那么LLM是否也可以进行推理呢?之前我们学过,LLM可以通过提示词或者few-shot,zero-shot-Cot等进行推理。下面介绍一个新方法:自我一致性(Self-Consistency)
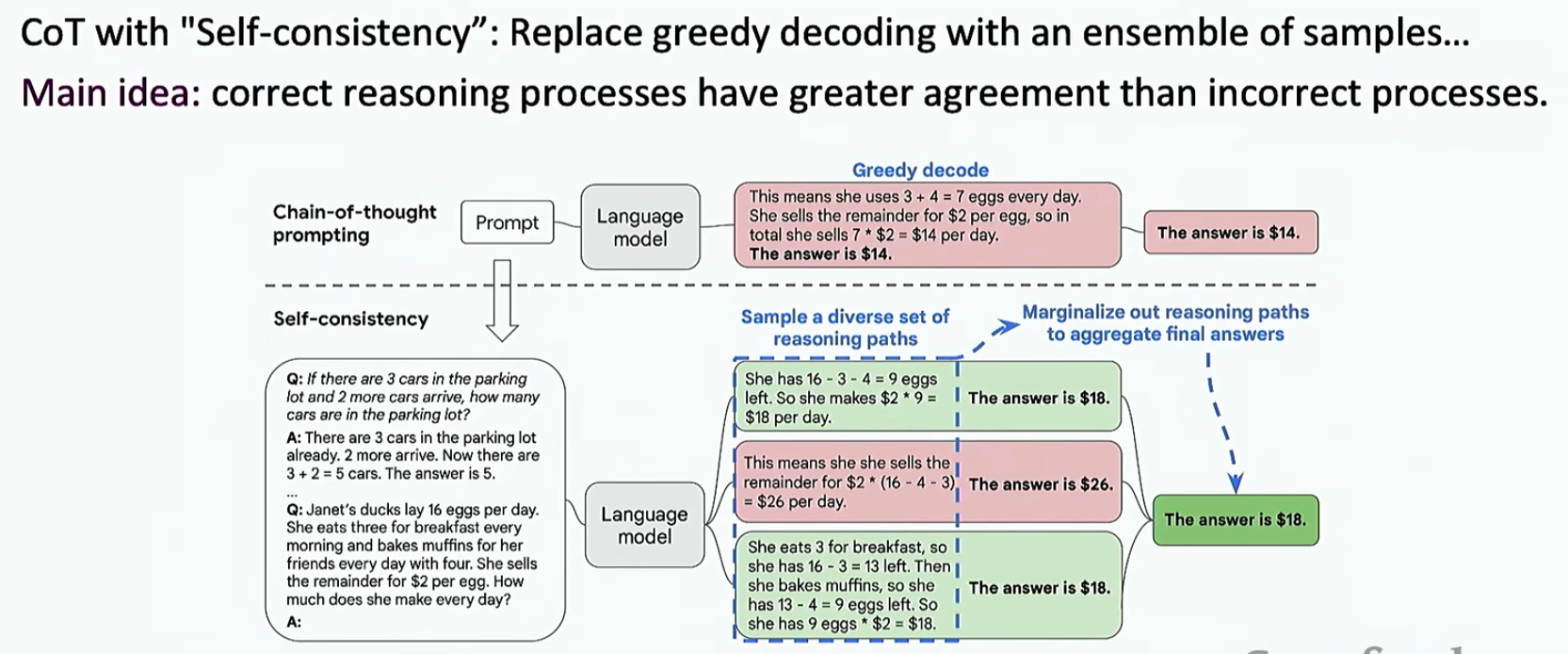
下面来看一下效果

还有一种策略:将一个问题分解成多个小问题逐个解决


这种方法的泛化性甚至很好,也就是说我们举出的例子是两个推理步骤,模型可以不止推理两步,如下

但是这种方法的必要性也存在争议,如下

上面讨论的都是LLM,那么如果我们想要让LM进行推理,应该怎么做呢?
一个方法就是知识蒸馏,这就是Orca
- Collect a wide variety of instructions from the FLAN-v2 collection
FLAN-v2是一个混合数据集,包含了多种类型的数据,如下

- Prompt GPT4 or ChatGPT with these instructions along with a system message
系统消息的目的是让LLM给出详细的推理过程,如下

- Finetune Llama-13b on outputs generated via ChatGPT + GPT4
之前都是小学数学题,现在我们换一种形式的推理问题,使用BigBench-hard.BigBench-hard涵盖了多种类型的推理任务,示例如下



来看下这种训练的效果如下

我们还有一种思路,就是语言模型基于自己生成的好答案进行微调,这个叫ReST(Reinforced Self-Training)

这个Improve阶段的重新训练就是把最开始的问题当做特征,模型自己的优质输出当做标签,重新放到模型里面,进行训练就好了
那么模型的推理是否可信呢?也就是说模型得到其答案到底是因为推理呢还是因为其他东西?我们做个实验来进行检查,让模型在数据集上进行回答,并且在若干步推理后直接中断模型的推理让其直接输出答案,去看答案是否与有推理的过程是一样的,结果如下
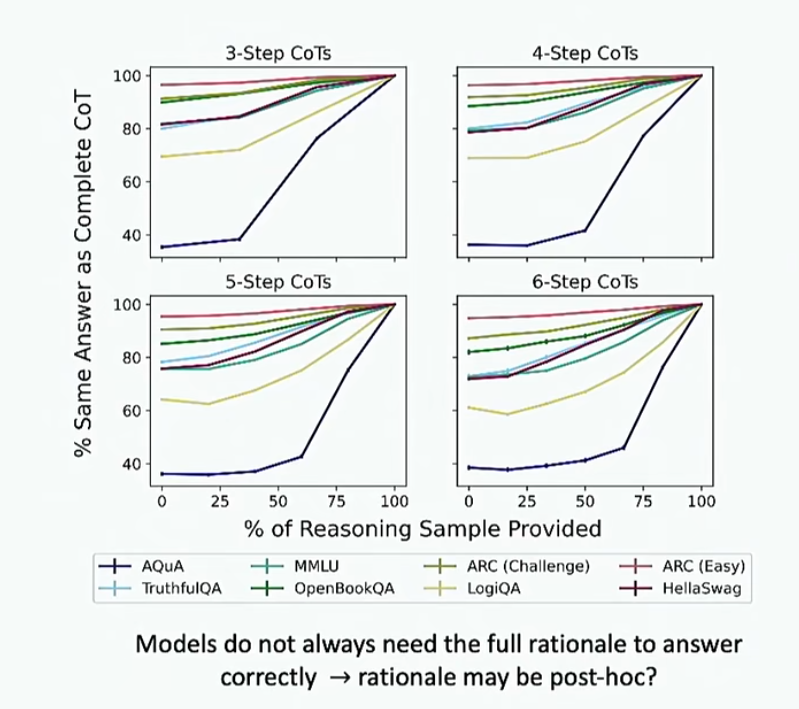
可以看到,在数据量比较大的时候,模型经过几步推理的答案都差不多,所以可能模型并不依靠其思维链。我们可以猜想,也许思维链是对模型答案的事后解释
我们还可以做另一个实验,在模型推理的某一步中对其当前的推理步骤进行干扰,然后再让其结束剩下的推理,如果答案都差不多就印证了我们的结论。结果如下

可以看到此时不一定了。但是也有数据集支撑我们的结论
那么模型在推理的时候,到底是记住了数据还是真的在进行推理呢?我们创建一个在数据集中不常见的数据即可(下面的图片把这种数据叫做反事实,其实叫做分布外更好),比如模型会做十进制加法,我们就创建一个九进制加法
结果如下

可以发现在利用分布外数据的时候,性能显著下降,所以模型更多地是记住了数据
我们还可以利用字符串变换来构造分布外数据进行测试。下图中,上面的是分布内数据,下面的是分布外数据

甚至还可以直接修改字母表顺序
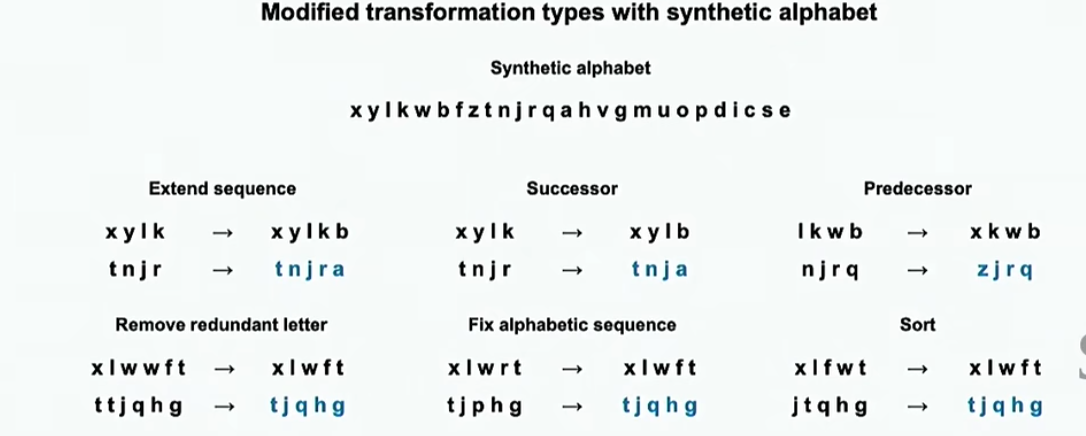
结果如下

接下来介绍代理(Agent)
首先要明白,环境,代理,动作和观察。如下

代理接收指令\(g\),对环境发出动作,并在环境中进行观察
环境的例子如下

代理的例子如下



在没有LM之前,Agent是怎么工作的呢?
第一种方法比较简单,利用类似机器翻译的过程,将自然语言映射到概率最大的形式语言上,如下

第二种方法比较复杂,从(指令,轨迹)对中推断可执行的、结构化的计划(推断过程也类似于机器翻译),并训练一个模型将指令转换为计划

第三种思路是直接强化学习

现在就是使用离线强化学习去做(视频00:38:49开始)
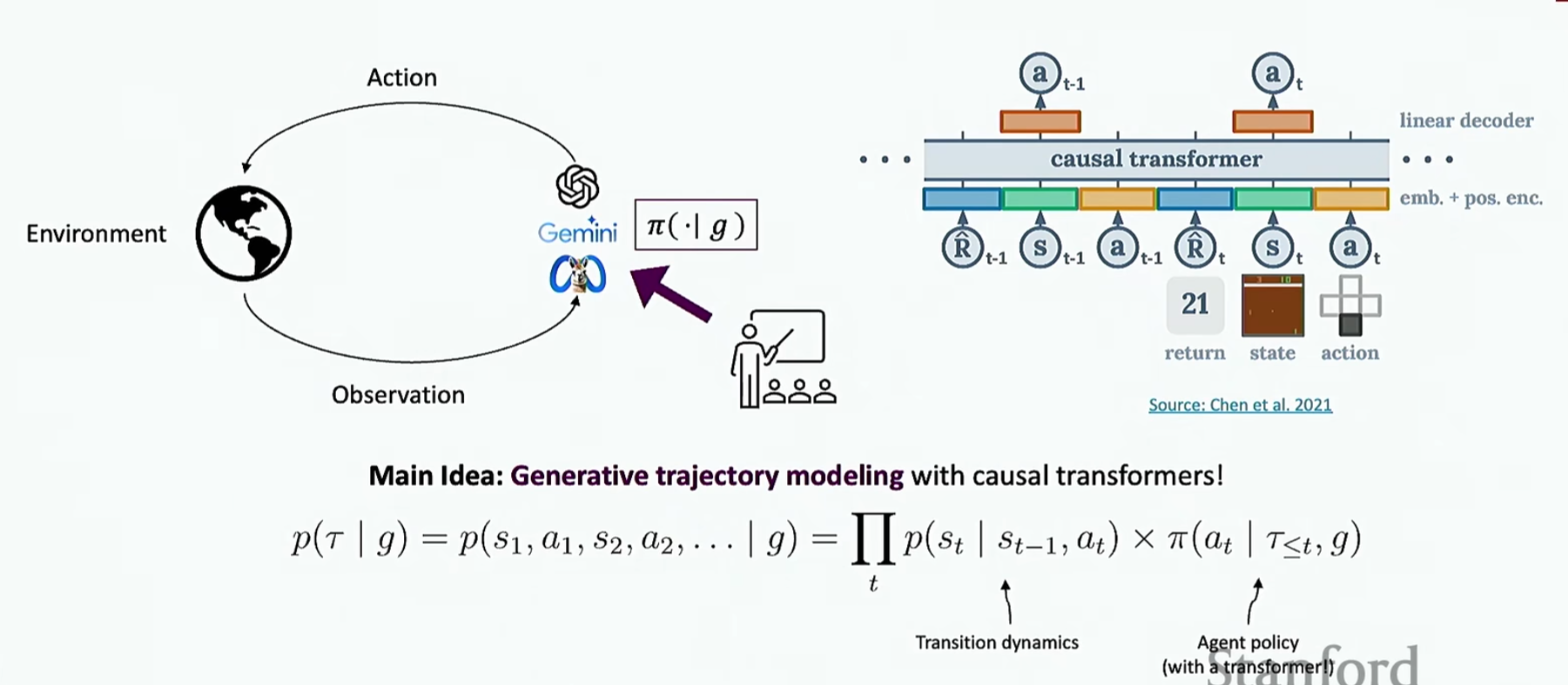
下面介绍几个评估Agent的环境
第一个是miniWob,就是评估Agent与浏览器的简单交互

第二个是更加接近现实的WebArena

第三个是WebLINX

那么如何训练Agent呢?标准方法就是人工标注数据集

显然有缺陷,因为与环境交互的方法太多了,人类不可能标注完
还有一种方法就是前面提到的让Agent利用自己的输出轨迹进行微调。具体步骤是:让我们要训练的Agent对环境作出一系列行为形成多个轨迹(比如让Agent在MiniWoB中进行随机的点击,滑动等,最后生成很多个轨迹);用另一个Agent将生成的轨迹转换成自然语言指令,如果能转换明白就将转换的指令记录下来
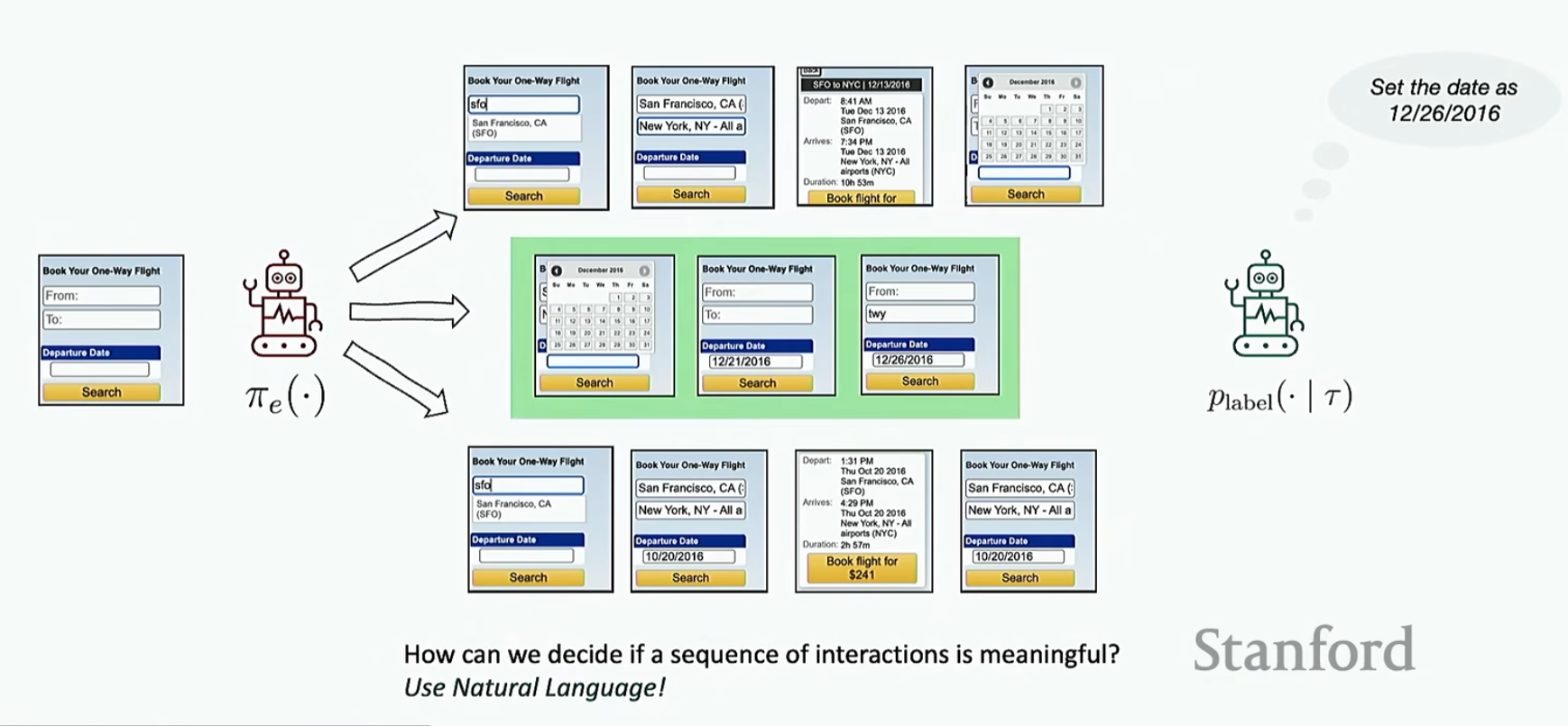
然后将转换的指令输入我们要训练的Agent,现在不再随机探索,而是让Agent生成与这个指令最匹配的操作序列,然后去看这个操作序列是否可以完成指令,如果可以直接将这一组数据加入微调数据中
那么如果Agent对某一条微调数据做错了怎么办?此时不要丢弃这个数据(因为成本很大),而是利用另一个Agent重新将训练Agent生成的轨迹进行标注(也就是将这个轨迹干的事正确标注),然后重新训练
总结如下

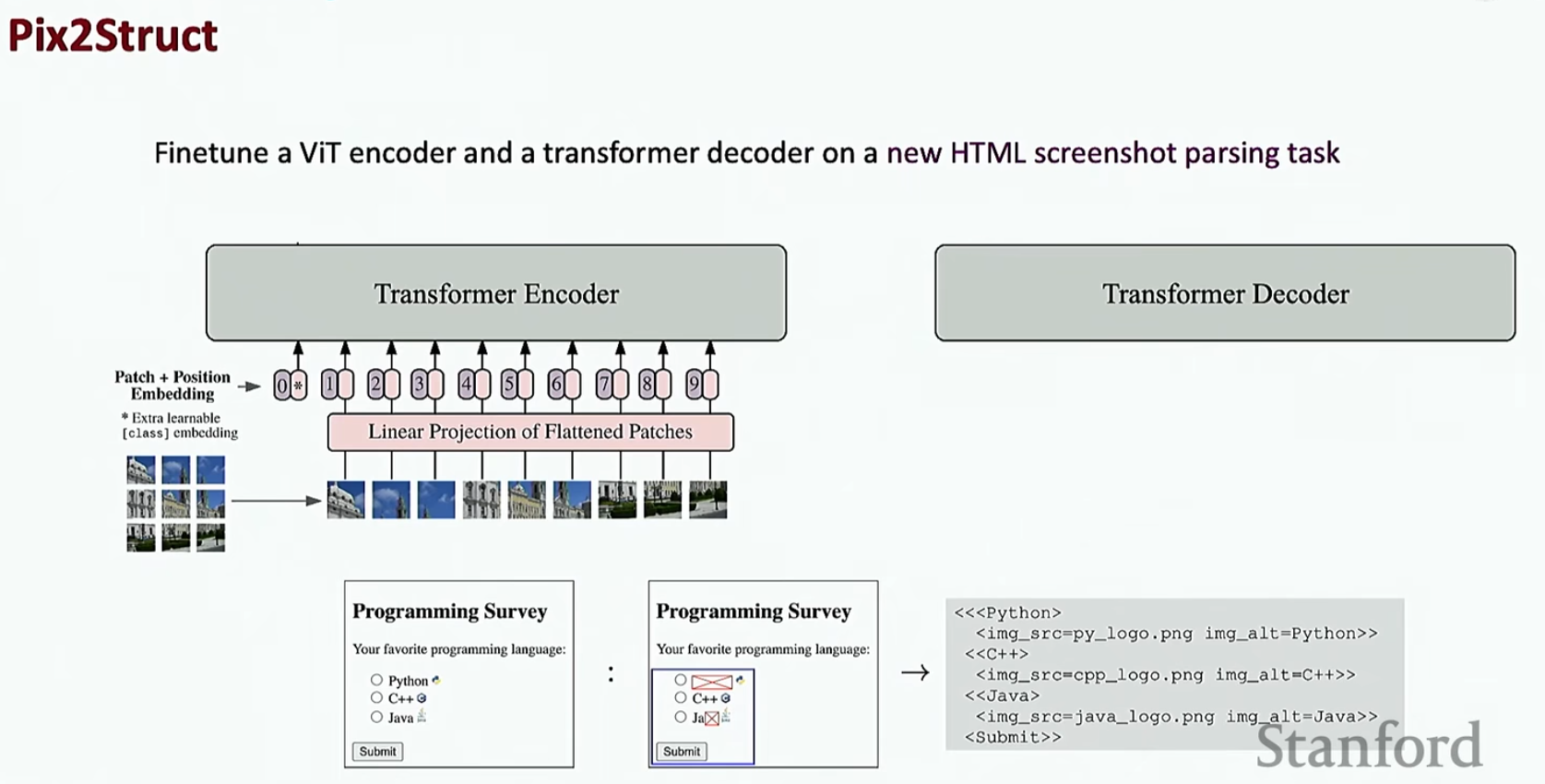
上面我们介绍只基于文本的Agent,但是由于HEML文本在现实中可能非常长,所以这种做法不一定OK,接下来介绍视觉模型,如下
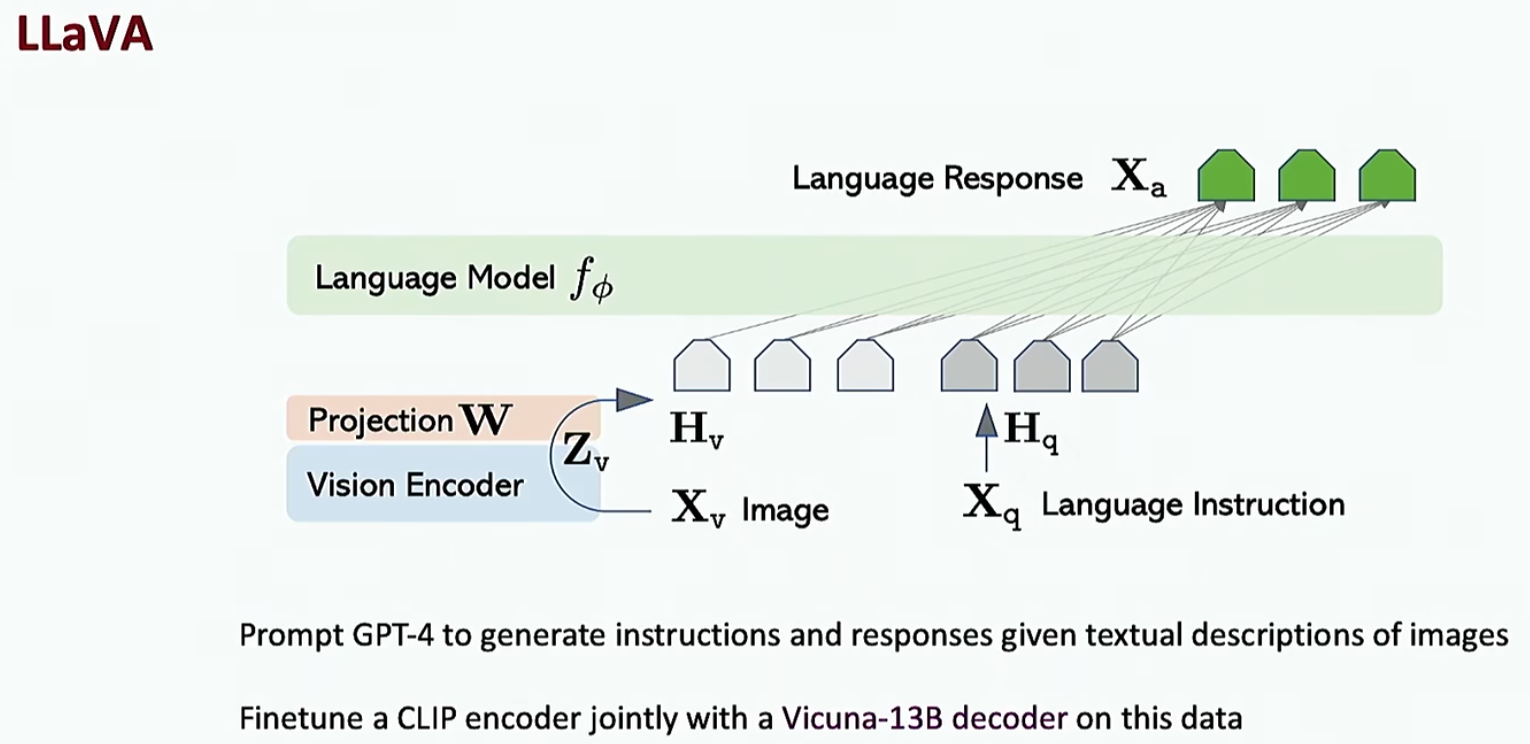
还有一种方法如下
对今天的总结如下