注意点
全局排序 OrderBy
SELECT <select_expression>, <select_expression>, ...FROM <table_name>ORDER BY <col_name> [ASC|DESC] [,col_name [ASC|DESC], ...]
- Hive 中使用全局排序时,会将所有数据交给一个 Reduce 任务进行计算,实现查询结果的全局排序。所以数据量大的情况下会耗费大量的时间。
- Hive 适用于离线处理,执行全量计算任务时,一般不会用到全局排序。如果涉及到全局排序场景,需要将 Hive 处理后的数据存放到快速查询的产品中,比如 Presto、Impala、ClickHouse 等等。
- 数据处理过程中的全局排序,最好使用 UDF 转换为局部排序。
- 先预估数据的范围,将数据划分为多个批次;
- 每个批次会分发到一个 Reducer 执行任务,然后在每个 Reduce 作业中进行局部排序。
- 一般不涉及到全局排序,可以先通过子查询减小查询范围,然后再排序。
如果是 TOPN 的情况,先用子查询对每个 Reducer 排序,然后取前 N 个数据,最后对结果集进行全局排序。
select t.id, t.name from
(select id, name from <table_name>distributed by length(name) sort by length(name) desc limit 10
) t
order by length(t.user_name) desc limit 10;
局部排序 SortBy
SELECT <select_expression>, <select_expression>, ...FROM <table_name>SORT BY <col_name> [ASC|DESC] [,col_name [ASC|DESC], ...]
局部排序操作,Hive 会在每个 Reduce 任务中对数据进行排序,当启动多个 Reduce 任务时,OrderBy 输出一个文件,SortBy 输出多个文件且局部有序。
聚合操作 GroupBy、DistributeBy、ClusterBy
- GroupBy:按照某些字段的值进行分组,在底层 MapReduce 执行过程中,同一组的数据会发送到同一个 Reduce 任务中,意味着每个 Reduce 会包含多组数据,同一组的数据会单独进行聚合运算。
可以配置 Reducer 数量 mapred.reduce.tasks,或者配置 hive.groupby.skewindata=true 来优化数据倾斜问题。
select col1, [col2], count(1), sel_expr(聚合操作) from table
where condition -- Map端执行
group by col1 [,col2] -- Reduce端执行
[having] -- Reduce端执行
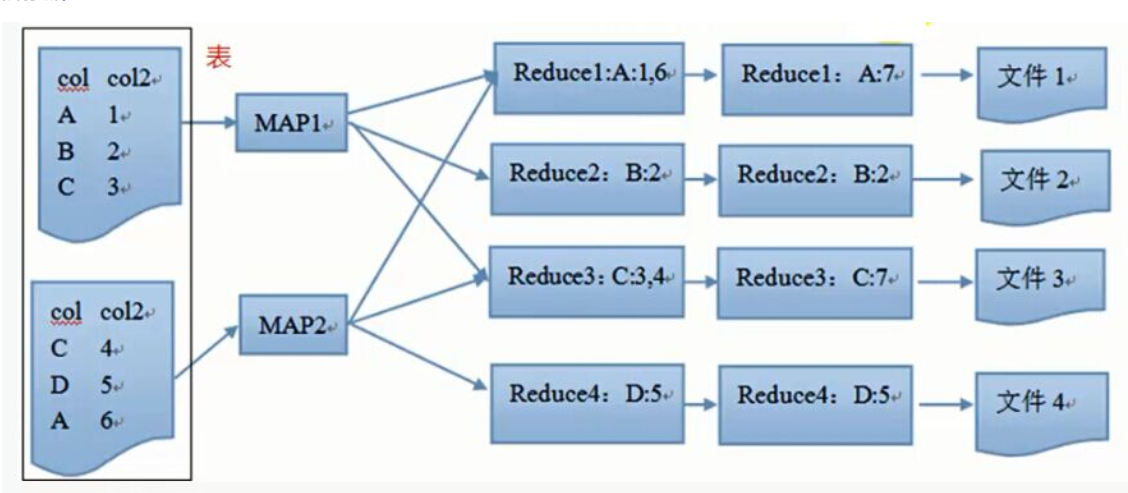
- DistributeBy:通过哈希取模的方式,将列值相同的数据发送到同一个 Reducer 任务,只是单纯的分散数据,不执行其他操作。
SELECT <select_expression>, <select_expression>, ...FROM <table_name>DISTRIBUTE BY <col_list>[SORT BY <col_name> [ASC|DESC] [, col_name [ASC|DESC], ...] ]
DistrubuteBy 通常和 SortBy 一起使用,实现先聚合后排序。并且可以指定升序 ASC 还是降序 DESC,但 DistributeBy 必须在 SortBy 之前。
- ClusterBy:把相同值的数据聚合到一起并且排序,效果等价于
distribute by col sort by col。
SELECT <select_expression>, <select_expression>, ...FROM <table_name>CLUSTER BY <col_list>
ClusterBy 没有 DistributeBy 那么灵活,并且不能自定义排序,当 DistributeBy 和 SortBy 列完全相同且按照升序排序时,等价于执行 ClusterBy。
Join优化
MySQL Join 优化
https://blog.csdn.net/norminv/article/details/108020102
MySQL JOIN 都是通过循环嵌套的方式实现,用小表驱动大表减少多次连接操作带来的性能开销。
- left join:小表 left join 大表;
- right join:大表 right join 小表;
- 用子查询代替 JOIN 减少驱动表扫描行数。
举个例子,如下用子查询优化示例:
selecto.no,s_order.no,sum(s_item.count),sum(after_sale_item.count)frombuyer_order oleft join seller_order s_order on o.id = s_order.buyer_order_idleft join seller_order_item s_item on s_order.id = s_item.seller_order_idleft join seller_order_after_sale after_sale on s_order.id = after_sale.seller_order_idleft join seller_order_after_sale_item after_sale_item on after_sale.id = after_sale_item.after_sale_id
where o.add_time >='2019-05-01'
group byo.id,s_order.id
order byo.id
limit 0,10
用子查询优化后:
selecto.id,o.no,s_order.no,(select sum(sot.count) from seller_order soleft join seller_order_item sot on so.id = sot.seller_order_idwhere so.id =s_order.id ),(select sum(osat.count) from seller_order_after_sale osaleft join seller_order_after_sale_item osat on osa.id = osat.after_sale_idwhere osa.seller_order_id = s_order.id )frombuyer_order oleft join seller_order s_order on o.id = s_order.buyer_order_id
where o.addTime >='2019-05-01'
order byo.id
limit 0,10
- 通过子查询减少了 left join 次数,从而减少驱动表的数据量;
- 减少了 groupby 的使用,方案一中先分组再取后 10 条;方案二先取后 10 条再执行聚合操作,效率更高。
SteamTable
Hive 执行 Join 操作时,默认会将前面的表直接加载进缓存,后一张表进行 stream 处理,即 shuffle 操作。这样可以减少 shuffle 过程,因为直接加载到缓存中的表,只需要等待后面 stream表的数据,不需要进行 shuffle。
使用时通过声明 /*+ STREAMTABLE(xxx) */ 来定义 stream 表:
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
MapJoin
MapJoin 即将小表直接加载到 Map 作业中,减少 shuffle 开销。
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key=b.key
数据倾斜
数据倾斜主要表现在,执行 map/reduce 时 reduce 大部分节点执行完毕,但是有一个或几个 reduce 节点运行很慢,导致程序整体处理时间很长;
数据倾斜发生原因:
join:使用 join 关键字处理的问题;- 小表驱动大表,但是 key 比较集中导致分发到某个 Reduce 上的数据远高于平均值;
- 大表驱动大表,但是分桶判断字段空值过多,空值由一个 Reduce 处理;
group by:先分派后聚合,某个 Reduce 处理耗时很长;count distinct:特殊值过多。
解决方案:
参数调节
- Map 端部分聚合:配置
hive.map.aggr=true; - 数据倾斜时进行负载均衡:配置
hive.groupby.skewindata=true;它生成的查询计划有两个 MR Job,一个 MR Job 会将 Map 的结果随机分不到 Reduce 中;另外一个 MR Job 则根据预处理结果按照 Key 值相同分布到同一个 Reduce 中,最后完成聚合操作。
SQL调节
大小表Join:MapJoin 让小表先进内存,在 Map 端完成 Reduce 操作,减少 shuffle;大表大表Join:将空值变成字符串加上随机数,将倾斜数据分散到不同 Reduce,避免零值/空值分布到同一个 Reduce 导致倾斜;
用户自定义函数
Hive 除了支持内置函数外,还允许用户自定义函数来扩充函数的功能;
UDF 对每一行数据处理,输出一行数据;
UDAF 对多行数据处理,最终输出一行数据,一般用于聚合操作;
UDTF 对一行数据处理,输出多个结果,比如将一行字符串按照某个字符拆分后进行存储,表的行数会增加。
创建函数:
-- 临时创建
ADD JARS[S] <local_hdfs_path>;
CREATE TEMPORARY FUNCTION <function_name> AS <class_name>;
DROP TEMPORARY FUNCTION <function_name>;--- 永久创建
CREATE PERMANENT FUNCTION <function_name> AS <class_name> [USING JAR|FILE <file_uri>];
DROP PERMANENT FUNCTION <function_name>;
UDF
实现方式有两种:继承UDF、继承 GenericUDF,其中 GenericUDF 处理起来更加灵活。
继承 GenericUDF 的步骤:
initialize方法,检查输入数据并初始化;evaluate方法,执行数据处理过程,返回最终结果;getDisplayString方法,定义 explain 的返回内容。
@org.apache.hadoop.hive.ql.exec.Description(name = "AvgScore",extended = "示例:select AvgScore(score) from src;",value = "_FUNC_(col)-对Map类型保存的学生成绩进行平均值计算")
public class AvgScore extends GenericUDF {// 检查输入数据,初始化输入数据@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {…}// 数据处理,返回最终结果@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {…}// 函数执行 HQL Explain 展示的字符串内容@Overridepublic String getDisplayString(String[] strings) {…}
}
- 然后将函数打包为 jar 上传到服务器对应路径
/xxxx/xxx/xxx.jar; - 将 jar 包添加到 hive 的 classpath:
add jar /xxxx/xxx/xxx.jar; - 创建临时函数与开发好的
java class关联:create temporary function func_name as "xxxx.xxx.xxx.MyUDF"; - hql 中使用临时函数:
select func_name(col) from src;;
UDAF
实现方式:继承 UDAF、AbstractGenericUDAFResolver,其中 AbstractGenericUDAFResolver 更加灵活。
使用 AbstractGenericUDAFResolver 的步骤:
- 继承
AbstractAggregationBuffer,来保存中间结果; - 继承
GenericUDAFEvaluator,实现 UDAF 处理流程; - 继承
AbstractGenericUDAFResolver,注册 UDAF。
// UDAF 注册函数
public class FieldLength extends AbstractGenericUDAFResolver {@Overridepublic GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException {return super.getEvaluator(info);}
}// 保存中间结果
class FieldLengthAggregationBuffer extends GenericUDAFEvaluator.AbstractAggregationBuffer {private Integer value = 0;public Integer getValue() {return value;}public void setValue(Integer value) {this.value = value;}@Overridepublic int estimate() {return JavaDataModel.PRIMITIVES1;}public void add(int addVal) {synchronized (value) {value += addVal;}}
}// 数据处理函数
class FieldLengthUDAFEvaluator extends GenericUDAFEvaluator {// 输入private PrimitiveObjectInspector inputOI;// 输出private ObjectInspector outputOI;// 前一个阶段输出private PrimitiveObjectInspector integerOI;/*** 数据校验、数据初始化* 由于 UDAF 会执行 Map、Reduce 两个阶段任务,所以根据 Mode.xxx 区分具体阶段* @param m* @param parameters* @return* @throws HiveException*/@Overridepublic ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {super.init(m, parameters);// Map 阶段,输入为原始数据if (Mode.PARTIAL1.equals(m) || Mode.COMPLETE.equals(m)) {inputOI = (PrimitiveObjectInspector) parameters[0];} else {// combiner、redeuce 阶段基于前一个阶段的返回值作为输入integerOI = (PrimitiveObjectInspector) parameters[0];}// 指定输出类型outputOI = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class,ObjectInspectorFactory.ObjectInspectorOptions.JAVA);return outputOI;}/*** 获取中间存放结果对象* @return* @throws HiveException*/@Overridepublic AggregationBuffer getNewAggregationBuffer() throws HiveException {return new FieldLengthAggregationBuffer();}/*** 重置中间结果* @param aggregationBuffer* @throws HiveException*/@Overridepublic void reset(AggregationBuffer aggregationBuffer) throws HiveException {((FieldLengthAggregationBuffer)aggregationBuffer).setValue(0);}/*** Map 阶段* @param aggregationBuffer* @param objects* @throws HiveException*/@Overridepublic void iterate(AggregationBuffer aggregationBuffer, Object[] objects) throws HiveException {if (objects == null || objects.length < 1) {return;}Object javaobj = inputOI.getPrimitiveJavaObject(objects[0]);((FieldLengthAggregationBuffer)aggregationBuffer).add(String.valueOf(javaobj).length());}/*** 返回 Map、Combiner 阶段结果* @param aggregationBuffer* @return* @throws HiveException*/@Overridepublic Object terminatePartial(AggregationBuffer aggregationBuffer) throws HiveException {return terminate(aggregationBuffer);}/*** Reduce 阶段* @param aggregationBuffer* @param o* @throws HiveException*/@Overridepublic void merge(AggregationBuffer aggregationBuffer, Object o) throws HiveException {((FieldLengthAggregationBuffer) agg).add((Integer)integerOI.getPrimitiveJavaObject(partial));}/*** 返回最终结果* @param aggregationBuffer* @return* @throws HiveException*/@Overridepublic Object terminate(AggregationBuffer aggregationBuffer) throws HiveException {return ((FieldLengthAggregationBuffer)aggregationBuffer).getValue();}
}
UDTF
继承 GenericUDTF 类,并重写 initialize、process、close 方法:
initialize:初始化返回值类型;process:具体数据处理过程;close:清理收尾工作;forward:传递输出给收集器;
public class JsonParser extends GenericUDTF {private PrimitiveObjectInspector stringOI = null;// 输入数据解析,初始化@Overridepublic StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {if (argOIs.length != 1) {throw new UDFArgumentException("take only one argument");}// 输入必须为 PRIMITIVE 类型,且具体类型必须为 Stringif (argOIs[0].getCategory() != ObjectInspector.Category.PRIMITIVE &&((PrimitiveObjectInspector)argOIs[0]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {throw new UDFArgumentException("take only one string argument");}// 初始化输入stringOI = (PrimitiveObjectInspector) argOIs[0];// 定义输出类型List<String> fieldNames = new ArrayList<String>();List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();fieldNames.add("name");fieldNames.add("value");fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);}private ArrayList<Object[]> parseInputRecord(String feature) {ArrayList<Object[]> resultList = null;//......//.....return resultList;}@Overridepublic void process(Object[] objects) throws HiveException {final String feature = stringOI.getPrimitiveJavaObject(objects[0]).toString();ArrayList<Object[]> results = parseInputRecord(feature);Iterator<Object[]> it = results.iterator();while (it.hasNext()) {Object[] strs = it.next();// 结果 Key-Value 传递给收集器forward(strs);}}@Overridepublic void close() throws HiveException {}
}