苹果公司发布论文公开其 AI 模型的训练细节,放弃英伟达GPU而转向选择谷歌TPU芯片。科技巨头们在尖端 AI 训练方面开始寻求更多元化的算力硬件解决方案。
苹果公司发布论文公开其 AI 模型的训练细节,放弃英伟达GPU而转向选择谷歌TPU芯片。科技巨头们在尖端 AI 训练方面开始寻求更多元化的算力硬件解决方案。北京时间 7 月 30 日,苹果公司发布了一篇研究论文,论文显示苹果公司使用了谷歌开发的 TPU 芯片而非英伟达的 GPU 芯片来训练其人工智能系统“苹果智能”(Apple Intelligence)中的 AI 模型 Apple Foundation Model(简称 AFM)。苹果公布其使用了 2048 片 TPUv5p 芯片来训练拥有 27.3 亿参数的设备端模型 AFM-on-device ,以及 8192 片 TPUv4 芯片来训练其为私有云计算环境量身定制的大型服务器端模型 AFM-server。
苹果放弃英伟达 GPU 转向谷歌 TPU 的战略选择,在科技界投下了一枚震撼弹,英伟达股价应声下跌超 7%,创下近三个月最大跌幅,市值蒸发 1930 亿美元。苹果此次选择依赖谷歌的云基础设施、使用谷歌 TPU 进行其 AI 模型训练,充分反映了科技巨头们在尖端 AI 训练方面开始寻求更多元化的解决方案的趋势。
在这篇文章中,我们希望梳理与阐释:
苹果使用 TPU 训练其 AI 模型的技术细节,包括训练规模、训练方法、算力硬件配置情况、模型能力的基准测试结果;
对 TPU 的技术解读,TPU 与 GPU 在架构和设计层面有哪些本质区别,以及面向 AI 训练场景时 TPU 有何优势;
北美人工智能和半导体圈正在发生的AI算力硬件的转向,包括以英特尔、微软、AWS、特斯拉等为代表的科技巨头们所做的替代或超越英伟达 GPU 的尝试;
一夜爆红的 AI 专用芯片初创公司们不断涌现并大受资本瞩目与追逐,海外投资界对AI芯片创业赛道的投资选择;
TPU VS. GPU,海外的 AI 算力硬件市场现在一片火热,国内如何在AI专用芯片领域实现技术与产品的突围;
......
苹果与英伟达 GPU 的公开分手
英伟达一直是 AI 算力基础设施领域的领导者,在 AI 硬件市场、尤其是 AI 训练领域,其市场份额在 80% 以上,英伟达 GPU 一直是如亚马逊、微软、Meta、OpenAI 等众多科技巨头在 AI 和机器学习领域的首选算力解决方案。
然而,市场格局正在迅速变化。据悉,谷歌早在 2013 年就开始在内部研发专用于 AI 机器学习算法的芯片,直到 2016 年这款自研的名叫 TPU 的芯片才被正式公开。在 2016 年 3 月打败李世石和 2017 年 5 月打败柯杰的 AlphaGo,就是使用谷歌的 TPU 系列芯片训练而成。谷歌 TPU 作为传统 GPU 的替代,旨在比通用 GPU 更高效地处理 AI 工作负载中常见的张量运算。
如今,TPU 已经成为谷歌 AI 战略的核心。谷歌在 2023 年 12 月官宣了全新的基于 TPU 训练而成的、包含三个版本的多模态大模型 Gemini。根据谷歌的基准测试结果,其中的 Gemini Ultra 版本在许多测试中都表现出了「最先进的性能」,甚至在大部分测试中「完全击败」了 OpenAI 的 GPT-4。不过,不像英伟达,谷歌并不会以独立产品的形态单独出售自己的TPU 芯片,而是通过谷歌云平台(Google Cloud Platform,简称 GCP)向外部客户提供基于 TPU 的算力服务。这也意味着使用谷歌 TPU 的客户需要在谷歌的生态系统内开发软件,包括使用其提供的集成工具和服务来完成 AI 模型的开发和部署流程。

这一次,苹果虽然在论文中没有明确表示其完全没有使用英伟达 GPU,但苹果在描述其训练 AFM 模型所用的 AI 基础设施时详细分享了使用谷歌 TPU 的很多数量、配置及性能细节,而刻意忽略了对英伟达硬件的任何提及,这一细节确实暗示了苹果有意选择了谷歌的技术。
苹果过去一直极少披露自己用于开发目的的硬件选择,再考虑到英伟达 GPU 一直以来的行业领导地位,这一次苹果公开选择从英伟达 GPU 转向拥抱谷歌 TPU 的举措,极大可能会激励其他科技公司探索英伟达 GPU 之外的替代方案,TPU 的强大性能和用于AI模型训练时的高能效比,定将吸引大量寻求优化 AI 工作负载的企业。
苹果使用 TPU 进行 AI 模型训练的技术细节
苹果的工程师们在论文中详细描述了谷歌 TPU 如何被组织成大型集群,为苹果 AI 模型的训练提供必要的计算能力。AFM 模型的预训练结合了张量(tensor)、全分片数据并行(fully-sharded-data-parallel)和序列并行(sequence parallelism)三种技术,模型训练在扩展到巨量模型参数和长序列长度时依然能保持高效率和高硬件利用率。苹果在论文中写到,TPU 的使用 “使我们能够以高效的、可扩展的方式训练 AFM 模型,包括设备端模型 AFM-on-device、服务器端模型 AFM-server,以及更庞大而复杂的 AI 模型。”

苹果 AFM 模型的预训练拥有三个不同阶段,分别是:核心阶段(Core Stage),这是预训练过程中算力消耗与花费最多的阶段,模型在此阶段主要学习基础的语言模型能力;持续阶段(Continued Stage),训练数据的权重在此阶段被调整,降低了低质量的大规模网络爬取数据的权重,而增加了高质量代码和数学内容的权重;上下文扩展阶段(Context-Lengthening Stage),这个阶段类似于持续阶段,但进行在更长的序列长度上,并且在训练数据中包括了合成的长上下文数据。
AFM-server 是苹果使用了 8192 片 TPUv4 芯片、 “从头开始”训练起来的拥有 27.3 亿参数的设备端模型。这 8192 片 TPUv4 芯片被划分为 8 组,每组 1024 片,通过数据中心网络(DCN)进行组间连接,只有数据并行(data-parallelism)会跨芯片组进行,其他类型的状态分片(state sharding)仅在组内进行,因为组内的互连带宽比组间 DCN 高出几个数量级。AFM-server 模型首先在预训练的核心阶段使用了 6.3 万亿个 token,再在持续阶段使用了额外的 1 万亿个 token ,在最后的上下文扩展阶段再额外使用了 1000 亿个 token。整个预训练过程中持续的模型浮点运算利用率(MFU)约为 52%。
AFM-on-device 使用了 2048 片 TPUv5p 芯片训练,全部芯片直接互联为 1 组。TPUv5p 作为谷歌更强大的新一代 TPU 版本,其提供的每秒浮点运算次数(FLOPS)是 TPUv4 的 2 倍,内存是 TPUv4 的 3 倍,进行模型训练的速度是 TPUv4 的 3 倍。苹果使用了知识蒸馏(knowledge distillation)和结构剪枝(structural pruning)的方法来提升训练效率和模型表现,AFM-on-device 是从一个经过剪枝的 64 亿参数模型(这个模型是使用与 AFM-server 相同的方法“从头开始”训练出的)初始化而来的。
苹果在论文中分享了 AFM 模型在指令遵循、工具使用、写作、数学等能力的基准测试中,与 GPT‐3.5 、GPT‐4、Llama-3-70B 、Gemma-7B 、Mistral-7B 等大模型的表现对比,苹果内部测试结果显示 AFM 在这些大模型关键能力上都有令人满意的表现:
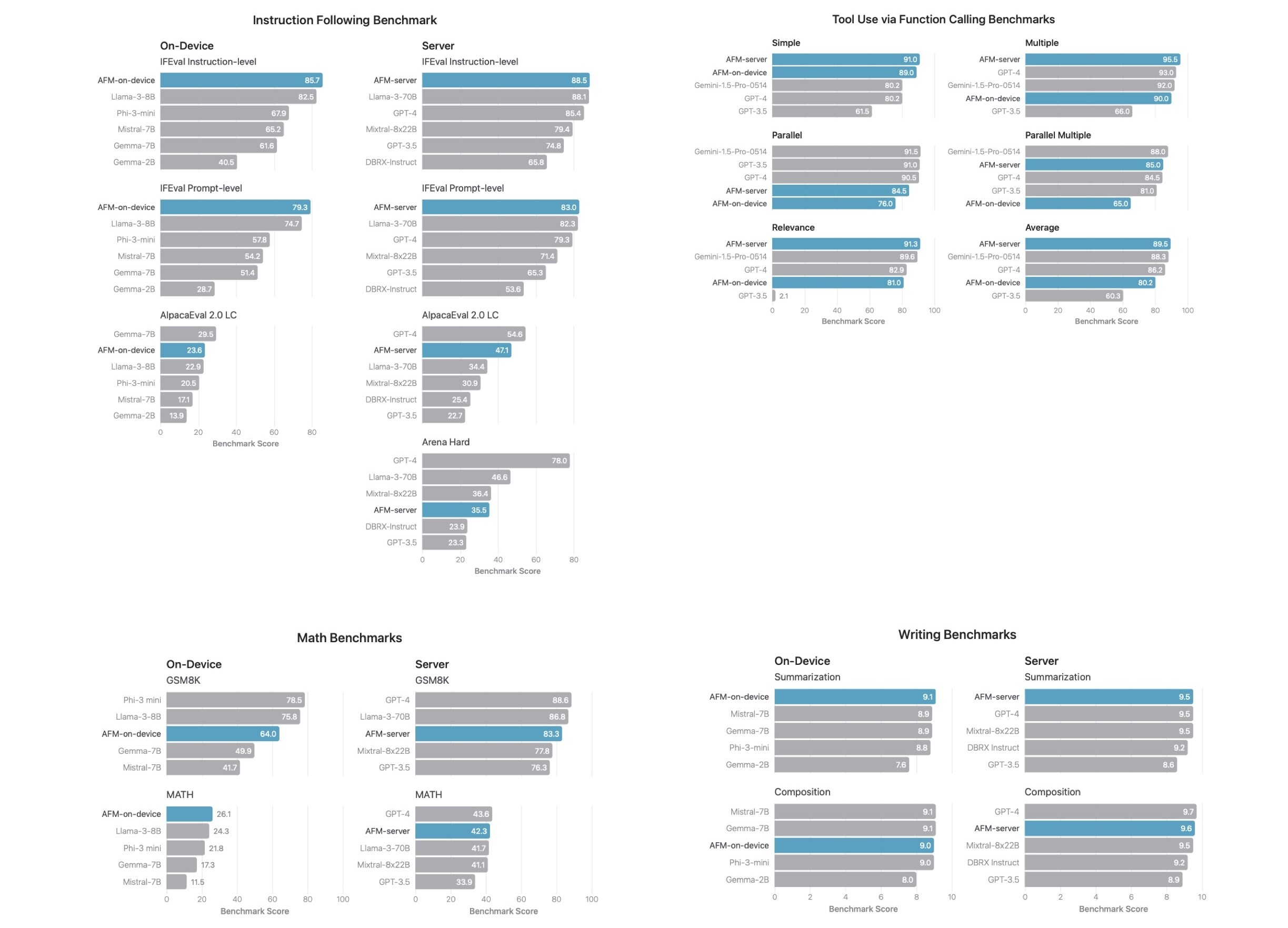
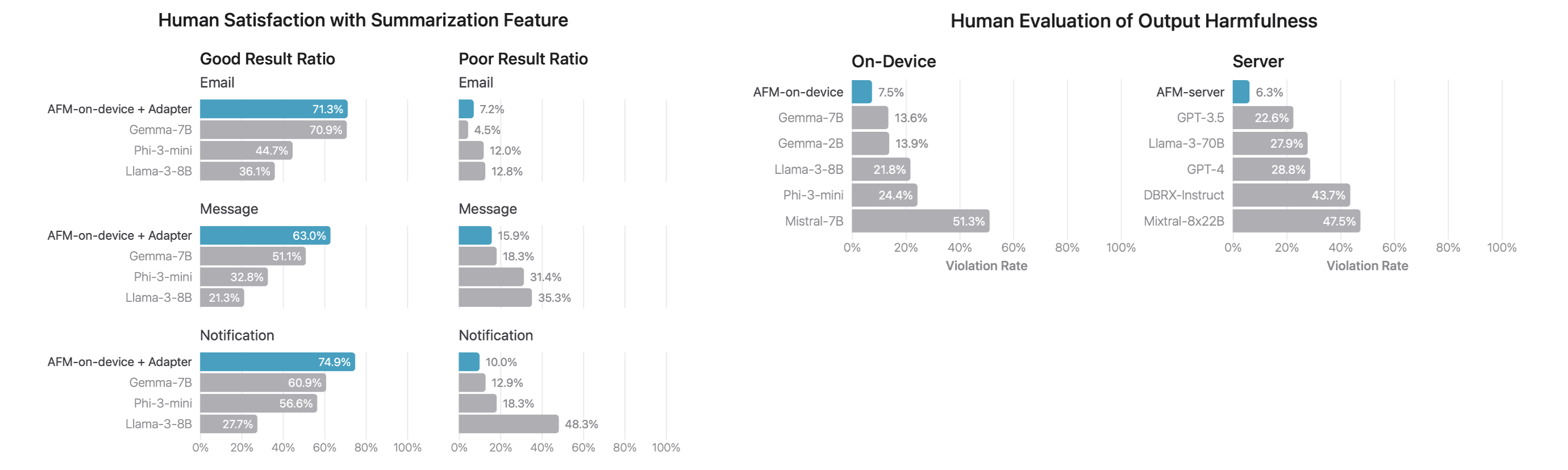
同时,在评估人类对模型输出的满意度时,AFM 在关于有害响应、敏感话题、事实正确性等方面的性能评估与测试结果也展现出了不错的结果:
TPU VS. GPU,为 AI 大模型而生的天然优势架构
GPU 最初设计用于图形处理,尤其是实时渲染和图像处理,因此对其中体面结构的矩阵和向量运算做了专门优化,后来逐渐发展成为通用计算设备(GPGPU)。GPU 具有大量结构较为简单的并行处理单元,适合处理高度并行的任务,如图形渲染和科学计算,因此被广泛应用于计算机图形学、游戏开发、视频编码/解码、深度学习训练和推理。
TPU 是谷歌专为加速机器学习和深度学习任务而设计的专用芯片,特别是针对深度学习模型的训练和推理。TPU 针对张量运算进行了高度优化,单个的脉动阵列架构吞吐量和处理效率相较 GPU 有了更大提升,特别适合于处理矩阵乘法等常见于神经网络的操作,主要用于机器学习和深度学习模型的训练和推理,特别是使用 TensorFlow 框架的任务。
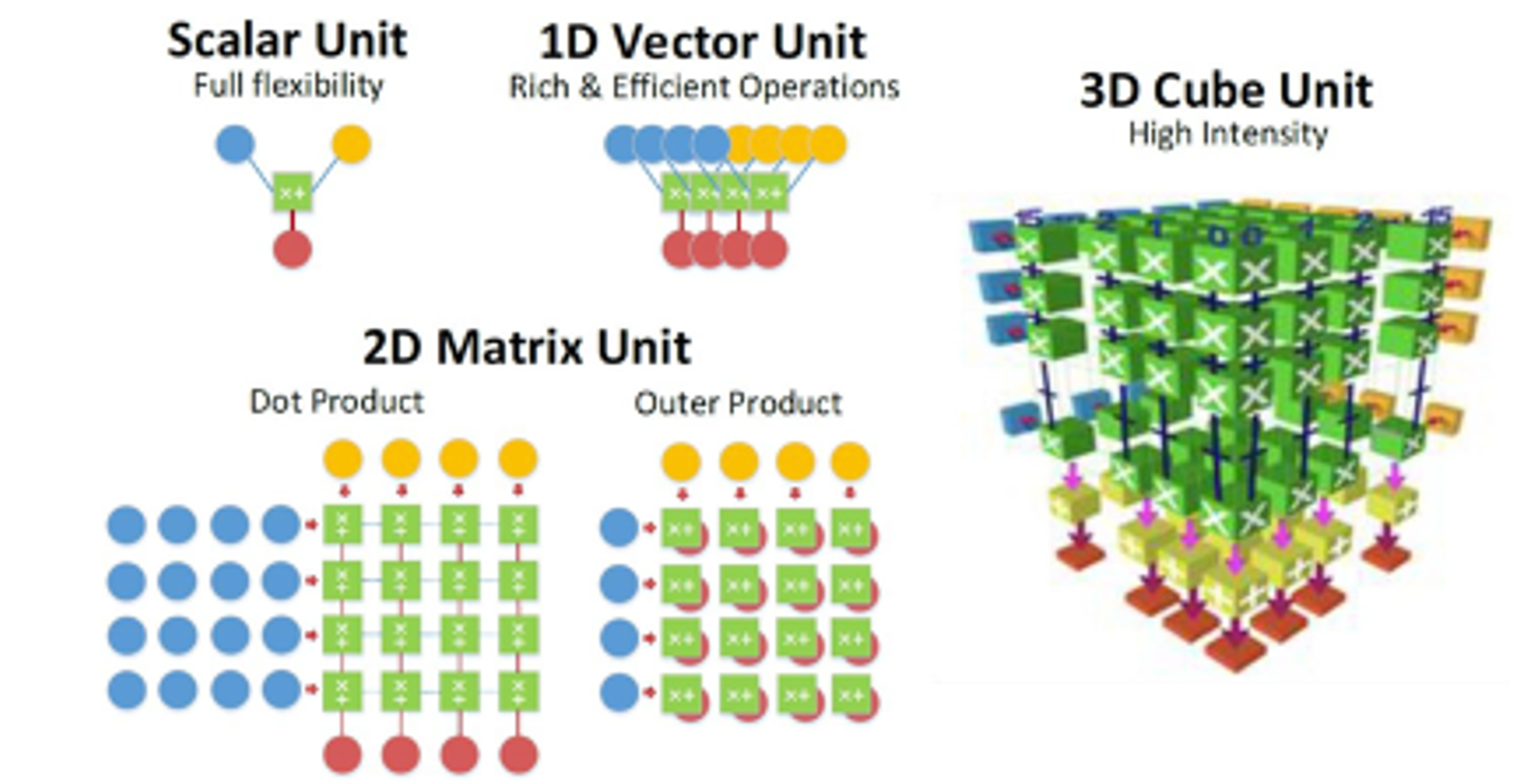
TPU 以强大的并行处理能力实现了模型训练速度和精度的双重提升,可以说是比 GPU 更适合进行大量部署或使用的深度学习计算单元:
-
多维度的计算单元提高计算效率:相较于 CPU 中的标量计算单元和 GPU 中的矢量计算单元,TPU 使用二维乃至更高维度的计算单元完成计算任务,将卷积运算循环展开的方式实现最大限度的数据复用,降低数据传输成本,提升加速效率;
-
更省时的数据传输和高效率的控制单元:冯诺依曼架构带来的存储墙问题在深度学习任务当中尤为突出,而 TPU 采用更为激进的策略设计数据传输,且控制单元更小,给片上存储器和运算单元留下了更大的空间;
-
设计面向 AI 的加速,强化 AI/ML 计算能力:定位准确,架构简单,单线程控制,定制指令集,TPU 架构在深度学习运算方面效率极高,且易于扩展,更适合超大规模的 AI 训练计算;
TPU 为 AI 大模型而生的天然优势架构,使其在面向 AI 计算场景时,在同等生产制程下相较于 GPU 可以拥有 3-5 倍的性能提升,即 12nm 制程的 TPU 芯片可以匹配 7nm 制程的 GPU 芯片性能。以中昊芯英历时近五年全自研的国内首枚已量产 TPU AI 训练芯片「刹那®」为例,「刹那®」在处理大规模 AI 模型训练和推理任务时,相较于英伟达 A100 芯片,计算性能可以超越其近 1.5 倍,在完成相同训练任务量时的能耗降低 30%,将价格、算力和能耗综合在一起测算,「刹那®」的单位算力成本仅为英伟达 A100 的 42%。

同时,因 TPU 在设计之初就将满足机器学习/深度学习所需的高速的数据流与计算流纳入核心设计理念中,它预见并致力于解决芯片片间互联的症结。面对如今千亿以上参数的超大规模模型训练所需的计算性能与资源,当需要构建千卡、万卡级别的大规模计算集群时,TPU 的这一片间互联优势将能极大提升数据传输速率、可用性和能效比。正如苹果在分享 AFM 的训练细节时提到的,片间互联的芯片为一组,组内的互联带宽能比组间通过数据中心网络连接的带宽高出几个数量级,在苹果 AFM-server 的训练场景中,谷歌 TPUv5p 实现了高达 2048 片芯片的直接互联。像中昊芯英的「刹那®」芯片能够实现多达 1024 片芯片间的直接高速互联,因而在构建大规模计算集群时的系统集群性性能可以远超传统 GPU 数十倍。
与传统的 CPU 相比,GPU 的并行计算能力使其特别适合处理大规模数据集和复杂计算任务,于是在 AI 大模型爆发的近几年,GPU 一度成为了 AI 训练的算力硬件首选。然而,随着AI大模型的不断发展,计算任务在指数级地日益庞大与复杂化,这对计算能力与计算资源提出了全新的要求,GPU 用于 AI 计算时的算力利用率较低、能耗较高的能效比瓶颈,以及英伟达 GPU 产品的价格高昂和供货紧张,让本就是为深度学习和机器学习而生的 TPU 架构凭借其高算力性能、低功耗、强集群扩展性等特性,成为了不少科技企业认为的下一代 AI 算力基础设施的新方向。
TPU 与类 TPU 芯片,AI 硬件的新转向
苹果并不是唯一转向了非 GPU 方向来构建 AI 算力基础设施以支撑 AI 模型训练的科技巨头。同时,也不仅仅是谷歌的 TPU,已有越来越多的世界顶尖科技公司在积极研发自己的 TPU 或类 TPU 架构的 AI 专用芯片:
-
早在 2019 年,英特尔就收购了来自以色列的 AI 芯片制造商 Habana Labs,并在今年 4 月推出了专攻深度学习神经网络推理的类 TPU 芯片 Gaudi 3;
-
2023 年 7 月的 xAI 会议上,特斯拉以及 X(即Twitter)的 CEO 马斯克公开宣布了特斯拉正在自研芯片且一定不会将其称为 GPU,暗示着特斯拉可能正在开发一种与传统 GPU 不同的芯片架构,以满足特斯拉的需求;
-
2023 年 11 月,微软在其全球技术大会 Ignite 上宣布推出专为 Azure 云服务和 AI 工作负载设计的 ASIC 芯片 Maia 100;
-
2023年11月底,AWS 在其“AWS re:Invent 2023”大会发布了为生成式 AI 和机器学习训练设计的云端 AI 算力芯片 Trainium 2;
-
今年 6 月,据 SemiAnalysis 报道,OpenAI 正在积极从谷歌 TPU 团队招募顶尖研发人才,开始自研 AI 专用芯片。

另一方面,全球各式各样的 TPU 或类 TPU 初创公司也在不断涌现,通过创新架构推动 AI 性能的极限,并一夜爆红,大受资本的瞩目与追逐。
今年 2 月,一家名为 Groq 的美国初创公司凭借其开发的新型 AI 处理器 LPU(Language Processing Unit)在美一夜爆红,Groq LPU 的推理速度相较于英伟达 GPU 提高了 10 倍,成本却降低到十分之一。LPU 以每秒超过 100 个词组的惊人速度执行了开源的大型语言模型 —— 拥有 700 亿个参数的 Llama-2,它还在 Mixtral 中展示了自己的实力,实现了每个用户每秒近 500 个 token。这一突破凸显了计算模式的潜在转变,即在处理基于语言的任务时,LPU 可以提供一种专业化、更高效的替代方案,挑战传统上占主导地位的 GPU。而 Groq 的创始团队与中昊芯英的创始人及 CEO 杨龚轶凡一样,就来自于原谷歌 TPU 核心研发团队。

今年 6 月底,两位从哈佛联手退学的 00 后创立的 AI 芯片公司 Etched 站在了北美科技界和投资界的聚光灯中央。Etched宣布其完成了由 Primary Venture Partners 和 Positive Sum Ventures 领投的 1.2 亿美元 A 轮融资,金额不算惊人,但其天使轮和 A 轮背后却站着一群极具分量的投资人,包括硅谷创投教父、PayPal 联合创始人、Facebook 首位投资人、OpenAI 创始人Sam Altman首支VC基金最大出资人Peter Thiel,对冲基金巨头 Stanley Druckenmiller,加密数字货币交易平台 Coinbase 前首席技术官及前 a16z 普通合伙人 Balaji Srinivasan,代码开源平台 GitHub 首席执行官 Thomas Dohmke,Youtube 联合创始人 Jawed Karim,等等。
A 轮融资宣布当日,Etched发布了他们的首款 AI 芯片—— “Sohu”,世界上第一款用于 Transformer 的 ASIC 芯片(专用集成电路)。公司宣称 Sohu 的速度比英伟达 H100 快 20 倍,与英伟达今年 3 月推出的顶配芯片 B200 相比则要快 10 倍以上,而且售价更低,“虽无法运行 CNN、RNN、LSTM 等其他 AI 模型,但在 Transformer 领域,Sohu 将是有史以来最快的芯片,甚至没有竞争对手。”
国内唯一全自研、已量产 TPU 芯片的公司
核心创始团队组建于 2018 年,作为国内唯一一家掌握 TPU 架构训推一体 AI 芯片核心技术的公司,中昊芯英的创始人及 CEO 杨龚轶凡曾在谷歌 TPU 核心研发团队深度参与过 TPU v2/3/4 的设计与研发工作。2017 年,当身在谷歌 TPU 团队的杨龚轶凡看到谷歌使用他们团队研发的 TPU 芯片训练出了 Transformer 这样可以逐步具备人脑智力水平的模型框架时,他预见并相信未来的 20 年一定是 AI 的时代,AI也一定会成为任何国家未来科技发展的核心竞争力,于是在 2018 年底回国创立了中昊芯英。
在 ChatGPT 爆火之前,中昊芯英经历了数年理念不被认可的艰难时期,彼时国内大多数的科技企业、投资机构、行业客户、研究学者都没有「大模型方向能够产生真正的人工智能」的认知与共识。然而预见并相信 AI 大模型时代必将到来的杨龚轶凡,坚信着只有如 TPU 这样专为深度学习和 AI 模型训练而生的芯片架构,才能满足大模型以及整个 AI 产业发展对算力的极高需求。直到 2022 年底 ChatGPT 带来了大模型井喷,2023 年底中昊芯英花费近五年研发的TPU人工智能训练芯片「刹那®」也成功量产,AI 专用芯片的时代如杨龚轶凡所预期地到来,公司目前已与全国多地政府、运营商、企业合作,共建多个千卡集群规模的智算中心。
结语
随着 AI 模型技术的不断发展,AI 的应用场景或将远超以往任何计算的使用场景;随着 AI 训练的计算复杂度的持续增加以及全球 AI 算力资源需求的不断扩大,训练 AI 模型所需的算力资源或许也将超过人类历史上对算力资源的想象。以 TPU 为代表的 AI 专用芯片和 GPU 的竞争必然将会更加激烈,而这种竞争也将推动 AI 硬件和软件的持续创新和优化。