1、安装wsl2
具体过程网上一搜一把,这里就先略过了,只有wsl2能用哈
2、wsl里装docker,及相关配置
装docker
wget https://download.docker.com/linux/static/stable/aarch64/docker-23.0.6.tgz
cd /mydata/tmp/
tar -zxvf docker-23.0.6.tgz
mv docker/* /usr/bin/
mv docker.service /usr/lib/systemd/system/
chmod +x /usr/lib/systemd/system/docker.service
装完后有个小问题,wsl里的systemctl没法用,所以要编辑 /etc/wsl.conf 文件,添加:
[boot]
systemd=truewsl --shutdown 停止后再启动。
然后是某些总所周知的原因国内没法用dockerhub比较烦,这里推荐 这个教程 来解决。
3、给wsl装上 NVIDIA Container Toolkit,并让wsl能识别显卡
只用CPU来跑ollama的话可以跳过这一步,不过CPU真的太慢了。
装 NVIDIA Container Toolkit:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get updatesudo apt-get install -y nvidia-container-toolkit然后 nvidia-smi 看一下(提示没nvidia-smi命令的话 apt-get install装一下),这时候极大可能看到的列表为空。
查阅n卡官网的说明我们得知,还需要去 https://www.nvidia.com/Download/index.aspx 这个地址下载对应你显卡版本的GeForce Game Ready 驱动程序。
下载安装,重启电脑,再敲nvidia-smi命令,看到如下信息就是wsl识别到显卡了:
nvidia-smi
Sun Aug 4 22:21:33 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 560.70 CUDA Version: 12.6 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|4、docker里跑ollama
运行如下命令启动ollama,只用GPU的话把--gpus=all这个去掉就行:
docker run -d --gpus=all -v /dockerdata/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama如下命令拉取想要的模型
docker exec -it ollama ollama pull然后运行如下命令就可以对话了
docker exec -it ollama ollama run llama3.1或者调web接口:
curl http://localhost:11434/api/generate -d '{"model": "qwen:4b","prompt": "写一个冒泡排序","stream": false
}'可以看到GPU用起来了:
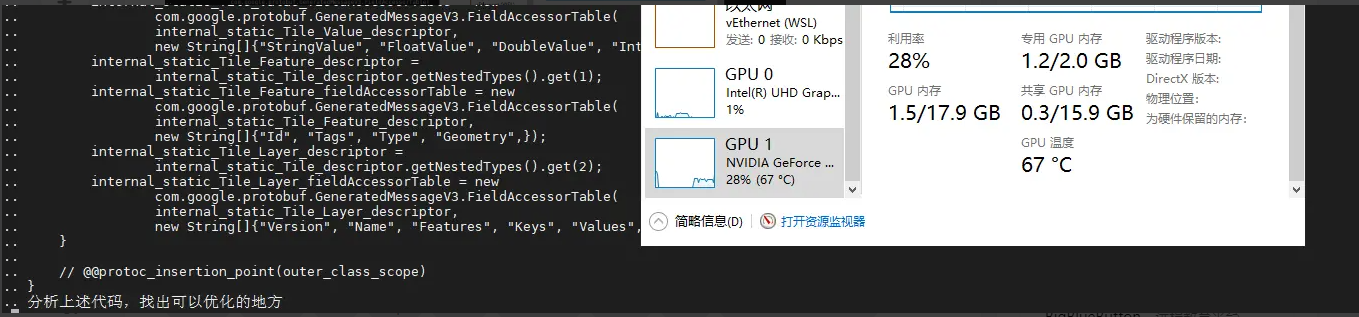
虽然笔者的GPU是老掉牙的MX150,但性能明显比CPU模式要好很多,CPU跑这个问题要3分钟左右才有响应,但是GPU10多秒就开始有流输出了。但奇怪的是流输出开始后,GPU的使用率立马又掉下去了,不知道这个是bug还是feature还是笔者哪里没弄对,后面再研究一下。