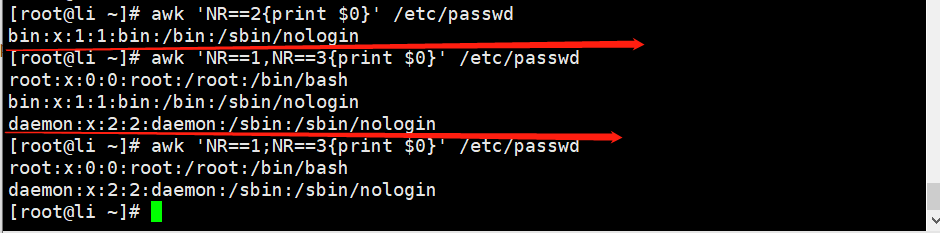
//取出文件第二行的内容
awk 'NR==2{print $0}' (显示二2行的全部内容)//取第一行到第三行的内容
[root@web01 for]# awk 'NR==1,NR==3{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin//取第一行和第三行的内容
[root@web01 for]# awk 'NR==1;NR==3{print $0}' /etc/passwd//取出以root开头的行
[root@Shell ~]# awk '/^root/' /etc/passwd//取出以root开头的行
[root@Shell ~]# awk '$0 ~ /^root/' /etc/passwd

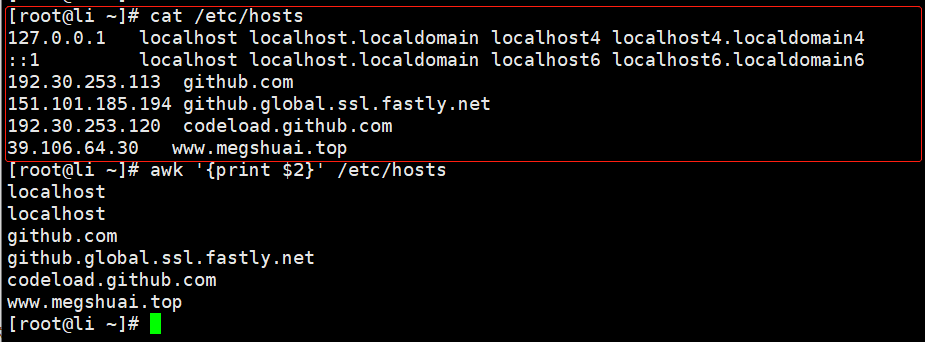
查询-取列
查找列内容
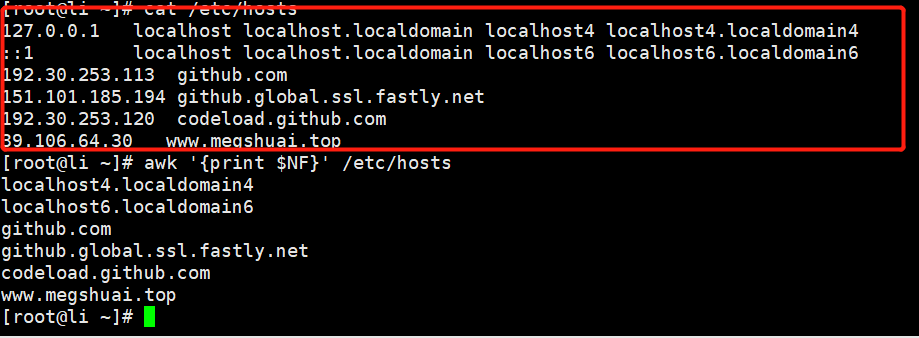
NF:文件的最后一列
//取出文件的第二列的内容
awk '{print $2}' /etc/hosts//取出文件的最后一列内容
awk '{print $NF}' /etc/hosts//取文件倒数第二列内容
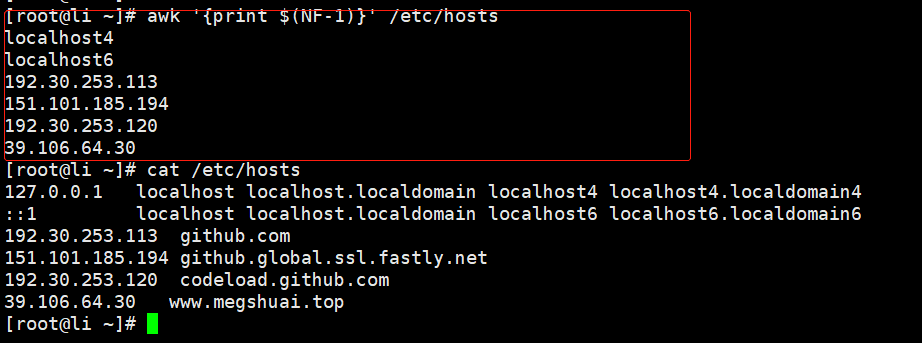
awk '{print $(NF-1)}' /etc/hosts//保存行的最后一列并输出列号
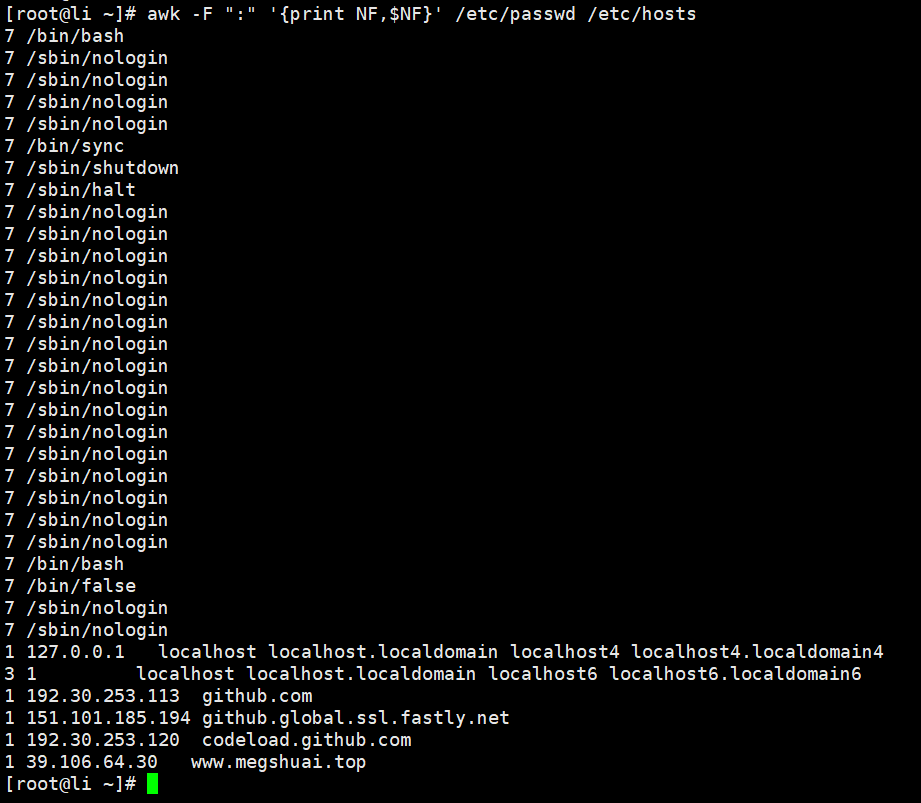
[root@Shell ~]# awk -F ":" '{print NF,$NF}' /etc/passwd /etc/hosts
统计文件列数
NF:统计文件列数
-F:创建分隔符,字段分隔符
[]:匹配[]中指定范围内的任意一个字符
//原文件内容
[root@Shell ~]# cat b.txt
lzy lizhenya:is a:good boy!//统计文件总列数
[root@Shell ~]# awk '{print NF}' b.txt
4//以‘:’为分隔符,统计文件有多少列
[root@Shell ~]# awk -F ':' '{print NF}' b.txt
3//以空格和冒号为分隔符,统计文件列数
[root@Shell ~]# awk -F"[ :]" '{print NF}' b.txt
6
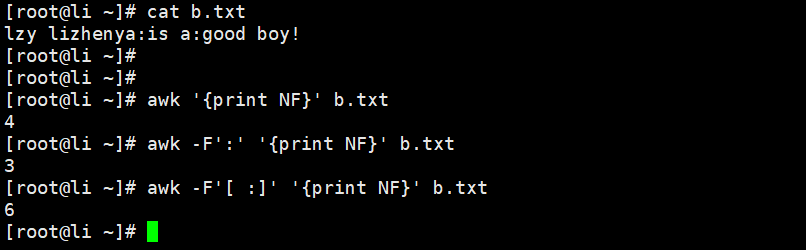
查询匹配内容
//匹配字段:匹配操作符(~ !~)
~:传递数据,将前面的数据传递给
!~:不传递该数据
//查询文件第一列以root开头的列
[root@Shell ~]# awk '$1~/^root/' /etc/passwd
[root@Shell ~]# awk '$NF !~ /bash$/' /etc/passwd

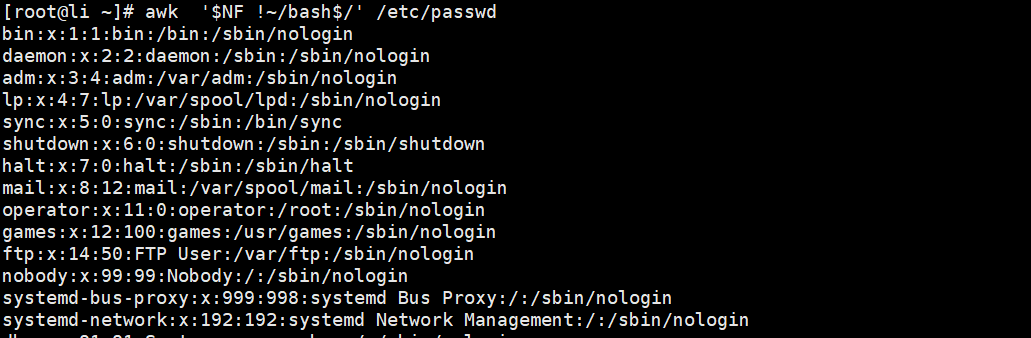
范围-查找内容
格式:
awk ‘//,//’(从包含什么内容开始,到包含什么内容结束)
示例:
[root@li ~]# awk '/root/,/operator/' /etc/passwd
创建分隔符
-F:创建分隔符,字段分隔符
在awk里默认的分隔符为单个空格 连续空格 tab键
FS 创建分隔符,字段分隔符
//以冒号为分隔符,显示文件第二列的内容
[root@li ~]# awk -F':' '{print $2}' /etc/passwd//以冒号为分隔符,取1~3行的第二列内容
[root@web01 for]# awk -F":" 'NR==1,NR==3{print $1}' /etc/passwd//以冒号作为字段分隔符,查找包含root的行,并且取出第一列和第三列
[root@Shell ~]# awk -F: '/root/{print $1,$3}' /etc/passwd//以冒号作为字段分隔符,查找包含root的行,并且取出第一列和第三列
[root@Shell ~]# awk 'BEGIN{FS=":"} {print $1,$3}' /etc/passwd//以空格冒号tab作为字段分割,取出第一二三列的内容
[root@Shell ~]# awk -F'[ :\t]' '{print $1,$2,$3}' /etc/passwd
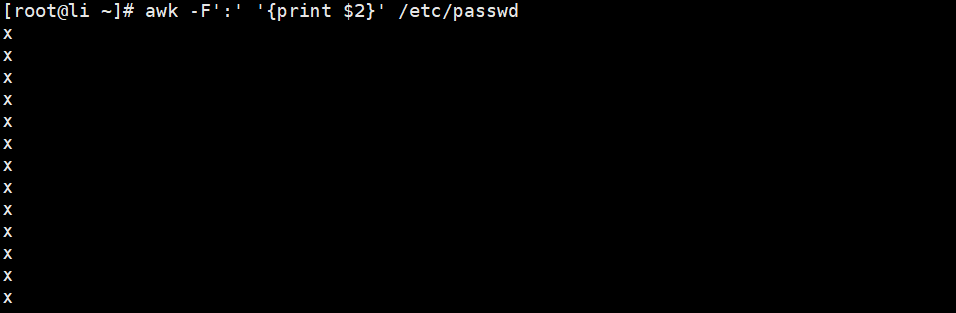




OFS指定输出字段分隔符*
//,逗号映射为OFS, 初始情况下OFS变量是空格//以冒号为分隔符,取出1 2 3 4列内容(观察每列之间是以空格隔开的)
[root@Shell ~]# awk -F: '/root/{print $1,$2,$3,$4}' /etc/passwd//以冒号为分隔符,取出1 2 3 4列的内容,指定分隔符为+++ (观察每列之间的分隔符更换为了+++)
[root@Shell ~]# awk 'BEGIN{FS=":"; OFS="+++"} /^root/{print $1,$2}' /etc/passwd
```**awk使用变量**
> -v:修改或创建awk变量,传递变量
OFS:输出字段分隔符(默认值是一个空格)**图片理解**
https://www.processon.com/view/link/5aa1df8ae4b0b089b9e60cbd```
//调换 /etc/passwd第1列和最后一列的内容
[root@web01 oldboy]# awk -F: -vOFS=: '{a=$1;$1=$NF;$NF=a;print}' /etc/passwd
》使用-F指定冒号为分隔符,OFS将默认输出分隔符(空格)修改为冒号,-v创建awk变量,传递数据数据;将第一列赋值给a,将最后一列赋值给第一列,在将a赋值给最后一列,最后打印输出,完成调换。
```
## 3.4.6.1 比较表达式:
```
格式运算符 含义 示例
```
```
< 小于 x<y
<= 小于或等于 x<=y
== 等于 x==y
!= 不等于 x!=y
>= 大于等于 x>=y
> 大于 x>y
```
**比较表达式示例**
```
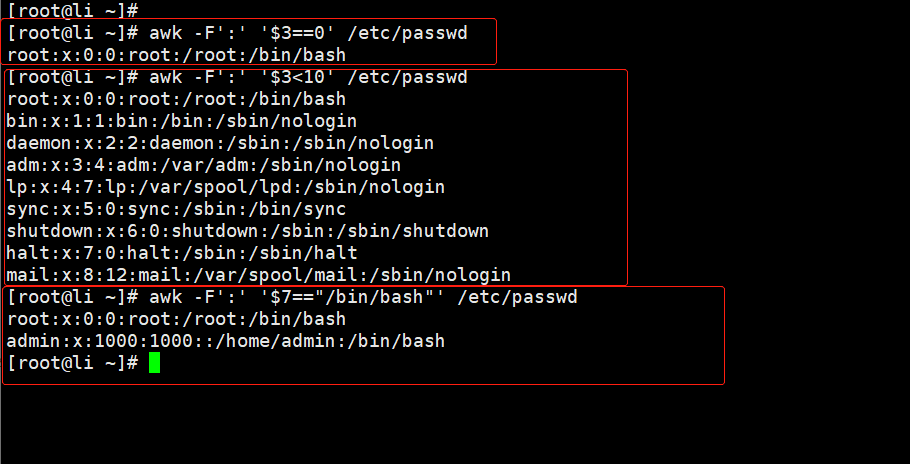
//将uid为0的列出来[root@Shell ~]# awk -F ":" '$3==0' /etc/passwd//将uid小于10的全部列出来[root@Shell ~]# awk -F: '$3 < 10' /etc/passwd//用户登陆的shell等于/bin/bash[root@Shell ~]# awk -F: '$7 == "/bin/bash" ' /etc/passwd//第一列为root的列出来[root@Shell ~]# awk -F: '$1 == "root" ' /etc/passwd //将为root的用户列出来[root@Shell ~]# awk -F: '$1 ~ /root/ ' /etc/passwd //将非root的用户列出来[root@Shell ~]# awk -F: '$1 !~ /alice/ ' /etc/passwd//磁盘使用率大于多少则,则打印可用的值[root@Shell ~]# df |awk '/\/$/'|awk '$3>1000000 {print $4}'\\解析:df:查看磁盘空间命令,awk '/\/$/' :查找以 / 结尾的行(根目录表示符号);awk '$3>1000000 {print $4}' 筛选第三列大于1000000的行,打印出第四列的内容。
```
**数字对比**
```在比较数字的时候有时候会有出现错误,比如数字和字符挨着,系统就会把数字当做符号,现在就需要在“条件”后面加数字参数,目的就是告诉系统这是数字,或者就是指定新的分隔符示例:awk -F":" '$3>1000' /etc/passwddf -h | awk '$5+0>10'
```
### 过滤**正则表达式作为键(过滤)**
```
格式awk ‘//’ 文件路径 (//里面属于需要过滤的内容)
```
**示例**
```
//查找文件中包含root的行
[root@web01 oldboy]# awk '/root/' /etc/passwd
```
### 条件表达式
```
格式:awk '$?>$?{print $0}' 文件路径 (根据条件筛选对应的条件)
```
```
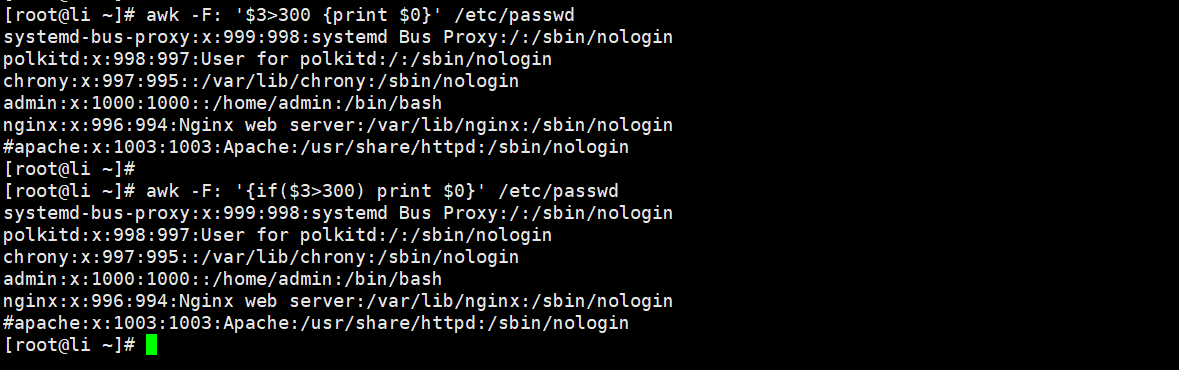
//查找文件第三列大于300的行
[root@Shell ~]# awk -F: '$3>300 {print $0}' /etc/passwd
//查找文件第三列大于300的行
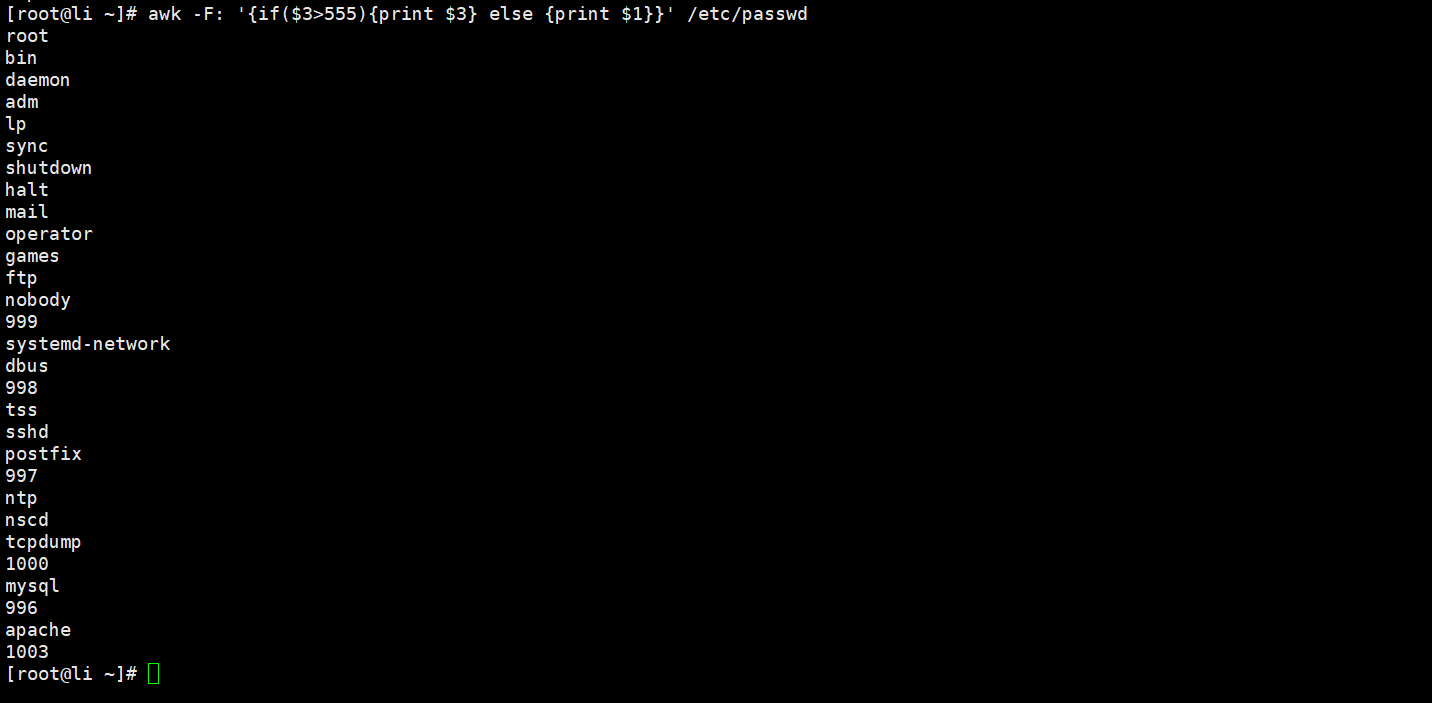
[root@Shell ~]# awk -F: '{if($3>300) print $0}' /etc/passwd//查找文件中第三列大于555的内容,否则打印出第一列的内容。
[root@Shell ~]# awk -F: '{if($3>555){print $3} else {print $1}}' /etc/passwd
```
**运算表达式**
```
格式:awk '$? 运算符号 * ' 文件路径
```
```
加 +
减 -
乘 *
除 /
幂 **。例子:4**0.5=2.0
整除(地板除,向下取整) //。例子:5//2=2 -5//2=-3
取余 %。例子:5%2=1 -5%2=1 5%(-2)=-1 (-5)%(-2)=-1
```
```
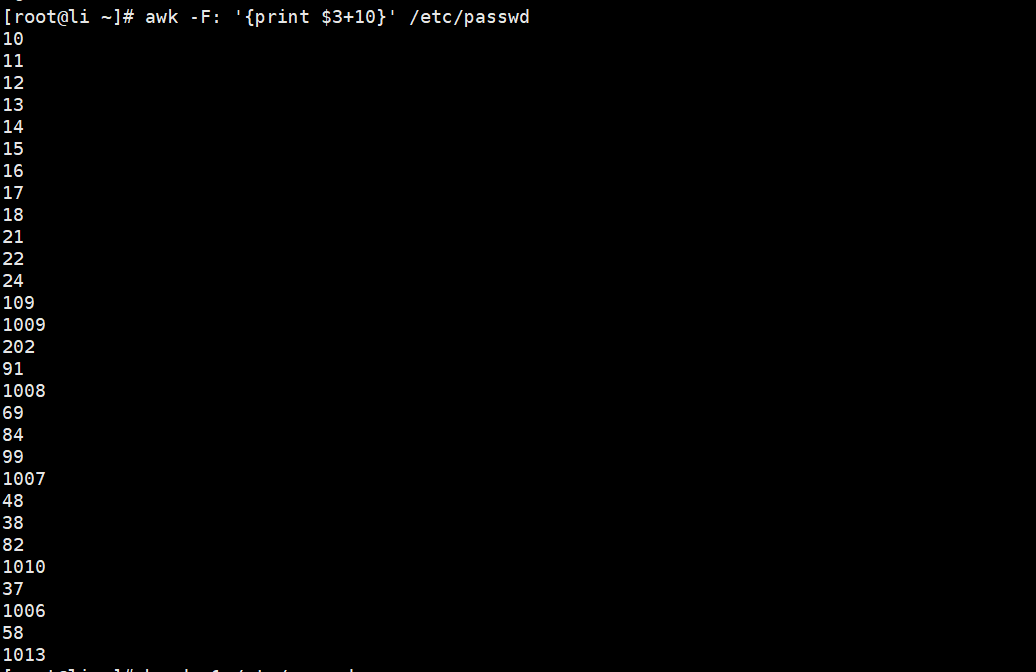
//取文件第三列加上10的结果
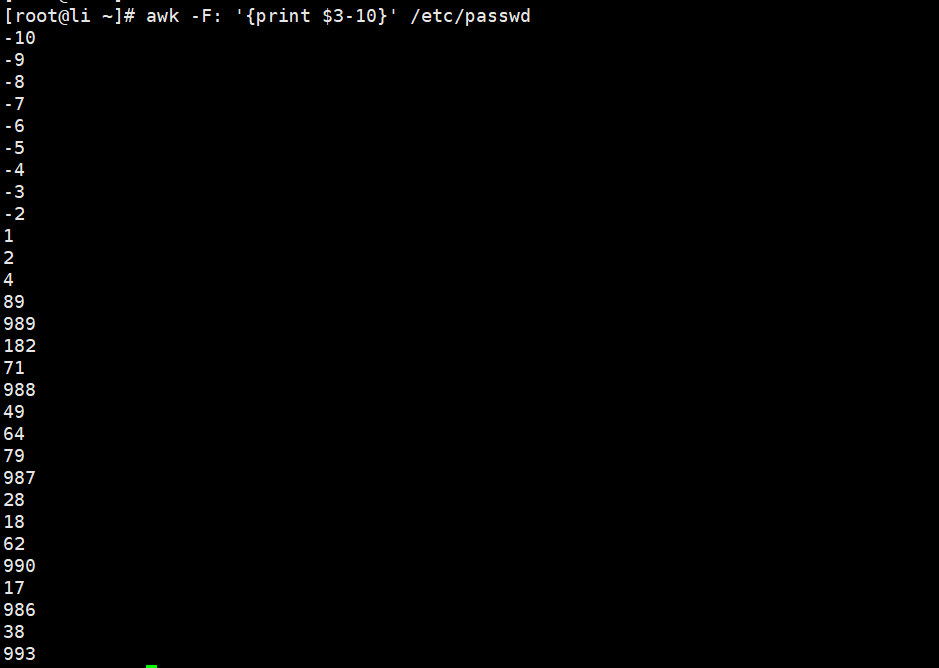
[root@li ~]# awk -F: '{print $3+10}' /etc/passwd//取文件第三列减去10的结果
[root@li ~]# awk -F: '{print $3-10}' /etc/passwd//取文件第三列乘以10的结果
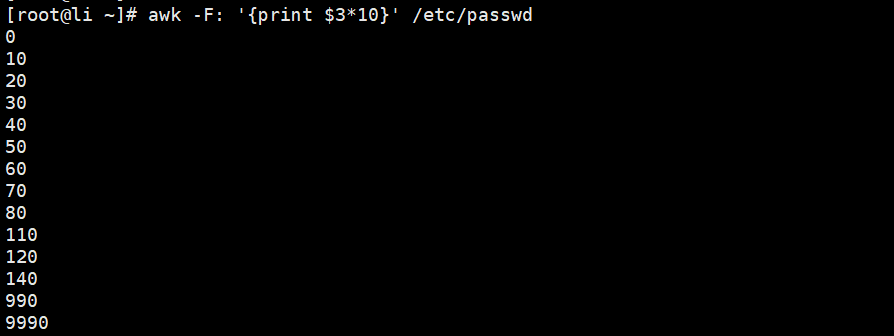
[root@Shell ~]# awk -F: '{print $3*10}' /etc/passwd//打印出文件第三列乘以10,后结果小于50的列
[root@li ~]# awk -F: '($3*10<50) {print $3*10}' /etc/passwd//取出文件第三列的内容,第三列的内容乘以10,如果大于500,则输出文件第1列和第三列,否则,输出“no”,在执行结束后输出“打印OK”字样。
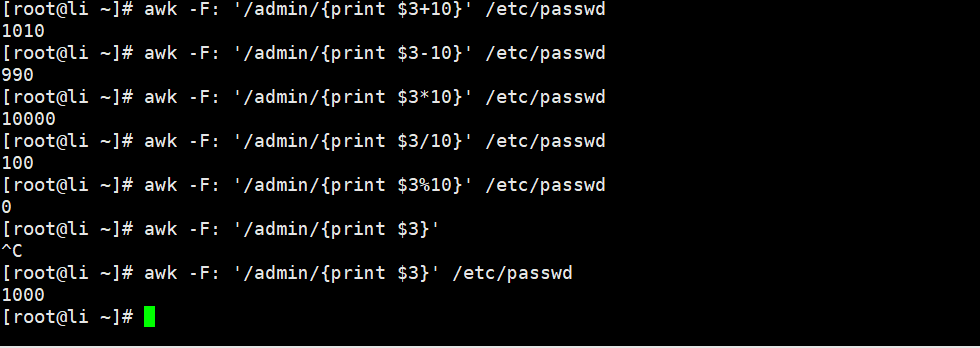
[root@Shell ~]# awk -F: 'BEGIN{OFS="--"} { if($3*10>500) {print $1,$3} else {print "no"} } END {print "打印ok"} ' /etc/passwd//打印出包含admin的行的第三列加10的结果
[root@li ~]# awk -F: '/admin/{print $3+10}' /etc/passwd
1010
//打印出包含admin的行的第三列减去10的结果
[root@li ~]# awk -F: '/admin/{print $3-10}' /etc/passwd
990
//打印出包含admin的行的第三列乘以10的结果
[root@li ~]# awk -F: '/admin/{print $3*10}' /etc/passwd
10000
//打印出包含admin的行的第三列除以10的结果
[root@li ~]# awk -F: '/admin/{print $3/10}' /etc/passwd
100
//打印出包含admin的行的第三列取余的结果
[root@li ~]# awk -F: '/admin/{print $3%2}' /etc/passwd
0```
**逻辑操作符和复合模式***
```
&& 逻辑“与,并且”
|| 逻辑“或,或者”
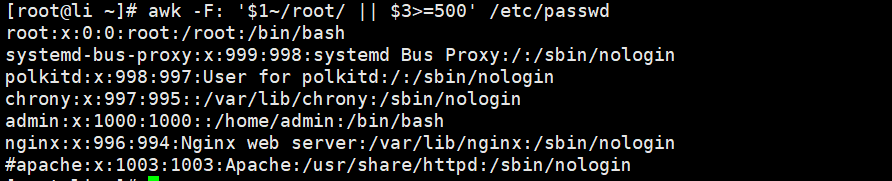
! 逻辑“非,不,取反” //匹配用户名为root并且打印uid小于15的行
[root@Shell ~]# awk -F: '$1~/root/ && $3<=15' /etc/passwd //匹配用户名为root或uid大于500
[root@Shell ~]# awk -F: '$1~/root/ || $3>=500' /etc/passwd//匹配用户名不为root的行
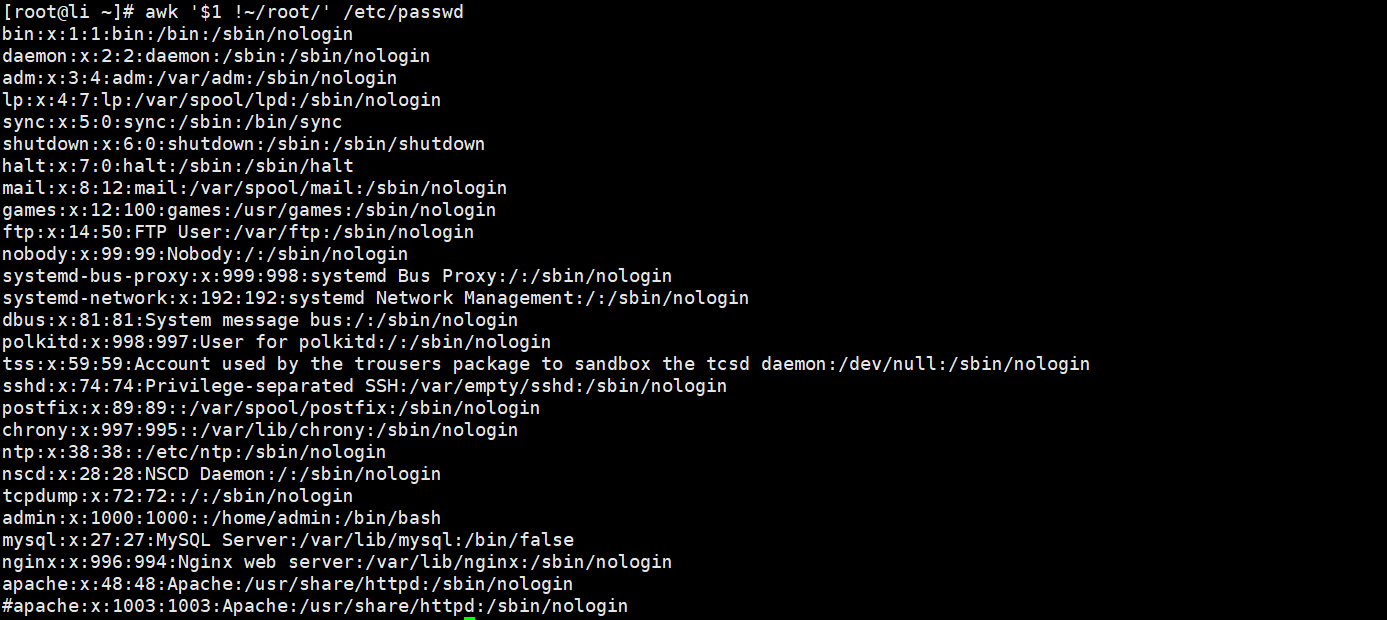
awk '$1 !~/root/' /etc/passwd
```
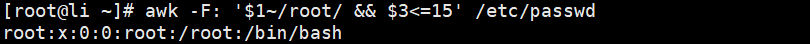### 替换
```
格式awk ‘{gsub(//,””);print $0}’ (//里面输入要替换的内容,””里面输入替换后的内容)
```
示例:
```
将00替换为11[root@web01 oldboy]# awk '{gsub(/00/,"11");print $0}' 01.txt
17/Apr/2015:09:29:24 +0811
17/Apr/2015:09:30:26 +0811
17/Apr/2015:09:31:56 +0811
18/Apr/2015:09:34:12 +0811
```### 特殊条件: BEGIN{} 、END{}
```
含义:
BEGIN{}:BEGIN {}:里面的内容,会在awk读取文件之前执行,现在一般用于计算END{}:END{}:里面的内容,会在awk读取文件之后执行,显示最终结果
```
**BEGIN{} 计算**
```
* 乘,乘以
** 次幂,次幂和次方的意义是一样的,只是中文叫法不一样
^ 次方,次幂和次方的意义是一样的,只是中文叫法不一样
% 取余
```
```
格式:awk ‘BEGIN{print 计算的内容}’
```
**示例:**
```
//计算3乘以2
[root@li ~]# awk 'BEGIN{print 3*2}'
[root@li ~]# awk 'BEGIN{print 3**2}'
[root@li ~]# awk 'BEGIN{print 3^2}'
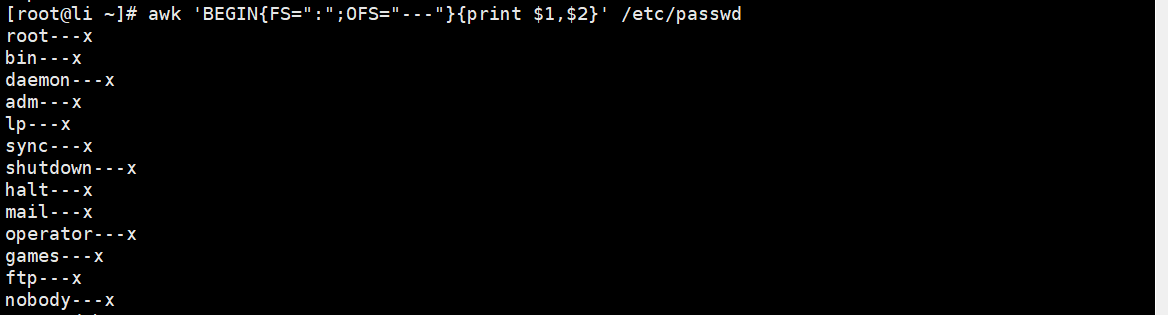
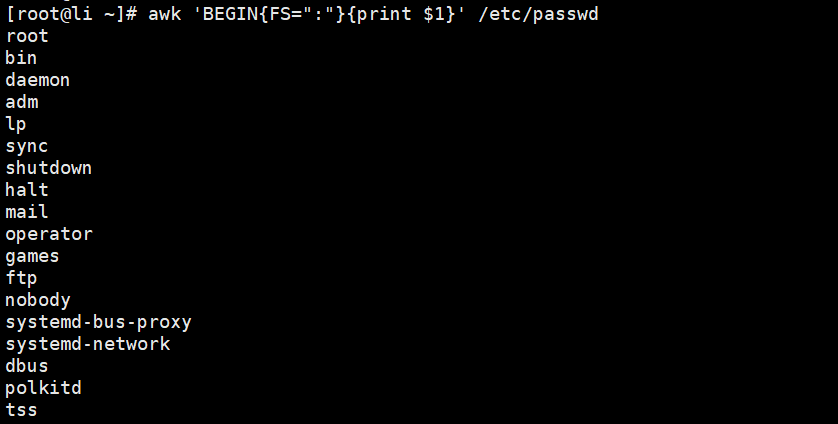
[root@li ~]# awk 'BEGIN{print 3%2}'//BEGIN在行处理前, 修改字段分隔符,将默认分隔符修改为':',并去除第一列内容[root@Shell ~]# awk 'BEGIN{FS=":"} {print $1}' /etc/passwd//BEGIN在行处理前, 修改字段读入和输出分隔符[root@Shell ~]# awk 'BEGIN{FS=":";OFS="---"} {print $1,$2}' /etc/passwd
```
### 自动加法公式:
```i=i+1 或 i++ (i就是变量),统计查询内容的次数/个i=i+$1 或i+=$?? 求和都需要用print 加变量显示结果
```
**示例:**
```
#awk在执行过程中是一行一行的去读取文件的,每次开始前都会去读取一遍命令,i就会去运算,从而完成统计i=i+1 使用END{} 输出
//源文件
[root@web01 oldboy]# cat 01.txt
17/Apr/2015:09:29:24 +0800
17/Apr/2015:09:30:26 +0800
17/Apr/2015:09:31:56 +0800//统计文件的列数,
[root@web01 oldboy]# awk '{i=i+1}END{print i}' 01.txt #直接显示最后结果
[root@li ~]# awk '{i=i+1;print i}' 01.txt #显示执行结果//统计17出现的次数
[root@li ~]# awk '/17/{i++;print i}' 01.txt #显示执行过程[root@li ~]# awk '/17/{i++}END{print i}' 01.txt #直接显示执行结果```
**i=$i+$?? 求和运算**```
//使用脚本计算1..100所有数的和的结果
#!/bin/bash
for i in {1..100}
dolet sum=$sum+$i
done
echo $sum
[root@web01 oldboy]# sh w.sh
5050
```**`print`格式化输出函数***
```
//以现在是“..年..月..号-时间”的格式,格式化时间
[root@li ~]# date | awk '{print "现在是"$NF"年"$1"月"$3"号""-"$4}'//以“用户是.. 用户UID:用户GID:”的格式输出
[root@li ~]# awk -F: '{print "用户是:"$1 "\t 用户UID:"$3 "\t 用户GID:"$4}' /etc/passwd
```
**printf 函数,式样化输出函数**
```
参数:%s 字符类型%d 数值类型- 表示左对齐,默认是右对齐#printf 默认不会在行尾自动换行,加\n
```
```
//于echo命令的输出,Linux是经管道发给awk。printf函数包含一个控制串。百分号让printf做好准备,它要打印一个占15个格、向左对齐的字符串,这个字符串夹在两个竖杠之间,并且以换行符结尾。百分号后的短划线表示左对齐。控制串后面跟了一个逗号和$1。printf将根据控制串中的格式说明来格式化字符串Linux。
[root@li ~]# echo "Linux" | awk '{printf "|%-8s|\n",$1}'
|Linux |
//字符串Linux被打印成一个占8格、向右对齐的字符串,夹在两个竖杠之间,以
换行符结尾。
[root@li ~]# echo "Linux" | awk '{printf "|%8s|\n",$1}'
| Linux|```
**FIELDWIDTHS 字段宽度列表(用空格键分隔)**
```
[root@shells ~]# echo 20190101 |awk -vFIELDWIDTHS="4 2 2" -vOFS=- '{print $1,$2,$3}'
2019-01-01
```
## 3.5 awk数组处理以下文件内容,将域名取出并根据域名进行计数排序处理:(百度和sohu面试题)
**文件内容:**
```
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html
```
**答案**
```
[root@shells ~]# awk -F"[/.]+" '{h[$2]=h[$2]+1}END{print h["www"],h["mp3"],h["post"]}' url.txt
3 1 2
[root@shells ~]# awk -F"[/.]+" '{h[$2]=h[$2]+1}END{for(i in h) print i}' url.txt
www
mp3
post
[root@shells ~]# awk -F"[/.]+" '{h[$2]=h[$2]+1}END{for(i in h) print i,h[i]}' url.txt
www 3
mp3 1
post 2
```
**统计access.log中每个ip地址出现次数**
```
[root@shells ~]# awk '{h[$1]++}END{for(i in h) print i,h[i]}' access.log |sort -rnk2 |head
58.220.223.62 12049
112.64.171.98 10856
114.83.184.139 1982
117.136.66.10 1662
115.29.245.13 1318
223.104.5.197 961
116.216.0.60 957
180.111.48.14 939
223.104.5.202 871
223.104.4.139 869
实时统计
[root@Shell ~]# ss -an|awk -F ':' '/:80/{ips[$(NF-1)]++} END {for(i in ips){print i,ips[i]}}'
```
**3.5.1 统计access.log中每个状态码出现次数**
```
[root@shells ~]# awk '{h[$9]++}END{for(i in h) print i,h[i]}' access.log |sort -rnk2 |head
200 142666
304 18712
404 3863
302 789
499 418
400 242
301 146
413 50
403 37
408 13
```
**3.5.2 统计每个ip地址使用的总流量**
```
[root@shells ~]# awk '{h[$1]=h[$1]+$10}END{for(i in h) print i,h[i]}' access.log |sort -rnk2 |head
114.83.184.139 31362956
117.136.66.10 22431302
116.216.30.47 21466000
223.104.5.197 21464856
116.216.0.60 19145329
114.141.164.180 17219553
114.111.166.22 17121524
223.104.5.202 16911512
116.228.21.187 15969887
112.64.171.98 15255013
```
**3.5.3 awk脚本**
```
#!/bin/awk#awk '{h[$1]=h[$1]+$10}END{for(i in h) print i,h[i]}' access.log
{h[$1]=h[$1]+$10
}
END{
for(i in h) print i,h[i]
}
[root@shells ~]# awk -f ip.awk access.log
```
## 3.5.4 awk函数注意事项awk '//'#awk '$NF~/bash/' /etc/passwd #最后一列中包含bash #awk '/bash/' /etc/passwd #这一行中只要有bash就行 #awk '$0~/bash/' /etc/passwd #这一行中只要有bash就行 **awk 只有条件的时候,默认的动作**
```
awk '/bash/{print $0}' /etc/passwd
```
**3.5.5 企业面试题:请过滤range.log中在device: {}里面出现了多少次oldboy,过滤并统计出来**
**环境:**
```
oldboy is a linuxer.
device: {
oo
oldboy
no sql
this is log
niu niu
}
oldboy
device: {
oldboy
no sql
this is log
niu niu
}
oldboy
device: {
oldboy
no sql
this is log
niu niu
}
device: {
oldboy
no sql
this is log
niu niu
}
```
**答案:**
```
[root@web01 oldboy]# awk '/{/,/}/' 1.txt|grep -c 'oldboy'
4[root@web01 oldboy]# awk '/{/,/}/{if(/oldboy/)i++}END{print i}' 1.txt
4
```
**3.5.6 统计2018年01月25日,当天的PV量***
```
[root@Shell ~]# grep "25/Jan/2018" log.bjstack.log |wc -l
[root@Shell ~]# awk "/25\/Jan\/2018/" log.bjstack.log |wc -l
[root@Shell ~]# awk '/25\/Jan\/2018/ {ips[$1]++} END {for(i in ips) {sum+=ips[i]} {print sum}}' log.bjstack.log//统计15-19点的pv量
[root@Shell ~]# awk '$4>="[25/Jan/2018:15:00:00" && $4<="[25/Jan/2018:19:00:00 {print $0}"' log.bjstack.log |wc -l
```**3.5.7 统计日志中每分钟每个ip地址访问次数**
**原文:日志的第一行内容**
```
[root@web01 ~]# head -1 access.log
101.226.61.184 - - [22/Nov/2015:11:02:00 +0800] "GET /mobile/sea-modules/gallery/zepto/1.1.3/zepto.js HTTP/1.1" 200 24662 "http://m.oldboyedu.com.cn/mobile/theme/ppj/home/index.html" "Mozilla/5.0 (Linux; U; Android 5.1.1; zh-cn; HUAWEI CRR-UL00 Build/HUAWEICRR-UL00) AppleWebKit/533.1 (KHTML, like Gecko)Version/4.0 MQQBrowser/5.4 TBS/025478 Mobile Safari/533.1 MicroMessenger/6.3.7.5
```
**答案:**
```
方法一:
[root@web01 ~]# awk -F'[[/: ]' '{a[$1" "$4"/"$5"/"$6":"$7":"$8":"$9]++}END{for (i in a) print i,a[i]}' access.log |sort -rnk3|head
112.64.171.98 /22/Nov:2015:11:20 570
58.220.223.62 /22/Nov:2015:11:56 433
58.220.223.62 /22/Nov:2015:11:42 426
112.64.171.98 /22/Nov:2015:11:19 426
112.64.171.98 /22/Nov:2015:11:18 402
112.64.171.98 /22/Nov:2015:11:40 395
112.64.171.98 /22/Nov:2015:11:05 392
58.220.223.62 /22/Nov:2015:11:08 373
58.220.223.62 /22/Nov:2015:11:47 333
112.64.171.98 /22/Nov:2015:11:09 321方法二: substr
[root@web01 files]# awk '{t=substr($4,2,17);h[$1" "t]++}END{for (i in h)print i,h[i]}' access.log |sort -rnk3|head
112.64.171.98 22/Nov/2015:11:20 570
58.220.223.62 22/Nov/2015:11:56 433
58.220.223.62 22/Nov/2015:11:42 426
112.64.171.98 22/Nov/2015:11:19 426
112.64.171.98 22/Nov/2015:11:18 402
112.64.171.98 22/Nov/2015:11:40 395
112.64.171.98 22/Nov/2015:11:05 392
58.220.223.62 22/Nov/2015:11:08 373
58.220.223.62 22/Nov/2015:11:47 333
112.64.171.98 22/Nov/2015:11:09 321
思路:将ip地址和时间通过分隔符看做一个整体,通过(i++)加数组进行匹配,最后通过for循环,sort 将某个时间段及ip出现频率最高的进行输出
```
**3.5.8 日志中每个用户被破解了多少次**
```
[root@web01 files]# awk '/Failed password/{h[$(NF-5)]++}END{for (i in h) print i,h[i]}' secure-20161219 |sort -rnk2|head
root 364610
admin 725
user 245
oracle 119
support 104
guest 79
test 70
ubnt 47
pi 41
webadmin 36
```
**3.5.9 那个IP地址破解的用户登录的次数最多**
```
[root@web01 files]# awk '/Failed password/{h[$(NF-3)]++}END{for (i in h) print i,h[i]}' secure-20161219 |sort -rnk2|head
218.65.30.25 68652
218.65.30.53 34326
218.87.109.154 21201
112.85.42.103 18065
112.85.42.99 17164
218.87.109.151 17163
218.87.109.150 17163
218.65.30.61 17163
218.65.30.126 17163
218.65.30.124 17163
```
**3.5.10 统计日志中,每个ip访问的次数和每个ip使用的流量总数;优先按照ip出现的次数排序,然后根据流量大小进行排序**
```
[root@web01 files]# awk '{ip[$1]++;li[$1]+=$10}END{for (i in ip )print i,ip[i],li[i]/1024^2}' access.log |sort -rnk2 -k3|head58.220.223.62 12049 12.0192
112.64.171.98 10856 14.5483
114.83.184.139 1982 29.91
117.136.66.10 1662 21.3922
115.29.245.13 1318 1.10766
223.104.5.197 961 20.4705
116.216.0.60 957 18.2584
180.111.48.14 939 12.9787
223.104.5.202 871 16.1281
223.104.4.139 869 8.0237
原理:awk的运算的时候都调用了$1这个变量行,所以执行的时候,两个数组都会一起执行,到输出的时候书写任一数组,另外一数组也会被赋值进来
```**3.5.11 统计系统中管理用户,普通用户,虚拟用户的个数**
```
[root@web01 ~]# cat /etc/passwd|awk -F: '{if($3==0){i++}else if($3+0>=1000){a++}else if($3>0 && $3<1000){j++}}END{print "管理员用户有"i"个","普通用户有"a"个","虚拟用户有"j"个"}'
管理员用户有1个 普通用户有29个 虚拟用户有25个
```
**统计2018年01月25日,访问状态码为404及出现的次数($status)***
```[root@Shell ~]# grep "404" log.bjstack.log |wc -l
[root@Shell ~]# awk '{if($9=="404") code[$9]++} END {for(i in code){print i,code[i]}}' log.bjstack.log
```
**统计2018年01月25日,8:30-9:00访问状态码是404***
```[root@Shell ~]# awk '$4>="[25/Jan/2018:15:00:00" && $4<="[25/Jan/2018:19:00:00" && $9=="404" {code[$9]++} END {for(i in code){print i,code[i]}}' log.bjstack.log
[root@Shell ~]# awk '$9=="404" {code[$9]++} END {for(i in code){print i,code[i]}}' log.bjstack.log
```
**统计2018年01月25日,各种状态码数量***
```
//统计状态码出现的次数
[root@Shell ~]# awk '{code[$9]++} END {for(i in code){print i,code[i]}}' log.bjstack.log
[root@Shell ~]# awk '{if($9>=100 && $9<200) {i++}
else if ($9>=200 && $9<300) {j++}
else if ($9>=300 && $9<400) {k++}
else if ($9>=400 && $9<500) {n++}
else if($9>=500) {p++}}
END{print i,j,k,n,p,i+j+k+n+p}' log.bjstack.log
```