这篇博客内容是我在安装开源hadoop 数据平台时候的工作日志,里面记录了部署平台的主要过程以及容易出错的步骤。
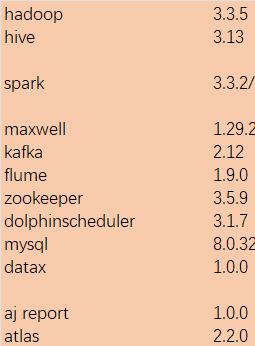
一,主要组件包括:
二,部署环境规划:
3台机器
系统:Centos 7.9
java: 1.8.220
三,部署顺序:
离线处理组件(主线组件):hadoop (存储)--hive(数仓) - spark(流式计算引擎) - dataX(数据集成)- dolphinscheduler(任务调度,任务设计) - aj report(数据可视化) -Atlas (元数据采集管理)
实时数据流组件:maxwell (对接mysql, binlog采集)- -- kafka (数据管道)-- flume(数据管道)
四,部署集群注意问题:
1,版本的兼容性
hadoop 和 hive 的兼容性问题。
hive 使用 spark 作为引擎的兼容性问题
2,注意内网的网络访问情况
2.1 防火墙设置
ssh 代理配置
ping /telnet 访问端口开放情况。
五,Hadoop 部署
5.1 ,系统环境配置:
1,配置时间服务器,进行同步:
使用天翼云的时间服务器:ntpdate ntp.ctyun.cn
(如果内网环境,需要先部署配置内网时间同步服务器)
2,内网环境内,节点之间的访问如果通过SSH代理的话,需要配置代理端口。
在${HADOOP_HOME}/etc/hadoop/hadoop-env.sh文件中,添加:
export HADOOP_SSH_OPTS="-p 9333"
5.2,安装和配置
1, 注意 hdfs-site.xml 内的 namenode 和 datanode 的数据目录配置。事前,必须查看磁盘分区情况,
配置为适合存储大量数据的数据分区。
2, block size ,依据我的项目内,数据文件普遍size 不大而且磁盘容量相对有限,而 hdfs 的默认size 是128M ,所以我减小了
block size 到 64M.
六, Hive 部署
在主节点单体部署
6.1,元数据管理数据库的配置的优化
1,使用了默认的derby元数据库。之后在dolphinscheduler中进行hive 任务运行时报错,
提示:不能在元数据库内新建元数据库。 才想起derby 元数据库只能运行一个client 的连接。
2,升级derby到 mysql 的过程。
2.1 ,添加连接包。mysql-connector-java-5.7.10.jar到$HIVE_HOME/lib
2.2,MySQL内添加hive 客户端的专用账号以及元数据db:
set global validate_password_policy=0;
create user 'hive'@'%' identified by '####'
库:create database hive_meta;
grant all on hive_meta.* to 'hive'@'%';
6.2 添加配置hive-site。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://134.98.###.###:3307/hive_meta?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>####</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value> # 根据你的mysql 版本配置
</property>
6.3 ,然后重新进行元数据初始化:
schematool -dbType mysql -initSchema
6.4, 开启hiveserver2 和 metastore
nohup $HIVE_HOME/bin/hiveserver2 &
nohup hive --service metastore &
七, Spark 部署
规划:版本:2.3.0 ,发行版:without-hadoop . 安装模式: standalone (后来改为yarn模式)
7.1 确认版本兼容性
1,从hive的源码内, 确认hive 按照spark该版本构建的。
2,spark 2.3.0的不同的发行版,没有支持3.3.5版本, 所以我们安装 without-hadoop 包。稍后需要做一些设置,满足兼容性。
7.2 spark和hadoop 兼容性配置 (参考: https://spark.apache.org/docs/2.3.0/hadoop-provided.html)
在配置文件内:conf/spark-env.sh.
export SPARK_DIST_CLASSPATH=$(/path/to/hadoop/bin/hadoop classpath)
7.2,开启standalone ,
./sbin/start-master.sh
7.3,开启一个worker:
./sbin/start-slave.sh spark://localhost:7077 (spark master url)
7.4 为Hive 配置 Spark 引擎 (参考:https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started#HiveonSpark:GettingStarted-VersionCompatibility)
1,把如下的包复制一份到HIVE_HOME/lib
scala-library spark-core spark-network-common
chill-java chill jackson-module-paranamer jackson-module-scala jersey-container-servlet-core
jersey-server json4s-ast kryo-shaded minlog scala-xml spark-launcher
spark-network-shuffle spark-unsafe xbean-asm5-shaded
2, 配置 hive-site.xml
set spark.master=<Spark Master URL> set spark.eventLog.enabled=true; set spark.eventLog.dir=<Spark event log folder (must exist)> set spark.executor.memory=512m; set spark.serializer=org.apache.spark.serializer.KryoSerializer;
八,Datax 的部署
8.1 注意:
1,依赖python 安装环境。
2,注意datax的版本情况,不同版本支持的功能有些细节上的差别,比如insert_mode 支持 ‘truncate’.
3, 测试环境可以安装datax_web,方便编写 job.json文件。
8.2 步骤:
1 安装包下载:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
2 执行自带样例通过。
python /opt/datax/bin/datax.py job/job.json
九,Dolphinscheduler 任务调度器部署
单机伪集群安装
9.1 注意事项:
1, 由于依赖mysql 和zookeeper 版本不一致,我替换 api-server 、alert-server、master-server、worker-server的 相关jar包。
9.2 安装步骤:
1, 依赖msyql服务作为任务调度服务数据库,添加MySQL用户和 调度器的专用db.
2, 在 /bin/env/dolphinscheduler_env.sh内配置(目前我只有hive ,datax 任务):
hive_home:/opt/bd/apache-hive-3.1.3-bin
datax_home: /opt/opt/datax-web/datax
十, Atlas 部署
注意:
1,官方只提供了源码包,需要自己编译成安装包。
10.1 部署步骤:
1,下载并编译源码
编译命令:
mvn clean -DskipTests package -Pdist,embedded-hbase-solr # 包括内置的hbase 、 solr.
-Drat.numUnapprovedLicenses=50000 # 出现了大量的没有认证的证书文件,添加该配置
报错过程处理:
1.1报错:Failed to execute goal org.apache.rat:apache-rat-plugin: 大量的没有认证的证书的文件,添加配置,忽略该错误。
处理方法:-Drat.numUnapprovedLicenses=50000
1.2 报错: 编译过程中,缺失包。因为时内网环境,本地的maven 仓库 和 公司级的maven repo 都没有这些包。所以手动下载jar, 然后上传到公司 maven repo.
The following artifacts could not be resolved:
org.restlet.jee:org.restlet:jar:2.4.3 (absent),
org.restlet.jee:org.restlet.ext.servlet:jar:2.4.3 (absent):
Could not find artifact org.restlet.jee:
org.restlet:jar:2.4.3 in nexus (http://134.98.6.5:8081/repository/HescRepository/) -> [Help 1]
处理方法:安装包的maven 命令。
mvn deploy:deploy-file \
-DgroupId=org.restlet.jee \
-DartifactId=org.restlet \
-Dversion=2.4.3 \
-DgeneratePom=true \
-Dpackaging=jar \
-DrepositoryId=maven-releases \
-Durl=http://134.98.6.5:8081/repository/maven-releases/ \
-Dfile=org.restlet-2.4.3.jar
mvn deploy:deploy-file \
-DgroupId=org.restlet.jee \
-DartifactId=org.restlet.ext.servlet \
-Dversion=2.4.3 \
-DgeneratePom=true \
-Dpackaging=jar \
-DrepositoryId=maven-releases \
-Durl=http://134.98.6.5:8081/repository/maven-releases/ \
-Dfile=org.restlet.ext.servlet-2.4.3.jar
mvn deploy:deploy-file \
-DgroupId=org.apache.sqoop \
-DartifactId=sqoop \
-Dversion=1.4.6.2.3.99.0-195 \
-DgeneratePom=true \
-Dpackaging=jar \
-DrepositoryId=maven-releases \
-Durl=http://134.98.6.5:8081/repository/maven-releases/ \
-Dfile=sqoop-1.4.6.2.3.99.0-195.jar
1.3 报错:内网编译,需要配置 http ,https 代理上网。
处理方法:
-Dhttps.proxyHost=10.80.101.### -Dhttps.proxyPort=9218
-Dhttps.proxyHost=10.80.101.### -Dhttps.proxyPort=9218
2,启动atlas 服务时,内部会同时启动内置的hbase ,solr , zookeeper, kafka.
使用bin/atlas_start.py 一键启动时, 可能导致内置的部分服务不能启动,最后atlas 不能正常启动。
建议手动启动:
2.1 启动hbase: hbase/bin/start-hbase.sh
2.2 启动solr: solr/bin/solr start -c -z 127.0.0.1:2181 -p 8983 -force
2.2 启动 atlas: bin/atlas_start.py
启动过程中,同时关注启动日志。 有些进程看起来启动正常了,但是日志有报错情况。真正的情况时,服务启动失败的。
3,配置hive 连接到atlas 的元数据库管理。
hive_hook 编译包: /opt/bd/apache-atlas-sources-2.2.0/distro/target
3.1,配置hive: hive-site.xml
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
3.2,执行:bin/import-hive.sh
报错: ClassNotFoundException: org.apache.hadoop.hive.ql.metadata.InvalidTableException
方法:因为hive和atlas安装在不同的节点。 导入了hive 安装包到该机器。
报错:NoClassDefFoundError: javax/ws/rs/core/Link$Builder
方法:在atlas的path 内,增加缺失的jar包:javax.ws.rs-api-2.0.1.jar