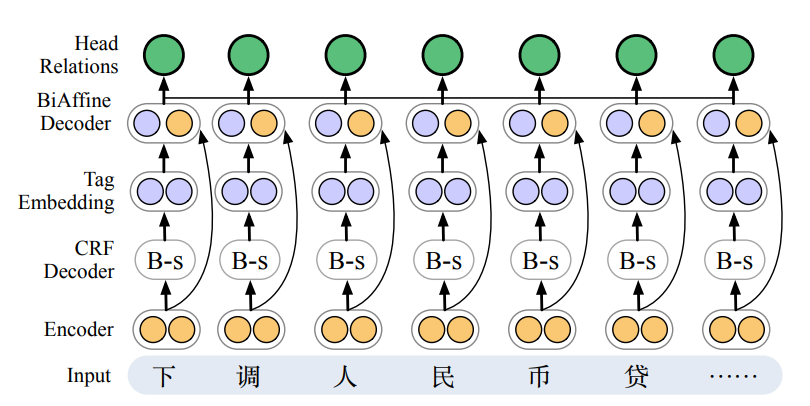
模型
- 论文中提出的模型旨在联合处理
提及词汇和共指关系。 - 该模型由一个
编码器、一个用于提及识别的CRF解码器和一个用于共指识别的BiAffine解码器组成。 - 此外,利用
HowNet的sememe知识增强了编码器。
基础模型
- 编码器:利用
BERT作为基本编码器:
\[h_1 ... h_n = BERT(c_1,...,c_n)
\]
- 提及识别:利用
CRF解码器获取序列标记输出。这有助于识别所有提及的词汇,包括融合词和分离词。(\(L_{mention}\)训练目标是最小化 gold-standard tagging sequence的交叉熵) - 共指识别:在确定提及对是否为共指关系时,模型利用了
BiAffine解码器。(\(L_{coref}\)采用平均交叉熵损失) - 联合训练:将两个子任务的损失合并在一起进行联合训练。(\(L_{joint} = L_{mention} + \alpha L_{coref}\))
Sememe加强模型
从HowNet构建Sememe。字符表示的语义通过两个步骤获得:
1)首先,通过其sememe图和其源词的位置偏移得到sememe表示:
- 使用
GAT构建sememe图。 - 第二部分是通过嵌入意义源词的
位置偏移直接获得的。 位置偏移量用 [s,e] 表示,其中 s 和 e 表示源词的开始和结束字符与当前字符的相对位置。 - 接下来,我们将这两个部分
连接起来,得到意义表示。
2)然后,通过全局注意力,聚合所有意义表示以达到字符级表示,从而产生 sememe 增强编码器。
补充
BiAffine解码器
BiAffine解码器的核心思想是利用双仿射(BiAffine)关系来对元素对之间的潜在关系进行建模和评分。BiAffine解码器通常接受来自神经网络(如LSTM或Transformer)的上下文化特征表示作为输入。
- 特征提取:从输入文本中
提取特征,通常这一步是通过预训练的模型(如BERT)来完成的。 - 仿射变换:对提取的特征进行
两次不同的仿射变换,生成两组向量。每组向量代表文本中的每个元素(如单词或字符)。 - BiAffine操作:将两组向量通过双仿射操作结合起来,生成一个
关系矩阵。矩阵中的每个元素表示一对元素之间的关系得分。 - 解码和链接:根据关系矩阵中的得分,进行
解码操作,确定元素对之间的关系(如是否共指、依存关系类型等)。 - 优化:通过训练数据优化模型参数,使得模型能更准确地识别和预测元素之间的真实关系。
GAT:图注意力网络
GAT是一种专门用于处理图结构数据的深度学习模型。它的核心是注意力机制,它允许模型聚焦于重要的节点,并动态地从邻近节点聚合信息:
- 节点表示:每个节点都有一个
向量表示,这些表示可以是节点的特征或者是经过嵌入的低维向量。 - 注意力系数的计算:对于每一对节点,GAT通过一个
可学习的函数(通常是一个小型的神经网络)来计算它们之间的注意力系数。这个系数决定了在聚合邻居节点信息时,每个邻居节点的重要性。 - 加权特征聚合:每个节点会根据计算出的注意力系数,从其邻居节点中
聚合信息。这意味着每个节点的更新表示是其邻居节点表示的加权和,权重即为注意力系数。 - 多头注意力:为了增强模型的表达能力,GAT通常会采用
多头注意力机制,类似于Transformer模型。通过多个独立的注意力机制并行处理信息,然后将结果聚合,可以提高学习的稳定性和性能。 - 非线性激活:聚合完邻居节点信息后,通常会应用
非线性激活函数(如ReLU),以增加模型的非线性表达能力。
Liu Y, Zhang M, Ji D. End to end Chinese lexical fusion recognition with sememe knowledge[J]. arXiv preprint arXiv:2004.05456, 2020.

![P2163 [SHOI2007] 园丁的烦恼 题解](https://cdn.luogu.com.cn/upload/image_hosting/aidicipl.png)