scikit-opt是一个封装了多种启发式算法的Python代码库,可以用于解决优化问题。scikit-opt官方仓库见:scikit-opt,scikit-opt官网文档见:scikit-opt-doc。
scikit-opt安装代码如下:
pip install scikit-opt
# 调用scikit-opt并查看版本
import sko
sko.__version__
'0.6.6'
0 背景介绍
启发式算法介绍
启发式算法,顾名思义,就是一种基于直觉或经验来解决问题的算法。它不像传统算法那样一步一步地穷尽所有可能性,而是通过一些启发式的规则或策略,快速找到一个可行的解。打个比方,若开车去一个陌生的地方,没有导航仪。启发式算法就像问路一样,可以向路人询问,也可以根据路边的标志和指示牌来判断方向。虽然这种方式不能保证找到最优路线,但通常能够在较短时间内找到一个可行的路线。
启发式算法通常具有以下特点:
- 快速性: 启发式算法通常能够在较短时间内找到一个可行的解,特别是在面对复杂问题时。
- 鲁棒性: 启发式算法对问题的细节不敏感,即使问题输入发生变化,也能找到一个合理的解。
- 有效性: 启发式算法通常能够找到高质量的解,在许多实际应用中表现良好。
当然,启发式算法也存在一些缺点:
- 近似性: 启发式算法不能保证找到最优解,只能找到一个较好的近似解。
- 经验性: 启发式算法的性能很大程度上依赖于经验或规则的设计,不同的启发式算法可能具有不同的效果。
- 局限性: 启发式算法通常针对特定的问题设计,难以应用于其他问题。
尽管存在一些缺点,启发式算法仍然是一种非常有效的解决问题的方法,特别是在面对复杂问题或需要实时决策的情况下。启发式算法在许多领域都有应用,例如:
- 人工智能: 启发式算法被广泛应用于人工智能领域,例如机器学习、机器人、游戏等。
- 运筹优化: 启发式算法被用于解决各种运筹优化问题,例如旅行商问题、调度问题、资源分配问题等。
- 计算机图形学: 启发式算法被用于解决计算机图形学中的各种问题,例如路径规划、图像分割、纹理生成等。
scikit-opt中的启发式算法
scikit-opt支持的启发式算法包括:
- 差分进化算法 (Differential Evolution):一种基于群体搜索的优化算法,通过模拟生物进化的过程来寻找最优解。
- 遗传算法 (Genetic Algorithm):模拟自然选择和遗传机制,通过种群中个体的变异、交叉和选择来优化问题。
- 粒子群算法 (Particle Swarm Optimization):模拟鸟群或鱼群中个体的群体行为,通过个体间信息共享来搜索最优解。
- 模拟退火算法 (Simulated Annealing):受金属退火过程启发,通过接受状态降低的解的概率来在搜索空间中跳出局部最优解。
- 蚁群算法 (Ant Colony Optimization):模拟蚂蚁寻找食物的行为,通过信息素的沉积和蒸发来寻找优化路径。
- 免疫优化算法(Immune Optimization Algorithm):基于免疫系统的进化过程,通过模拟抗体的生成和免疫反应来优化问题。
- 人工鱼群算法(Artificial Fish-Swarm Algorithm):模拟鱼群觅食行为,通过个体之间的位置调整和信息共享来搜索最优解。
这些算法都属于启发式算法的范畴,适用于复杂的优化问题,如函数优化、参数调优等。scikit-opt提供了这些算法的Python实现,并且通常还包括了对不同问题的适应性调整和优化参数的支持,使得用户能够更方便地应用这些算法进行问题求解。
以下表格包含了这些算法的优缺点和适用环境:
| 算法名称 | 优点 | 缺点 | 适用环境 |
|---|---|---|---|
| 差分进化算法 | 鲁棒性强,适用于多种优化问题,收敛速度快 | 参数设置对算法性能影响较大,容易陷入局部最优 | 连续优化问题,特别是高维空间的优化问题 |
| 遗传算法 | 具有全局搜索能力,适用于复杂的优化问题 | 参数设置复杂,收敛速度较慢 | 组合优化问题,如旅行商问题、调度问题等 |
| 粒子群算法 | 实现简单,收敛速度快,适用于多模态优化问题 | 易陷入局部最优,参数设置对算法性能影响较大 | 连续优化问题,特别是多模态优化问题 |
| 模拟退火算法 | 具有跳出局部最优的能力,适用于复杂优化问题 | 参数设置复杂,收敛速度较慢 | 组合优化问题,如电路设计、图像处理等 |
| 蚁群算法 | 适用于离散优化问题,具有分布式计算的特点 | 参数设置复杂,收敛速度较慢 | 组合优化问题,如旅行商问题、车辆路径问题等 |
| 免疫优化算法 | 具有较强的鲁棒性和自适应性,适用于动态优化问题 | 算法复杂度较高,参数设置较困难 | 组合优化问题,如特征选择、数据分类等 |
| 鱼群算法 | 实现简单,具有较好的并行性,适用于多目标优化问题 | 易陷入局部最优,参数设置对算法性能影响较大 | 连续优化问题,特别是多目标优化问题 |
1 算法使用
1.1 差分进化算法
差分进化算法(Differential Evolution, DE)是一种基于种群的启发式优化算法,其核心思想是通过模拟生物进化过程中的变异和自然选择机制,不断探索和改进解,最终找到问题的最优或近似最优解。这个过程可以简单比喻为一次探险旅行:
- 探险队伍的组建:在探险开始前,我们会组建一支队伍,这支队伍由多个探险者组成,每个探险者都代表了一个可能的解决方案。这些探险者携带着地图和装备,准备出发探索未知的领域。
- 差分(Differential):在探险过程中,每个探险者会观察周围的环境,并与其他探险者交流信息。差分在这里可以理解为探险者之间的信息交流,他们通过比较彼此的地图和装备,发现哪些是更有效的策略。在DE算法中,差分是指通过计算两个随机选择的探险者(解)之间的差异来生成新的探索方向。
- 进化(Evolution):随着探险的进行,探险者会根据收集到的信息不断调整自己的路线和策略。在DE算法中,进化是指通过交叉(crossover)操作将新的探索方向与当前的解结合,生成新的候选解。这个过程类似于自然选择,优秀的策略会被保留下来,而不适应的策略则会被淘汰。
- 适应度评估:探险者在探索过程中会不断评估自己的路线是否有效,比如是否更接近目标或者是否避开了危险区域。在DE算法中,适应度评估是指根据优化问题的特定目标来评价每个候选解的性能。
- 迭代更新:探险者在每次评估后,会根据结果更新自己的策略。在DE算法中,这意味着根据适应度评估的结果,选择保留或替换当前的解,从而不断进化和改进。
- 目标达成:最终,探险者会找到一条通往目标的最佳路径。在DE算法中,这意味着找到了一个接近最优解的候选解。
上面的比喻可能不完全准确,差分进化算法详细理解见:差分进化算法的基本概念和原理。
scikit-opt库中的DE类用于实现差分进化算法算法,DE类构建参数介绍如下:
| 参数 | 默认值 | 意义 |
|---|---|---|
| func | - | 需要优化的函数 |
| n_dim | - | 目标函数包含的自变量个数 |
| size_pop | 50 | 种群规模,种群规模越大,探索范围越广,但计算量也越大 |
| max_iter | 200 | 算法运行的最大迭代次数 |
| prob_mut | 0.001 | 变异概率,变异概率越高,种群多样性越大,但也可能导致陷入局部解 |
| F | 0.5 | 变异系数,变异系数越大,变异幅度越大,种群的探索范围也越大 |
| lb | -1 | 每个自变量的最小值 |
| ub | 1 | 每个自变量的最大值 |
| constraint_eq | 空元组 | 等式约束 |
| constraint_ueq | 空元组 | 不等式约束,形式为小于等于0 |
差分进化算法对参数设置比较敏感,需要根据具体问题进行调整。scikit-opt中DE类使用实例如下:
定义优化问题
优化问题如下:
min f(x1, x2, x3) = x1 + x2^2 + x3^3
s.t.x1*x2 >= 1x1*x2 <= 5x2 + x3 = 10 <= x1, x2, x3 <= 5
这是一个带有约束条件的非线性规划问题。在这个问题中,目标是找到一组变量 \(x_1, x_2, x_3\) 的值,使得目标函数 \(f(x_1, x_2, x_3) = x_1 + x_2^2 + x_3^3\) 达到最小值,同时满足一系列给定的约束条件。
目标函数(Objective Function):
- \(f(x_1, x_2, x_3) = x_1 + x_2^2 + x_3^3\)
约束条件(Constraints):
- \(x_1 \cdot x_2 \geq 1\) (这是一个非线性约束,确保 \(x_1\) 和 \(x_2\) 的乘积不小于1)
- \(x_1 \cdot x_2 \leq 5\) (同样是非线性约束,限制 \(x_1\) 和 \(x_2\) 的乘积不大于5)
- \(x_2 + x_3 = 1\) (这是一个线性等式约束,表示 \(x_2\) 和 \(x_3\) 的和必须为1)
- \(0 \leq x_1, x_2, x_3 \leq 5\) (这是变量边界约束,限制 \(x_1, x_2, x_3\) 的取值范围在0到5之间)
示例代码
# 定义约束优化问题
def obj_func(p):# 给出输入x1, x2, x3 = p# 返回目标函数值,目的是最小化目标函数值return x1 + x2 ** 2 + x3 ** 3# 定义第三个约束条件
constraint_eq = [lambda x: 1 - x[1] - x[2]
]# 定义第一个和第二个约束条件
constraint_ueq = [lambda x: 1 - x[0] * x[1],lambda x: x[0] * x[1] - 5
]# 调用差分进化算法解决问题
from sko.DE import DE# lb和ub定义第四个约束条件
de = DE(func=obj_func, n_dim=3, size_pop=50, max_iter=100, lb=[0, 0, 0], ub=[5, 5, 5],constraint_eq=constraint_eq, constraint_ueq=constraint_ueq)# 将返回最优解的变量值和目标函数值
# 目的是最小化目标函数值
best_x, best_y = de.run()
print('best_x:', best_x, '\n', 'best_y:', best_y)
best_x: [1.60211276 0.73970843 0.26021027] best_y: [2.16689999]
带入最优解的变量值到目标函数中的计算结果和best_y相等:
best_x[0]+best_x[1]**2+best_x[2]**3
2.1668999924186294
功能函数
# 每次迭代的最优函数值
res = de.generation_best_Y
# 长度为max_iter
len(res)
100
# 每次迭代的最优函数值对应的输入值
res = de.generation_best_X
# 长度为max_iter
len(res)
100
# 每次迭代种群所有个体的函数值
res = de.all_history_Y
# 长度为max_iter
# len(res)
# 返回值为size_pop,也就是种群个数
len(res[0])
50
1.2 遗传算法
1.2.1 基础遗传算法
遗传算法(Genetic Algorithm,GA)是一种模拟自然选择和遗传机制的搜索和优化算法。它通过模拟生物进化过程中的遗传、突变、交叉和选择等自然现象,来解决优化问题。通过挖宝这个例子来通俗地说明遗传算法的核心思想:
- 定义问题(宝藏在哪里):假设你在一个广阔的区域内寻找宝藏。这个区域可以看作是一个巨大的地图,宝藏可能藏在任何位置。
- 初始化种群(随机选择起点):开始时,你不知道宝藏的具体位置,因此你随机选择一些起点,这些起点可以看作是“种群”中的“个体”。每个个体代表一个可能的宝藏位置。
- 适应度评估(评估宝藏位置):每个个体(宝藏位置)需要被评估其“适应度”。在挖宝的例子中,适应度可以定义为距离宝藏的真实位置的远近。越接近宝藏的位置,适应度越高。
- 选择(淘汰不合适的个体):根据适应度,选择那些更接近宝藏的个体进入下一代。这就像是自然选择中,更适应环境的生物更有可能生存并繁衍后代。
- 交叉(产生新的宝藏位置):将选择出的个体进行“交叉”(类似于生物的交配)。在遗传算法中,这通常通过交换个体之间的某些特征来实现。例如,两个宝藏位置的坐标可以相互交换,产生新的宝藏位置。
- 变异(引入新的宝藏位置):为了增加种群的多样性,引入一些随机变化(变异)。这就像是生物基因突变一样,可能会产生新的宝藏位置。
- 重复迭代(不断尝试):重复上述过程,直到找到宝藏或者达到一定的迭代次数。每一次迭代都会产生新的种群,逐渐接近宝藏的真实位置。
- 收敛(找到宝藏):最终,通过不断的迭代和优化,种群中的个体将越来越接近宝藏的真实位置,直到找到宝藏。
上面的比喻可能不完全准确,遗传算法详细理解见:10分钟搞懂遗传算法。
scikit-opt库中的GA类用于实现遗传算法,GA类的构造参数介绍如下:
| 参数 | 默认值 | 意义 |
|---|---|---|
| func | - | 目标函数 |
| n_dim | - | 目标函数的维度 |
| size_pop | 50 | 种群规模 |
| max_iter | 200 | 最大迭代次数 |
| prob_mut | 0.001 | 变异概率 |
| lb | -1 | 每个自变量的最小值 |
| ub | 1 | 每个自变量的最大值 |
| constraint_eq | 空元组 | 等式约束 |
| constraint_ueq | 空元组 | 不等式约束 |
| precision | 1e-7 | 精准度,int/float或者它们组成的列表 |
案例 1
如下代码展示了利用遗传算法求解schaffer函数:
import numpy as np# schaffer函数是一种用于优化算法测试的标准基准函数
def schaffer(p):'''该函数有许多局部最小值,并且存在强烈的震荡。全局最小值出现在 (0,0) 处,其函数值为 0。'''# 解包传入的参数 p,其中 p 是一个包含两个元素的元组或数组x1, x2 = p# 计算 x1 和 x2 的平方和x = np.square(x1) + np.square(x2)# 计算schaffer函数的值# 这里使用了正弦函数和平方函数,并通过一个分母项来增加函数的复杂性return 0.5 + (np.square(np.sin(x)) - 0.5) / np.square(1 + 0.001 * x)# 导入遗传算法模块
from sko.GA import GA# 初始化遗传算法
ga = GA(func=schaffer, # 需要优化的目标函数,返回n_dim=2, # 决策变量的维度size_pop=30, # 种群大小max_iter=100, # 最大迭代次数prob_mut=0.001, # 突变概率lb=[-1, -1], # 决策变量的下界ub=[1, 1], # 决策变量的上界precision=1e-7 # 算法精度
)# 将返回最优解的变量值和目标函数值
# 目的是最小化目标函数值
best_x, best_y = ga.run()# 输出最优解的决策变量和目标函数值
# 可以看到best_x中两个变量值接近0
print('best_x:', best_x, '\n', 'best_y:', best_y)
best_x: [-0.0001221 0.0074937] best_y: [5.9325642e-08]
# 导入pandas和matplotlib.pyplot库,用于数据处理和绘图
import pandas as pd
import matplotlib.pyplot as plt# 将遗传算法过程中的所有个体的函数值历史记录转换为DataFrame
# ga.all_history_Y为每次迭代种群所有个体的函数值
# Y_history形状为(max_iter,size_pop)
Y_history = pd.DataFrame(ga.all_history_Y)# 创建一个包含两个子图的图形
fig, ax = plt.subplots(2, 1)# 在第一个子图中绘制函数值的历史记录
ax[0].plot(Y_history.index, Y_history.values, '.', color='red')# 在第二个子图中绘制每次迭代的各种群的函数最小值
Y_history.min(axis=1).cummin().plot(kind='line')# 显示图形
plt.show()

GA类还提供了其他的功能函数:
ga.generation_best_Y # 每一代的最优函数值
ga.generation_best_X # 每一代的最优函数值对应的输入值
ga.all_history_FitV # 每一代的每个个体的适应度
ga.all_history_Y # 每一代每个个体的函数值
案例 2
如下代码展示了利用precision参数控制变量的精度。当precision参数被设定为整数时,系统自动激活整数规划模式,使得变量值严格遵循整数约束。在整数规划模式下,为了达到最佳的收敛速度与效果,推荐变量的可能取值数量尽量为\(2^n\)的形式:
from sko.GA import GAdemo_func = lambda x: (x[0] - 1) ** 2 + (x[1] - 0.05) ** 2 + x[2] ** 2
ga = GA(func=demo_func, n_dim=3, max_iter=500, lb=[-1, -1, -1], ub=[5, 1, 1], precision=[1, 2, 1e-7])
best_x, best_y = ga.run()
print('best_x:', best_x, '\n', 'best_y:', best_y)
best_x: [1.00000000e+00 1.00000000e+00 2.98023233e-08] best_y: [0.9025]
案例 3
以下代码展示了使用遗传算法进行曲线拟合:
import numpy as np
# 导入matplotlib.pyplot用于绘图
import matplotlib.pyplot as plt
# 导入sko库中的遗传算法模块
from sko.GA import GA# 创建数据点x_true,范围从-1.2到1.2,共20个点
x_true = np.linspace(-1.2, 1.2, 20)
# 计算对应的y_true值,为三次多项式的值加上随机噪声
y_true = x_true ** 3 - x_true + 0.4 * np.random.rand(20)# 定义三次多项式函数f_fun,参数包括x值和系数a, b, c, d
def f_fun(x, a, b, c, d):return a * x ** 3 + b * x ** 2 + c * x + d# 定义遗传算法的适应度函数obj_fun,用于计算多项式拟合的残差平方和
def obj_fun(p):a, b, c, d = p # 解包参数# 计算拟合多项式与原始数据点的残差平方和residuals = np.square(f_fun(x_true, a, b, c, d) - y_true).sum()return residuals # 返回残差平方和# 初始化遗传算法,设置适应度函数、维度、种群大小、迭代次数、参数界限
ga = GA(func=obj_fun, n_dim=4, size_pop=100, max_iter=500,lb=[-2] * 4, ub=[2] * 4)# 运行遗传算法,获取最优参数和对应的残差
best_params, residuals = ga.run()
# 打印最优参数和残差
print('best_x:', best_params, '\n', 'best_y:', residuals)# 使用最优参数计算预测的y值
y_predict = f_fun(x_true, *best_params)# 创建绘图窗口和坐标轴
fig, ax = plt.subplots()# 在同一个坐标轴上绘制原始数据点和预测的曲线
ax.plot(x_true, y_true, 'o')
ax.plot(x_true, y_predict, '-')# 显示绘图窗口
plt.show()
best_x: [ 0.82131277 -0.01955447 -0.86175541 0.16721198] best_y: [0.21969302]

1.2.2 用于解决旅行商问题的遗传算法
scikit-opt提供了GA_TSP模块以专门为解决旅行商问题(Traveling Salesman Problem, TSP)而设计的遗传算法。它通过对问题的特定部分进行重载,比如交叉(crossover)和变异(mutation)操作,来适应TSP问题的特点。使用GA_TSP时,首先需要定义问题的坐标和距离矩阵,然后创建一个GA_TSP对象并调用run方法来执行算法,最终得到最短路径和对应的总距离。
所谓是TSP问题一个经典的组合优化问题,通常描述为:给定一组城市和各城市之间的距离,求解一条访问每个城市一次并且回到起始城市的最短路径。这个问题在计算机科学和运筹学中非常著名,也是NP-hard问题的代表之一,意味着随着城市数量的增加,找到最优解的计算复杂度呈指数增长。TSP的解决方案不仅限于商业旅行推销员的路线优化,也可以应用于诸如电路板生产、DNA测序等各种现实生活中的路径规划问题。
GA_TSP的输入参数如下,可控制参数比GA算法少:
| 参数 | 默认值 | 意义 |
|---|---|---|
| func | - | 目标函数 |
| n_dim | - | 城市个数 |
| size_pop | 50 | 种群规模 |
| max_iter | 200 | 最大迭代次数 |
| prob_mut | 0.001 | 变异概率 |
案例 1
以下是使用scikit-opt中的GA_TSP类来求解TSP问题的简单示例:
import numpy as np
from scipy import spatial # 导入scipy库中的spatial模块,用于计算空间距离
import matplotlib.pyplot as plt # 设置点的数量
num_points = 20 # 生成随机点坐标
points_coordinate = np.random.rand(num_points, 2) # 生成一个num_points x 2的数组,包含随机坐标 # 计算点之间的距离矩阵,使用欧几里得距离
distance_matrix = spatial.distance.cdist(points_coordinate, points_coordinate, metric='euclidean') # 定义目标函数,计算给定路线(routine)的总距离
def cal_total_distance(routine): ''' 目标函数。输入一个路线(routine),返回一个总距离。 route是一个一维数组,表示访问点的顺序''' num_points, = routine.shape # 获取路线数组的长度 # 使用列表推导式和距离矩阵计算总距离 # 遍历路线中的每个点对,计算相邻点之间的距离并求和 return sum([distance_matrix[routine[i % num_points], routine[(i + 1) % num_points]] for i in range(num_points)]) # 从sko库导入遗传算法(GA)解决旅行商问题(TSP)的类
from sko.GA import GA_TSP # 初始化GA_TSP对象
ga_tsp = GA_TSP(func=cal_total_distance, n_dim=num_points, size_pop=50, max_iter=100, prob_mut=1) # 运行遗传算法,得到最优解
best_points, best_distance = ga_tsp.run()
print(best_points)
print(best_distance) # 最小距离
[13 15 1 11 16 7 3 9 5 12 14 19 6 17 2 10 8 18 4 0]
[3.91036766]
可视化代码如下:
# 绘图展示结果
fig, ax = plt.subplots(1, 2) # 创建一个包含两个子图的图形
# 绘制最优路线
best_points_ = np.concatenate([best_points, [best_points[0]]]) # 将起点添加到终点,形成闭环
best_points_coordinate = points_coordinate[best_points_, :] # 获取最优路线上的点坐标
ax[0].plot(best_points_coordinate[:, 0], best_points_coordinate[:, 1], 'o-r') # 绘制最优路线
# 添加箭头表示路线方向
for i in range(num_points):ax[0].annotate('', xy=best_points_coordinate[i + 1], xytext=best_points_coordinate[i],arrowprops=dict(arrowstyle='->', color='green'))
ax[0].plot(best_points_coordinate[0, 0], best_points_coordinate[0, 1], 'gs') # 使用绿色方块标记起点 # 绘制算法迭代过程中的最优解变化
ax[1].plot(ga_tsp.generation_best_Y) # generation_best_Y存储了每代的最优解
plt.show() # 显示图形

案例 2
下面的示例展示了遗传TSP问题中固定起点和终点的方法。假设起点和终点的坐标分别指定为(0, 0)和(1, 1),考虑共有n+2个点,优化目标是中间的n个点,而起点和终点则固定不参与优化。目标函数即为实际路径的总距离:
import numpy as np
from scipy import spatial # 导入scipy库中的spatial模块,用于计算空间距离
import matplotlib.pyplot as plt # 设置点的数量
num_points = 15 # 生成随机点坐标
points_coordinate = np.random.rand(num_points, 2) # 生成一个num_points x 2的数组,包含随机坐标 start_point=[[0,0]] # 起始点
end_point=[[1,1]] # 结束点
points_coordinate = np.concatenate([points_coordinate,start_point,end_point])
# 计算点之间的距离矩阵,使用欧几里得距离
distance_matrix = spatial.distance.cdist(points_coordinate, points_coordinate, metric='euclidean') # 定义目标函数,计算给定路线(routine)的总距离
def cal_total_distance(routine): ''' 目标函数。输入一个路线(routine),返回一个总距离。 route是一个一维数组,表示访问点的顺序''' num_points, = routine.shape# start_point,end_point 本身不参与优化。给一个固定的值,参与计算总路径# num_points,num_points+1为start_point,end_point的标号routine = np.concatenate([[num_points], routine, [num_points+1]])# 遍历路线中的每个点对,计算相邻点之间的距离并求和 return sum([distance_matrix[routine[i], routine[i + 1]] for i in range(num_points+2-1)])# 从sko库导入遗传算法(GA)解决旅行商问题(TSP)的类
from sko.GA import GA_TSP # 初始化GA_TSP对象
ga_tsp = GA_TSP(func=cal_total_distance, n_dim=num_points, size_pop=50, max_iter=100, prob_mut=1) # 运行遗传算法,得到最优解
best_points, best_distance = ga_tsp.run() # 绘图展示结果
fig, ax = plt.subplots(1, 2) # 创建一个包含两个子图的图形
# 绘制最优路线
best_points_ = np.concatenate([best_points, [best_points[0]]]) # 将起点添加到终点,形成闭环
best_points_coordinate = points_coordinate[best_points_, :] # 获取最优路线上的点坐标
ax[0].plot(best_points_coordinate[:, 0], best_points_coordinate[:, 1], 'o-r') # 绘制最优路线
# 添加箭头表示路线方向
for i in range(num_points):ax[0].annotate('', xy=best_points_coordinate[i + 1], xytext=best_points_coordinate[i],arrowprops=dict(arrowstyle='->', color='green'))
ax[0].plot(best_points_coordinate[0, 0], best_points_coordinate[0, 1], 'gs') # 使用绿色方块标记起点 # 绘制算法迭代过程中的最优解变化
ax[1].plot(ga_tsp.generation_best_Y) # generation_best_Y存储了每代的最优解
plt.show() # 显示图形

1.3 粒子群算法
粒子群优化算法(Particle Swarm Optimization, PSO)是一种模拟鸟群觅食行为的优化算法。想象一群鸟在广阔的天空中寻找食物,它们通过观察彼此的位置和移动方向来寻找食物最多的地方。粒子群算法也是基于类似的原理,下面通过探险的例子来通俗解释其核心理念:
- 探险队员:在粒子群算法中,每个“粒子”可以想象成一名探险队员。每个队员都有一定的位置,代表了一个可能的解决方案。
- 位置和速度:每个探险队员都有自己当前的位置(解决方案)和速度(向目标移动的方向和速度)。
- 个人经验:每个探险队员都会记得自己曾经到达过的最好位置,也就是他们个人找到的最丰富的食物源。
- 群体经验:除了个人经验外,探险队员们还会共享整个队伍找到的最好位置,这是整个群体的共识,代表了一个更优的解决方案。
- 探索与利用:探险队员们在移动时会考虑个人经验(自己找到的最好位置)和群体经验(整个队伍找到的最好位置)。他们会根据这两个因素调整自己的速度和方向,既探索新的地方,也利用已知的信息。
- 更新位置:根据速度和方向,探险队员们更新自己的位置,继续寻找更好的解决方案。
- 迭代过程:这个过程会不断重复,每次迭代都是一次新的探索,探险队员们会根据新的位置更新个人经验和群体经验。
- 收敛:随着时间的推移,探险队员们会逐渐聚集到宝藏最多的地方,这代表算法找到了最优解或接近最优解的位置。
上面的比喻可能不完全准确,粒子群算法详细理解见:粒子群优化算法的详细解读。
scikit-opt库中的PSO类用于实现粒子群优化算法,PSO类的构造参数介绍如下:
| 参数 | 默认值 | 意义 |
|---|---|---|
| func | - | 目标函数 |
| n_dim | - | 目标函数的维度 |
| size_pop | 50 | 种群规模 |
| max_iter | 200 | 最大迭代次数 |
| lb | None | 每个参数的最小值 |
| ub | None | 每个参数的最大值 |
| w | 0.8 | 惯性权重,控制粒子运动速度对上次速度的影响程度。w值越大,粒子对历史速度的记忆力越强,全局搜索能力越强 |
| c1 | 0.5 | 个体记忆,控制粒子向自身历史最优位置移动的程度。c1值越大,粒子越倾向于向自身历史最优位置移动 |
| c2 | 0.5 | 集体记忆,控制粒子向全局最优位置移动的程度。c2值越大,粒子越倾向于向全局最优位置移动 |
| constraint_ueq | 空元组 | 不等式约束,形式为小于等于0 |
案例 1
以下代码展示了PSO类简单使用示例:
# 定义问题
def demo_func(x):"""目标函数。输入:x: 一个包含三个元素的列表,代表问题的三个变量。输出:目标函数值:优化目标尉最小化该值"""x1, x2, x3 = x # 将列表x解包为三个变量return x1 ** 2 + (x2 - 0.01) ** 2 + x3 ** 2 # 计算目标函数值# 调用粒子群算法
from sko.PSO import PSOpso = PSO(func=demo_func, # 目标函数n_dim=3, # 问题的维度(变量个数)pop=40, # 种群大小(粒子个数)max_iter=150, # 最大迭代次数lb=[0, -1, 0.2], # 变量的下界ub=[1, 1, 1], # 变量的上界w=0.8, # 惯性权重c1=0.5, # 个体学习因子c2=0.5 # 集体学习因子
)
pso.run() # 运行粒子群算法print('best_x is ', pso.gbest_x, 'best_y is', pso.gbest_y) # 打印最优解import matplotlib.pyplot as pltplt.plot(pso.gbest_y_hist) # 绘制目标函数值随迭代次数的变化曲线
plt.show()
best_x is [0. 0.01 0.2 ] best_y is [0.04]

案例 2
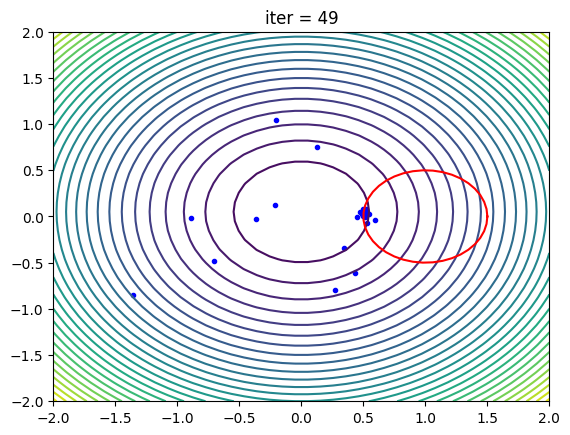
以下代码展示了带非线性约束的PSO类使用示例及可视化代码(注意该代码运行时间较长):
import numpy as np
from sko.PSO import PSO def demo_func(x):x1, x2 = xreturn x1 ** 2 + (x2 - 0.05) ** 2 # 定义非线性约束
constraint_ueq = ( lambda x: (x[0] - 1) ** 2 + (x[1] - 0) ** 2 - 0.5 ** 2 ,
) # 设置粒子群优化算法的最大迭代次数
max_iter = 50
# 创建PSO实例,设置目标函数、维度、种群大小、迭代次数、变量范围以及非线性约束
pso = PSO(func=demo_func, n_dim=2, pop=40, max_iter=max_iter, lb=[-2, -2], ub=[2, 2], constraint_ueq=constraint_ueq)
# 开启记录模式,以便后续绘制动态图
pso.record_mode = True
# 运行PSO算法
pso.run()
# 打印最优解的位置和值
print('best_x is ', pso.gbest_x, 'best_y is', pso.gbest_y) # 导入matplotlib库进行绘图
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation # 从PSO记录中获取数据
record_value = pso.record_value
X_list, V_list = record_value['X'], record_value['V'] # 创建图形和坐标轴
fig, ax = plt.subplots(1, 1)
ax.set_title('title', loc='center') # 暂时设置标题,后续更新
line = ax.plot([], [], 'b.') # 绘制初始空点 # 创建网格并计算目标函数值
X_grid, Y_grid = np.meshgrid(np.linspace(-2.0, 2.0, 40), np.linspace(-2.0, 2.0, 40))
Z_grid = demo_func((X_grid, Y_grid))
ax.contour(X_grid, Y_grid, Z_grid, 30) # 绘制等高线图 # 设置坐标轴范围
ax.set_xlim(-2, 2)
ax.set_ylim(-2, 2) # 绘制圆形约束的边界
t = np.linspace(0, 2 * np.pi, 40)
ax.plot(0.5 * np.cos(t) + 1, 0.5 * np.sin(t), color='r') # 定义更新散点图的函数
def update_scatter(frame): # 计算当前帧对应的迭代次数和子帧数 i, j = frame // 10, frame % 10 # 更新标题 ax.set_title('iter = ' + str(i)) # 计算当前粒子位置(考虑到速度和迭代) X_tmp = X_list[i] + V_list[i] * j / 10.0 # 更新散点图的数据 plt.setp(line, 'xdata', X_tmp[:, 0], 'ydata', X_tmp[:, 1]) return line # 创建动画
ani = FuncAnimation(fig, update_scatter, blit=True, interval=25, frames=max_iter * 10)
# 保存动画为gif文件
ani.save('pso.gif', writer='pillow')
best_x is [0.50070802 0.02494922] best_y is [0.25133606]
1.4 模拟退火算法
1.4.1 基础模拟退火算法
模拟退火算法 (Simulated Annealing,SA)来源于冶金学中的退火过程,这是一种通过加热和缓慢冷却金属来减少其内部缺陷的方法。在算法中,这个过程被用来寻找问题的最优解。核心理念可以用探险来通俗说明:
- 随机出发:想象你是一个探险家,开始时你站在一个未知的森林中,不知道宝藏在哪里。
- 探索周边:你开始随机走动,探索周围的区域,这就像是算法在解空间中随机选择候选解。
- 接受好坏:在探险中,你可能会遇到好地方(离宝藏更近)或坏地方(离宝藏更远)。模拟退火算法允许你在早期阶段接受好坏解,这就像是即使知道某个方向可能不是最佳路径,但为了探索未知,你还是决定去尝试。
- 温度降低:随着探险的进行,你会逐渐减少探索的范围,变得更加谨慎。在算法中,这相当于降低“温度参数”,意味着算法在选择新解时变得更加挑剔。
- 最佳解:最终你可能会找到一个宝藏,或者至少是一个相对较好的地方。算法通过这种方式逐步收敛到问题的最优解或近似最优解。
- 结束探险:当温度降到足够低,你几乎不再移动,算法也就停止搜索,此时你所在的地点就是算法找到的解。
模拟退火算法的关键特点在于它能够在搜索过程中接受次优解,这有助于算法跳出局部最优解,从而有更大机会找到全局最优解。随着“温度”的降低,算法逐渐变得更加专注于寻找更好的解,直到最终收敛。
上面的比喻可能不完全准确,模拟退火算法算法详细理解见:模拟退火算法详解。scikit-opt库中的SA类用于实现模拟退火算法,SA类的构造参数介绍如下:
| 参数 | 默认值 | 意义 |
|---|---|---|
| func | - | 目标函数 |
| x0 | - | 迭代初始点,算法开始搜索时的初始自变量值 |
| T_max | 100 | 最大温度,模拟退火算法中的初始温度,通常设置为一个较高的值以允许较大的解空间探索 |
| T_min | 1e-7 | 最小温度度,算法停止时的温度阈值,当温度降至此值以下时,算法停止 |
| L | 300 | 链长,模拟退火算法中链的步数或长度 |
| max_stay_counter | 150 | 冷却耗时,当达到此次数时,无论是否找到更好的解,都将降低温度并继续搜索 |
| lb | 每个自变量的最小值 | |
| ub | 每个自变量的最大值 |
案例 1
以下代码展示了如何将模拟退火算法用于多元函数优化:
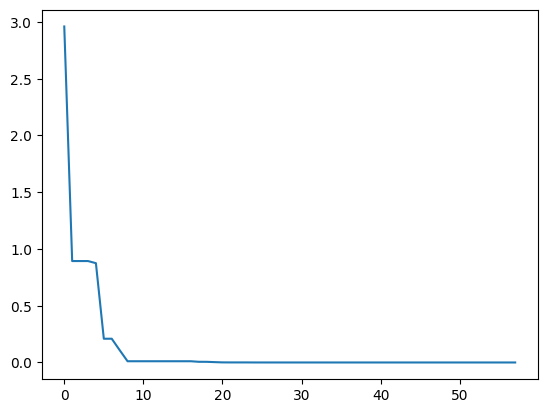
demo_func = lambda x: x[0] ** 2 + (x[1] - 0.02) ** 2 + x[2] ** 2from sko.SA import SAsa = SA(func=demo_func, x0=[1, 1, 1], T_max=1, T_min=1e-9, L=300, max_stay_counter=10)
best_x, best_y = sa.run()
print('best_x:', best_x, 'best_y', best_y)import matplotlib.pyplot as plt
import pandas as pd# de.generation_best_Y 每一代的最优函数值
# de.generation_best_X 每一代的最优函数值对应的输入值
plt.plot(pd.DataFrame(sa.best_y_history).cummin(axis=0))
plt.show()
best_x: [7.21355253e-06 2.00035659e-02 1.69597500e-05] best_y 3.5238375871831515e-10
案例 2
scikit-opt库的SA模块还包括了"Fast"、"Cauchy"和"Boltzmann"三种不同的温度下降策略或概率分布。关于这些SA算法的详细介绍,请参考:从模拟退火到退火进化算法。其中SA模块的SA类默认使用"Fast"版本算法。
Fast、Cauchy和Boltzmann各自有不同的优缺点:
- Fast(快速冷却):
- 优点:冷却速度快,可以在较短的时间内达到较低的温度,从而快速收敛到一个解。
- 缺点:由于冷却速度过快,可能导致算法过早地陷入局部最优解,而无法探索到全局最优解。
- Cauchy(柯西分布):
- 优点:使用柯西分布作为概率分布来选择新解,可以更好地避免局部最优,因为柯西分布的尾部较重,有助于探索更远的解空间。
- 缺点:由于柯西分布的特性,算法可能会在某些情况下过于集中在某些区域,导致搜索效率降低。
- Boltzmann(玻尔兹曼分布):
- 优点:使用玻尔兹曼分布作为概率分布,可以平衡探索和利用之间的关系,随着温度的降低,算法逐渐偏向于选择更优的解。
- 缺点:温度下降策略需要精心设计,以避免过快或过慢的冷却速度,这可能会影响算法的性能。
以上三种策略都有其适用的场景和问题类型。例如,对于需要快速得到一个解的问题,Fast策略可能更合适;而对于需要避免陷入局部最优的问题,Cauchy或Boltzmann策略可能更有优势。在实际应用中,选择哪种策略往往需要根据具体问题的特性和要求来决定。示例代码如下:
# 定义一个匿名函数,用于计算目标函数的值
# 该函数接受一个列表 x 作为参数,返回 x 中元素的平方和
demo_func = lambda x: x[0] ** 2 + (x[1] - 0.02) ** 2 + x[2] ** 2# 从 sko.SA 模块导入 SAFast 类,用于快速模拟退火算法
from sko.SA import SAFast
# 创建 SAFast 类的实例 sa_fast,用于执行模拟退火算法
# 参数说明:
# func: 目标函数
# x0: 初始解
# T_max: 最大温度
# T_min: 最小温度
# q: 温度衰减因子
# L: 邻域搜索次数
# lb: 下界列表
# ub: 上界列表
# max_stay_counter: 最大停滞次数
# SA等同于调用SAFast函数
sa_fast = SAFast(func=demo_func, x0=[1, 1, 1], T_max=1, T_min=1e-9, q=0.99, L=300, max_stay_counter=150,lb=[-1, 1, -1], ub=[2, 3, 4])
# 运行模拟退火算法
sa_fast.run()
# 打印算法找到的最佳解和对应的目标函数值
print('Fast Simulated Annealing: best_x is ', sa_fast.best_x, 'best_y is ', sa_fast.best_y)# 从 sko.SA 模块导入 SABoltzmann 类,用于 Boltzmann 模拟退火算法
from sko.SA import SABoltzmann
# 创建 SABoltzmann 类的实例 sa_boltzmann,用于执行 Boltzmann 模拟退火算法
# 其余参数与 SAFast 类似,但使用了不同的温度更新策略
sa_boltzmann = SABoltzmann(func=demo_func, x0=[1, 1, 1], T_max=1, T_min=1e-9, q=0.99, L=300, max_stay_counter=150,lb=-1, ub=[2, 3, 4])
# 打印算法找到的最佳解和对应的目标函数值,注意这里打印的 best_y 应该是 sa_boltzmann.best_y 而不是 sa_fast.best_y
print('Boltzmann Simulated Annealing: best_x is ', sa_boltzmann.best_x, 'best_y is ', sa_boltzmann.best_y) # 从 sko.SA 模块导入 SACauchy 类,用于 Cauchy 模拟退火算法
from sko.SA import SACauchy
# 创建 SACauchy 类的实例 sa_cauchy,用于执行 Cauchy 模拟退火算法
# 其余参数与 SABoltzmann 类似,但使用了不同的接受准则
sa_cauchy = SACauchy(func=demo_func, x0=[1, 1, 1], T_max=1, T_min=1e-9, q=0.99, L=300, max_stay_counter=150,lb=[-1, 1, -1], ub=[2, 3, 4])
sa_cauchy.run()
# 打印算法找到的最佳解和对应的目标函数值
print('Cauchy Simulated Annealing: best_x is ', sa_cauchy.best_x, 'best_y is ', sa_cauchy.best_y)
Fast Simulated Annealing: best_x is [2.58236441e-06 1.00000000e+00 2.91945906e-06] best_y is 0.9604000000151918
Boltzmann Simulated Annealing: best_x is [1 1 1] best_y is 2.9604
Cauchy Simulated Annealing: best_x is [-7.75482132e-04 1.00000000e+00 4.41811491e-05] best_y is 0.9604006033245103
1.4.2 用于解决旅行商问题的模拟退火算法
scikit-opt提供了SA_TSP模块以专门为解决旅行商问题(Traveling Salesman Problem, TSP)而设计的遗传算法。SA_TSP的输入参数如下,可控制参数比SA类少:
| 参数 | 默认值 | 意义 |
|---|---|---|
| func | - | 目标函数 |
| x0 | - | 迭代初始点 |
| T_max | 100 | 最大温度 |
| T_min | 1e-7 | 最小温度 |
| L | 300 | 链长 |
| max_stay_counter | 150 | 冷却耗时 |
示例代码如下:
import numpy as np
# 导入scipy库中的spatial模块,用于计算空间距离
from scipy import spatial
import matplotlib.pyplot as plt # 设置点的数量
num_points = 15 # 生成随机点坐标,生成一个num_points x 2的数组,包含随机的x和y坐标
points_coordinate = np.random.rand(num_points, 2) # 定义起始点和结束点的坐标
start_point = [[0,0]] # 起始点坐标
end_point = [[1,1]] # 结束点坐标# 将起始点、随机点坐标和结束点合并为一个数组
points_coordinate = np.concatenate([points_coordinate, start_point, end_point])# 计算点之间的距离矩阵,使用欧几里得距离
distance_matrix = spatial.distance.cdist(points_coordinate, points_coordinate, metric='euclidean') # 定义目标函数,计算给定路线(routine)的总距离
def cal_total_distance(routine): ''' 目标函数。输入一个路线(routine),返回一个总距离。route是一个一维数组,表示访问点的顺序。'''num_points, = routine.shape # 获取路线中点的数量# 将起始点和结束点的索引添加到路线数组中routine = np.concatenate([[num_points], routine, [num_points+1]])# 计算路线中相邻点之间的距离,并累加得到总距离return sum([distance_matrix[routine[i], routine[i + 1]] for i in range(num_points + 1)])# 导入模拟退火算法的TSP求解器
from sko.SA import SA_TSP# 初始化模拟退火TSP求解器
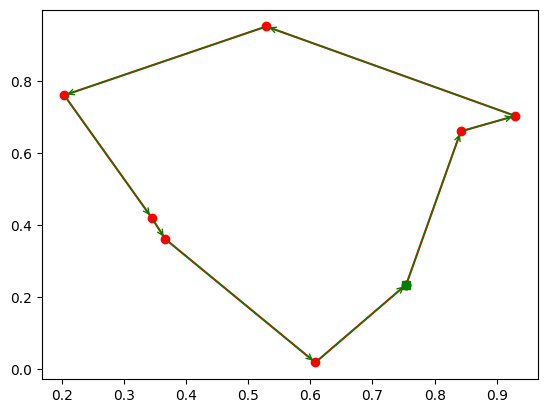
sa_tsp = SA_TSP(func=cal_total_distance, x0=range(num_points), T_max=100, T_min=1, L=10 * num_points)# 运行求解器,找到最佳路线和对应的总距离
best_points, best_distance = sa_tsp.run()# 打印最佳路线和对应的总距离
print(best_points, best_distance, cal_total_distance(best_points))# 准备绘图
from matplotlib.ticker import FormatStrFormatter# 创建一个1x2的子图
fig, ax = plt.subplots(1, 2, figsize=(12,6))# 将最佳路线的点索引扩展,包括起始点和结束点
best_points_ = np.concatenate([best_points, [best_points[0]]])
# 获取最佳路线对应的坐标点
best_points_coordinate = points_coordinate[best_points_, :]# 在第一个子图中绘制模拟退火算法的最优解历史
ax[0].plot(sa_tsp.best_y_history)
ax[0].set_xlabel("Iteration")
ax[0].set_ylabel("Distance")# 在第二个子图中绘制最佳路线
ax[1].plot(best_points_coordinate[:, 0], best_points_coordinate[:, 1],marker='o', markerfacecolor='white', color='red', linestyle='-')# 添加箭头表示路线方向
for i in range(num_points):ax[1].annotate('', xy=best_points_coordinate[i + 1], xytext=best_points_coordinate[i],arrowprops=dict(arrowstyle='->', color='green'))# 使用绿色方块标记起点
ax[1].plot(best_points_coordinate[0, 0], best_points_coordinate[0, 1], 'gs')# 设置坐标轴的格式
ax[1].xaxis.set_major_formatter(FormatStrFormatter('%.3f'))
ax[1].yaxis.set_major_formatter(FormatStrFormatter('%.3f'))# 设置坐标轴的标签
ax[1].set_xlabel("Longitude")
ax[1].set_ylabel("Latitude")# 显示图形
plt.show()
[ 8 12 4 2 3 6 9 13 1 7 11 5 0 14 10] 5.6269966435102825 5.6269966435102825

1.5 蚁群算法
蚁群算法(Ant Colony Algorithm,ACA)是一种模拟蚂蚁寻找食物的行为的算法,用于解决路径优化问题。灵感来源于蚂蚁寻找最短路径到达食物源的现象。下面用探险来解释蚁群算法的核心理念:
- 探险准备:设想一群探险者要穿越一片未知的森林寻找宝藏。他们不知道宝藏的确切位置,只能通过试错来探索路径。
- 信息素的发现:探险者们在走动时,会留下一种特殊的“信息素”。这种信息素会随着时间的推移逐渐消失,但它会吸引其他探险者朝这个方向前进。
- 选择路径:当探险者站在一个交叉路口时,他们倾向于选择信息素浓度较高的路径,因为这些路径可能已经被其他探险者探索并确认为较优的路径。
- 局部探索与全局优化:探险者在探索过程中会进行局部探索,即跟随信息素浓度高的路径前进,但同时算法也允许他们进行随机探索,以避免陷入局部最优解。
- 更新信息素:每当探险者找到一条新的路径到达宝藏,他们就会在这条路径上留下更多的信息素。这样,其他探险者在遇到这个交叉路口时,更可能选择这条新的、被更多信息素标记的路径。
- 信息素的更新规则:信息素的更新不仅取决于找到新路径的探险者,还取决于他们找到宝藏的速度。如果探险者找到了更快的路径,那么他们留下的信息素会更多,从而更快地影响其他探险者的选择。
- 收敛与稳定:随着时间的推移,探险者们会逐渐收敛到最优或近似最优的路径上,因为信息素的不断更新使得所有探险者都倾向于选择越来越短的路径。
- 算法的终止:探险结束的条件可以是找到宝藏,或者所有探险者都集中在一条路径上,或者达到一定的探索次数。
上面的比喻可能不完全准确,蚁群算法详细理解见:一文搞懂什么是蚁群优化算法。
通过这种模拟蚂蚁寻找食物的策略,蚁群算法能够有效地解决旅行商问题(TSP)和其他优化问题,尤其是在问题规模较大且求解空间复杂时。因此在scikit-opt库中的蚁群算法主要用于求解旅行商问题。ACA_TSP类用于实现蚁群算法算法,ACA_TSP类的构造参数介绍如下:
| 参数 | 默认值 | 意义 |
|---|---|---|
| func | - | 目标函数 |
| n_dim | - | 城市个数 |
| size_pop | 10 | 蚂蚁数量,更多的蚂蚁可能会提高找到全局最优解的概率,但计算成本也会增加 |
| max_iter | 20 | 最大迭代次数 |
| distance_matrix | - | 城市之间的距离矩阵,其中每个元素代表两个城市之间的距离,用于计算信息素的挥发 |
| alpha | 1 | 信息素重要程度,决定了信息素在蚂蚁选择路径时的影响。较高的alpha值意味着信息素的影响更大 |
| beta | 2 | 适应度的重要程度,决定了路径适应度(如距离或成本)在选择路径时的影响。较高的beta值意味着适应度的影响更大 |
| rho | 0.1 | 信息素挥发速度,控制信息素随时间的挥发速度。较高的rho值意味着信息素挥发得更快,从而减少信息素对路径选择的影响 |
以下案例展示了如何利用ACA_TSP类求解旅行商问题:
# 导入所需的库
import numpy as np
from scipy import spatial
import pandas as pd
import matplotlib.pyplot as plt# 设置点的数量
num_points = 20# 生成点的坐标
points_coordinate = np.random.rand(num_points, 2) # 计算点与点之间的欧几里得距离矩阵
distance_matrix = spatial.distance.cdist(points_coordinate, points_coordinate, metric='euclidean')# 定义计算旅行商问题总距离的函数
def cal_total_distance(routine):# 获取路径长度num_points, = routine.shape# 计算并返回路径的总距离return sum([distance_matrix[routine[i % num_points], routine[(i + 1) % num_points]] for i in range(num_points)])# 从 sko 库导入 ACA_TSP 算法用于解决 TSP 问题
from sko.ACA import ACA_TSP# 初始化 ACA_TSP 算法,设置问题参数
# 注意直接运行以下代码会报错:module 'numpy' has no attribute 'int'
# 需要将ACA_TSP函数报错位置改为self.Table = np.zeros((size_pop, n_dim)).astype(np.int32)
aca = ACA_TSP(func=cal_total_distance, n_dim=num_points,size_pop=50, max_iter=200,distance_matrix=distance_matrix)# 运行算法并获取最优解
best_x, best_y = aca.run()# 创建绘图窗口和轴
fig, ax = plt.subplots(1, 2)# 将最优路径的点连接起来,包括起点和终点
best_points_ = np.concatenate([best_x, [best_x[0]]])
best_points_coordinate = points_coordinate[best_points_, :]# 在第一个子图中绘制最优路径
ax[0].plot(best_points_coordinate[:, 0], best_points_coordinate[:, 1], 'o-r')# 在最优路径上添加箭头,表示行进方向
for i in range(num_points):ax[0].annotate('', xy=best_points_coordinate[i + 1], xytext=best_points_coordinate[i],arrowprops=dict(arrowstyle='->', color='green'))# 用绿色方块标记最优路径的起点
ax[0].plot(best_points_coordinate[0, 0], best_points_coordinate[0, 1], 'gs')# 在第二个子图中绘制算法性能随迭代次数的变化
pd.DataFrame(aca.y_best_history).cummin().plot(ax=ax[1])# 显示图表
plt.show()

1.6 免疫优化算法
免疫优化算法 (Immune Optimization Algorithm)是一种受人体免疫系统启发的计算方法,它模仿了生物免疫系统中识别和消灭外来病原体的过程。这种算法通常用于解决优化问题,尤其是在那些传统算法难以解决的复杂和高维度问题上。以下是免疫优化算法核心理念的探险式解释:
- 免疫系统的启发:人体的免疫系统能够识别并消灭入侵的病原体,如细菌和病毒。这种能力是通过识别特定的抗原(病原体的特定部分)来实现的。
- 抗体的多样性:免疫系统产生大量不同的抗体,以覆盖广泛的抗原类型。在优化算法中,这相当于生成多种可能的解决方案。
- 克隆选择:当抗体成功识别并结合到抗原上时,免疫系统会克隆这些抗体,以增加其数量,从而更有效地对抗病原体。在算法中,这相当于对好的解决方案进行复制和增强。
- 记忆细胞:免疫系统会保留一些成功的抗体作为记忆细胞,以便在将来遇到相同或相似的病原体时快速响应。在算法中,这意味着保留并更新最佳解决方案。
- 负选择:免疫系统通过负选择过程去除那些可能攻击自身组织的抗体。在算法中,这相当于避免找到的解决方案与问题约束条件相冲突。
- 亲和力成熟:抗体通过突变和选择过程提高其与抗原的结合能力。在算法中,这相当于通过局部搜索来改进解决方案的质量。
- 多样性维持:免疫系统通过引入新的抗体来保持其多样性,以应对不断变化的病原体。在算法中,这涉及到引入新的解决方案,以避免陷入局部最优。
- 并行处理:免疫系统同时处理多个抗原,这在算法中相当于并行评估多个解决方案。
上面的比喻可能不完全准确,免疫优化算法算法详细理解见:万字长文了解免疫算法原理。在scikit-opt库中的免疫优化算法主要用于求解旅行商问题。提供IA_TSP类用于实现免疫优化算法,IA_TSP类的构造参数介绍如下:
| 参数 | 默认值 | 意义 |
|---|---|---|
| func | - | 目标函数,用于评估解的适应度或质量 |
| n_dim | - | 城市个数,表示问题规模,即优化问题中的变量数量 |
| size_pop | 50 | 种群规模,表示每次迭代中个体的数量 |
| max_iter | 200 | 最大迭代次数,算法运行的迭代次数上限 |
| prob_mut | 0.001 | 变异概率,表示个体在迭代过程中发生变异的可能性 |
| T | 0.7 | 抗体与抗体之间的亲和度阈值,用于确定个体间的相似性,大于这个阈值认为个体间亲和,否则认为不亲和 |
| alpha | 0.95 | 多样性评价指数,用于平衡抗体的适应度和多样性,即抗体和抗原的重要性与抗体浓度的重要性 |
以下案例展示了如何利用IA_TSP求解旅行商问题:
import numpy as np# 从 sko 库的 demo_func 模块中导入用于生成TSP问题的函数
from sko.demo_func import function_for_TSP# num_points 是点的数量,points_coordinate 是点的坐标,distance_matrix 是点之间的距离矩阵
# cal_total_distance 是一个函数,用于计算给定路径的总距离
num_points, points_coordinate, distance_matrix, cal_total_distance = function_for_TSP(num_points=8)from sko.IA import IA_TSP
# 定义优化函数
ia_tsp = IA_TSP(func=cal_total_distance, n_dim=num_points, size_pop=500, max_iter=800, prob_mut=0.2,T=0.7, alpha=0.95)# best_points 是最优路径的点的索引序列
# best_distance 是最优路径的总距离
# 请注意,该段代码运行速度可能较慢,因为它涉及到大量的迭代计算
best_points, best_distance = ia_tsp.run()
# ia.generation_best_Y 每一代的最优函数值
# ia.generation_best_X 每一代的最优函数值对应的输入值
# ia.all_history_FitV 每一代的每个个体的适应度
# ia.all_history_Y 每一代每个个体的函数值
# ia.best_y 最优函数值
# ia.best_x 最优函数值对应的输入值
print('best routine:', best_points, 'best_distance:', best_distance)# 导入 matplotlib 库的 pyplot 模块,用于绘图
import matplotlib.pyplot as plt# 创建一个图形和坐标轴对象
fig, ax = plt.subplots(1, 1)# 将最优路径的点连同起点一起构成闭环路径
best_points_ = np.concatenate([best_points, [best_points[0]]])# 根据最优路径的点索引获取对应的坐标
best_points_coordinate = points_coordinate[best_points_, :]# 绘制最优路径的点,并用红色线条连接
ax.plot(best_points_coordinate[:, 0], best_points_coordinate[:, 1], 'o-r')# 在最优路径上添加箭头,表示行进方向
for i in range(num_points):# 使用 annotate 函数在两点之间添加箭头ax.annotate('', xy=best_points_coordinate[i + 1], xytext=best_points_coordinate[i],arrowprops=dict(arrowstyle='->', color='green'))# 用绿色方块标记最优路径的起点
ax.plot(best_points_coordinate[0, 0], best_points_coordinate[0, 1], 'gs')# 显示图形
plt.show()
best routine: [0 3 4 6 1 5 7 2] best_distance: [2.49060449]
1.7 人工鱼群算法
人工鱼群算法(Artificial Fish-Swarm Algorithm, AFSA)是一种模拟自然界中鱼群行为的优化算法。它的核心理念可以从以下几个方面来解释,就像探险一样:
- 探索与开发:探险家需要在未知的领域进行探索,同时也需要开发已知的资源。类似地,AFSA中的个体(模拟鱼)在搜索空间中进行探索,寻找最优解,同时也对当前找到的较好解进行开发,以期进一步优化。
- 群体行为:探险队中的成员通常会相互协作,共享信息。鱼群算法中,鱼群通过群体行为,如追随、避障等,来共同寻找食物资源。在算法中,个体会根据群体中其他个体的位置和信息来调整自己的搜索策略。
- 随机性与适应性:探险过程中充满了不确定性,探险家需要根据环境的变化灵活调整策略。人工鱼群算法中的个体也会根据环境的反馈进行自适应调整,比如改变搜索方向或速度。
- 生存竞争:在探险中,资源有限,探险家之间可能存在竞争。鱼群算法中,个体之间也存在竞争,通过竞争可以促进算法的多样性,避免早熟收敛。
- 学习和记忆:探险家会根据以往的经验来指导未来的行动。在AFSA中,个体会学习并记忆先前的成功经验,利用这些信息来指导当前的搜索过程。
- 环境互动:探险家需要与环境互动,了解环境特征。鱼群算法中的个体也会与搜索空间的环境进行互动,根据环境反馈调整搜索策略。
- 目标导向:探险的最终目的是达到某个特定的目标。AFSA的目标是找到问题的最优解,所有的行为和策略都是为了这一目标服务。
上面的比喻可能不完全准确,人工鱼群算法算法详细理解见: 人工鱼群算法超详细解析。scikit-opt库中的AFSA类用于实现人工鱼群算法,AFSA类的构造参数介绍如下:
| 参数 | 默认值 | 意义 |
|---|---|---|
| func | - | 目标函数 |
| n_dim | - | 目标函数的维度 |
| size_pop | 50 | 种群规模 |
| max_iter | 300 | 最大迭代次数 |
| max_try_num | 100 | 最大尝试捕食次数 |
| step | 0.5 | 每一步的最大位移比例 |
| visual | 0.3 | 定义了个体在搜索过程中能够感知到其他个体的范围 |
| q | 0.98 | 鱼的感知范围衰减系数 |
| delta | 0.5 | 拥挤度阈值,较大值可能导致过度聚集和局部搜索 |
以下代码展示了如何将人工鱼群算法用于多元函数优化:
def func(x):x1, x2, x3 = xreturn (x1 - x2) ** 2 + (x2 - 0.01) ** 2 + x3 ** 2from sko.AFSA import AFSAafsa = AFSA(func, n_dim=3, size_pop=50, max_iter=100,max_try_num=100, step=0.5, visual=0.3,q=0.98, delta=0.5)
best_x, best_y = afsa.run()
print(best_x, best_y)
[ 0.00593808 0.00693321 -0.00039819] 1.0554063699211183e-05
2 参考
- scikit-opt
- scikit-opt-doc
- 差分进化算法的基本概念和原理
- 10分钟搞懂遗传算法
- 粒子群优化算法的详细解读
- 模拟退火算法详解
- 从模拟退火到退火进化算法
- 一文搞懂什么是蚁群优化算法
- 万字长文了解免疫算法原理
- 人工鱼群算法超详细解析