1 对抗学习
对抗学习的目的是增加鲁棒性。
对抗生成网络(GAN)包括生成器(Generator)和判别器(Discriminator)。如果目标是创建能够生成新内容的系统,那么生成器是希望得到并优化的模型,这是一个零和问题。

1.1 GenB
GenB是对抗网络用于VQA的产物,如图添加了偏置模型和目标模型。
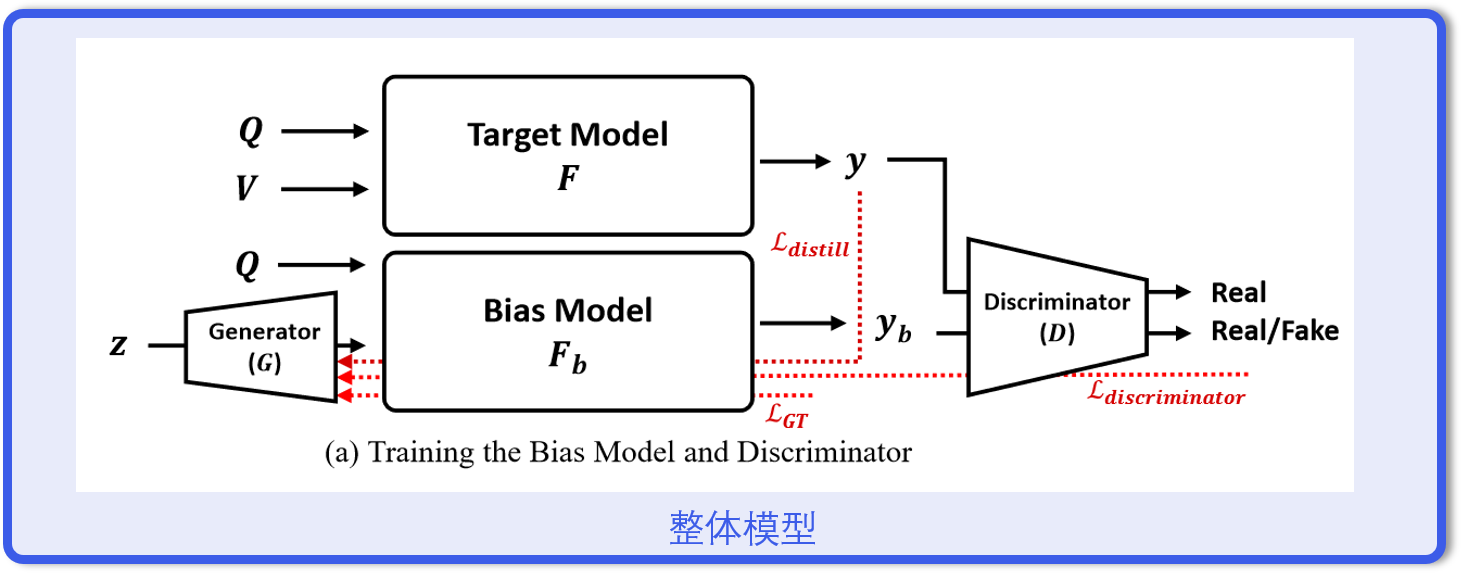
训练偏置模型
传统的VQA损失函数是BCE,即
在这个情境下,额外引入对抗训练,对于损失函数
生成器希望损失函数尽可能小,判别器希望损失函数尽可能大。
此外,还用知识蒸馏的方法训练偏置模型
整体损失函数是
纠正偏置模型
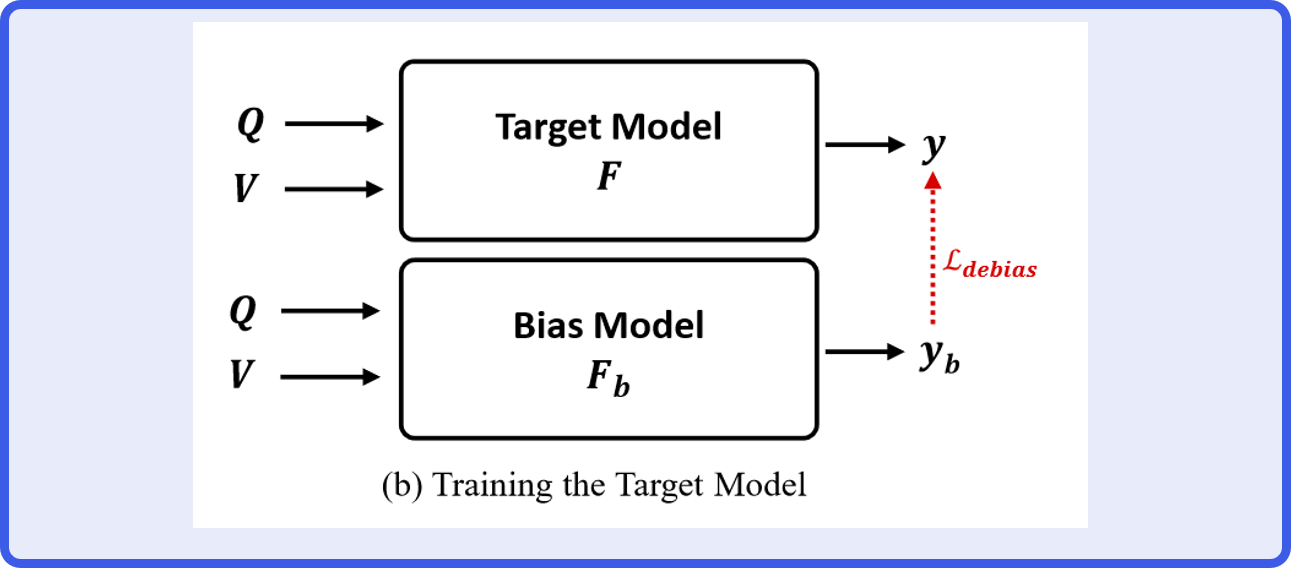
纠正偏见过程的损失函数定义为
其中
\(y_{gt},y_b\)分别代表真实答案和偏置答案。
2 迁移学习
迁移学习的目的是减少计算复杂度。
迁移学习通常是将一个在相关任务上已经训练好的模型应用到一个新的但相似的任务上。具体做法包括在特征提取器的输出上添加新的全连接层或其他分类层,以适应特定任务,然后对模型进行微调。
2.1 知识蒸馏
知识蒸馏用于将一个大型、复杂的教师模型的知识转移给一个更小、更简单的学生模型。教师模型的输出(Softmax层)包含对不同类别的预测概率,学生模型在训练过程中模仿教师模型的输出概率分布。
3 强化学习
强化学习的目的是最大化策略奖励。
强化学习的基本流程如下:
- 初始化:智能体和环境的初始状态。
- 观测:智能体在环境中观察当前状态。
- 选择行动:智能体根据其策略选择一个行动。
- 执行行动:智能体在环境中执行选定的行动。
- 获得奖励:智能体从环境中接收该行动的奖励反馈。
- 更新状态:环境根据智能体的行动更新状态。
- 学习更新:智能体利用获得的奖励和新的状态,更新其策略或价值函数。
- 重复:重复以上步骤直到满足停止条件。
3.1 AlphaGo
AlphaGo由MCTS(蒙特卡罗树搜索)和两个卷积神经网络(策略网络预测下法、价值网络预测胜率)组成。
MCTS由四部分构成:
- 选择:从根节点开始,根据UCB算法得到子节点的顺序,沿着搜索树向下进行,直到遇到一个没有完全展开的子节点。
- 扩展:扩展出可能的下一步棋局,增加新的子节点。
- 模拟:从新扩展的节点开始进行模拟,随机选择动作,直到到达终局。
- 反向传播:将模拟结果从叶节点回传到根节点,更新所有经过节点的统计数据,重新计算UCB。
结合CNN的MCTS如下:
- 选择:使用CNN的输出来指导选择优先扩展的节点,然后再用UCB作选择,直到遇到一个没有完全展开的子节点。
- 扩展:使用策略网络为新节点的所有下一步走法分配初始的概率分布。
- 模拟:使用策略网络模拟,当模拟达到预设的深度限制时(而不是完整的终局)停止模拟。在此中间状态,调用价值网络来评估该状态的胜率。
- 反向传播:将价值网络的胜率估计从当前中间状态回传到根节点,更新所有经过节点的统计数据。
UCB公式如下:
其中:
- \(Q(s,a)\)是动作\(a\)在状态\(s\)下的平均价值(exploitation)。
- \(P(s,a)\)是策略网络输出的在状态\(s\)下选择动作\(a\)的概率。
- \(N(s)\)是状态\(s\)被访问的次数。
- \(N(s,a)\)是在状态\(s\)下选择动作\(a\)的次数(exploration)。
- \(c\)是一个常数,控制exploration和利用exploitation之间的平衡。
4 半监督学习
半监督学习的目的是解决标记数据稀缺的问题。
半监督学习介于监督学习和无监督学习之间。监督学习中模型训练完全依赖于标记的数据集;无监督学习中模型则是基于没有任何标签的数据进行训练。半监督学习利用少量的标记数据和大量的未标记数据来训练模型。
自训练是一种简单的半监督学习策略,其中首先使用有标签的数据训练一个初始模型,然后这个模型用来预测未标记数据的标签,选择预测最有信心的数据点及其标签重新加入训练集,再次训练模型,不断迭代进行。
5 联邦学习
联邦学习的目的是保护隐私。
联邦学习是一种在不同本地设备或节点上分别训练模型后,将更新的模型参数汇总到中央服务器进行联邦平均的方法。特别是在医院等数据隐私敏感的情况下,各个医院分别在本地使用患者数据独自训练模型,然后将训练得到的模型更新发送到中央服务器。中央服务器聚合这些更新,以更新全局模型。