更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
火山引擎数智平台 VeDI 是火山引擎推出的新一代企业数据智能平台,基于字节跳动数据平台多年的“数据驱动”实践经验,为企业提供端到端的数智产品、场景化的行业解决方案和专业的数智转型咨询。
Parquet 在字节跳动内部已广泛使用和深度优化,结合小文件合并、列级 TTL 两个应用场景,我们已经实现兼顾高查询性能下的存储成本优化。
基于 Parquet 的降本增效优化和应用,目前已经通过火山引擎数智平台 VeDI 旗下的湖仓一体 LAS 对外输出。
Parquet 在字节跳动的使用
字节跳动离线数仓默认使用 Parquet 格式进行数据存储。Parquet 作为一种列式存储的开源文件格式,在大数据领域被广泛应用,它所提供的一系列特性,如高压缩率、高查询性能等都非常契合大数据领域。
另外在数据安全方面,它提供的模块化加密功能在对数据进行保护的同时也兼顾了高查询性能。除了社区提供的一些基础能力,字节跳动也基于 Parquet 格式进行了深度优化和应用,其中包括 LocalSort/PreWhere 等功能,进一步提升了 Parquet 的存储和查询性能。另外在数据安全方面,也基于 Parquet 构建了透明加密系统,对底层数据进行加密保护的同时不影响用户的正常使用。
在实际的生产过程中,随着海量数据的持续增长,也遇到了一些问题。其中比较典型的就是小文件问题和存储成本问题。小文件问题指的是在存储系统中存在大量小文件,由于字节跳动离线存储采用的是 HDFS,大量小文件的存在会严重影响 HDFS 集群的稳定性以及数据访问的效率。
经过分析,我们发现 HDFS 中大部分数据来源于 Hive,因此治理的目标将主要针对于 Hive 数据。而在存储成本方面,海量数据带来了高额的存储成本,如何安全高效地控制存储成本也是降本增效的一大难点。
小文件合并
首先介绍在小文件治理方面的一些技术实践,主要包括小文件问题的产生原因以及小文件问题的技术解决方案。
小文件问题是怎么产生的
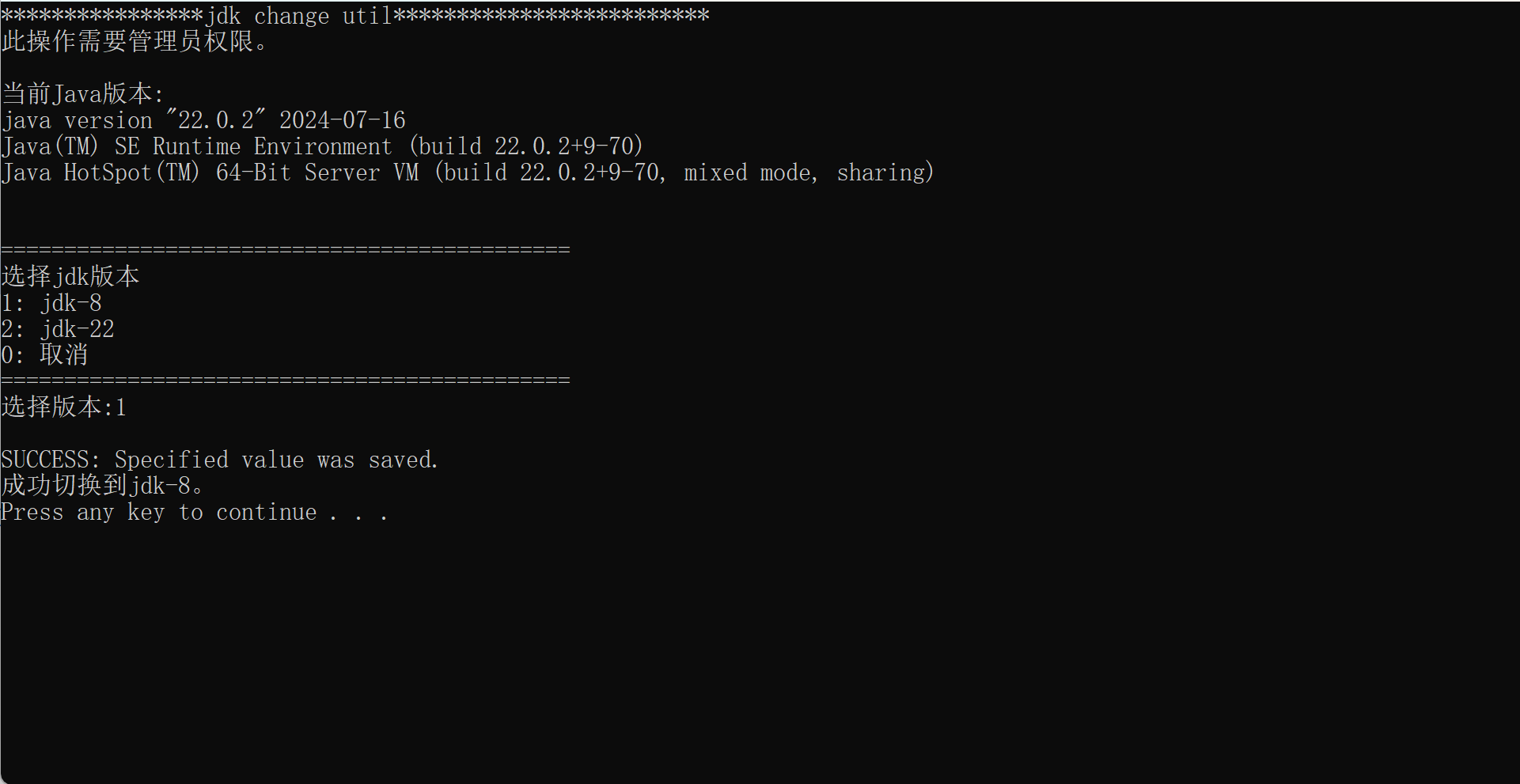
小文件问题的产生可能是由于数据源本身的问题,比如一些流式任务天然地就会按照一定时间周期产出一些小文件。
另外比较常见的是,用户在使用 Spark 等分布式引擎对数据进行处理的过程中使用了过高的并发,也会产出大量小文件,如果同时又用到了动态分区,还会进一步加剧文件数量的放大。
类似于下图中所示的例子,最终产出的文件数量是并发数乘上分区数,一个作业很容易就会产出上千甚至上万个小文件。
如何解决小文件问题
针对上文中提到的小文件问题,当下已经存在一些常见的解决方法,比如用 repartition 控制输出的并发;或者用 distribute by 控制数据的分布形式,每个分区只输出一个文件;一些情况下甚至还需要把作业拆成 2 个单独处理来应对不同的数据场景。
以上这些方法总的来说都不够灵活,对业务的侵入性较大,并且往往还涉及到繁琐的调参工作,影响工作效率。为此我们提出了一套自动化、声明式的小文件合并方案。用户只需要通过参数开启小文件合并,并设置目标文件大小,就能让作业自动输出合适的文件大小。
这种方式除了简单直接,而且合并效率也很高,这部分内容会在后文的原理中详细展开介绍。此外,该方案对静态分区和动态分区也都能很好地支持。
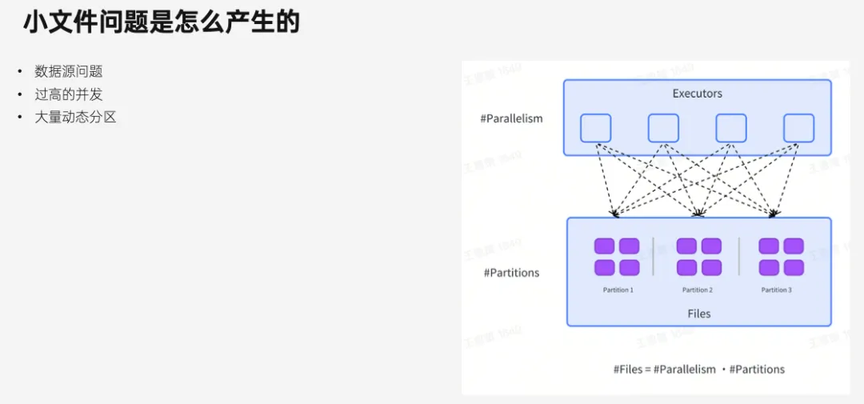
下面来介绍一下这个功能的实现原理。假设不考虑小文件问题,对于一个普通的 Spark ETL 作业来说,数据经过计算后会先写到目标表的各个分区目录下,然后 Spark 会触发 Hive 表元信息的更新,这时候数据就对下游正式可见了。
而当用户开启了小文件合并后,我们会在更新元数据,也就是数据可见之前插入小文件合并操作。具体来说,就是检查各个分区下的文件是否满足大小要求。如果发现文件太小,就会在这个分区下触发小文件合并。
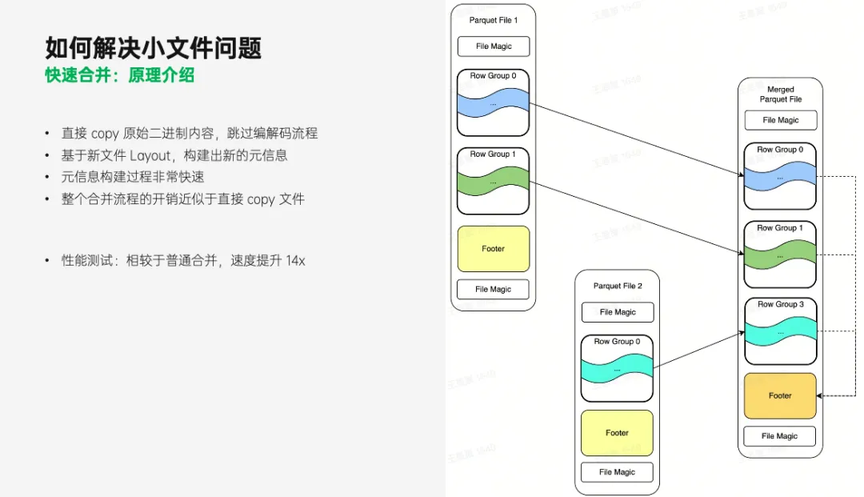
对于那些已经满足要求的分区,则是直接跳过,不做任何操作。这种按需合并的方式是合并效率高的一个原因,而另一个原因则是我们采用了快速合并技术。
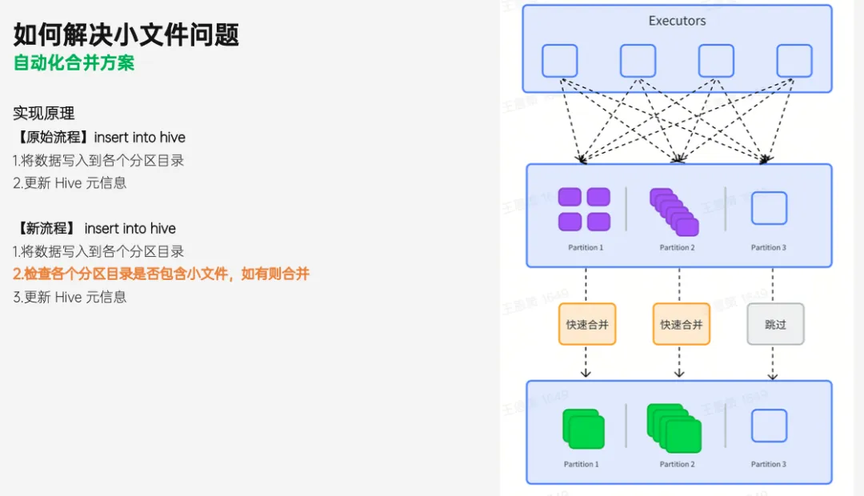
小文件合并的核心是如何把一个分区下的多个 Parquet 小文件合并成一个,由于 Parquet 格式具有特殊的编码规则,文件内部被划分为多个功能子模块,我们不能直接把 2 个 Parquet 文件首尾拼接进行合并。
常规的做法是需要用 Spark 读取这些小文件,提取出文件中的一行行记录,然后再写成新的文件。在这个一读一写的过程中,会涉及到大量的压缩反压缩、编码反编码等等操作,这些操作消耗了大量的计算资源。
为了提高合并速度,我们采用了一种快速合并的方式,这种方式借鉴了 Parquet 社区所提供的 merge 工具,能够快速地将多个 Parquet 文件合并成一个,下面介绍一下它的实现原理。
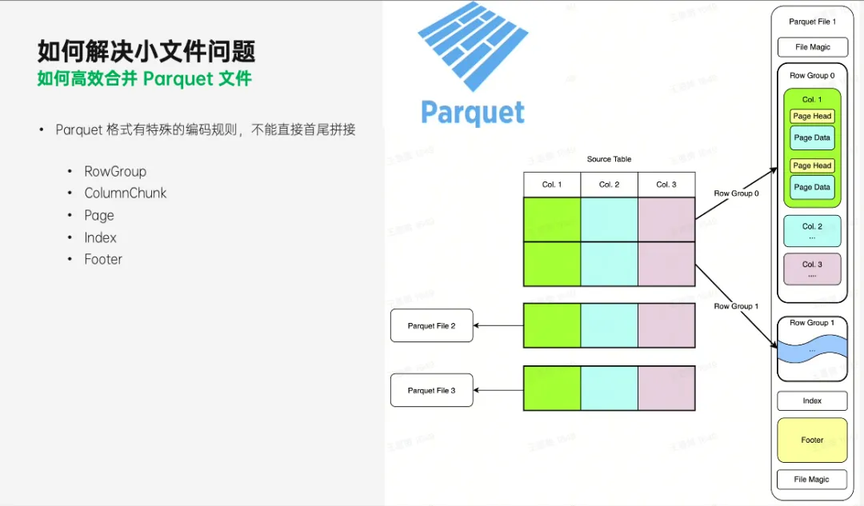
Parquet 文件的内部有很多内容,例如 Footer、RowGroup 等等。这些内容可以分为 2 类,一类是被压缩和编码后的实际数据,而另一类则是记录了数据是如何被编码和排列的元数据。快速合并的基本思路就是:直接 copy 实际数据所对应的原始二进制 Data(跳过编解码流程),再基于数据在新文件中的位置构建出新的元信息。
元信息构建过程非常快速,因此整体开销近似于直接 copy 整个文件。值得注意的是,这种合并方式并不会合并 RowGroup,因此对压缩率和查询性能并不会有明显提升,但是却极大地提升了合并效率,而文件数量的减少最终有效降低了 HDFS 集群的压力。
经过性能测试, 快速合并上相比于普通合并有 14 倍左右的提升。根据线上任务的实际运行情况,作业在开启快速小文件合并后,平均运行时长只增加了 3.5% 左右,可以看到对业务的影响很小。
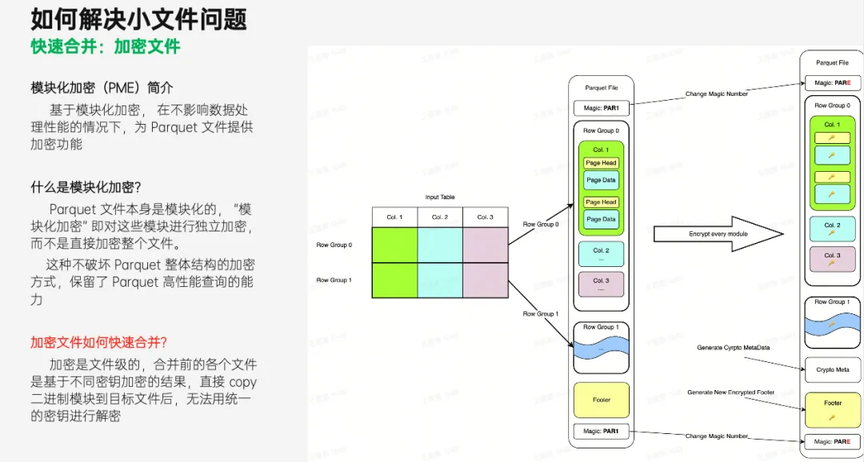
另外,在实际生产环境中,为了数据安全,Parquet 文件是被加密存储的,并且为了保证高查询性能,加密存储采用的是模块化加密的方式,也就是对文件中的各个模块分别加密。
这种加密方式保留了 Parquet 文件的基本结构,从而保留了 Parquet 高性能查询的能力。但在小文件合并过程中,这也带来了新的挑战。
我们无法像之前的模式那样直接 copy 二进制数据,因为各个文件的数据是基于不同密钥加密的结果,密钥信息保存在每个文件的 Footer 中,直接 copy 二进制模块到目标文件后,无法用新文件中的统一密钥进行解密。
为此需要在原有快速合并的基础上,在 copy 二进制模块的同时加上解密和再加密操作,用原文件中的密钥解密,然后再用新文件的密钥进行加密。整体流程上还是以 copy 二进制数据为主,跳过了编码反编码之类的多余操作,实现快速合并。
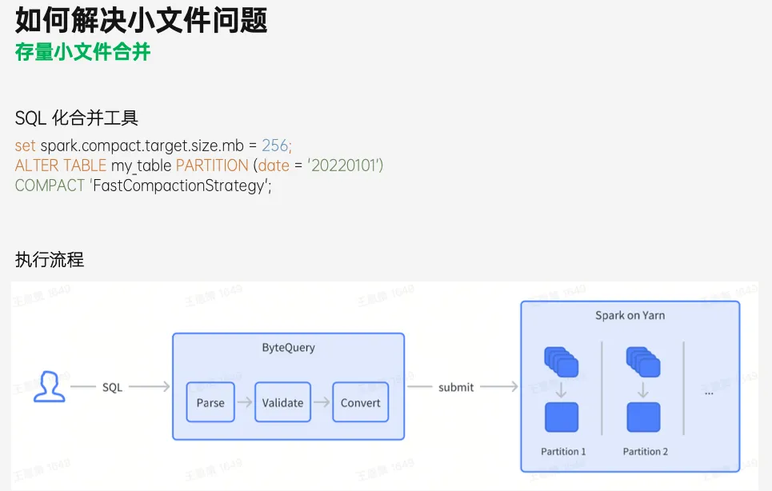
以上介绍了如何在数据产出的同时合并小文件,在实际情况中,HDFS 集群上会存在着大量历史小文件,为此我们提供了存量小文件合并工具进行处理,其使用方法也是非常简单:用户提交一个 SQL,在 SQL 中制定合并的那张表、分区、合并的目标文件大小。SQL 提交后,系统就会启动一个 Spark 作业,再结合刚刚提到的工具和流程对存量数据进行快速合并。
小结:我们在增量和存量场景都提供了对应的小文件合并能力,以一种简单高效的方式对小文件进行综合治理,提升了整个集群的健康度和稳定性,最终有效降低了机器成本和人力运维成本。
列级 TTL
上文介绍了在解决小文件问题时的相关实践。接下来将介绍 Parquet 格式在字节跳动另一降本增效实践——列级 TTL 相关的内容。
列级 TTL 产生的背景
-
随着业务发展,海量数据的存储成本逐渐成为离线数仓的一大痛点。而目前离线数仓清理存储只有分区级的行级 TTL 方案,类似于使用 alter table drop partition 的 DDL 来完成分区数据的整体删除。对于具有时间跨度较大汇总需求的表,则需要保留较长时间的历史分区,而这些历史分区中很多明细数据在汇总任务中并不会使用,也就是历史分区中存在很多低频访问字段。如果想删除这些不再使用的字段数据,目前已有的方式就是通过 Spark 等引擎将数据读取出来,并将需要删除的字段设置为 NULL 的覆写方式来完成。这种方式有两个缺点:海量数据的覆写计算资源开销很大;
-
对于字段较多的大宽表,用户需要在 select 中罗列出所有字段,并对需要删除的字段逐个置空,TTL 任务运维成本高。
轻量级列级 TTL 方案
针对以上业务存在的痛点,结合 Parquet 列存的特性,提出了一种如下图所示的轻量级的列级 TTL 方案。
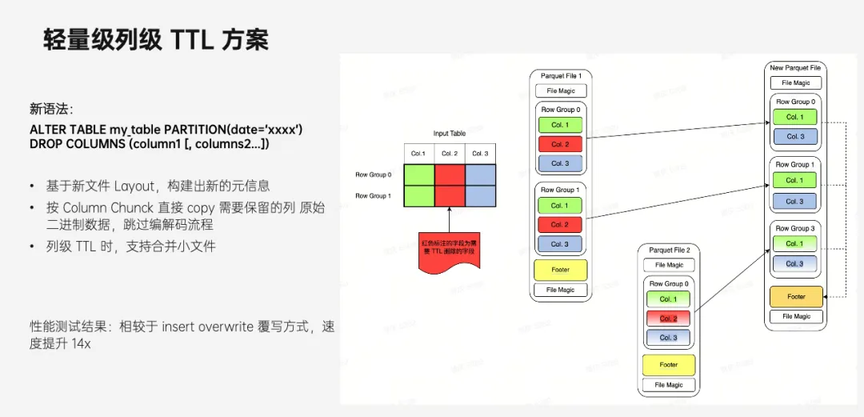
该方案按照 Column chunck 直接 Copy 每个 RowGroup 中需要保留的列的二进制数据,跳过编解码流程。举一个例子,假如表有 1、2、3 列,现在需要删除第 2 列数据。
首先要做的是构造新的 schema,从原文件 schema 中删除需要 TTL 的列(第 2 列)并作为新文件的 schema,然后从原文件中按照 Column Chunk copy 第 1 列和第 3 列的数据到新文件中。在进行列级 TTL 时,因为删除了部分列数据,会导致新文件 size 变小,容易出现小文件问题,所以我们支持将原来多个文件的数据合并到同一个文件中。
这种列级 TTL 的方式,相比于 insert overwrite 覆写的方式,速度能够实现提升 14 倍 +。前文还提到 insert overwrite 方式需要在 select 中枚举所有列,为了方便业务方使用这个列级 TTL 功能,我们定义了一种新的语法来支持列级 TTL 功能:alter table ${db.table} partition(${part_name}) drop columns(xxx)。
用户只需指定需要执行列级 TTL 的库表分区以及需要删除的列即可,不用再把其他不需要删除的列也一一列举,然后往数据引擎提交这个 SQL,就能触发列级 TTL 任务的执行。
列级 TTL 功能实现到落地还涉及到一个问题,就是如何高效的发现哪些分区下的哪些列能够进行列级 TTL。
LAS 团队开发了一个列级血缘的分析工具,支持快速分析表历史分区查询情况,然后自动推荐能够进行列级 TTL 的 columns 及对应的 TTL 时间,比如某张表 column A 90 天前基本无用户查询,那么 90 天前的历史分区中 column A 可以进行 TTL;Column B 120 天前的数据无用户查询,可以进行列级 TTL 等。
列级 TTL 在字节跳动主要应用于历史低优数据的清理,大 JSON、大 MAP 类型字段的清理或者明细日志的数据清理。该功能上线后已经为公司清理了大量的无用历史数据,释放了较大的存储空间。
结合字节跳动自身经验,火山引擎数智平台 VeDI 不断对 Parquet 这项开源技术进行优化和重构,进一步提升性能,并兼顾存储成本。未来,火山引擎数智平台 VeDI 也将凭借卓越的技术能力和丰富的行业经验,持续为更多用户提供了优质的数据技术服务,助力企业实现数字化转型。