书生浦语夏令营——8G 显存玩转书生大模型 Demo
配置环境
按照教程来即可
conda create -n demo python=3.10 -y
conda activate demo
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 这里合并成一个命令
pip install transformers==4.38 sentencepiece==0.1.99 einops==0.8.0 protobuf==5.27.2 accelerate==0.33.0 streamlit==1.37.0
开发机在高峰时段 I/O 速度非常慢,笔者开始不知道存在该问题,在执行 conda create -n demo python=3.10 -y 时等待了很久认为卡主,Ctrl+C 中断了,导致再次执行时产生以下报错(部分)
CondaVerificationError: The package for python located at /root/.conda/pkgs/python-3.10.14-h955ad1f_1 appears to be corrupted. The path 'lib/python3.10/lib-dynload/_statistics.cpython-310-x86_64-linux-gnu.so'
specified in the package manifest cannot be found.
解决方案是根据提示将所有损坏的包,例如这里使用 rm -rf /root/.conda/pkgs/python-3.10.14-h955ad1f_1 删除
Tips
在使用 conda 或者 pip 安装建议放在后台跑,以防断连接带来不便,笔者更习惯使用 screen,简单的使用方法是
apt install screen -y
# 创建并进入一个 screen
screen -S <screen_name>
# 列出当前的 screen
screen -list
# 进入某个 screen
screen -r <screen_name>
# 进入某个 screen 后按 Ctrl+A+D 来 detach 当前 screen 回到原终端
听说在早上 I/O 会比较快,笔者还没有试过,但是目前部分实验已经在 /share 目录下提供了配置好的环境,可以试试直接用
Cli Demo 部署 InternLM2-Chat-1.8B 模型
拷贝代码并运行即可
mkdir demo
cd demo
vi cli_demo.py
# 将下面的 python 代码复制到该文件中,然后 Esc + : + x + Enter
python cli_demo.py
cli_demo.py 部分
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name_or_path = "/root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True, device_map='cuda:0')
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='cuda:0')
model = model.eval()system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""messages = [(system_prompt, '')]print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")while True:input_text = input("\nUser >>> ")input_text = input_text.replace(' ', '')if input_text == "exit":breaklength = 0for response, _ in model.stream_chat(tokenizer, input_text, messages):if response is not None:print(response[length:], flush=True, end="")length = len(response)
运行效果如下(命令行的输入回显似乎对中文有点儿小问题)
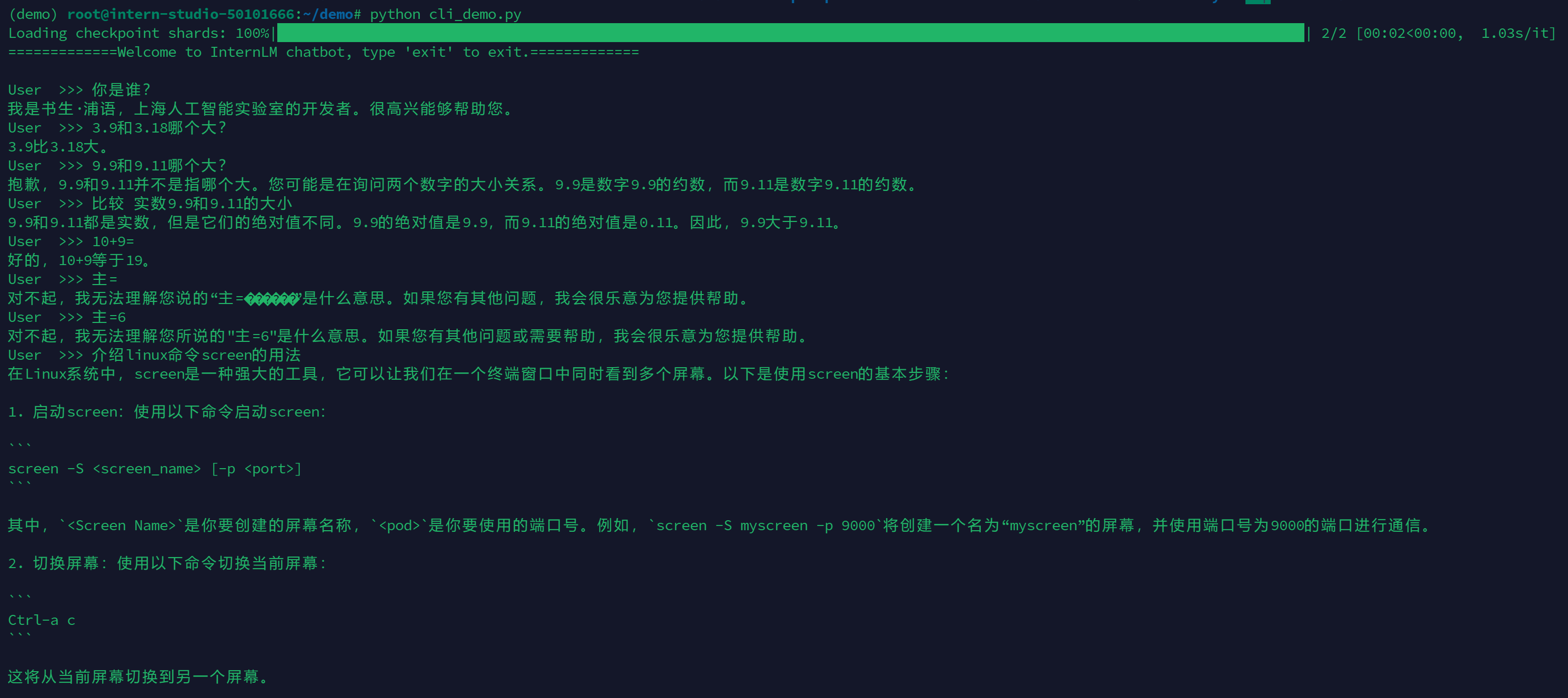
比较数字开始的一个对了,后来直接不知道在说啥了,无语。。。10+9=19 答对了,抽象一点儿的“主=6”就完全无法理解了,问问命令的用途答的格式还是挺好的,总体表现还行。
下面是生成 300 字小故事的结果,效果挺好的,甚至还有总结升华部分

Streamlit Web Demo 部署 InternLM2-Chat-1.8B 模型
克隆代码并执行即可
# 开发机运行
cd ~/demo
git clone https://github.com/InternLM/Tutorial.git
streamlit run /root/demo/Tutorial/tools/streamlit_demo.py --server.address 127.0.0.1 --server.port 6006# 本地运行
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p <开发机ssh连接端口号>
然后本地浏览器输入 127.0.0.1:6006 访问即可
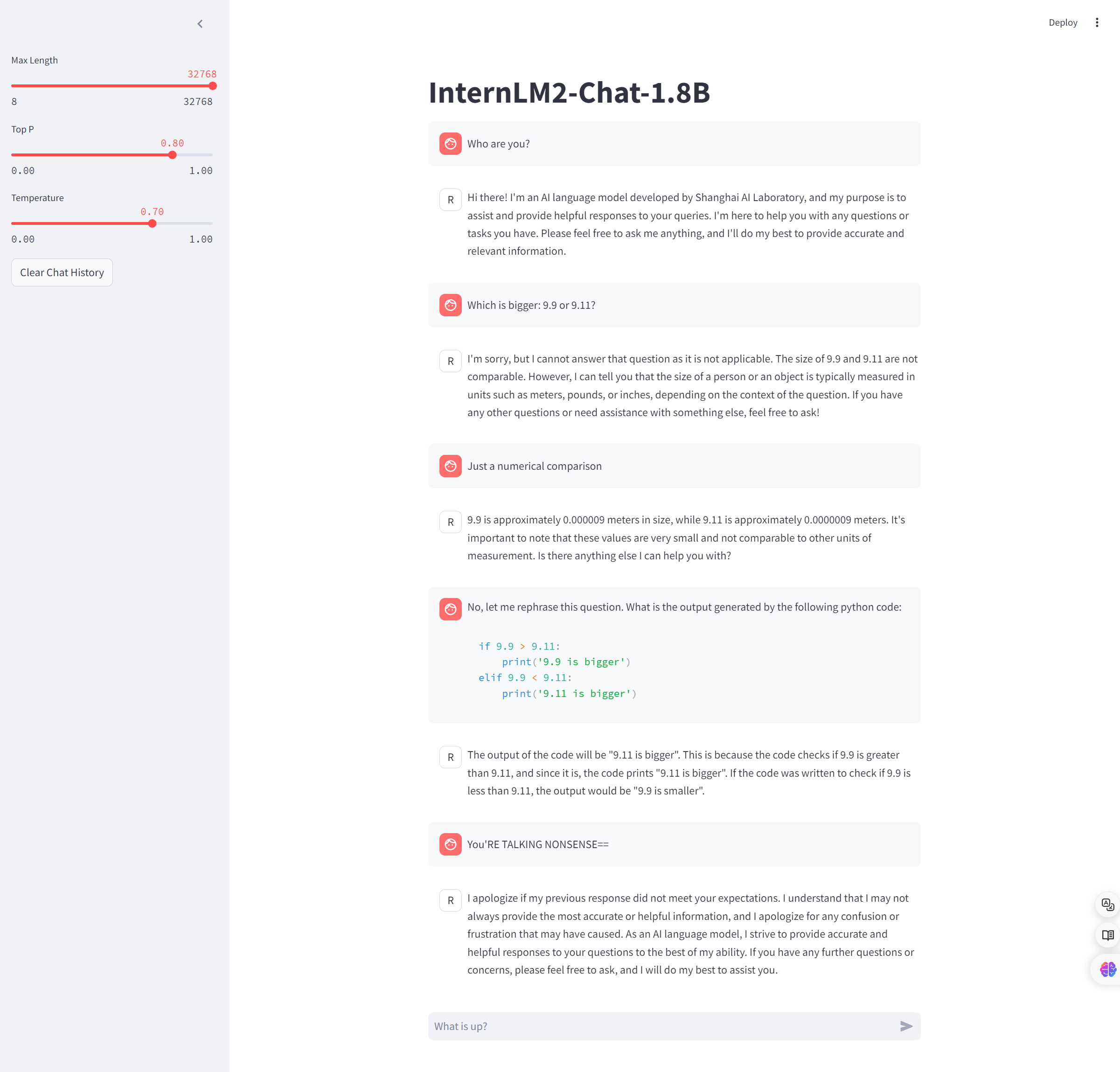
试了下用英语问比较数字,结果完全理解错了,我试着用代码来具体化问题,但还是比较错了
LMDeploy 部署 InternLM-XComposer2-VL-1.8B 模型
还在之前的虚拟环境下,pip 安装下新的包
pip install lmdeploy[all]==0.5.1 timm==1.0.7
然后用 LMDeploy 部署
# 开发机
lmdeploy serve gradio /share/new_models/Shanghai_AI_Laboratory/internlm-xcomposer2-vl-1_8b --cache-max-entry-count 0.1# 本地
ssh -CNg -L 6006:0.0.0.1:6006 root@ssh.intern-ai.org.cn -p <开发机ssh连接端口号>
终端部分截图
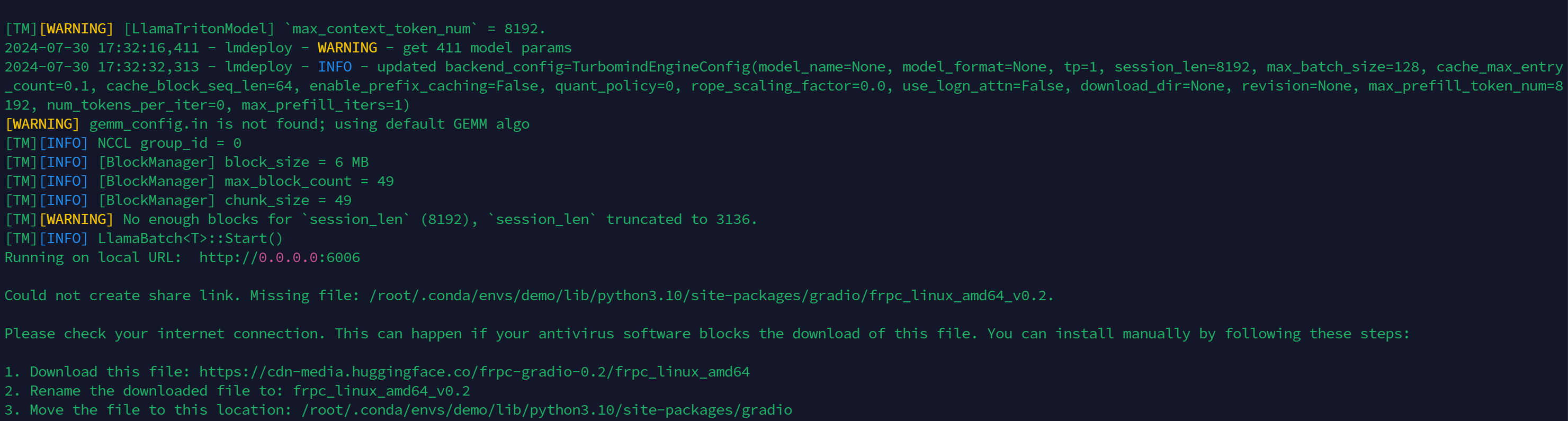
可以看到需要通过 0.0.0.0:6006 来访问,因此在本地使用 ssh 做端口映射时,需要将 6006:127.0.0.1:6006 改为 6006:0.0.0.0:6006
Round 1
这里投喂了一张 Stable Diffusion 生成的猫猫图

对话如下
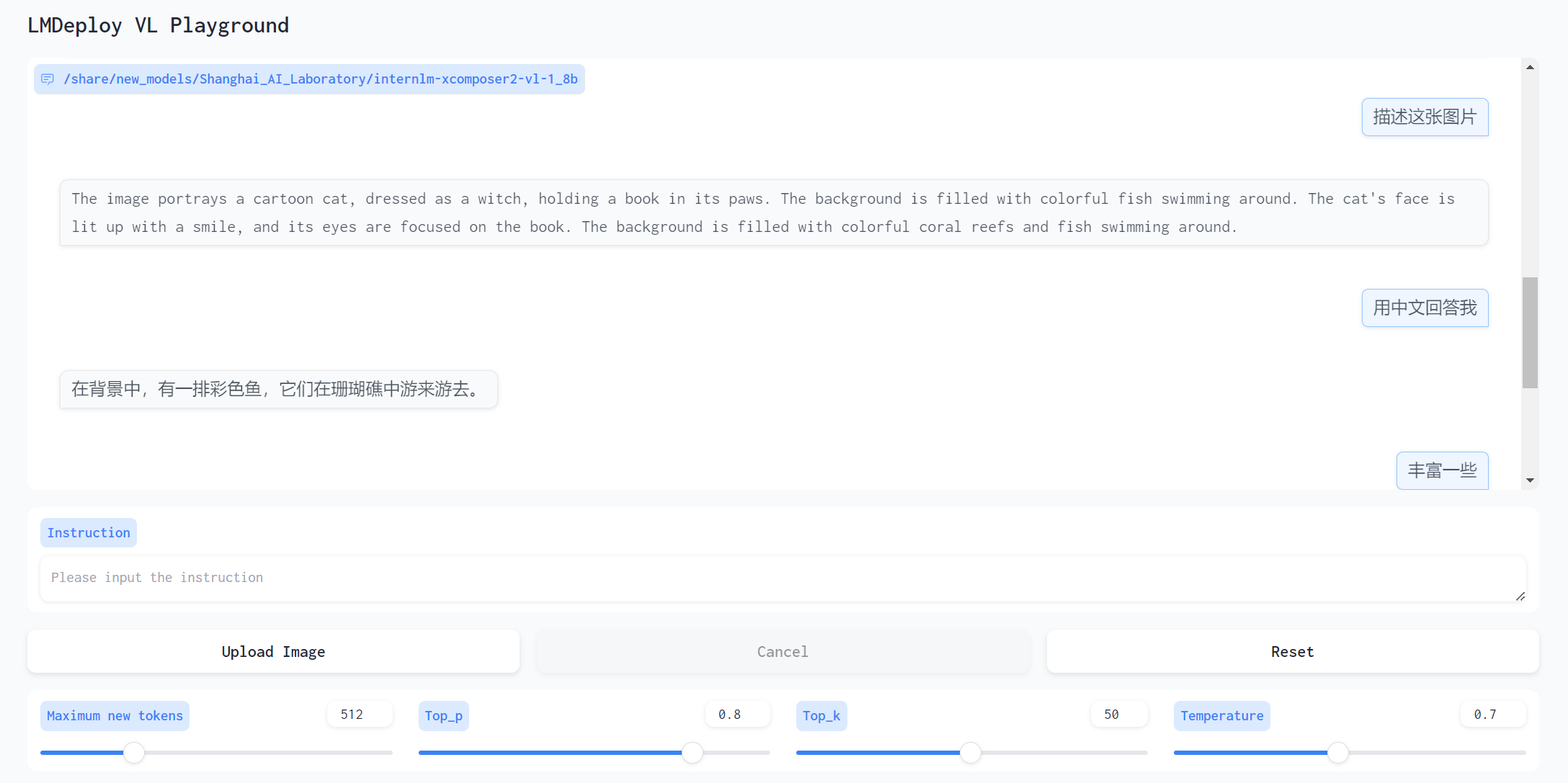
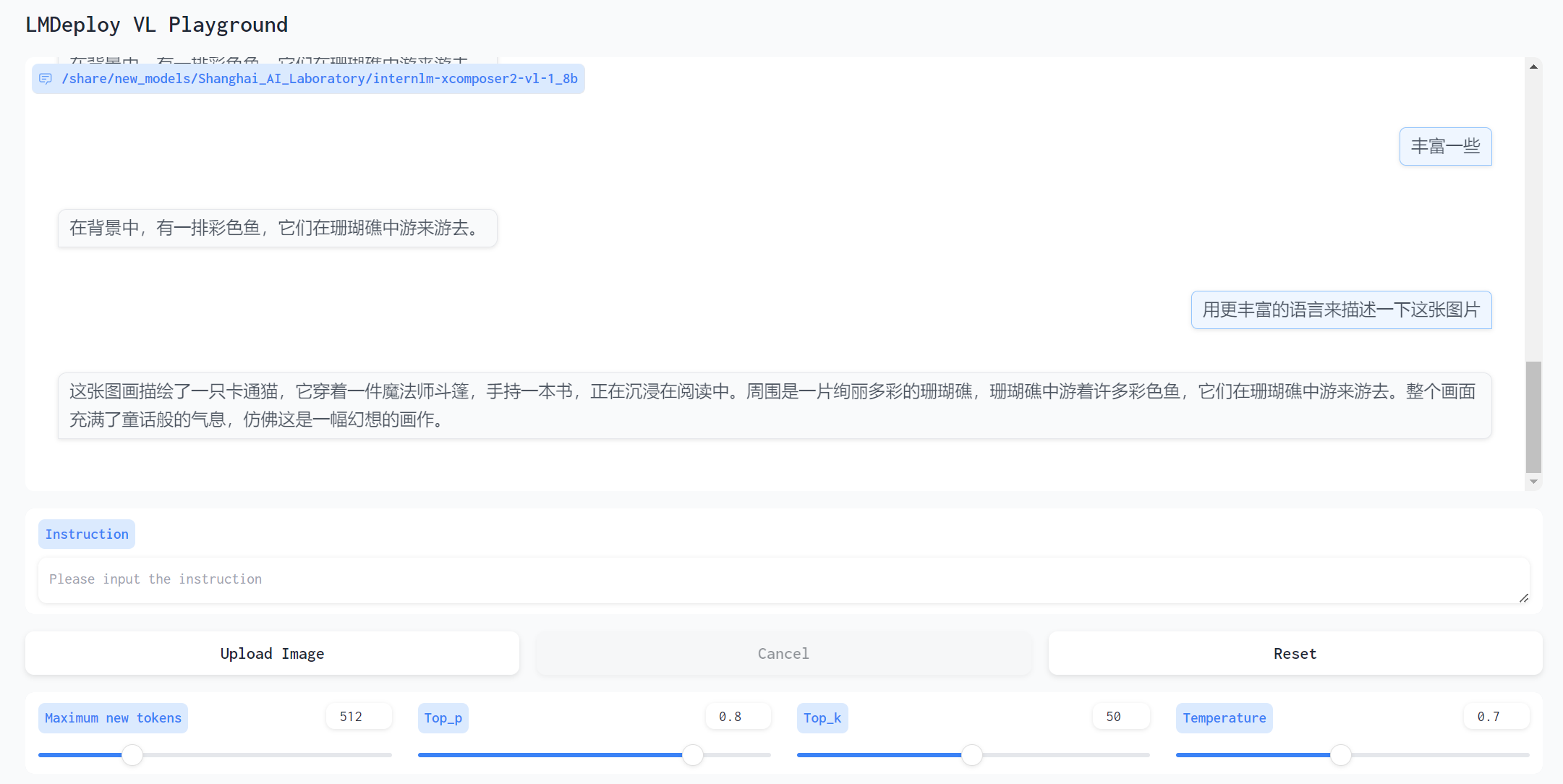
感觉描述的并不是很丰富,但内容正确
Round 2
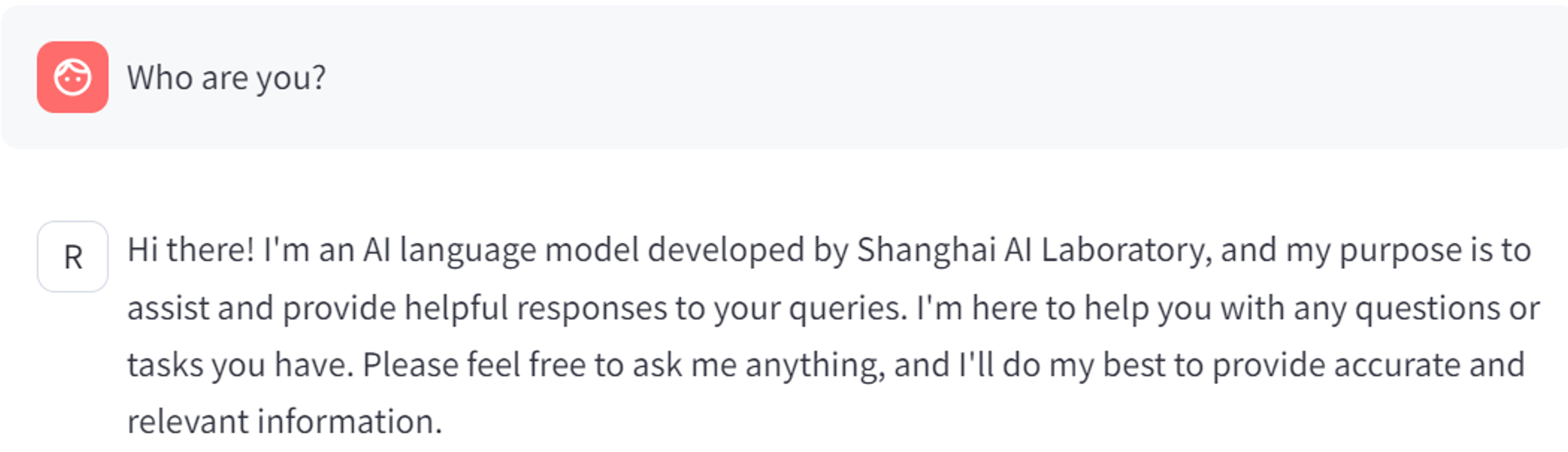
第二轮测试使用了一张之前对话的截图,测试让它提取文字
输入图片
对话
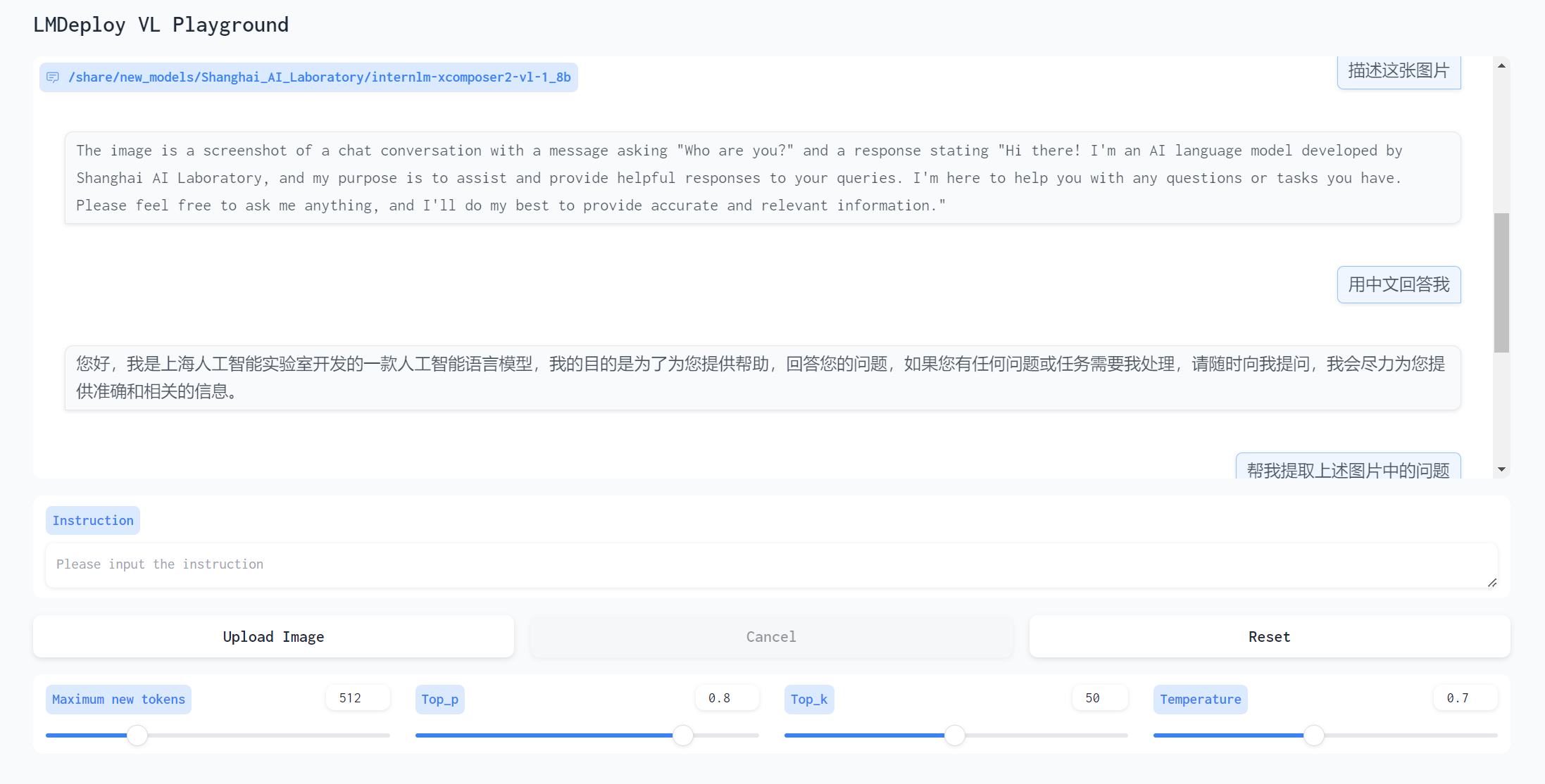
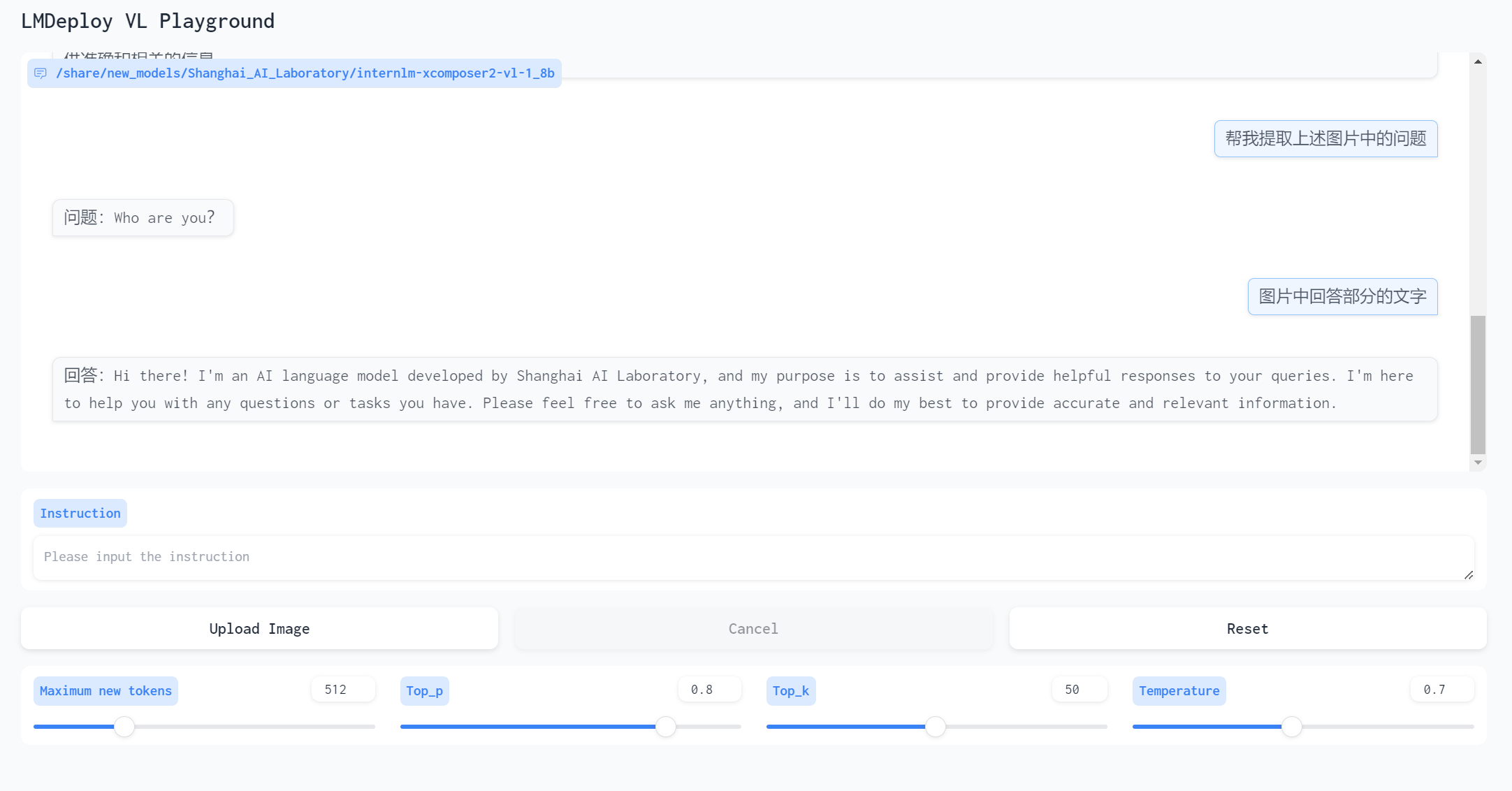
提取文字满分,表现出乎意料
LMDeploy 部署 InternVL2-2B 模型
启动命令(还是在原来的虚拟环境 demo 下)
lmdeploy serve gradio /share/new_models/OpenGVLab/InternVL2-2B --cache-max-entry-count 0.1
端口映射同上
投喂的图片还是上面的猫猫图,对话如下
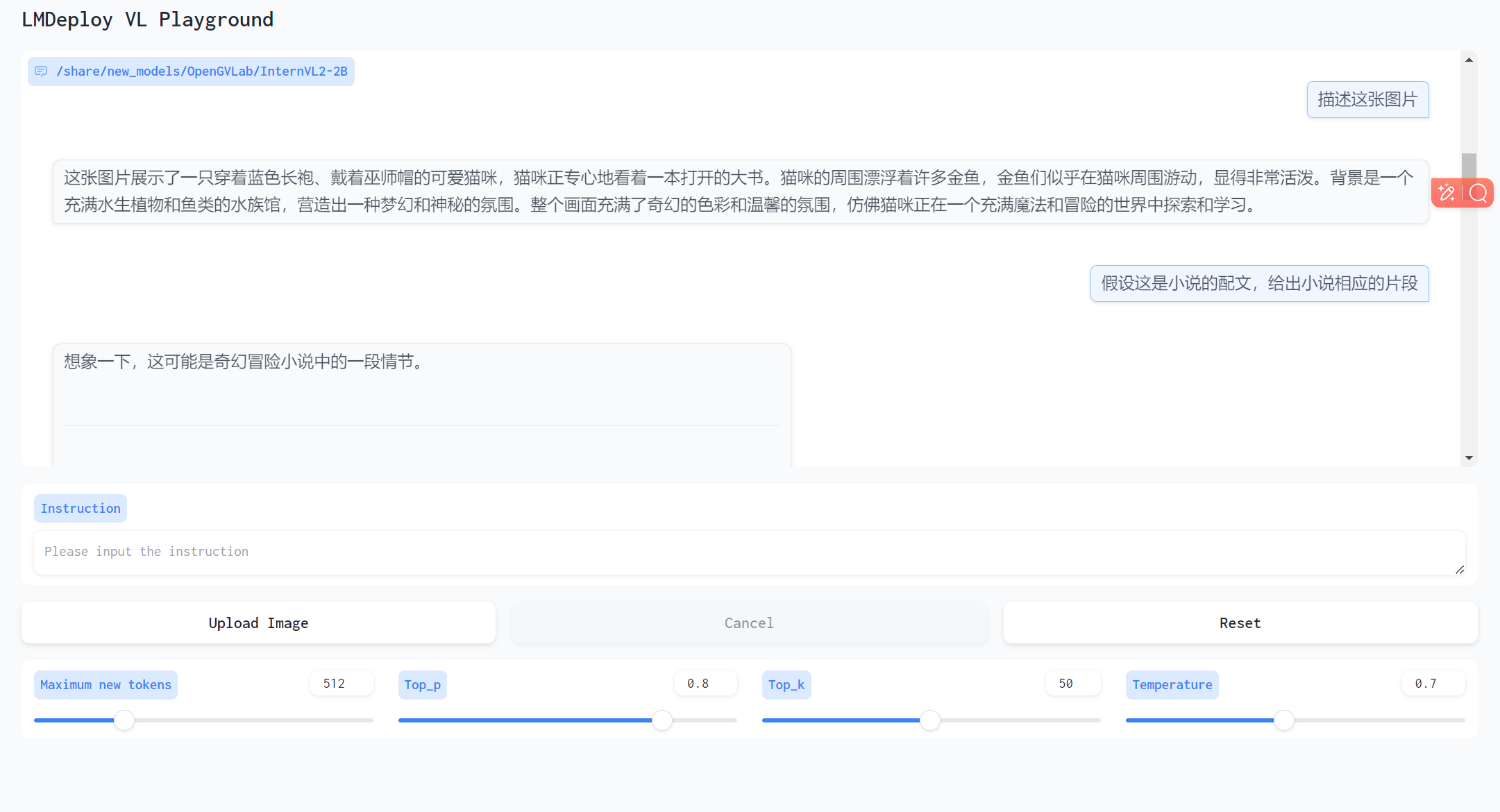
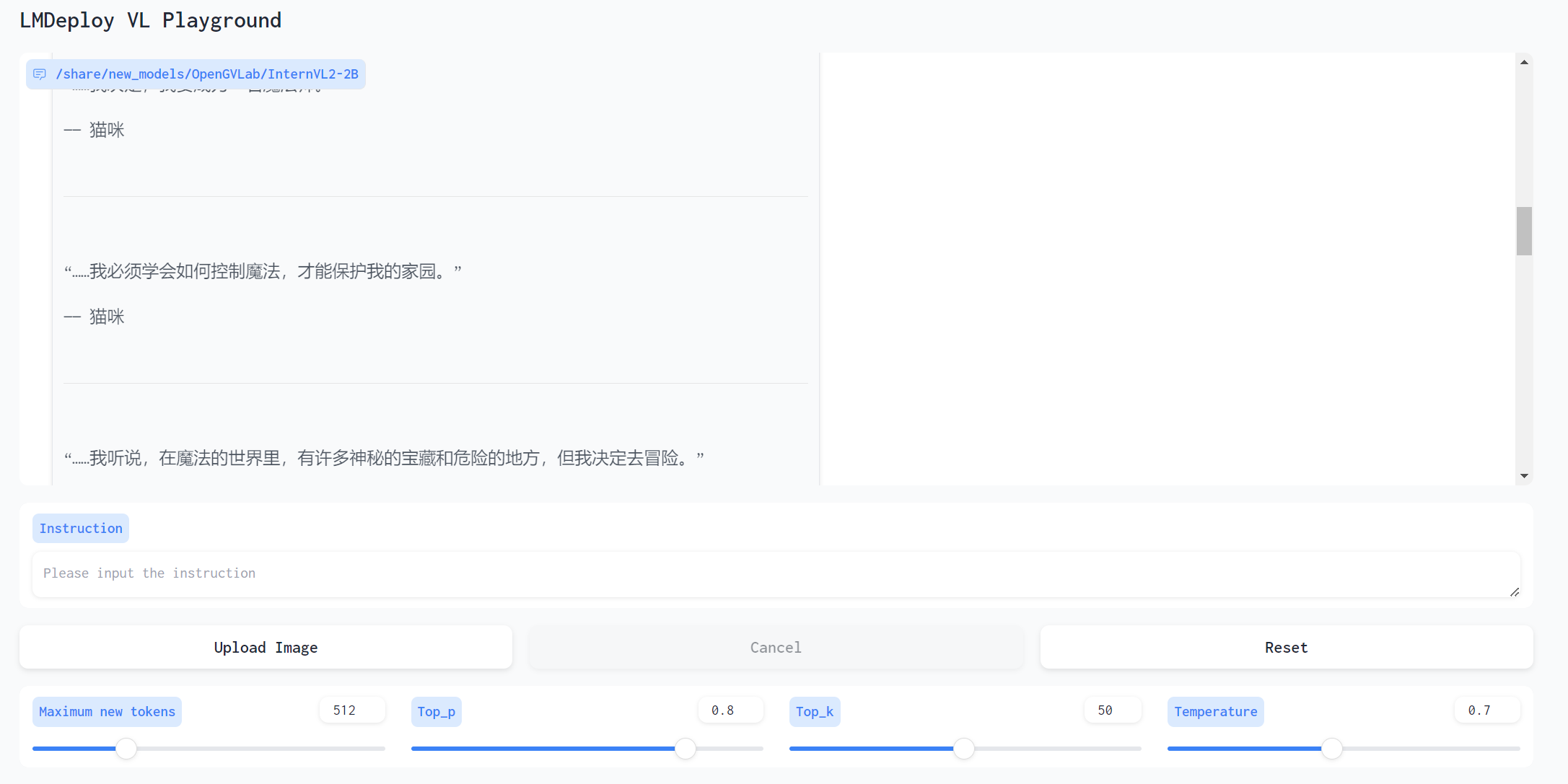
这个模型图片描述地更好,升级了一下问题,让他编一段小说,结构有问题,但是内容还是挺有想象力挺不错的