创建一个webapi项目做测试使用。

创建新控制器,搭建一个基础框架,包括获取当天日期、wiki的请求地址等

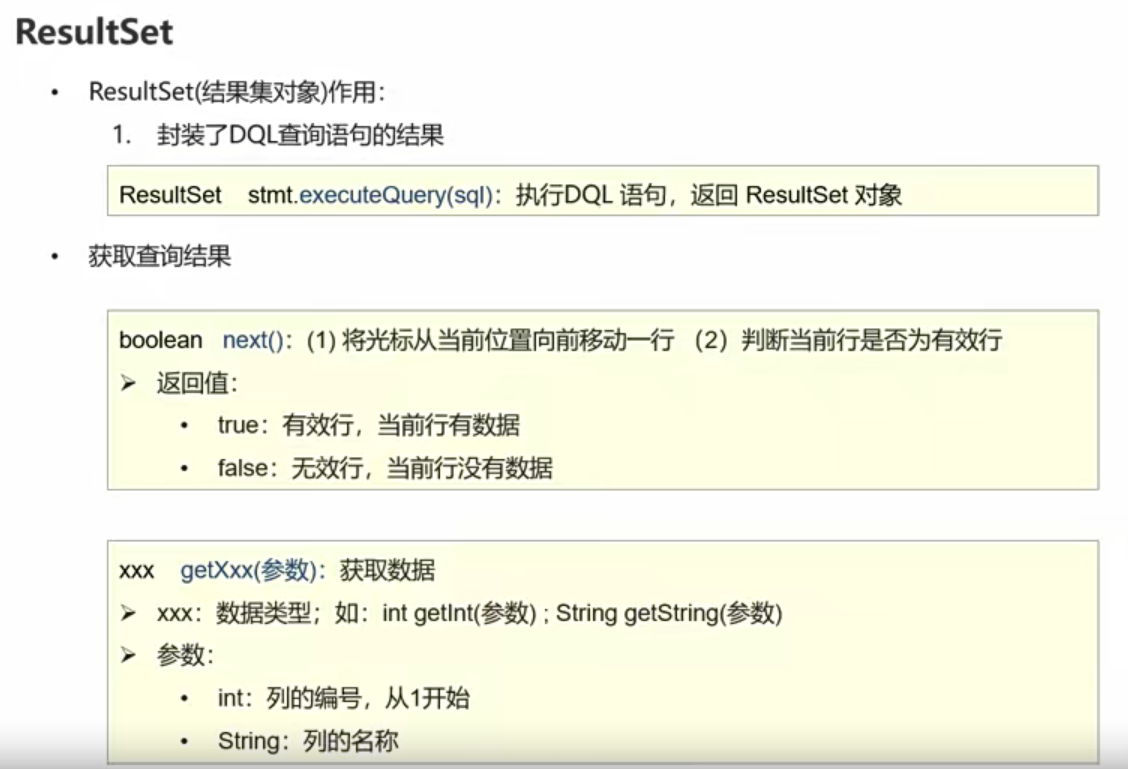
创建一个Http请求帮助类以及方法,用于获取指定URL的信息

使用http请求访问指定url,先运行一下,看看返回的内容。内容如图右边所示,实际上是一个Json数据。我们主要解析 大事记 部分的内容,位于Json的revisions字段内

定义有关实体类,用于把收到的json数据转换为对象

根据转换的对象,可以看到对象内所有需要的内容,都在Content字段里面了。由于不知道是否存在多层结构,所以此处使用循环来遍历内容。先搭建个模子。

编写一个正则表达式,根据规律,可以识别出,每个词条都是以[]的形式存在,并且存在嵌套内容,所以做一个数据清理,清理嵌套抽重复的数据。

解析出来的新文本,看起来内容舒服一点了。然后我们只需要获取[[xx年]]的这些词行数据,所以可以继续做个数据清理,匹配正则表达式

根据匹配的正则表达式内容,做个遍历输出

查看输出的内容,可以看到已经被过滤成功了:

不过默认是繁体字,咱们再完善下,做成简体字。先安装一个古老的包:ChineseConverter 有提示不用管,能用。

然后直接调用即可:
string simplifiedText = ChineseConverter.Convert(繁体中文字符串, ChineseConversionDirection.TraditionalToSimplified);
然后重新跑一下,可以看到繁体变成了简体了。

最后,剩下的一些括号等符号,或者特殊字符,只需要做一个全局替换即可。以及如果需要解析其他内容,也可以自行再开发一个对应的正则表达式即可。
如需以上源码,可在个人公众号【Dotnet Dancer】后台回复“历史上的今天” 即可获取以上源码。