CH-6 时间与窗口
6.1 时间语义
-
事件时间(
Event Time):数据产生的时间,默认使用 -
处理时间(
Processing Time):数据到达窗口的时间 -
摄入时间:被Flink Source读入的时间
6.2 水位线
6.2.1 逻辑时钟
在使用事件时间时,Flink使用逻辑时钟对数据进行窗口计算。逻辑时钟依靠数据的时间戳前进,比如有如下数据:
(Bob,9:00)-->(Jack,8:55)-->(Mary,8:50) --> | Flink
当(Mary,8:50)到达Flink时,逻辑时钟就认为当前是8:50, 即8:50之前的数据都已到达,之后不会再有8:50之前的数据。
如果窗口为[8:00~9:00),那么当(Bob,9:00)到达时,窗口就会认为数据到齐。因此关闭窗口,触发计算,输出结果。
6.2.2 水位线简介
单纯的逻辑时钟存在问题:假设窗口是[8:00~9:00),算子并行度为3,每个算子都有一个逻辑时钟,当(Bob,9:00)来临时,只会发给其中一个算子,从而触发计算、获得结果,但其他两个算子仍将继续等待。
解决方案:算子接收到新数据后,除了更新自己的逻辑时钟,将数据发送给下游之外,还要定期把逻辑时钟的最新值作为特殊数据广播给下游所有算子。
这个特殊数据就是水位线,水位线的内容就是一个时间戳。
-
有序流:如果流中数据有序,那么周期性插入水位线即可。
-
乱序流:在分布式系统中,数据在节点间传输,会因为传输延迟等原因,导致数据顺序改变,比如时间戳7:00的数据早于6:55的数据到达
因此,乱序流中需解决以下问题
-
水位线生成问题:
如果7:00的数据早于6:00到达,此时已生成7:00的水位线,当6:00到达时,如果再次生成6:00的水位线,就好像发生了时钟回退,会出错,
解决方法:插入新的水位线时,先判断新的时间戳是否比之前大,如果大就生成新水位线,否则不生成。
-
迟到数据处理:
有6:55和7:00两个数据,窗口为
[6:00~7:00),7:00先到,此时就会关闭窗口,触发计算,而之后6:55才到,数据不完整,结果也将不准确。解决方案:更新逻辑时钟时,将新来的时间减去一些时间再更新
比如7:00到来时,减去2分钟,即
6:58,然后更新时钟,此时就不会触发计算,只有当7:02的数据到来时,才会触发计算,相当于等了迟到数据2分钟。注:在等待迟到数据期间,可能会有
7:00~7:02的数据到来,这些数据不会落入[6:00~7:00),而是会在[7:00~8:00),数据的时间戳决定了数据属于哪个窗口,每个窗口只收集属于它的数据。
-
水位线概念总结
-
水位线是一个特殊的数据,主要内容是一个时间戳
-
水位线基于数据的时间戳生成
-
水位线必须单调递增,确保时钟一直向前推进
-
水位线可设置延迟,稍微等一等迟到数据
-
水位线是定时生成的,默认生成周期为
200ms,可通过如下方法修改:即
WatermarkGenerator的onPeriodicEmit()方法每200ms被调用一次,可重写此方法自定义水位线生成逻辑。//单位为ms env.getConfig.setAutoWatermarkInterval(...)
6.2.3 水位线生成策略
-
水位线生成的原则
如果需要高实时性,就减少等待时间,代价是可能遗漏迟到数据,结果不够准确
如果需要高精确度,就延长等待时间,代价是花费时间会比较久,结果不够实时
-
内置水位线生成策略
Flink内置了一些水位线生成策略,方便使用:
-
有序流
WatermarkStrategy.forMonotonousTimestamps()时间戳单调增长,不会出现迟到数据的问题,直接使用时间戳字段的最大值作为水位线
case class Event(user: String, url: String, timestamp: Long) stream.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps[Event]().withTimestampAssigner(new SerializableTimestampAssigner[Event] {// 指定时间戳字段override def extractTimestamp(element: Event, recordTimestamp: Long): Long = element.timestamp}) ) -
乱序流
WatermarkStrategy.forBoundedOutOfOrderness()可设置等待时长,等待迟到数据。
生成水位线的值,是时间戳的最大值减去延迟时间。
stream.assignTimestampsAndWatermarks(WatermarkStrategy// 等待时长.forBoundedOutOfOrderness[Event](Duration.ofSeconds(5)).withTimestampAssigner(new SerializableTimestampAssigner[Event] {override def extractTimestamp(element: Event, recordTimestamp: Long): Long = element.timestamp}) )生成的水位线的值,是
最大时间戳-延迟时间-1,单位是ms-1的目的:水位线为t的含义是时间戳≤t的数据全部到齐。假设延迟为0,当时间戳为7s的数据到来时,之后还有可能来7s的数据,如果此时触发计算,那么数据将会丢失,所以生成的水位线不能是7s,而是6.999s,这样。之后再来7秒的数据也不会丢失。查看BoundedOutOfOrdernessWatermarks源码就可以发现这一点@Override public void onPeriodicEmit(WatermarkOutput output) {output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1)); }
-
-
WatermarkStrategy接口通过如下方法指定水位线生成策略
.assignTimestampsAndWatermarks()val stream = env.socketTextStream("locahost", 9998) stream.assignTimestampsAndWatermarks({Watermark Strategy})assignTimestampsAndWatermarks接收WatermarkStrategy作为参数,即水位线生成策略主要关注
WatermarkStrategy的两个方法-
createTimestampAssignerTimestampAssigner:指定数据流中某个字段作为时间戳。 -
createWatermarkGenerator:WatermarkGenerator:按照既定的方式,基于时间戳生成水位线。WatermarkGenerator接口有两个方法:@Public public interface WatermarkGenerator<T> {void onEvent(T event, long eventTimestamp, WatermarkOutput output);void onPeriodicEmit(WatermarkOutput output); }-
onEvent():每来一个新事件(数据)会触发的方法参数:当前事件、时间戳,以及允许发出水位线的Watermark-Output,可基于事件进行各种操作。
-
onPeriodicEmit():由框架周期性调用,生成水位线的方法,可由WatermarkOutput发出水位线。可通过setAutoWatermarkInterval()方法来设置生成水位线的周期时长,默认为200毫秒。
-
-
-
自定义WatermarkStrategy
WatermarkGenerator接口有两个方法:onEvent()和onPeriodicEmit(),前者在每个事件(数据)到来时被调用,后者由框架周期性调用。前者发出的是断点式生成水位线,后者发出的是周期性生成水位线-
周期性水位线生成器 -
onPeriodicEmit()通过
onEvent()观察判断输入的事件,通过onPeriodicEmit()发出水位线。object Main {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)env.addSource(new ClickSource).assignTimestampsAndWatermarks(new CustomWatermarkStrategy).print()env.execute()} }class CustomWatermarkStrategy extends WatermarkStrategy[Event] {// 指定WatermarkGeneratoroverride def createWatermarkGenerator(context: WatermarkGeneratorSupplier.Context): WatermarkGenerator[Event] = {new CustomWatermarkGenerator}// 指定时间戳字段override def createTimestampAssigner(context: TimestampAssignerSupplier.Context): TimestampAssigner[Event] = {(element: Event, _: Long) => element.timestamp} }class CustomWatermarkGenerator extends WatermarkGenerator[Event]{private val delayTime = 5000Lprivate var maxTs = Long.MinValue + delayTime + 1Loverride def onEvent(event: Event, eventTimestamp: Long, output: WatermarkOutput): Unit = {maxTs = math.max(maxTs, event.timestamp)}override def onPeriodicEmit(output: WatermarkOutput): Unit = {output.emitWatermark(new Watermark(maxTs - delayTime - 1L))} } -
断点式水位线生成器 -
onEvent()断点式生成器需要持续检测
onEvent()中的事件,当发现带有水位线信息的特殊事件时,就立即发出水位线。一般来说,断点式生成器不会通过
onPeriodicEmit()发出水位线。class PunctuatedWatermarkGenerator extends WatermarkGenerator[Event]{override def onEvent(event: Event, eventTimestamp: Long, output: WatermarkOutput): Unit = {if(event.user.equals("Mary"))output.emitWatermark(new Watermark(event.timestamp - 1L))}override def onPeriodicEmit(output: WatermarkOutput): Unit = {} }
-
-
自定义Source,使得数据自带水位线
在数据源中发送水位线后,就不能再使用
assignTimestampsAndWatermarks方法来生成水位线了,两者只能取其一。// 自定义Source class ClickSourceWithWatermark extends SourceFunction[Event] {var running = trueoverride def run(ctx: SourceFunction.SourceContext[Event]): Unit = {val random = new Randomval users = Array("Mary", "Bob", "Alice", "Cary")val urls = Array("./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2")while(running) {val curTs = Calendar.getInstance.getTimeInMillisval username = users(random.nextInt(users.length))val url = urls(random.nextInt(urls.length))val event = Event(username, url, curTs)ctx.collectWithTimestamp(event, event.timestamp)// 生成水位线ctx.emitWatermark(new Watermark(event.timestamp - 1L))Thread.sleep(1000L)}}override def cancel(): Unit = running = false }
6.2.4 水位线更新策略
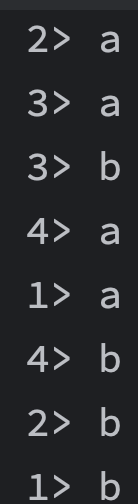
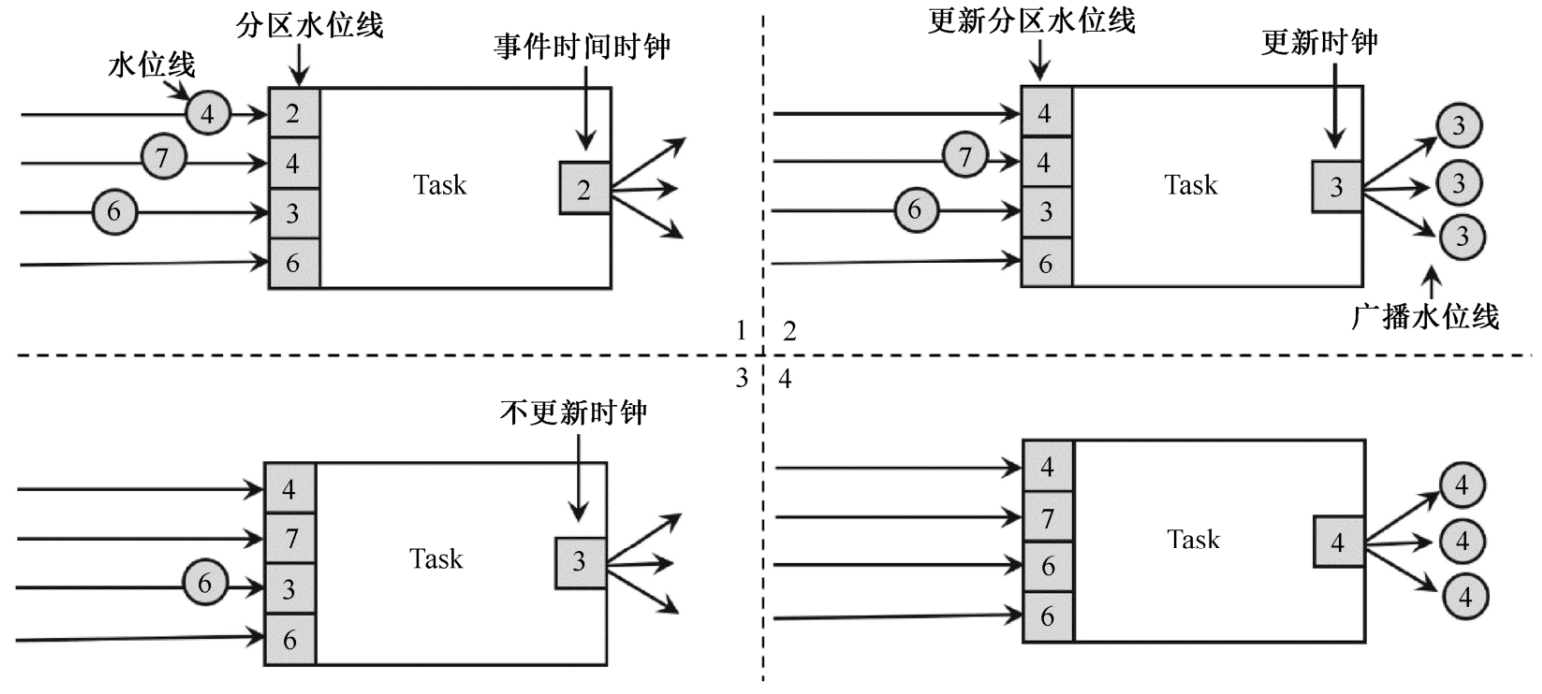
若上下游都存在多个算子,当收到来自多个分区上游的水位线时,以最小的那个水位线为准。
以下图为例,上游四个算子,下游三个算子,当前每个分区的水位线是(2,4,3,6),
-
1号图:1号上游算子发来的最大值为2,当前下游算子向下游发送水位线也就是2
-
2号图:1号上游算子发来4,下游算子更新自己,之后对所有上游水位线进行对比,发现最小值变为3,于是发送新的水位线3
3、4号图以此类推。。。
6.2.5 水位线总结
- 在数据流开始前,Flink会插入一个大小为
-Long.MAX_VALUE的水位线。数据流结束时,会插入一个Long.MAX_VALUE的水位线,以此保证所有的窗口闭合以及所有的定时器都被触发。 - 对于批处理数据集,只会在开始时插入负无穷大的水位线,结束时插入一个正无穷大的水位线。
6.3 窗口
窗口就像是一个个桶,对流进行分隔,每个数据都会分发到对应的桶中,当到达窗口结束时间时,就关闭窗口,对桶中数据进行处理。
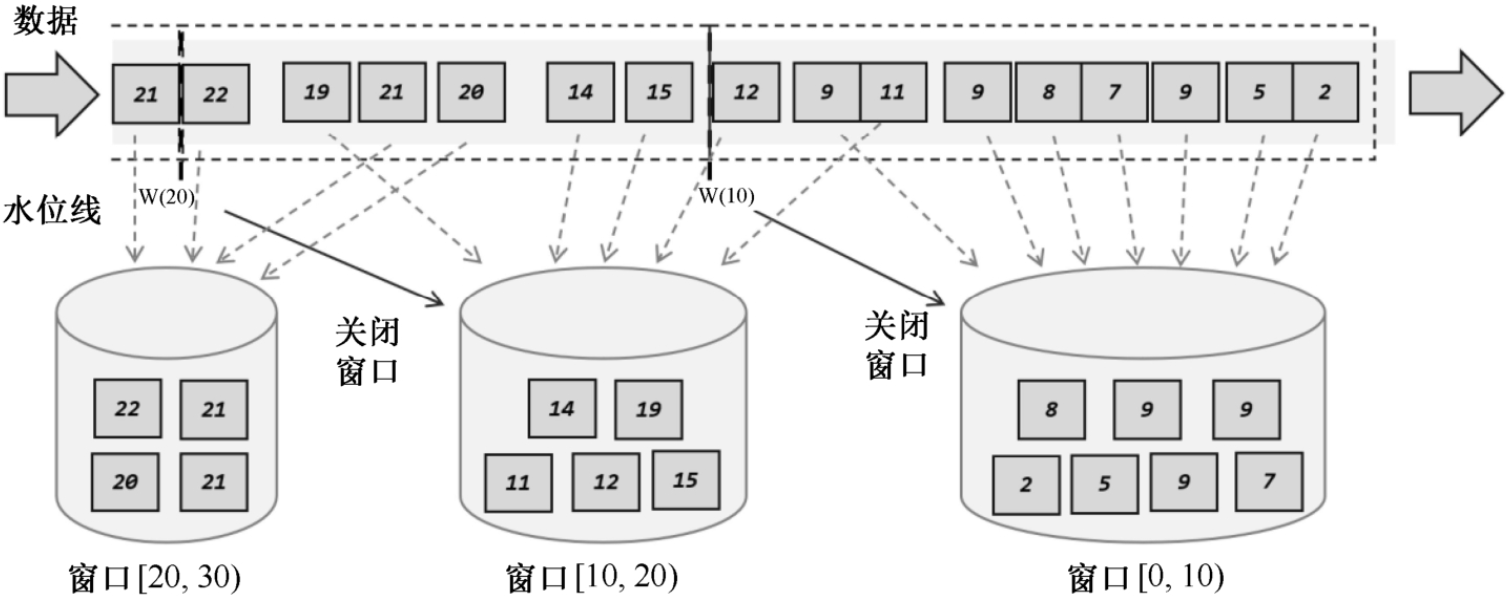
桶的创建是动态的,当有新窗口的数据到来时,才会创建其对应的桶。
另外,到达窗口结束时间,触发计算并关闭窗口。其中触发计算和窗口关闭这两个行为可以分开。
6.3.2 窗口的分类
-
按照
驱动类型分为两种:时间窗口和计数窗口-
时间窗口:以时间点决定窗口的开始和结束,到达结束时间时,窗口关闭,触发计算,输出结果,销毁窗口。根据时间语义的不同,又可分为
处理时间窗口和事件时间窗口时间窗口对应的类是
TimeWindow,包含两个属性start和end其中有一个方法
maxTimestamp(),返回该窗口能包含的最大时间戳,public long maxTimestamp() {return end - 1; }可以看出窗口时间范围是
[start, end),-1是因为水位线生成的时间戳本身就会-1。 -
计数窗口:基于元素个数来截取数据,桶内数据个数达到目标时就触发计算并关闭窗口。底层是通过
全局窗口(Global Windows)来实现的。
-
-
根据窗口分配数据的规则分类
根据数据分配的规则分为4类:
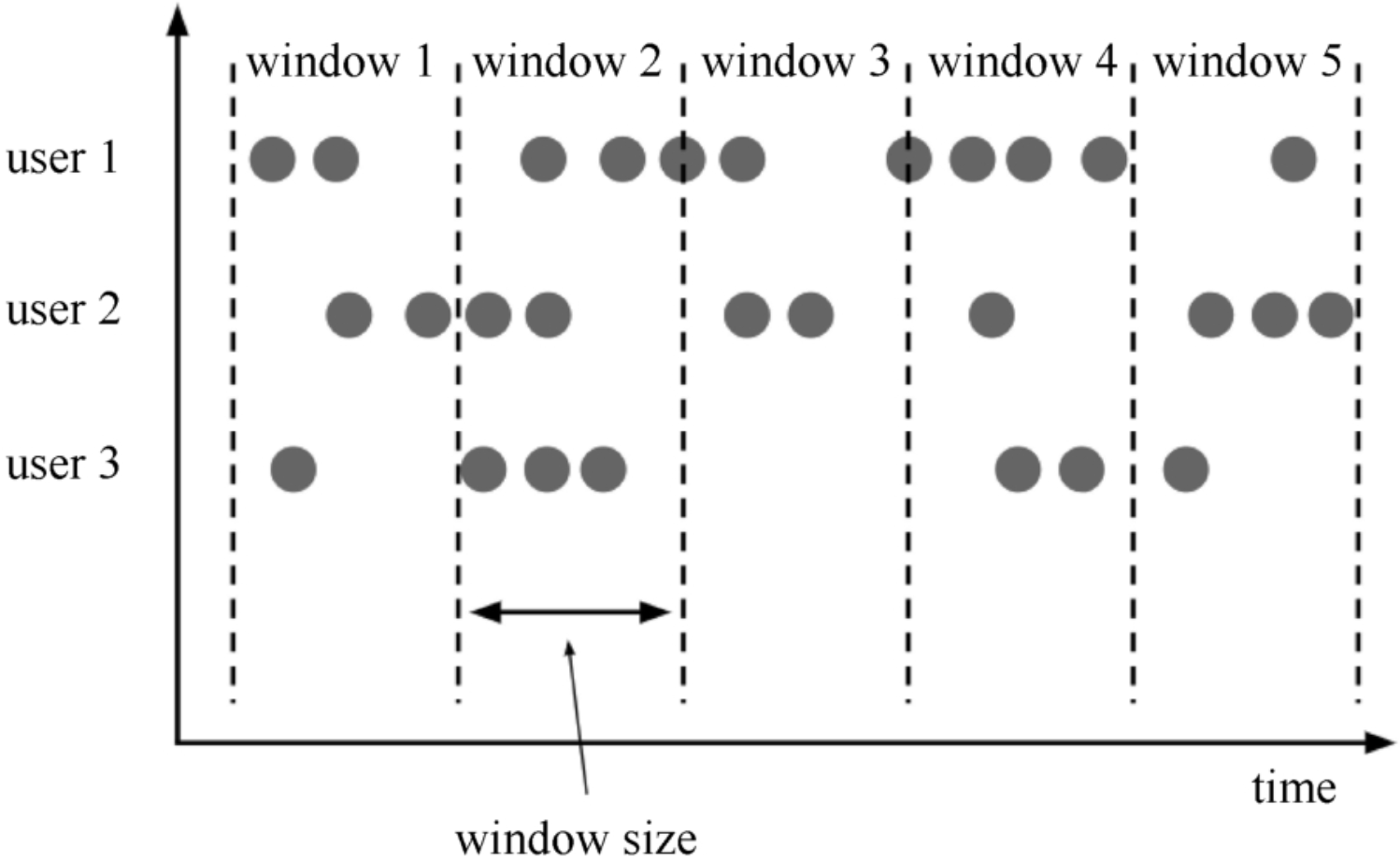
滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。-
滚动窗口(Tumbling Window)参数:窗口大小
窗口之间没有重叠,也没有间隔。
可基于时间定义,也可基于数据个数定义。
-
滑动窗口(Sliding Window)参数:
窗口大小、滑动步长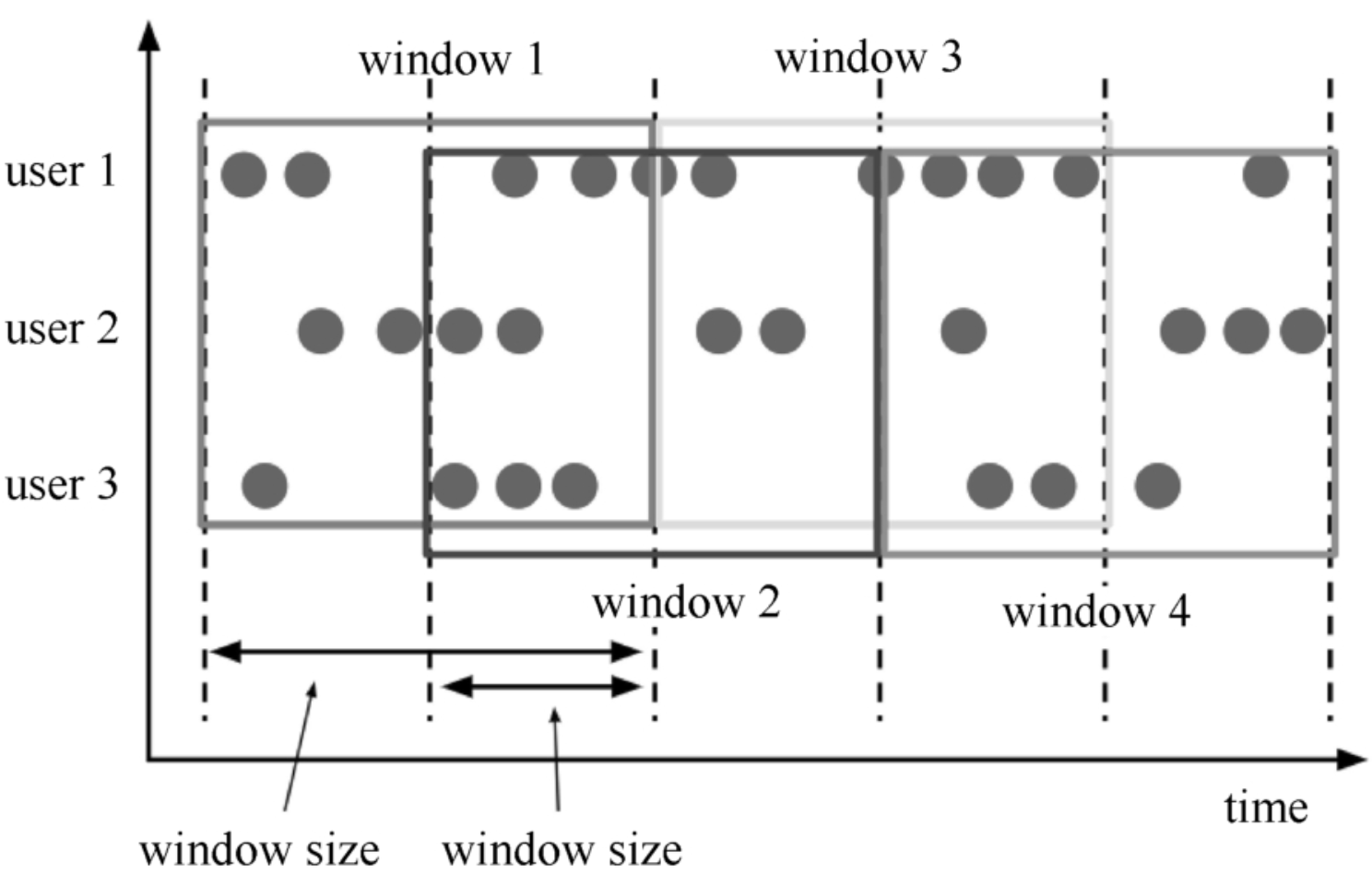
-
会话窗口(Session Window)当有数据到达时,就开启一个会话窗口,如果有数据来,就一直保持会话;如果一段时间没收到数据,就认为会话超时失效,窗口关闭。
会话窗口只能基于时间来定义,因为会话终止的标志就是
隔一段时间没有数据来会话间隔可以设置固定值,也可自定义逻辑从数据中提取值。
Flink底层对会话窗口处理比较特殊:每来一个新数据,就创建一个新的会话窗口,然后判断已有窗口之间的距离,如果小于给定size,就合并之。
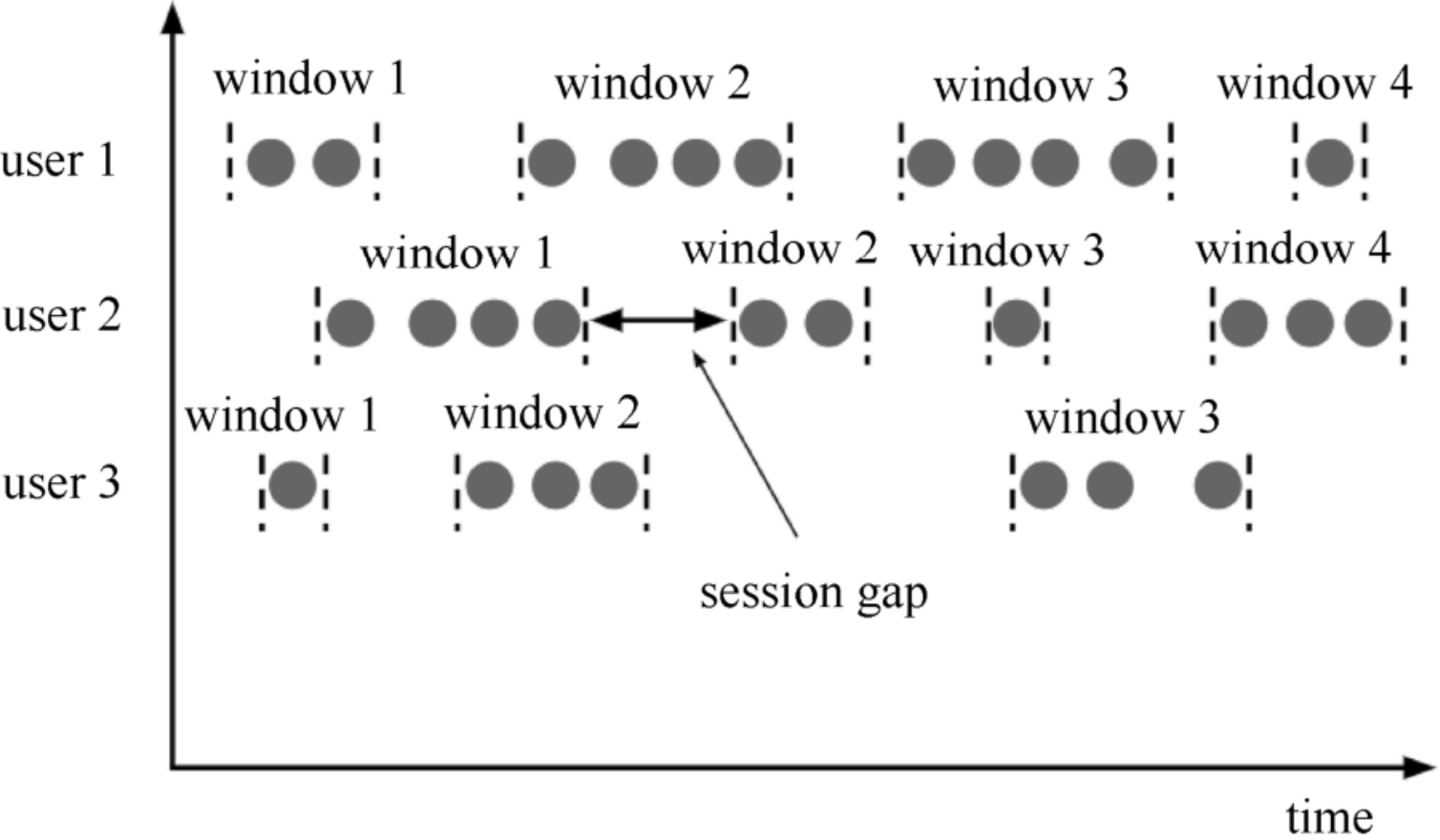
会话窗口长度不固定,起始和结束时间也不确定的,各个分区之间的窗口没有任何关联。
-
``全局窗口(Global Window)`
全局窗口会把相同key的所有数据都分配到同一窗口中,因为无界流没有终点,所以这种窗口没有结束,触发计算的那一刻。要数据进行计算处理,需要自定义
触发器(Trigger)。
-
6.3.3 窗口API概览
定义窗口操作前,需要先确定,是基于Keyed Stream还是没有按键分区,即:在调用窗口算子之前,是否有keyBy()操作。
-
按键分区窗口 - 实际中都使用这个
stream.keyBy(...).window(...) -
非按键分区窗口 - 很少用
stream.windowAll()非按键分区窗口的算子并行度只能为1,不推荐使用。
窗口使用模板
stream.keyBy().window().aggregate()
window():需传入窗口分配器,决定数据被分配到哪个窗口。aggregate():需传入窗口函数,定义窗口的处理逻辑。
6.3.4 窗口分配器
作用:决定数据应该被分配到哪个窗口
通过.windows()传入WindowAssigner,返回WindowedStream。
对于非按键分区窗口,可调用.windowAll(),传入WindowAssigner,返回AllWindowedStream。
按照驱动类型,窗口分为时间窗口和计数窗口,
按照分配规则,窗口分为滚动窗口、滑动窗口、会话窗口、全局窗口。
时间窗口
-
滚动窗口
滚动
事件时间窗口stream.keyBy().window(TumblingEventTimeWindows.of(Duration.ofSeconds(5)))滚动
处理时间窗口stream.keyBy().window(TumblingProcessingTimeWindows.of(Duration.ofSeconds(5)))of()还有一个重载方法,两个参数:size和offset。分别表示窗口大小和窗口起始点偏移量窗口大小为
1day时,默认是0:00到24:00,如果想统计2:00到第二天2:00,就可以使用偏移量调整还有比如切换时区,从UTC切换到UTC+8
.window(TumblingProcessingTimeWindows.of(Duration.ofDays(1), Duration.ofHours(-8))) -
滑动窗口
-
滑动事件时间窗口
stream.keyBy().window(SlidingEventTimeWindows.of(Duration.ofSeconds(10), Duration.ofSeconds(5)))参数:窗口大小、滑动步长、窗口偏移量(可选) -
滑动处理时间窗口
stream.keyBy().window(SlidingProcessingTimeWindows.of(Duration.ofSeconds(10), Duration.ofSeconds(5)))
-
-
会话窗口
-
会话事件时间窗口
.window(EventTimeSessionWindows.withGap(Duration.ofSeconds(10)))参数:会话超时时间支持动态确定会话超时时间
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[(String, Long)] {override def extract(element: (String, Long)): Long = {element._1.length * 1000} })) -
会话处理时间窗口
.window(ProcessingTimeSessionWindows.withGap(Duration.ofSeconds(10)))
-
计数窗口
基于全局窗口。Flink提供了方便的接口:countWindow()。根据分配规则分为滚动计数窗口和滑动计数窗口。
-
滚动计数窗口
stream.keyBy().countWindow(10)参数:size,表示窗口大小。
这里定义了一个大小为10的滚动计数窗口,当窗口元素数量达到10的时候,就会触发计算并关闭窗口。
-
滑动计数窗口
stream.keyBy().countWindow(10, 3)参数:size(窗口大小)、slide(表示和滑动步长)这里定义了一个长度为10、滑动步长为3的窗口。每个窗口统计10个数据,每隔3个数据就统计输出一次结果
全局窗口
计数窗口的底层实现,需要自定义窗口逻辑时使用。
在使用全局窗口时,必须自定义触发器才能实现窗口计算,否则起不到任何作用。
strea.keyBy().window(GlobalWindows.create())
6.3.5 窗口函数
作用:
窗口分配器负责收集数据,决定数据属于哪个窗口。
窗口函数定义要对窗口数据做的计算逻辑
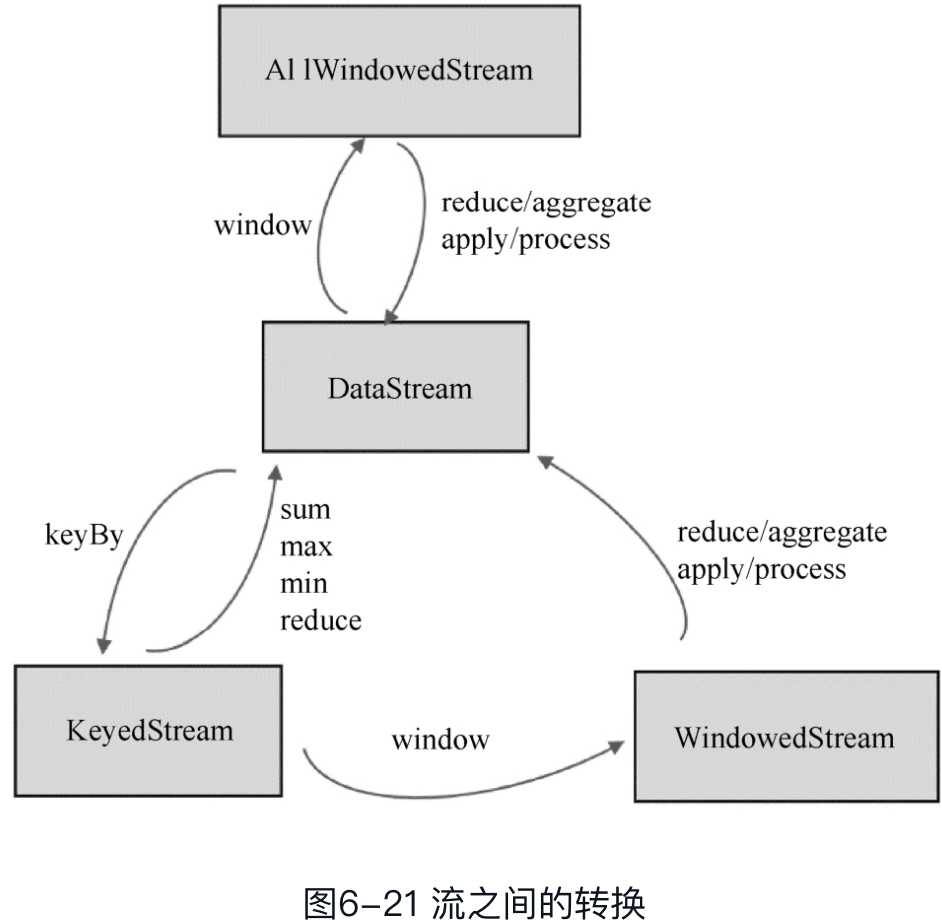
窗口分配器返回的类型为WindowedStream。可通过窗口函数对其进行处理计算,转换成DataStream。
窗口函数分为两类:增量聚合函数和全窗口函数
1. 增量聚合函数
窗口计算大致分为两个阶段:收集数据和处理数据,如果第一阶段只是等待数据到来,等到窗口结束,触发第二阶段再去处理数据,效率太低。
可借鉴流处理的思路:每来一条数据就进行计算,使用一个状态保存中间结果,窗口结束时,直接输出保存的状态,运行效率和实时性将大大提高。
典型的增量聚合函数有两个:ReduceFunction和AggregateFunction
-
ReduceFunction逻辑:将窗口中收集到的数据两两进行处理
创建一个状态,每来一个新的数据,就和之前的聚合状态做计算,从而实现增量式聚合。
@Public @FunctionalInterface public interface ReduceFunction<T> extends Function, Serializable {T reduce(T value1, T value2) throws Exception; }需实现ReduceFunction接口,重写
reduce(),参数是输入的两个元素,计算结果的数据类型需与输入数据的类型一致也就是说,中间聚合的状态和输出的结果,需要和输入的数据类型保持一致。
env.addSource(new ClickSource).assignAscendingTimestamps(_.timestamp).map(r=>(r.user, 1L)).keyBy(_._1).window(TumblingEventTimeWindows.of(Duration.ofSeconds(5))).reduce((r1,r2)=>(r1._1, r1._2+r2._2)).print()输入,中间状态,输出的数据类型都是二元组
(String,Long) -
AggregateFunctionReduceFunction可解决大多数问题,但它要求聚合和输出的数据类型必须和输入一样,使用起来不方便。AggregateFunction有三种数据类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT),三个都可以不一样,接口定义如下@PublicEvolving public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {// 创建初始状态,每个聚合任务只会调用一次。ACC createAccumulator();// 将输入的元素添加到累加器中,// 两个参数:新到的数据value, 当前的累加器accumulator// 返回新的累加器值,对聚合状态进行更新// 每条数据到来都会调用这个方法。ACC add(IN value, ACC accumulator);// 从累加器中提取聚合的输出结果OUT getResult(ACC accumulator);// 合并累加器,并将合并后的累加器返回。// 这个方法只在需要合并窗口的场景下才会被调用, 比如会话窗口。ACC merge(ACC a, ACC b); }
Demo:统计AvgPV
Demo地址
2.全窗口函数
全窗口函数集齐所有数据后才触发计算,因为有些场景下,计算必须基于全部的数据。
全窗口函数有两种:WindowFunction和ProcessWindowFunction。
-
WindowFunction用的比较少,一般用
ProcessWindowFunction,后者是前者的超集- -
ProcessWindowFunctionProcessWindowFunction即包含窗口中的所有数据,还有一个上下文对象(Context)。通过这个Context,可以获取窗口信息、时间信息和状态信息。时间信息包括处理时间和事件时间水位线。
统计UV Demo
Demo地址
3.增量聚合和全窗口结合使用
之前在调用reduce()和aggregate()时,只是直接传入ReduceFunction或AggregateFunction进行增量聚合。还可传入第二个参数:一个全窗口函数:WindowFunction或ProcessWindowFunction
这样,将基于第一个增量聚合函数来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个全窗口函数,处理逻辑输出结果。这样相当于结合了两者的优势,
Demo:统计Url访问量,同时打印窗口起止时间
Demo地址
6.4.6 观察水位线
实验目的: 观察逻辑时钟
实验思路:Source每3s产生一个元素每个Event中的时间戳只比上一个Event中的时间戳增长1s观察触发计算时间观察窗口起止时间和watermark的值
Demo地址
6.3.7 其他API
1. trigger
作用:控制什么时候开始对窗口内元素进行计算
env.addSource(new CustomEventSource_(cnt = 11, gap = 3000)).keyBy(_.user).window(TumblingEventTimeWindows.of(Duration.ofSeconds(1))).trigger()
每种窗口分配器都会有默认触发器,例如,所有事件的时间窗口,默认的触发器都是EventTimeTrigger,一般情况下不需要自己实现trigger,不过有必要了解它的原理。
Trigger是抽象类,有四个抽象方法:
onElement():窗口每来一个元素,调用这个方法,一般用来注册触发时间。onEventTime():水位线 >= 注册的事件时间,调用这个方法。onProcessingTime():水位线 >= 注册的处理时间,调用这个方法。clear():窗口关闭销毁时,调用这个方法。一般用来清除自定义的状态。
前3个函数的返回类型都是TriggerResult,这是一个枚举类型,定义了对窗口的4种操作。
CONTINUE:什么都不做。FIRE:触发计算,输出结果。PURGE:清空窗口中所有数据,销毁窗口。FIRE_AND_PURGE:触发计算输出结果,并清除窗口。
可以看出,Trigger可以控制触发计算、定义窗口何时关闭(销毁),之前我们认为,到了窗口结束时间,就会触发计算输出结果并关闭窗口—这两个操作似乎不可分割;但TriggerResult的定义告诉我们,两者可以分开。
计算PV Demo
窗口大小为20s,计算url在20秒内的访问量,并且每5s触发一次计算。
demo地址
class MyTrigger extends Trigger[Event, TimeWindow] {override def onElement(element: Event, timestamp: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {val isFirstEvent = ctx.getPartitionedState(new ValueStateDescriptor[Boolean]("first_event", classOf[Boolean]))if (!isFirstEvent.value()) {println(s"${window.getStart}~${window.getEnd}:")// 每5s注册一个定时器for (i <- window.getStart to window.getEnd by 5000L) {println(s" Register $i")ctx.registerEventTimeTimer(i)}isFirstEvent.update(true)}TriggerResult.CONTINUE}override def onProcessingTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {TriggerResult.CONTINUE}override def onEventTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {println(s"CurrentTime:$time, Watermark:${ctx.getCurrentWatermark} Called onEventTime")TriggerResult.FIRE}override def clear(window: TimeWindow, ctx: Trigger.TriggerContext): Unit = {ctx.getPartitionedState(new ValueStateDescriptor[Boolean]("first_event", classOf[Boolean])).clear()}
}
-
onElement():每来一个元素,该方法就会被调用,一般在该方法内注册定时器ctx.registerEventTimeTimer(1000L) ctx.registerProcessingTimeTimer(1000L)上述两行分别是注册
EventTime和ProcessingTime触发时间 -
onEventTime():当EventTime水位线值超过注册的定时器值时,该方法就会被调用 -
onProcessingTime:当ProcessingTime水位线值超过注册的定时器值时,该方法就会被调用
比如注册的EventTime定时器的值为1000,当数据推进逻辑时钟大于等于1000时,就会调用onEventTime(),如果没有注册定时器值,则onEventTime和onProcessingTime都不会被触发。
注:Flink所有时间相关的功能都是基于水位线,水位线由数据内的时间戳推动,和真实世界的时间没有关系,比如上面定义的每5s触发一次,实际可能10s、30s或者1min才触发,取决于水位线被时间戳推动到哪里。
2. 移除器
主要用来定义移除某些数据的逻辑,基于WindowedStream调用
3.允许延迟
基于WindowedStream调用allowedLateness(),表示允许这段时间内的延迟数据。
env.addSource(new BasicEventSource).assignAscendingTimestamps(_.timestamp).keyBy(_.url).window(TumblingEventTimeWindows.of(Duration.ofSeconds(5)))//允许10s延迟.allowedLateness(Time.seconds(10))
比如,窗口是08:00~09:00,原本水位线到达09:00就触发计算并关闭窗口。现在允许延迟1分钟,09:00仍然触发计算并输出结果,但不关窗。后续如果有迟到数据到来,将利用之前的结果继续计算并输出结果。直到水位线到达了09:01才真正清空状态、关窗,之后再来的迟到数据会被丢弃。
4.将迟到数据放入测流
将迟到数据输出到测流
Demo地址
6.3.8 窗口API总结
// Keyed Windows
stream.keyBy(...).window(...)[.trigger(...)][.evictor(...)][.allowedLateness(...)][.sideOutputLateData(...)].reduce/aggregate/fold/apply()[.getSideOutput(...)]// Non-Keyed Windows
stream.windowAll(...)[.trigger(...)][.evictor(...)][.allowedLateness(...)][.sideOutputLateData(...)].reduce/aggregate/apply/process()[.getSideOutput(...)]
stream <--DataStream.keyBy(...) <--KeyedStream.window() <--WindowedStream.reduce/aggregate/apply/process() <--DataStreamstream. <--DataStream.windowAll() <-- AllWindowedStream.reduce/aggregate/apply/process() <--DataStream
-
.reduce()参数:
ReduceFunction,ProcessWindowFunction(可选)[增量聚合](1. 增量聚合函数),也可以传入
ProcessWindowFunction实现增量聚合和全窗口结合使用 -
.aggregate()参数:
AggregateFunction,ProcessWindowFunction(可选)和reduce相同
-
.apply()参数:
WindowFunction用的比较少
-
.process()参数:
ProcessWindowFunction全窗口函数
6.4 迟到数据处理总结
-
设置延迟时间
在6.2.3的乱序流中,通过设置延迟时间,在水位线更新时,减去延迟时间,相当于把时钟水位线推进的速度推迟了几分钟,达到等待数据的效果。
-
允许窗口处理迟到数据
通过
allowedLateness()实现,到达窗口时先输出大致结果,先快速实时地输出一个近似结果,之后迟到数据来临时再不断修正,最终得到正确结果。 -
输出到测流
略
案例
结合上面三点,处理迟到数据
- 延迟时间为10s
- 允许迟到20s
- 输出到名为Late的测流
地址
CH-7 处理函数(ProcessFuntion)
处理函数比之前介绍的算子更底层,直面数据流中最基本的元素:数据事件(event)、状态(state),时间(time)。相当于对流有完全的控制权。
7.1 ProcessFuntion
太底层,很少用
1 简介
- 通过
Context的timerService(),访问流中的事件(event)、时间戳(timestamp)、水位线(watermark),注册“定时事件” - 访问状态(state)和其他运行时信息,直接将数据输出到侧输出流(side output)中
使用示例
Github
2 内部解析
两个泛型类型参数:
I(Input):输入数据类型O(Output):输出数据类型
内部两个方法
-
抽象方法
processElement()三个参数:输入值、上下文、收集器(Collector)
对流中每个元素调用一次,方法没有返回值,通过收集器输出数据。
-
非抽象方法
onTimer()当注册的定时器被水位线触发时,该方法就会被调用
也有三个参数:时间戳、上下文,以及收集器,时间戳指的是注册的定时器时间
总结:两个方法都是基于事件触发。处理真实数据调用processElement(),处理水位线调用onTimer()。
注:只有KeyedStream才支持设置定时器
4. 处理函数的分类
-
ProcessFunction最基本的处理函数,基于DataStream直接调用process()时作为参数传入
-
KeyedProcessFunction基于KeyedStream,调用process()时作为参数传入。要想使用定时器,必须基于KeyedStream。
-
ProcessWindowFunction开窗之后的处理函数,也是全窗口函数的代表。基于WindowedStream调用process()时传入。
-
ProcessAllWindowFunction开窗之后的处理函数,基于AllWindowedStream调用process()时传入。
-
CoProcessFunction连接两条流之后的处理函数,基于ConnectedStreams调用process()时传入。关于流的连接合并操作,我们会在后续章节详细介绍。
-
ProcessJoinFunction间隔连接两条流之后的处理函数,基于IntervalJoined调用process()时作为参数传入。
-
BroadcastProcessFunction广播连接流处理函数,基于BroadcastConnectedStream调用process()时作为参数传入。这里的“广播连接流”BroadcastConnectedStream,是一个未做keyBy()处理的普通DataStream与一个广播流进行连接后的产物。关于广播流的相关操作,我们会在后续章节详细介绍。
-
KeyedBroadcastProcessFunction按键分区的广播连接流处理函数,同样是基于BroadcastConnectedStream调用process()时作为参数传入。与BroadcastProcessFunction不同的是,这时的广播连接流,是一个KeyedStream与广播流进行连接之后的产物。
本节主要讲解KeyedProcessFunction和ProcessWindowFunction
7.2 KeyedProcessFunction
1.timerService介绍
注:只有KeyedStream才支持设置定时器,其他的Stream只能获取当前时间
通过Context获得timerService
ctx.timerService()
有6个方法
long currentProcessingTime();
long currentWatermark();
void registerProcessingTimeTimer(long time);
void registerEventTimeTimer(long time);
void deleteProcessingTimeTimer(long time);
void deleteEventTimeTimer(long time);
对于每个key和时间戳,最多只有一个定时器,即使多次注册,onTimer()也只调用一次
定时器也被保存到检查点中。发生故障后,Flink会重启、读取检查点、恢复定时器。如果定时器已经“过期”,它会在重启时被立刻触发。
2.基本使用
只能对
KeyedStream调用KeyedProcessFunction
三个泛型类型参数:
K(Key):按键分区的Key的类型I(Input):输入数据类型O(Output):输出数据类型
方法和ProcessFunction基本相同,用法也相同,就是多了获取分区Key的方法
7.3 窗口处理函数
全窗口处理数据:等所有数据都集齐,才开始处理数据
两个相关函数
-
ProcessWindowFunction对KeyedStream使用 -
ProcessAllWindowFunction对AllWindowStream使用,即不分区的数据流
1. ProcessWindowFunction
四个泛型类型参数
IN(Input):输入数据类型OUT(Output):输出数据类型KEY:Key类型W:窗口的类型,是Window的子类型。一般情况下我们定义时间窗口,W就是TimeWindow
方法:
-
process()public abstract void process(KEY key, Context context, Iterable<IN> elements, Collector<OUT> out) throws Exception;四个参数:
key:KeyBy的Key值context:窗口上下文elements:窗口收集到所有数据out:收集器,收集要输出的元素
窗口处理函数未提供定时器,如果需要定时操作,可以通过窗口触发器trigger实现
7.4 案例 - TOP N
需求:统计每10秒内最热门的两个url链接,并且每5秒更新一次
1. 基于ProcessAllWindowFunction
思路:使用SlideWindow,将窗口内的所有数据都收集起来,然后排序、处理、输出
完整代码
2. 基于KeyedProcessFunction
思路:
- 对数据使用url进行keyBy
- 使用aggregate
- 使用增量聚合对每个url统计访问量
- 使用全窗口函数,对结果进行包装,然后输出
- 使用之前窗口的结束值进行keyBy,对url进行处理,输出结果
完整代码